A proposal for PU classification under Non-SCAR using clustering and logistic model
Pith reviewed 2026-05-10 06:19 UTC · model grok-4.3
The pith
A 2-means clustering step cleans labels for logistic regression in positive-unlabeled data when SCAR fails.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The proposed algorithm obtains cleaning labels from 2-means clustering on the positive-unlabeled data and then performs logistic regression, treating observations labeled positive by the clusterer along with true positives as positive class and the remainder as negative, proving effective for classification under non-SCAR conditions.
What carries the argument
The cluster cleaning procedure that uses 2-means clustering to derive labels for training a logistic model on PU data violating SCAR.
If this is right
- The proposed clustering algorithm effectively classifies positive-unlabeled data when SCAR is violated.
- LassoJoint shows moderate robustness to SCAR condition perturbations.
- The method works across multiple real machine learning datasets and synthetic data.
Where Pith is reading between the lines
- Extending the cleaning labels to other supervised learners besides logistic regression could broaden applicability.
- The success implies that clusterability in the feature space can replace the SCAR assumption for some problems.
- Testing with higher numbers of clusters or different distance metrics might improve label accuracy in complex cases.
Load-bearing premise
That 2-means clustering on the mixed positive-unlabeled data will produce sufficiently accurate cleaning labels to support effective logistic regression training when the SCAR condition does not hold.
What would settle it
A counterexample dataset where 2-means clustering assigns inaccurate labels leading to logistic regression accuracy no better than chance or standard PU methods under non-SCAR conditions would disprove the method's efficacy.
Figures
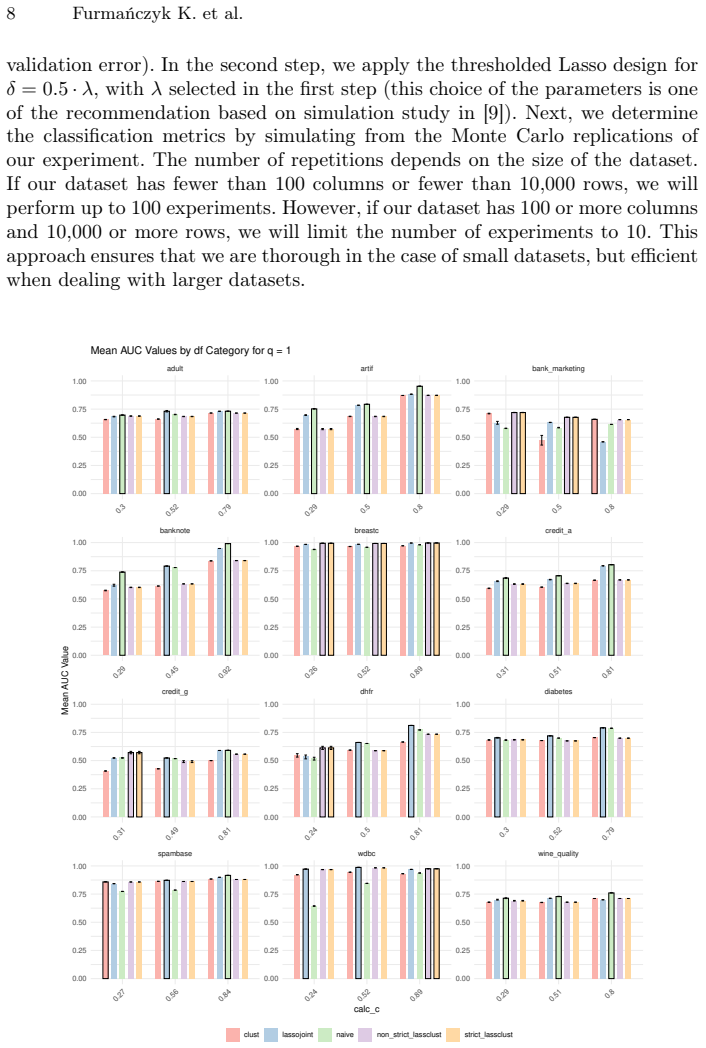

read the original abstract
The present study aims to investigate a cluster cleaning algorithm that is both computationally simple and capable of solving the PU classification when the SCAR condition is unsatisfied. A secondary objective of this study is to determine the robustness of the LassoJoint method to perturbations of the SCAR condition. In the first step of our algorithm, we obtain cleaning labels from 2-means clustering. Subsequently, we perform logistic regression on the cleaned data, assigning positive labels from the cleaning algorithm with additional true positive observations. The remaining observations are assigned the negative label. The proposed algorithm is evaluated by comparing 11 real data sets from machine learning repositories and a synthetic set. The findings obtained from this study demonstrate the efficacy of the clustering algorithm in scenarios where the SCAR condition is violated and further underscore the moderate robustness of the LassoJoint algorithm in this context.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a two-step algorithm for positive-unlabeled (PU) classification when the SCAR assumption does not hold: apply 2-means clustering to the combined positive and unlabeled observations to obtain cleaning labels, then train logistic regression on the resulting cleaned dataset (assigning the positive cluster plus true positives as positive and the remaining observations as negative). It reports evaluation on 11 real datasets from machine learning repositories plus one synthetic dataset and claims that the clustering approach is effective under non-SCAR violations while LassoJoint exhibits moderate robustness.
Significance. If the empirical claims were supported by quantitative metrics, baseline comparisons, and controlled non-SCAR simulations, the work would offer a computationally simple alternative for PU learning in practical settings where the SCAR assumption is routinely violated, such as in medical or fraud-detection applications.
major comments (2)
- [Abstract] Abstract: the claim that the clustering algorithm demonstrates efficacy on 11 real datasets plus one synthetic set and that LassoJoint shows moderate robustness is unsupported, as the abstract (and visible manuscript) supplies no quantitative performance metrics, no description of how non-SCAR violations were generated or measured, and no baseline comparisons.
- [Algorithm description] Algorithm description (first step): the central claim requires that 2-means clustering on the mixed positive-unlabeled data produces cleaning labels sufficiently aligned with the true positive class to support effective logistic regression; under non-SCAR the unlabeled set is an arbitrary mixture whose components need not form two well-separated spherical clusters, and no mechanism is given to guarantee that the algorithm-chosen positive cluster corresponds to the true class rather than an unrelated feature partition.
minor comments (1)
- [Abstract] The term 'LassoJoint' is introduced without definition or citation to its original source.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, agreeing where revisions are needed to strengthen the presentation and clarifying the heuristic nature of our proposed method.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the clustering algorithm demonstrates efficacy on 11 real datasets plus one synthetic set and that LassoJoint shows moderate robustness is unsupported, as the abstract (and visible manuscript) supplies no quantitative performance metrics, no description of how non-SCAR violations were generated or measured, and no baseline comparisons.
Authors: We agree that the abstract would benefit from quantitative support for the claims. The experimental section of the manuscript already contains performance tables comparing our method to baselines including LassoJoint across the 11 real datasets and the synthetic data, along with details on how non-SCAR violations were introduced via feature-dependent labeling probabilities. In the revision we will condense key metrics (e.g., AUC or accuracy gains) and a brief description of the simulation protocol into the abstract to make the efficacy claims explicit. revision: yes
-
Referee: [Algorithm description] Algorithm description (first step): the central claim requires that 2-means clustering on the mixed positive-unlabeled data produces cleaning labels sufficiently aligned with the true positive class to support effective logistic regression; under non-SCAR the unlabeled set is an arbitrary mixture whose components need not form two well-separated spherical clusters, and no mechanism is given to guarantee that the algorithm-chosen positive cluster corresponds to the true class rather than an unrelated feature partition.
Authors: The referee correctly identifies that the method is heuristic rather than theoretically guaranteed. Under non-SCAR the unlabeled data can indeed form arbitrary mixtures, and 2-means may recover a partition unrelated to the true label. Our proposal relies on the practical assumption that the positive class often exhibits sufficient separation in feature space for clustering to provide useful cleaning labels, which we observe empirically on the evaluated datasets. We will revise the algorithm description to state this assumption explicitly, add a limitations paragraph discussing failure cases when clusters do not align with the positive class, and include a new analysis on the synthetic data quantifying cluster-label agreement under varying degrees of non-SCAR violation. revision: yes
Circularity Check
No circularity: empirical algorithm proposal evaluated on external benchmarks
full rationale
The paper proposes a two-step procedure (2-means clustering on mixed PU observations to produce cleaning labels, followed by logistic regression on the cleaned set) and evaluates it by direct performance comparison on 11 real ML-repository datasets plus one synthetic set. No mathematical derivation chain, fitted parameters presented as predictions, or self-citation load-bearing steps exist; the efficacy claim is grounded solely in these external empirical results rather than any reduction of outputs to the algorithm's own inputs by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption 2-means clustering produces useful cleaning labels for subsequent logistic regression under non-SCAR conditions
Reference graph
Works this paper leans on
-
[1]
A vailable from http:arxiv.org/abs/1811.04820v3 (2020) A proposal for PU
Bekker, J., Davis, J.: Learning from positive and unlabel ed data: a survey. A vailable from http:arxiv.org/abs/1811.04820v3 (2020) A proposal for PU ... 11
-
[2]
Bekker,J., Robberechts, R., Davis, J.: Beyond the Select ed Completely At Random Assumption for Learning from Positive and Unlabeled Data. P roceedings of the 2019 European Conference on Machine Learning and Principle s and Practice of Knowledge Discovery in Databases, v. 11907, Springer, Cham . pp. 71-85. (2019)
work page 2019
-
[3]
BMC Bioinformatics 11, 1, 228, (2010) https://doi.org/10.1186/1471-2105-11-228
Cerulo, L., Elkan, C., Ceccarelli, M.: Learning gene regu latory networks from only positive and unlabeled data. BMC Bioinformatics 11, 1, 228, (2010) https://doi.org/10.1186/1471-2105-11-228
-
[4]
Dua, D., Graff, C.: UCI Machine Learning Repository. [http://archive.ics.uci.edu/ml], Irvine, CA: Universit y of California, School of Information and Computer Science (2019)
work page 2019
-
[5]
Friedman, J., Hastie, T., Simon, N., Tibshirani, R.: Glmn et: Lasso and elastic-net regularized generalized linear models. R package version 2 .0 (2015)
work page 2015
-
[6]
Journal of Statistical Soft ware 33 (1), pp
Friedman, J., Hastie, T., Tibshirani, R.: Regularizatio n Paths for Generalized Linear Models via Coordinate Descent. Journal of Statistical Soft ware 33 (1), pp. 1-22. (2010) https://www.jstatsoft.org/v33/i01/
work page 2010
-
[7]
Computa tional Sciences-ICCS 2021, Lecture Notes In Computer Science 12744, pp
Furmańczyk, K., Dudziński, M., Dziewa-Dawidczyk, D.: So me proposal of the high dimensional PU learning classification procedure. Computa tional Sciences-ICCS 2021, Lecture Notes In Computer Science 12744, pp. 18-25. (2 021)
work page 2021
-
[8]
Lecture Notes In Compute r Science 13350, pp
Furmańczyk, K., Paczutkowski, K., Dudziński, M., Dziewa -Dawidczyk, D.: Compu- tational Sciences-ICCS 2022, Classification methods based on fitting logistic regres- sion to positie and unlabeled data. Lecture Notes In Compute r Science 13350, pp. 31-45. (2022)
work page 2022
-
[9]
Furmańczyk, K., Paczutkowski, K., Dudziński, M., Dziewa -Dawidczyk, D.: Classifi- cation and feature selection methods based on fitting logist ic regression to PU data. J. Comput. Sci. 72: 102095 (2023)
work page 2023
-
[10]
Furmańczyk, K., Mielniczuk, J., Rejchel, W., Teisseyre , P.: Double Logistic Regres- sion Approach to Biased Positive-Unlabeled Data. ECAI 2023 : pp. 764-771. (2023)
work page 2023
-
[11]
R package version 6.0-86 (20 20)
Kuhn, M.: The caret package. R package version 6.0-86 (20 20)
-
[12]
IEEE Trans Pattern Anal Mach Intell, pp
Gong, C., Wang, Q., Liu, T., Han, B., You, J., Yang, J., Tao , D.: Instance- dependent positive and unlabeled with labeling bias estima tion. IEEE Trans Pattern Anal Mach Intell, pp. 1-16. (2021)
work page 2021
-
[13]
Guo, T., Xu, C., Huang, J., Wang, Y., Shi, B., Xu, C., Tao, D .: On positive- unlabeled classification in GAN. CVPR (2020)
work page 2020
-
[14]
Hou, M., Chaib-draa, B., Li, C., Zhao, Q.: Generative adv ersarial positive- unlabeled learning. Proceedings of the twenty-seventh Int ernational Joint Confer- ence on Artificial Intelligence (IJCAI-18) (2018)
work page 2018
-
[15]
IEEE Tran sactions on Geo- science and Remote Sensing 49, 2, pp
Li, W., Guo, Q., Elkan, C.: A Positive and Unlabeled Learn ing Algorithm for One-Class Classification of Remote-Sensing Data. IEEE Tran sactions on Geo- science and Remote Sensing 49, 2, pp. 717–725. (2011) https: //doi.org/10.1109/ TGRS.2010.2058578
-
[16]
Li, X., Liu, B.: Learning to Classify Texts Using Positiv e and Unlabeled Data. In Proceedings of the 18th International Joint Conference o n Artificial Intelligence (Acapulco, Mexico) (IJCAI’03), Morgan Kaufmann Publisher s Inc., San Francisco, CA, USA, pp. 587–592. (2003)
work page 2003
-
[17]
B Liu, Y. Dai, X. Li, W.S. Lee, P. S. Yu, Building Text Class ifiers Using Positive and Unlabeled Examples, In Proceedings of the Third IEEE Int ernational Confer- ence on Data Mining (ICDM ’03), IEEE Computer Society, USA, ( 2003), 179
work page 2003
-
[18]
Journal of Informa tion Science and En- gineering, (2014), 30 (5)
Liu, L., & Peng, T., Clustering-based method for positiv e and unlabeled text cat- egorization enhanced by improved TFIDF. Journal of Informa tion Science and En- gineering, (2014), 30 (5). https://doi.org/10.6688/JISE . 2014.30.5.10 12 Furmańczyk K. et al
-
[19]
Advances in Da ta Analysis and Classifi- cation 15, pp
Łazęcka, M., Mielniczuk, J., Teisseyre, P.: Estimating the class prior for positive and unlabelled data via logistic regression. Advances in Da ta Analysis and Classifi- cation 15, pp. 1039-1068. (2021)
work page 2021
-
[20]
et al.: pROC: An Open-Source Package for R and S+ t o Analyze and Compare ROC Curves
Robin X. et al.: pROC: An Open-Source Package for R and S+ t o Analyze and Compare ROC Curves. BMC Bioinformatics, vol. 12, p. 77. (201 1)
-
[21]
BMC Bioinformatic s 16, 18 (2015), S12
Ren, J., Liu, Q., Ellis, J., Li,J.: Positive-unlabeled l earning for the predic- tion of conformational B-cell epitopes. BMC Bioinformatic s 16, 18 (2015), S12. https://doi.org/10.1186/1471-2105-16-S18-S12
-
[22]
R package version 1.1.1 (2020)
Sokol, S.: MLmetrics: Machine Learning Evaluation Metr ics. R package version 1.1.1 (2020)
work page 2020
-
[23]
Computationa l Sciences-ICCS 2020, pp
Teisseyre, P., Mielniczuk, J., Łazęcka, M.: Different st rategies of fitting logistic regression for positive and unlabelled data. Computationa l Sciences-ICCS 2020, pp. 3-17. (2020)
work page 2020
-
[24]
Tibshirani, R.: Regression shrinkage and selection via the lasso. J. Roy. Statist. Soc. Ser. B 58, pp. 267-288. (1996)
work page 1996
-
[25]
R package version 1.4.0 (2019)
Wickham, H.: stringr: Simple, Consistent Wrappers for C ommon String Opera- tions. R package version 1.4.0 (2019)
work page 2019
-
[26]
R package version 1.0.0 (2020)
Wickham, H., François, R., Henry, L., Müller, K.: dplyr: A Grammar of Data Manipulation. R package version 1.0.0 (2020)
work page 2020
-
[27]
Yi, J., Hsieh, C.-J., Varshney, K. R., Zhang, L., Li, Y.: S calable Demand-Aware Recommendation, In Proceedings of the 31st International C onference on Neural Information Processing Systems. (Long Beach, California, USA) (NIPS’17). Curran Associates Inc., Red Hook, NY, USA, pp. 2409–2418. (2017)
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.