Recognition: unknown
RoIt-XMASA: Multi-Domain Multilingual Sentiment Analysis Dataset for Romanian and Italian
Pith reviewed 2026-05-10 06:24 UTC · model grok-4.3
The pith
RoIt-XMASA dataset with meta-learned adversarial training lets XLM-R reach 66.23% F1 in cross-lingual and cross-domain sentiment analysis for Italian and Romanian.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
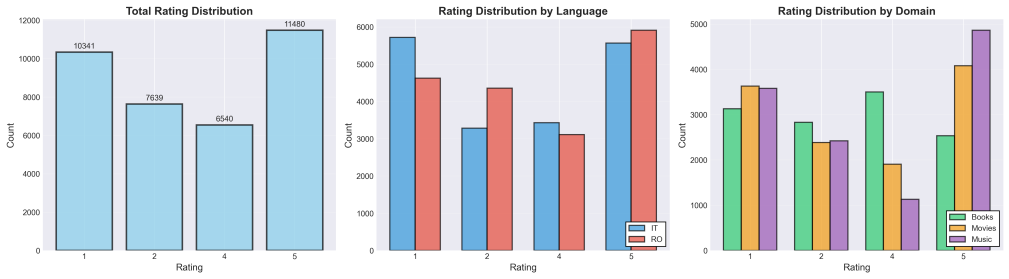
We present the RoIt-XMASA dataset extending cross-lingual multi-domain sentiment analysis to Italian and Romanian with 36,000 labeled and 202,141 unlabeled reviews in books, movies, and music. Our multi-target adversarial training framework uses loss reversal with meta-learned coefficients to balance sentiment classification against domain and language invariance. This allows XLM-R to achieve an F1-score of 66.23%, which is 4.64% better than the baseline, while few-shot prompting of Llama-3.1-8B yields 58.43% F1-score.
What carries the argument
Multi-target adversarial training framework with loss reversal and meta-learned coefficients for balancing sentiment discrimination, domain invariance, and language invariance.
If this is right
- Higher accuracy on cross-lingual and cross-domain sentiment classification for Italian and Romanian.
- Meta-learning provides a workable way to tune multiple adversarial objectives at once.
- Fine-tuned models outperform few-shot large language models on this task by a clear margin.
- New labeled and unlabeled resources exist for testing future multilingual models in these languages.
Where Pith is reading between the lines
- The same dataset construction and balancing method could extend to other language pairs or additional domains.
- The approach may apply to other tasks where models must ignore certain attributes like topic while focusing on a target label.
- Larger models or refined prompting could narrow the gap to fine-tuned performance in future experiments.
- Uniform models trained this way could simplify real-world analysis of customer feedback across languages and product types.
Load-bearing premise
The meta-learned coefficients successfully balance sentiment discrimination against domain and language invariance without causing training instability or overfitting on the specific dataset splits.
What would settle it
Retraining XLM-R on the same splits with fixed rather than meta-learned coefficients and finding no statistically significant F1 improvement over the baseline would show the meta-learning step adds no value.
Figures





read the original abstract
We present RoIt-XMASA, a multilingual dataset that extends the Cross-lingual Multi-domain Amazon Sentiment Analysis to Italian and Romanian, comprising 36,000 labeled reviews across three domains (books, movies, and music) and 202,141 unlabeled samples. To address cross-lingual and cross-domain challenges, we propose a multi-target adversarial training framework that employs loss reversal with meta-learned coefficients to dynamically balance sentiment discrimination with domain and language invariance. XLM-R achieves an F1-score of 66.23% with our approach, outperforming the baseline by 4.64%. Few-shot evaluation shows that Llama-3.1-8B achieves 58.43% F1-score, revealing a meaningful trade-off between the efficiency of prompting-based approaches and the higher performance of task-specific fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RoIt-XMASA, a multilingual multi-domain sentiment analysis dataset extending prior Amazon review resources to Romanian and Italian, with 36,000 labeled reviews across books/movies/music domains plus 202,141 unlabeled samples. It proposes a multi-target adversarial training method for XLM-R that applies loss reversal with meta-learned coefficients to dynamically balance sentiment discrimination against domain and language invariance, reporting 66.23% F1 (4.64% above baseline) and a few-shot Llama-3.1-8B result of 58.43% F1.
Significance. If validated, the dataset provides a useful new resource for cross-lingual and cross-domain sentiment analysis in lower-resource Romance languages, and the adversarial framework with meta-learned balancing offers a potentially generalizable technique for multi-objective invariance. The efficiency comparison to prompting-based LLMs is also informative. The work earns credit for dataset scale and the inclusion of both fine-tuning and few-shot evaluations.
major comments (2)
- [Method and Results sections (as described in abstract)] The central performance claim (XLM-R at 66.23% F1 via the proposed multi-target adversarial training, 4.64% above baseline) depends on the meta-learned coefficients successfully balancing the objectives without overfitting to the specific 36k labeled splits. The method description indicates dynamic balancing via loss reversal, but no coefficient trajectories, training dynamics, seed-wise variance, or ablation isolating the meta-learning component from other training choices are provided; this leaves the attribution of the gain unverified and is load-bearing for the main result.
- [Experimental evaluation (abstract and results)] No error bars, statistical significance tests, or full experimental protocol (including exact train/val/test partitions, hyperparameter search, and convergence criteria) accompany the reported F1 scores or the few-shot evaluation; this undermines assessment of whether the 4.64% margin is reproducible or statistically meaningful.
minor comments (2)
- [Dataset description] Dataset construction details (e.g., annotation process, domain balance, and how the 202k unlabeled samples are used) would benefit from a dedicated table or subsection for clarity.
- [Method] Notation for the meta-learned coefficients and the precise form of the multi-target loss could be formalized with equations to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments below regarding verification of the performance gains and experimental reproducibility. We will incorporate additional analyses and details in the revised version to strengthen the paper.
read point-by-point responses
-
Referee: [Method and Results sections (as described in abstract)] The central performance claim (XLM-R at 66.23% F1 via the proposed multi-target adversarial training, 4.64% above baseline) depends on the meta-learned coefficients successfully balancing the objectives without overfitting to the specific 36k labeled splits. The method description indicates dynamic balancing via loss reversal, but no coefficient trajectories, training dynamics, seed-wise variance, or ablation isolating the meta-learning component from other training choices are provided; this leaves the attribution of the gain unverified and is load-bearing for the main result.
Authors: We agree that further details on the meta-learning dynamics are needed to fully attribute the gains. In the revised manuscript, we will add plots showing the trajectories of the meta-learned coefficients across training epochs, report performance with standard deviations over multiple random seeds, and include an ablation study comparing the full meta-learning approach against variants with fixed coefficients or without the meta-component. These additions will help confirm the balancing mechanism's effectiveness. revision: yes
-
Referee: [Experimental evaluation (abstract and results)] No error bars, statistical significance tests, or full experimental protocol (including exact train/val/test partitions, hyperparameter search, and convergence criteria) accompany the reported F1 scores or the few-shot evaluation; this undermines assessment of whether the 4.64% margin is reproducible or statistically meaningful.
Authors: We acknowledge the importance of these elements for reproducibility. In the revision, we will report all F1 scores with error bars (standard deviation across 5 seeds), include statistical significance tests (e.g., paired t-tests with p-values) for the reported improvements, and expand the Experimental Setup section with exact train/val/test splits, the hyperparameter search procedure, and convergence criteria. Similar details will be added for the few-shot Llama-3.1-8B evaluation. revision: yes
Circularity Check
No circularity: empirical F1 scores measured on held-out test splits of newly introduced dataset
full rationale
The central result is an F1-score of 66.23% achieved by XLM-R on the RoIt-XMASA test set after multi-target adversarial training. This metric is computed on data partitions that are disjoint from training, so the reported improvement over baseline does not reduce by construction to any fitted coefficient or self-citation. The meta-learned coefficients are internal to the training procedure; their effect is evaluated externally via held-out performance rather than being redefined as the result itself. No self-definitional equations, renamed known results, or load-bearing self-citations that collapse the claim are present in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Labeled reviews in the dataset carry accurate sentiment annotations.
- domain assumption Adversarial loss reversal combined with meta-learned coefficients can produce representations that are invariant to domain and language while remaining discriminative for sentiment.
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 31st annual ACM symposium on applied computing, 1140–1145
An evaluation of machine translation for multilingual sentence-level sentiment analysis. InProceedings of the 31st annual ACM symposium on applied computing, 1140–1145. Augustyniak, L.; Wo´zniak, S.; Gruza, M.; Gramacki, P.; Ra- jda, K.; Morzy, M.; and Kajdanowicz, T. 2023. Massively multilingual corpus of sentiment datasets and multi-faceted sentiment cl...
-
[2]
InProceedings of the 2023 conference on empirical methods in natural lan- guage processing, 11265–11279
UDAPDR: unsupervised domain adaptation via LLM prompting and distillation of rerankers. InProceedings of the 2023 conference on empirical methods in natural lan- guage processing, 11265–11279. Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. At- tention is all you need.Advances in neural in...
2023
-
[3]
For most authors... (a) Would answering this research question advance sci- ence without violating social contracts, such as violat- ing privacy norms, perpetuating unfair profiling, exac- erbating the socio-economic divide, or implying disre- spect to societies or cultures? Yes, this work introduces a multilingual dataset to improve sentiment analy- sis ...
-
[4]
Additionally, if your study involves hypotheses testing... (a) Did you clearly state the assumptions underlying all theoretical results? N/A (b) Have you provided justifications for all theoretical re- sults? N/A (c) Did you discuss competing hypotheses or theories that might challenge or complement your theoretical re- sults? N/A (d) Have you considered ...
-
[5]
(a) Did you state the full set of assumptions of all theoret- ical results? N/A (b) Did you include complete proofs of all theoretical re- sults? N/A
Additionally, if you are including theoretical proofs... (a) Did you state the full set of assumptions of all theoret- ical results? N/A (b) Did you include complete proofs of all theoretical re- sults? N/A
-
[6]
Additionally, if you ran machine learning experiments... (a) Did you include the code, data, and instructions needed to reproduce the main experimental results (ei- ther in the supplemental material or as a URL)? Yes, the dataset is released on HuggingFace (see Footnote 1). (b) Did you specify all the training details (e.g., data splits, hyperparameters, ...
-
[7]
(a) If your work uses existing assets, did you cite the cre- ators? Yes, we cite the original XMASA dataset cre- ators and the developers of models like XLM-R and Llama-3.1
Additionally, if you are using existing assets (e.g., code, data, models) or curating/releasing new assets,without compromising anonymity... (a) If your work uses existing assets, did you cite the cre- ators? Yes, we cite the original XMASA dataset cre- ators and the developers of models like XLM-R and Llama-3.1. (b) Did you mention the license of the ass...
-
[8]
Additionally, if you used crowdsourcing or conducted research with human subjects,without compromising anonymity... (a) Did you include the full text of instructions given to participants and screenshots? N/A (b) Did you describe any potential participant risks, with mentions of Institutional Review Board (IRB) ap- provals? N/A (c) Did you include the est...
2007
-
[9]
This includes ellipses (”......”→”...”) and mixed punctuation patterns
while preserving essential, semantic, and syntactic in- formation for sentiment analysis: 1.Punctuation normalization: Multiple consecutive punctuation marks were reduced to a maximum of three instances (e.g., ”!!!!!”→”!!!”), preserving emphasis while preventing excessive repetition. This includes ellipses (”......”→”...”) and mixed punctuation patterns. ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.