Recognition: unknown
Understanding and Enforcing Weight Disentanglement in Task Arithmetic
Pith reviewed 2026-05-10 06:31 UTC · model grok-4.3
The pith
Task-feature specialization causes weight disentanglement in task arithmetic and can be strengthened by enforcing orthogonality on task vectors during fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
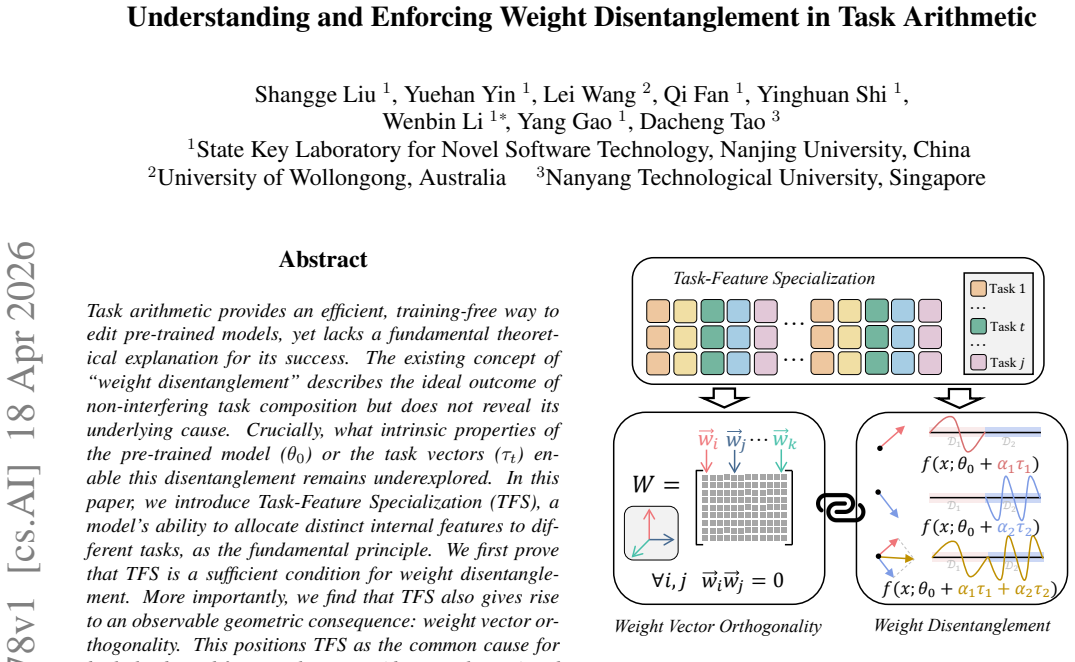
We introduce Task-Feature Specialization (TFS) as the fundamental principle underlying weight disentanglement. We prove that TFS is a sufficient condition for weight disentanglement and that it also produces weight vector orthogonality. This link lets us promote disentanglement indirectly by shaping the observable geometry: OrthoReg regularizes the weight updates that form each task vector to be orthogonal, and we prove this regularization promotes disentanglement. Experiments show OrthoReg consistently improves the performance of multiple task arithmetic methods.
What carries the argument
Task-Feature Specialization (TFS), defined as a model's allocation of distinct internal features to different tasks, which suffices for weight disentanglement and implies orthogonality of the resulting task vectors.
If this is right
- OrthoReg applied during fine-tuning increases orthogonality and thereby improves disentanglement.
- Multiple existing task arithmetic techniques gain performance when their task vectors are produced under OrthoReg.
- Weight vector orthogonality functions as a measurable proxy for the harder-to-observe TFS property.
- The theoretical chain from TFS to disentanglement to orthogonality supplies a causal account for why task arithmetic succeeds.
Where Pith is reading between the lines
- If orthogonality reliably signals successful disentanglement, measuring angles between task vectors could serve as a quick diagnostic before full composition tests.
- The same geometric regularization idea might be adapted to other model-merging settings that rely on additive updates.
- Models fine-tuned under OrthoReg could support larger numbers of composable tasks before interference appears.
- Whether TFS arises spontaneously in certain pre-training regimes or architectures could be tested by checking orthogonality of natural task vectors.
Load-bearing premise
That actively making weight updates orthogonal during fine-tuning will induce or strengthen the internal property of task-feature specialization.
What would settle it
An experiment in which OrthoReg produces clearly orthogonal task vectors yet the composed model still shows interference and accuracy drops when tasks are combined.
Figures









read the original abstract
Task arithmetic provides an efficient, training-free way to edit pre-trained models, yet lacks a fundamental theoretical explanation for its success. The existing concept of ``weight disentanglement" describes the ideal outcome of non-interfering task composition but does not reveal its underlying cause. Crucially, what intrinsic properties of the pre-trained model ($\theta_0$) or the task vectors ($\tau_t$) enable this disentanglement remains underexplored. In this paper, we introduce Task-Feature Specialization (TFS), a model's ability to allocate distinct internal features to different tasks, as the fundamental principle. We first prove that TFS is a sufficient condition for weight disentanglement. More importantly, we find that TFS also gives rise to an observable geometric consequence: weight vector orthogonality. This positions TFS as the common cause for both the desired functional outcome (disentanglement) and a measurable geometric property (orthogonality). This relationship provides the key insight for our method: since the abstract TFS property is intractable to enforce directly, we can instead promote weight disentanglement by shaping its concrete geometric consequence, orthogonality. Therefore, we propose OrthoReg, a simple and effective regularization method that actively enforces an internal orthogonal structure on weight updates ($\Delta W$) that constitute $\tau_t$ during fine-tuning. And we theoretically prove that OrthoReg promotes disentanglement. Extensive experiments demonstrate that OrthoReg consistently and significantly enhances the performance of various task arithmetic methods. Code is available at \href{https://github.com/RL-MIND/OrthoReg}{https://github.com/RL-MIND/OrthoReg}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Task-Feature Specialization (TFS) as the fundamental principle underlying weight disentanglement in task arithmetic. It proves TFS is a sufficient condition for disentanglement and that TFS implies orthogonality of task vectors. It then proposes OrthoReg, a regularization method that enforces orthogonality on weight updates during fine-tuning, claims a theoretical proof that this promotes disentanglement, and reports consistent experimental improvements across task arithmetic methods, with code released.
Significance. If the proofs and the bidirectional link hold, the work supplies a theoretical foundation for task arithmetic by identifying a common cause (TFS) for both functional disentanglement and a measurable geometric property, while delivering a simple, reproducible regularization technique that improves existing methods. The explicit proofs for TFS sufficiency and the availability of code are clear strengths supporting further development in model editing.
major comments (2)
- [Abstract and theoretical analysis of OrthoReg] Abstract and theoretical analysis of OrthoReg: the claim that OrthoReg promotes disentanglement rests on enforcing orthogonality in the updates that form task vectors, yet the provided reasoning only establishes the forward direction (TFS implies orthogonality and disentanglement). The manuscript must supply the explicit step or assumption (e.g., on feature-map linearity or loss convexity) that converts the geometric constraint back into a guarantee of TFS; without it the regularization could produce orthogonal yet still entangled representations, undermining the central justification for the method.
- [Proof of TFS sufficiency] Proof of TFS sufficiency (theoretical section): while the sufficiency direction is stated, the manuscript should clarify whether the derivation assumes a specific model class (linear heads, etc.) or holds generally; any such assumption is load-bearing for the claim that TFS is the intrinsic cause of disentanglement across architectures.
minor comments (1)
- Notation for task vectors and updates (throughout): the distinction between pre-trained weights, task vectors, and fine-tuning updates could be made more explicit in the first use of each symbol to aid readability.
Simulated Author's Rebuttal
We thank the referee for the insightful and constructive comments on our manuscript. We have carefully reviewed the major points concerning the theoretical analysis of OrthoReg and the assumptions underlying the TFS sufficiency proof. Below we respond point-by-point, indicating the revisions we will make to address the concerns while preserving the core contributions.
read point-by-point responses
-
Referee: Abstract and theoretical analysis of OrthoReg: the claim that OrthoReg promotes disentanglement rests on enforcing orthogonality in the updates that form task vectors, yet the provided reasoning only establishes the forward direction (TFS implies orthogonality and disentanglement). The manuscript must supply the explicit step or assumption (e.g., on feature-map linearity or loss convexity) that converts the geometric constraint back into a guarantee of TFS; without it the regularization could produce orthogonal yet still entangled representations, undermining the central justification for the method.
Authors: We agree that the manuscript establishes the forward direction (TFS implies orthogonality and disentanglement) but does not fully close the loop with a converse guarantee. OrthoReg is motivated by orthogonality being a necessary geometric consequence of TFS; enforcing it during fine-tuning serves as a practical proxy to encourage feature specialization. A strict bidirectional proof would indeed require additional assumptions, such as linearity of the feature maps or convexity of the loss. We have revised the abstract and theoretical section to explicitly acknowledge this limitation, clarify that OrthoReg promotes the observable geometric property tightly associated with TFS (rather than claiming a full guarantee), and add a brief discussion of the conditions needed for the converse. The empirical improvements in disentanglement metrics and task arithmetic performance across architectures remain as supporting evidence. revision: yes
-
Referee: Proof of TFS sufficiency (theoretical section): while the sufficiency direction is stated, the manuscript should clarify whether the derivation assumes a specific model class (linear heads, etc.) or holds generally; any such assumption is load-bearing for the claim that TFS is the intrinsic cause of disentanglement across architectures.
Authors: The TFS sufficiency proof is derived in a general setting for neural networks where task vectors are added to a pre-trained model and functional behavior depends on distinct feature allocation. It does not restrict to linear heads but assumes standard additive composition in weight space and that task performance is governed by the specialized internal representations. We have revised the theoretical section to explicitly enumerate these modeling assumptions and to state that the result holds for the transformer and CNN architectures evaluated in the paper, while noting that applicability to other model classes would require analogous verification. This clarification reinforces rather than weakens the positioning of TFS as a fundamental principle. revision: yes
Circularity Check
No significant circularity; derivation is self-contained via new definitions and one-way proofs
full rationale
The paper introduces TFS as a novel internal property, proves it sufficient for weight disentanglement, derives orthogonality as a geometric consequence, and proposes OrthoReg to enforce orthogonality as a tractable proxy while claiming a separate theoretical proof that the regularization promotes disentanglement. These steps rely on explicit definitions and logical implications rather than redefining the target outcome in terms of itself or fitting parameters to the final metric. No self-citation chains, ansatz smuggling, or uniqueness theorems imported from prior author work are present in the provided text. The reverse direction (orthogonality implying TFS) is asserted via the new proof rather than assumed by construction, keeping the chain non-circular even if the proof's validity is debatable on other grounds.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Vector orthogonality implies non-interference in linear weight updates
invented entities (1)
-
Task-Feature Specialization (TFS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Absil, R
P.A. Absil, R. Mahony, and R. Sepulchre.Optimization Al- gorithms on Matrix Manifolds. Princeton University Press,
-
[2]
Uni- tary evolution recurrent neural networks
Mart ´ın Arjovsky, Amar Shah, and Yoshua Bengio. Uni- tary evolution recurrent neural networks. InProceedings of the 33nd International Conference on Machine Learning (ICML), pages 1120–1128, 2016. 2, 19
2016
-
[3]
Lei Jimmy Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization.CoRR, abs/1607.06450, 2016. 15, 16
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
Remote sens- ing image scene classification: Benchmark and state of the art.Proc
Gong Cheng, Junwei Han, and Xiaoqiang Lu. Remote sens- ing image scene classification: Benchmark and state of the art.Proc. IEEE, 105(10):1865–1883, 2017. 6
2017
-
[5]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3606–3613, 2014. 6
2014
-
[6]
Coxeter and S.L
H.S.M. Coxeter and S.L. Greitzer.Geometry Revisited. Mathematical Association of America, 1967. 19
1967
-
[7]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representa- tions (ICLR), 2021. 1
2021
-
[8]
The approximation of one ma- trix by another of lower rank.Psychometrika, 1(3):211–218,
Carl Eckart and Gale Young. The approximation of one ma- trix by another of lower rank.Psychometrika, 1(3):211–218,
-
[9]
Task singular vectors: Reducing task interference in model merging
Antonio Andrea Gargiulo, Donato Crisostomi, Maria Sofia Bucarelli, Simone Scardapane, Fabrizio Silvestri, and Emanuele Rodol `a. Task singular vectors: Reducing task interference in model merging. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18695–18705, 2025. 2
2025
-
[10]
Delving deep into rectifiers: Surpassing human-level per- formance on imagenet classification
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level per- formance on imagenet classification. InIEEE International Conference on Computer Vision (ICCV), pages 1026–1034,
-
[11]
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE J
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens., 12(7):2217–2226,
-
[12]
Dissecting fine-tuning unlearning in large language models
Yihuai Hong, Yuelin Zou, Lijie Hu, Ziqian Zeng, Di Wang, and Haiqin Yang. Dissecting fine-tuning unlearning in large language models. InProceedings of the 2024 Confer- ence on Empirical Methods in Natural Language Processing (EMNLP), pages 3933–3941, 2024. 1
2024
-
[13]
Horn and C.R
R.A. Horn and C.R. Johnson.Matrix Analysis. Cambridge University Press, 1990. 18, 21
1990
-
[14]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InThe Tenth International Conference on Learning Representations (ICLR), 2022. 7, 12
2022
-
[15]
Decor- related batch normalization
Lei Huang, Dawei Yang, Bo Lang, and Jia Deng. Decor- related batch normalization. In2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, pages 791–800. Com- puter Vision Foundation / IEEE Computer Society, 2018. 15, 16
2018
-
[16]
Editing models with task arithmetic
Gabriel Ilharco, Marco T ´ulio Ribeiro, Mitchell Wortsman, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic. InInternational Con- ference on Learning Representations (ICLR), 2023. 1, 2, 3, 6, 7, 8, 12, 23, 26, 27
2023
-
[17]
Batch normalization: Accelerating deep network training by reducing internal co- variate shift
Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal co- variate shift. InProceedings of the 32nd International Con- ference on Machine Learning, ICML 2015, Lille, France, 6- 11 July 2015, pages 448–456. JMLR.org, 2015. 15, 16
2015
-
[18]
Neu- ral tangent kernel: Convergence and generalization in neural networks
Arthur Jacot, Cl ´ement Hongler, and Franck Gabriel. Neu- ral tangent kernel: Convergence and generalization in neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), pages 8580–8589, 2018. 3
2018
-
[19]
Su, and Li Shen
Ruochen Jin, Bojian Hou, Jiancong Xiao, Weijie J. Su, and Li Shen. Fine-tuning attention modules only: Enhancing weight disentanglement in task arithmetic. InInternational Conference on Learning Representations (ICLR), 2025. 2, 6, 7, 23, 26, 27
2025
-
[20]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.CoRR, abs/2001.08361, 2020. 3, 12
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[21]
Collecting a large-scale dataset of fine-grained cars
Jonathan Krause, Jia Deng, Michael Stark, and Li Fei-Fei. Collecting a large-scale dataset of fine-grained cars. InPro- ceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, 2013. 6, 25
2013
-
[22]
Lecun, L
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner. Gradient- based learning applied to document recognition.Proceed- ings of the IEEE, 86(11):2278–2324, 1998. 6
1998
-
[23]
Re- visiting catastrophic forgetting in large language model tun- ing
Hongyu Li, Liang Ding, Meng Fang, and Dacheng Tao. Re- visiting catastrophic forgetting in large language model tun- ing. InFindings of the Association for Computational Lin- guistics: EMNLP 2024, pages 4297–4308, 2024. 1
2024
-
[24]
When is task vector provably effec- tive for model editing? A generalization analysis of nonlin- ear transformers
Hongkang Li, Yihua Zhang, Shuai Zhang, Pin-Yu Chen, Sijia Liu, and Meng Wang. When is task vector provably effec- tive for model editing? A generalization analysis of nonlin- ear transformers. InInternational Conference on Learning Representations (ICLR), 2025. 2
2025
-
[25]
Luenberger and Y
D.G. Luenberger and Y . Ye.Linear and Nonlinear Program- ming. Springer US, 2008. 20
2008
-
[26]
Pre-trained large language mod- els for financial sentiment analysis.CoRR, abs/2401.05215,
Wei Luo and Dihong Gong. Pre-trained large language mod- els for financial sentiment analysis.CoRR, abs/2401.05215,
-
[27]
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning.CoRR, abs/2308.08747, 2023. 1
-
[28]
Nikita Makarov, Maria Bordukova, Papichaya Quengdaeng, Daniel Garger, Raul Rodriguez-Esteban, Fabian Schmich, and Michael P. Menden. Large language models forecast patient health trajectories enabling digital twins.npj Digit. Medicine, 8(1), 2025. 1
2025
-
[29]
Spectral normalization for generative ad- versarial networks
Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative ad- versarial networks. InInternational Conference on Learning Representations (ICLR), 2018. 2, 3, 19
2018
-
[30]
On the stability of fine-tuning BERT: miscon- ceptions, explanations, and strong baselines
Marius Mosbach, Maksym Andriushchenko, and Dietrich Klakow. On the stability of fine-tuning BERT: miscon- ceptions, explanations, and strong baselines. In9th Inter- national Conference on Learning Representations (ICLR),
-
[31]
Reading digits in natural images with unsupervised feature learning
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bis- sacco, Baolin Wu, Andrew Y Ng, et al. Reading digits in natural images with unsupervised feature learning. InNIPS workshop on deep learning and unsupervised feature learn- ing, page 7. Granada, 2011. 6
2011
-
[32]
Task arithmetic in the tangent space: Improved editing of pre-trained models
Guillermo Ortiz-Jimenez, Alessandro Favero, and Pascal Frossard. Task arithmetic in the tangent space: Improved editing of pre-trained models. InAdvances in Neural Infor- mation Processing Systems, pages 66727–66754, 2023. 2, 3, 6, 7, 8, 12, 22, 23, 26, 27
2023
-
[33]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning (ICML), pages 8748–8763, 2021. 1, 6
2021
-
[34]
Rivlin.The Chebyshev Polynomials
T.J. Rivlin.The Chebyshev Polynomials. Wiley, 1974. 19
1974
-
[35]
Rudin.Principles of Mathematical Analysis
W. Rudin.Principles of Mathematical Analysis. McGraw- Hill, 1976. 19
1976
-
[36]
Shibani Santurkar, Dimitris Tsipras, Andrew Ilyas, and Aleksander Madry. How does batch normalization help op- timization? InAdvances in Neural Information Processing Systems 31: Annual Conference on Neural Information Pro- cessing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montr´eal, Canada, pages 2488–2498, 2018. 16
2018
-
[37]
Saxe, James L
Andrew M. Saxe, James L. McClelland, and Surya Gan- guli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. InInternational Conference on Learning Representations (ICLR), 2014. 2
2014
-
[38]
The german traffic sign recognition bench- mark: A multi-class classification competition
Johannes Stallkamp, Marc Schlipsing, Jan Salmen, and Christian Igel. The german traffic sign recognition bench- mark: A multi-class classification competition. InThe 2011 International Joint Conference on Neural Networks (IJCNN), pages 1453–1460. IEEE, 2011. 6
2011
-
[39]
Model merging with SVD to tie the knots
George Stoica, Pratik Ramesh, Boglarka Ecsedi, Leshem Choshen, and Judy Hoffman. Model merging with SVD to tie the knots. InInternational Conference on Learning Rep- resentations (ICLR), 2025. 1
2025
-
[40]
Parameter-efficient multi-task model fusion with partial linearization
Anke Tang, Li Shen, Yong Luo, Yibing Zhan, Han Hu, Bo Du, Yixin Chen, and Dacheng Tao. Parameter-efficient multi-task model fusion with partial linearization. InInter- national Conference on Learning Representations (ICLR),
-
[41]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, Aur´elien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models.CoRR, abs/2302.13971, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neu- ral Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 5998–6008, 2017. 12
2017
-
[43]
Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, and Ludwig Schmidt
Mitchell Wortsman, Gabriel Ilharco, Samir Yitzhak Gadre, Rebecca Roelofs, Raphael Gontijo Lopes, Ari S. Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, and Ludwig Schmidt. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. InInternational Con- ference on Machine Learning ...
-
[44]
Ehinger, Aude Oliva, and Antonio Torralba
Jianxiong Xiao, James Hays, Krista A. Ehinger, Aude Oliva, and Antonio Torralba. SUN database: Large-scale scene recognition from abbey to zoo. InIEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 3485– 3492, 2010. 6
2010
-
[45]
Multi-task model merging via adaptive weight disentanglement.CoRR, abs/2411.18729, 2024
Feng Xiong, Runxi Cheng, Wang Chen, Zhanqiu Zhang, Yiwen Guo, Chun Yuan, and Ruifeng Xu. Multi-task model merging via adaptive weight disentanglement.CoRR, abs/2411.18729, 2024. 14
-
[46]
Raf- fel, and Mohit Bansal
Prateek Yadav, Derek Tam, Leshem Choshen, Colin A. Raf- fel, and Mohit Bansal. Ties-merging: Resolving interference when merging models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 2, 3, 12
2023
-
[47]
arXiv preprint arXiv:2408.07666 , year=
Enneng Yang, Li Shen, Guibing Guo, Xingwei Wang, Xi- aochun Cao, Jie Zhang, and Dacheng Tao. Model merging in llms, mllms, and beyond: Methods, theories, applications and opportunities.CoRR, abs/2408.07666, 2024. 1, 2
-
[48]
Adamerging: Adap- tive model merging for multi-task learning
Enneng Yang, Zhenyi Wang, Li Shen, Shiwei Liu, Guibing Guo, Xingwei Wang, and Dacheng Tao. Adamerging: Adap- tive model merging for multi-task learning. InInternational Conference on Learning Representations (ICLR), 2024. 1, 2
2024
-
[49]
Yiting Yang, Hao Luo, Yuan Sun, Qingsen Yan, Haokui Zhang, Wei Dong, Guoqing Wang, Peng Wang, Yang Yang, and Hengtao Shen. Efficient adaptation of pre-trained vision transformer underpinned by approximately orthogonal fine- tuning strategy.CoRR, abs/2507.13260, 2025. 2, 19
-
[50]
Editing large language models: Problems, methods, and op- portunities
Yunzhi Yao, Peng Wang, Bozhong Tian, Siyuan Cheng, Zhoubo Li, Shumin Deng, Huajun Chen, and Ningyu Zhang. Editing large language models: Problems, methods, and op- portunities. InProceedings of the 2023 Conference on Em- pirical Methods in Natural Language Processing (EMNLP), pages 10222–10240, 2023. 1
2023
-
[51]
McAuley, and Hiroki Naganuma
Kotaro Yoshida, Yuji Naraki, Takafumi Horie, Ryosuke Ya- maki, Ryotaro Shimizu, Yuki Saito, Julian J. McAuley, and Hiroki Naganuma. Mastering task arithmetic: τjp as a key indicator for weight disentanglement. InInternational Con- ference on Learning Representations (ICLR), 2025. 2, 3
2025
-
[52]
Low-rank few-shot adaptation of vision-language models
Maxime Zanella and Ismail Ben Ayed. Low-rank few-shot adaptation of vision-language models. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition, CVPR 2024 - Workshops, Seattle, WA, USA, June 17-18, 2024, pages 1593–1603. IEEE, 2024. 30
2024
-
[53]
Siqi Zeng, Yifei He, Weiqiu You, Yifan Hao, Yao-Hung Hu- bert Tsai, Makoto Yamada, and Han Zhao. Efficient model editing with task vector bases: A theoretical framework and scalable approach.CoRR, abs/2502.01015, 2025. 2
-
[54]
Unraveling lora interference: Orthogonal subspaces for robust model merging
Haobo Zhang and Jiayu Zhou. Unraveling lora interference: Orthogonal subspaces for robust model merging. InProceed- ings of the 63rd Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, pages 26459– 26472. Association for Computational Linguistics, 2025. 2
2025
-
[55]
arXiv preprint arXiv:2201.05337 , year=
Hanqing Zhang, Haolin Song, Shaoyu Li, Ming Zhou, and Dawei Song. A survey of controllable text generation us- ing transformer-based pre-trained language models.CoRR, abs/2201.05337, 2022. 1
-
[56]
in-domain dis- entanglement
Zhengyan Zhang, Yankai Lin, Zhiyuan Liu, Peng Li, Maosong Sun, and Jie Zhou. Moefication: Transformer feed- forward layers are mixtures of experts. InFindings of the As- sociation for Computational Linguistics: ACL 2022, Dublin, Ireland, May 22-27, 2022, pages 877–890. Association for Computational Linguistics, 2022. 3, 12 Understanding and Enforcing Weig...
2022
-
[57]
(67) By Chebyshev’s inequality [34], for any constantC >1, we have, P ∥J(x)−µ J ∥2 2 ≥C 2σ2 J ≤ E ∥J(x)−µ J ∥2 2 C 2σ2 J = σ2 J C 2σ2 J = 1 C 2 . (68) This implies that the squared Euclidean distance between the random vectorJ(x)and its meanµ J is bounded by C 2σ2 J with a probability of at least1−1/C 2. In other words, for a “typical” (i.e., high-probabi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.