A Multi-Agent Approach for Claim Verification from Tabular Data Documents
Pith reviewed 2026-05-10 06:28 UTC · model grok-4.3
The pith
A three-agent zero-shot framework verifies tabular claims competitively while using smaller models and full reasoning traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
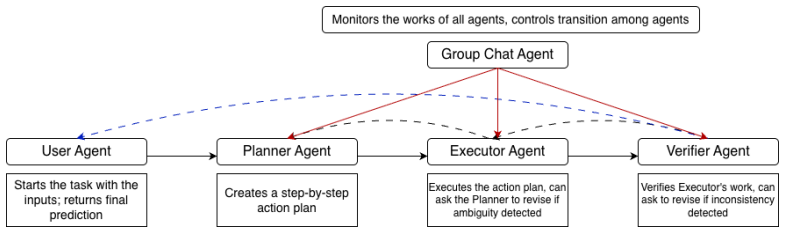
The authors introduce a multi-agent framework consisting of Planner, Executor, and Verifier agents that each apply zero-shot Chain-of-Thought prompting to handle claim verification from tabular data documents. The Planner generates explicit reasoning strategies, the Executor supplies detailed computation steps, and the Verifier validates the logic, producing interpretable verification traces. Experiments on multiple datasets show the framework reaches state-of-the-art performance on two of them and matches the best results on the other two, all while using underlying models of 27 to 92 billion parameters rather than 235 billion.
What carries the argument
The three specialized agents (Planner, Executor, Verifier) that each use zero-shot Chain-of-Thought prompting to decompose the verification task into strategy generation, computation, and logic validation.
If this is right
- Claim verification from tables reaches high accuracy without any fine-tuning of the underlying models.
- Each verification decision is accompanied by an explicit trace of the planning, execution, and validation steps.
- Performance near the best available results is achievable with models substantially smaller than the largest current systems.
- The same fixed agent roles function effectively across multiple distinct tabular datasets and claim types.
Where Pith is reading between the lines
- Similar role-based decompositions could support verification tasks over other structured data such as databases or knowledge graphs.
- The efficiency gains from smaller models suggest the approach may suit real-time or resource-constrained verification applications.
- Adding or swapping agent roles could extend coverage to claims requiring external knowledge sources not handled by the current prompts.
Load-bearing premise
The zero-shot Chain-of-Thought prompting with the three fixed agent roles produces reliable, generalizable verification results across varied tabular datasets and claim types without requiring fine-tuning or task-specific adaptation.
What would settle it
Testing the framework on a fresh tabular dataset with claims that demand multi-step calculations or domain knowledge outside the basic agent prompts and measuring whether accuracy falls well below the reported top results.
Figures











read the original abstract
We present a novel approach for claim verification from tabular data documents. Recent LLM-based approaches either employ complex pretraining/fine-tuning or decompose verification into subtasks, often lacking comprehensive explanations and generalizability. To address these limitations, we propose a Multi-Agentic framework for Claim verification (MACE) consisting of three specialized agents: Planner, Executor, and Verifier. Instead of elaborate finetuning, each agent employs a zero-shot Chain-of-Thought setup to perform its tasks. MACE produces interpretable verification traces, with the Planner generating explicit reasoning strategies, the Executor providing detailed computation steps, and the Verifier validating the logic. Experiments demonstrate that MACE achieves state-of-the-art (SOTA) performance on two datasets and performs on par with the best models on two others, while achieving 80--100\% of best performance with substantially smaller models: 27--92B parameters versus 235B. This combination of competitive performance, memory efficiency, and transparent reasoning highlights our framework's effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MACE, a multi-agent framework for claim verification from tabular data documents. It consists of three specialized agents (Planner, Executor, Verifier) that each use zero-shot Chain-of-Thought prompting rather than fine-tuning or pretraining. The framework generates interpretable verification traces. Experiments claim SOTA performance on two datasets, parity with best models on two others, and 80-100% of best performance using models of 27-92B parameters versus 235B for competing approaches.
Significance. If the performance claims hold under rigorous controls, the work would show that a lightweight multi-agent decomposition can enable substantially smaller LLMs to reach competitive accuracy on tabular claim verification while providing explicit reasoning traces, offering a practical alternative to large-model fine-tuning or complex pretraining pipelines.
major comments (3)
- [Experiments] Experimental section: The abstract and reported results claim SOTA or near-SOTA performance but supply no details on the exact baselines, dataset statistics, error analysis, or statistical significance tests. Without these, it is impossible to verify whether the data support the headline performance numbers.
- [Experiments] Experimental section: No ablation is presented that compares the three-agent MACE setup against a single-agent baseline using the identical base LLM, the same total reasoning budget, and a comparably detailed zero-shot CoT prompt. This omission leaves open the possibility that any sufficiently structured prompting on the smaller model would have produced equivalent results, undermining attribution of gains to the Planner-Executor-Verifier decomposition.
- [Methods] Methods section: The interaction protocol among the three agents, including how the Planner's strategy is passed to the Executor and how the Verifier reaches a final decision, is described at a high level only. Concrete prompt templates, termination conditions, and handling of conflicting agent outputs are not provided, impeding reproducibility.
minor comments (1)
- [Abstract] The abstract states '80--100% of best performance' without defining the reference 'best' model or the exact metric (accuracy, F1, etc.) used for the percentage calculation.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments identify important opportunities to strengthen the experimental rigor, ablation analysis, and reproducibility of the manuscript. We address each major comment below and will incorporate the necessary revisions in the next version.
read point-by-point responses
-
Referee: [Experiments] Experimental section: The abstract and reported results claim SOTA or near-SOTA performance but supply no details on the exact baselines, dataset statistics, error analysis, or statistical significance tests. Without these, it is impossible to verify whether the data support the headline performance numbers.
Authors: We agree that additional explicit details are needed to fully substantiate the performance claims. The experimental section already reports comparisons against published baselines and provides high-level dataset descriptions, but we will expand it in the revision to include: (1) a consolidated table of exact baseline models and their reported scores, (2) full dataset statistics (size, claim distribution, table characteristics), (3) a dedicated error analysis subsection categorizing failure modes, and (4) statistical significance tests (e.g., McNemar or bootstrap confidence intervals) for the reported improvements. These additions will be placed in the main experimental section or a new appendix. revision: yes
-
Referee: [Experiments] Experimental section: No ablation is presented that compares the three-agent MACE setup against a single-agent baseline using the identical base LLM, the same total reasoning budget, and a comparably detailed zero-shot CoT prompt. This omission leaves open the possibility that any sufficiently structured prompting on the smaller model would have produced equivalent results, undermining attribution of gains to the Planner-Executor-Verifier decomposition.
Authors: This is a valid concern regarding causal attribution. While the multi-agent decomposition is central to our contribution and enables the interpretable traces, we did not include a matched single-agent ablation with identical LLM, total token budget, and prompt detail. In the revised manuscript we will add this ablation study using the same base models (e.g., 27B–92B variants), ensuring the single-agent prompt incorporates an equivalent level of structured zero-shot CoT reasoning. Results will be reported alongside the main tables to quantify the incremental benefit of the three-agent protocol. revision: yes
-
Referee: [Methods] Methods section: The interaction protocol among the three agents, including how the Planner's strategy is passed to the Executor and how the Verifier reaches a final decision, is described at a high level only. Concrete prompt templates, termination conditions, and handling of conflicting agent outputs are not provided, impeding reproducibility.
Authors: We acknowledge that the current Methods description prioritizes the high-level architecture over implementation specifics. In the revision we will expand this section to provide: (1) the full zero-shot CoT prompt templates for the Planner, Executor, and Verifier (moved to an appendix if space-constrained), (2) the precise message-passing protocol (e.g., JSON-structured outputs passed between agents), (3) termination conditions (e.g., maximum rounds or consensus threshold), and (4) the conflict-resolution procedure used by the Verifier. These details will enable exact reproduction of the reported results. revision: yes
Circularity Check
No circularity: empirical results on external benchmarks with no fitted parameters or self-referential derivations
full rationale
The paper introduces MACE as a three-agent zero-shot CoT framework (Planner-Executor-Verifier) for tabular claim verification and reports performance on external datasets. No equations, fitted parameters, or predictions are defined in terms of themselves. Claims of SOTA or near-SOTA results rest on direct evaluation against held-out data rather than any reduction to inputs by construction. Self-citations, if present, are not load-bearing for the core method or results. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Zero-shot Chain-of-Thought prompting suffices for effective decomposition of tabular claim verification into planning, execution, and validation steps.
invented entities (1)
-
Planner, Executor, and Verifier agents
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InFind- ings of the Association for Computational Linguistics: NAACL 2022, pages 1–16
Pubhealthtab: A public health table-based dataset for evidence-based fact checking. InFind- ings of the Association for Computational Linguistics: NAACL 2022, pages 1–16. Si-An Chen, Lesly Miculicich, Julian Martin Eisen- schlos, Zifeng Wang, Zilong Wang, Yanfei Chen, Yasuhisa Fujii, Hsuan-Tien Lin, Chen-Yu Lee, and Tomas Pfister. 2024. Tablerag: Million-...
-
[2]
arXiv preprint arXiv:2402.14361 , year=
Opentab: Advancing large language mod- els as open-domain table reasoners.arXiv preprint arXiv:2402.14361. Qianlong Li, Chen Huang, Shuai Li, Yuanxin Xiang, Deng Xiong, and Wenqiang Lei. 2024. Graphot- ter: Evolving llm-based graph reasoning for com- plex table question answering.arXiv preprint arXiv:2412.01230. Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziya...
-
[3]
arXiv preprint arXiv:2411.02059 , year =
Okapi at trec-3.Nist Special Publication Sp, 109:109. Aofeng Su, Aowen Wang, Chao Ye, Chen Zhou, Ga Zhang, Guangcheng Zhu, Haobo Wang, Haokai Xu, Hao Chen, Haoze Li, et al. 2024. Tablegpt2: A large multimodal model with tabular data integration. arXiv preprint arXiv:2411.02059. Nancy XR Wang, Diwakar Mahajan, Marina Danilevsky, and Sara Rosenthal. 2021. S...
-
[4]
Extract "Water reused/recycled" and "Operational water use(4)" for "All Operations" (2023–2017) (rows 5 and 6of Table 1)
work page 2023
-
[5]
Compute yearly percentages and the overall percentage
-
[6]
Compare the overall percentage to 55.82%
-
[7]
Return "support" if the computed percentage is 55.82% (or very close, e.g., rounding to two decimal places), otherwise "refute." Final Verdict: The Executor will compute and return either "support" or "refute" based on the above steps. (Note: The Planner does not compute the final percentage; this is the Executor’s task.) Figure 3: Action plan, generated ...
work page 2017
-
[8]
Negation Awareness: Pay very close attention to negation words such as “not”, “no”, “without”, “fail to”, “does not”, or “cannot”. These drastically change the meaning of the claim and must be reflected in your plan. 2.Relevance: Focus only on the information in the table and caption. Do not invent data. 3.Consistency Rule: Your plan must lead to a verdic...
-
[9]
Auxiliary or unverifiable details should not force “refute” if the main claim is supported
Compound Claims: Treat the main point of the claim as decisive. Auxiliary or unverifiable details should not force “refute” if the main claim is supported
- [10]
-
[11]
Unclear Plans: If the Planner’s plan is vague or unexecutable, respond with “revise” instead of a verdict, explaining what needs clarification
-
[12]
Evidential Fairness: Terms like “large margin” or “substantial” should be judged relative to the scale of results, not by an arbitrary cutoff. Use “refute” only if the data shows systematic contradiction to the claim. Response Format: <explanation> Step-by-step reasoning here... </explanation> support/refute/not enough info OR "revise" Description: Execut...
-
[13]
Auxiliary unverifiable clauses should not override a supported main claim
Compound Claims: Do not demand perfection. Auxiliary unverifiable clauses should not override a supported main claim
-
[14]
5”). Interpret terms like “large margin
Numeric & Qualitative Terms: Accept approximate matches (e.g., 4.8 ≈ “5”). Interpret terms like “large margin” or “substantial” relative to the scale of the results, not as fixed thresholds
-
[15]
Revision Trigger: If the Executor’s verdict does not align with these definitions and guidelines, respond with “revise” and explain what should be corrected
-
[16]
Final Verdict: If Executor’s output is sound, repeat the verdict as-is. If flawed but fixable, return “revise”. Do not invent a verdict yourself beyond support/refute/not enough info. Response Format: <explanation> Your validation reasoning here... </explanation> support/refute/not enough info OR "revise" Description: Critically audits the Executor’s outp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.