Recognition: unknown
Learned Nonlocal Feature Matching and Filtering for RAW Image Denoising
Pith reviewed 2026-05-10 05:25 UTC · model grok-4.3
The pith
A neural network embeds the classical nonlocal denoising pipeline into a single learnable block per scale for RAW images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
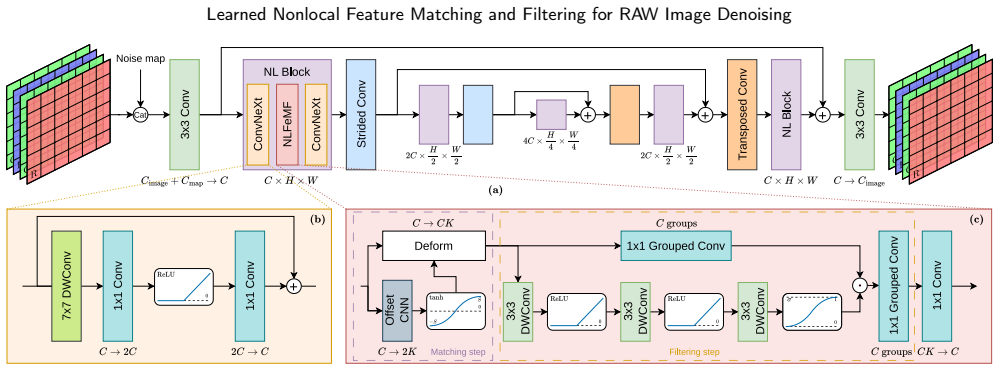
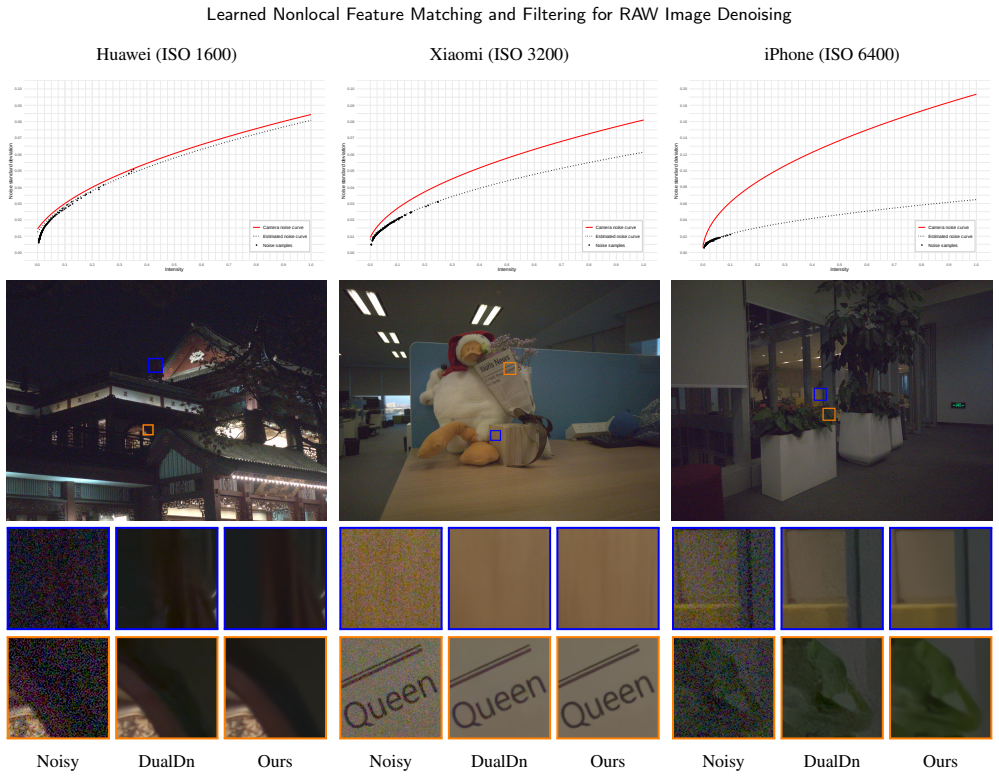
The central claim is that a novel nonlocal block operating on learned multiscale feature representations can replicate the classical pipeline of neighbor matching, collaborative filtering, and aggregation. With only one block per scale and a moderate number of neighbors, the network reaches high-quality RAW-to-RAW denoising when trained on a curated mix of real clean RAW data and modeled synthetic noise while being conditioned on a noise level map.
What carries the argument
The novel nonlocal block that performs learned neighbor matching, collaborative filtering, and aggregation on multiscale feature representations.
If this is right
- Competitive denoising quality on benchmarks and real photographs is obtained with significantly fewer parameters than state-of-the-art convolutional or transformer networks.
- A single nonlocal block per scale is sufficient because nonlocality already provides an expanded receptive field.
- The network produces a sensor-agnostic denoiser that generalizes to unseen devices.
- The architecture remains interpretable because it retains the explicit matching-filtering-aggregation structure of classical methods.
Where Pith is reading between the lines
- Similar blocks could be inserted into networks for other restoration tasks that rely on repeated patterns across an image.
- The reduction in parameter count may enable real-time RAW denoising directly on resource-limited camera hardware.
- The same matching-and-filtering logic might improve efficiency in related domains such as video denoising where temporal neighbors are available.
Load-bearing premise
A model trained on a mix of real clean RAW images and synthetic noise will handle noise statistics from any unseen camera without retraining or domain shift.
What would settle it
Measure the denoising quality of the trained model on RAW images from a new camera sensor never seen during training; if quality drops sharply relative to results on training sensors, the generalization claim fails.
Figures







read the original abstract
Being one of the oldest and most basic problems in image processing, image denoising has seen a resurgence spurred by rapid advances in deep learning. Yet, most modern denoising architectures make limited use of the technical knowledge acquired researching the classical denoisers that came before the mainstream use of neural networks, instead relying on depth and large parameter counts. This poses a challenge not only for understanding the properties of such networks, but also for deploying them on real devices which may present resource constraints and diverse noise profiles. Tackling both issues, we propose an architecture dedicated to RAW-to-RAW denoising that incorporates the interpretable structure of classical self-similarity-based denoisers into a fully learnable neural network. Our design centers on a novel nonlocal block that parallels the established pipeline of neighbor matching, collaborative filtering and aggregation popularized by nonlocal patch-based methods, operating on learned multiscale feature representations. This built-in nonlocality efficiently expands the receptive field, sufficing a single block per scale with a moderate number of neighbors to obtain high-quality results. Training the network on a curated dataset with clean real RAW data and modeled synthetic noise while conditioning it on a noise level map yields a sensor-agnostic denoiser that generalizes effectively to unseen devices. Both quantitative and visual results on benchmarks and in-the-wild photographs position our method as a practical and interpretable solution for real-world RAW denoising, achieving results competitive with state-of-the-art convolutional and transformer-based denoisers while using significantly fewer parameters. The code is available at https://github.com/MIA-UIB/nonlocal-matchfilter .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a neural network architecture for RAW-to-RAW image denoising that embeds a novel learned nonlocal block, which replicates the classical nonlocal pipeline of neighbor matching, collaborative filtering, and aggregation but operates on learned multiscale feature representations. A single such block per scale with a moderate number of neighbors is claimed to suffice for high-quality results. The network is trained on a curated mix of real clean RAW data and modeled synthetic noise, conditioned only on a noise level map, yielding a sensor-agnostic model asserted to generalize to unseen devices. Quantitative and visual results on benchmarks and in-the-wild photos are reported as competitive with state-of-the-art CNN and transformer denoisers while using significantly fewer parameters; code is released.
Significance. If the empirical claims hold, the work is significant for demonstrating how to incorporate interpretable classical nonlocal structures into compact, learnable networks, addressing both performance and deployment constraints for real-device RAW denoising across diverse sensors. The parameter efficiency and code release are concrete strengths that could facilitate practical adoption and further research.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The central claim that training on real clean RAW plus modeled synthetic noise conditioned on a noise level map produces a truly sensor-agnostic denoiser generalizing to unseen devices is load-bearing for the practical advantage, yet no held-out sensor tests, device-specific domain-shift metrics, or ablations on noise-model fidelity are described; real RAW noise contains sensor-specific components (spatially correlated read noise, CFA patterns) that generic synthetic models often fail to capture exactly.
- [Abstract and Table 1] Abstract and Table 1 (or equivalent quantitative table): Competitive performance is asserted without error bars, statistical significance tests, or full ablation tables on the nonlocal block components (number of neighbors, multiscale feature scales), making it impossible to verify whether the reported PSNR/SSIM gains are robust or merely within noise of the baselines.
minor comments (2)
- [§3] Notation for the learned nonlocal block (e.g., definitions of matching, filtering, and aggregation operators) should be introduced with explicit equations in §3 to improve traceability to the classical BM3D-style pipeline.
- [Abstract] The abstract states 'significantly fewer parameters' but does not quantify the parameter count relative to the cited SOTA methods; a direct comparison table would clarify this advantage.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claim that training on real clean RAW plus modeled synthetic noise conditioned on a noise level map produces a truly sensor-agnostic denoiser generalizing to unseen devices is load-bearing for the practical advantage, yet no held-out sensor tests, device-specific domain-shift metrics, or ablations on noise-model fidelity are described; real RAW noise contains sensor-specific components (spatially correlated read noise, CFA patterns) that generic synthetic models often fail to capture exactly.
Authors: We agree that dedicated held-out sensor experiments with explicit domain-shift metrics would provide stronger evidence for the sensor-agnostic claim. Our evaluations already include quantitative results on standard benchmarks drawn from multiple camera sensors as well as qualitative results on in-the-wild RAW photographs captured by devices absent from the training set; these serve as de-facto generalization tests. The inclusion of real clean RAW patches from diverse sources during training, combined with conditioning on a noise-level map, is intended to promote robustness across sensors. Nevertheless, we acknowledge that synthetic noise models cannot fully replicate all sensor-specific effects such as spatially correlated read noise or CFA-dependent patterns. In the revised manuscript we will expand §4 with a dedicated paragraph discussing noise-model limitations, explicitly noting the lack of isolated held-out-sensor ablations as a limitation, and outlining directions for future validation. This constitutes a partial revision. revision: partial
-
Referee: [Abstract and Table 1] Abstract and Table 1 (or equivalent quantitative table): Competitive performance is asserted without error bars, statistical significance tests, or full ablation tables on the nonlocal block components (number of neighbors, multiscale feature scales), making it impossible to verify whether the reported PSNR/SSIM gains are robust or merely within noise of the baselines.
Authors: We accept that the absence of error bars, significance testing, and exhaustive ablations on the nonlocal block hyperparameters limits the ability to assess robustness. We will recompute the main quantitative table with standard deviations obtained from multiple independent training runs (where compute permits) and add paired statistical significance tests (e.g., Wilcoxon signed-rank) between our method and the strongest baselines. In addition, we will insert a new ablation subsection in §4 that systematically varies the number of neighbors and the choice of multiscale feature resolutions, reporting the corresponding PSNR/SSIM changes. These updates will be included in the revised version. revision: yes
Circularity Check
No circularity: empirical performance from supervised training on external data
full rationale
The paper proposes a neural network with a learned nonlocal block inspired by classical patch-based methods, trains it end-to-end on a mix of real clean RAW images and synthetic noise (conditioned on a noise map), and reports competitive PSNR/visual results on benchmarks. No equation, prediction, or first-principles claim reduces to a fitted parameter or self-citation by construction. The architecture choice and generalization statement are design decisions validated empirically, not tautological redefinitions of inputs. Self-citations to nonlocal means literature are to independent prior work and not load-bearing for the reported metrics.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of neighbors per block
- network weights
axioms (1)
- domain assumption Synthetic noise model plus real clean RAW data sufficiently approximates real sensor noise distributions for unseen devices
invented entities (1)
-
Learned nonlocal block
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Yaroslavsky, Leonid P. , title =. 1985 , isbn =. doi:10.5555/536657 , pages =
-
[2]
A feature based correspondence algorithm for image matching , year =
F. A feature based correspondence algorithm for image matching , year =. Proceedings of the ISPRS Commission III Symposium, Part 3 , series =
-
[3]
and Westin, C.-F
Knutsson, H. and Westin, C.-F. , booktitle=. Normalized and differential convolution , year=
-
[4]
Smith, Stephen M. and Brady, J. Michael , title =. 1997 , issue_date =. doi:10.1023/A:1007963824710 , journal =
-
[5]
and Kimmel, R
Sochen, N. and Kimmel, R. and Malladi, R. , journal=. A general framework for low level vision , year=
-
[6]
2020 , volume =
Buades, Antoni and Duran, Joan , journal =. 2020 , volume =
2020
-
[7]
and Buades, A
Sánchez-Beeckman, M. and Buades, A. and Brandonisio, N. and Kanoun, B. , journal=. Combining Pre- and Post-Demosaicking Noise Removal for. 2026 , volume=
2026
-
[8]
Pseudo four-channel image denoising for noisy
Akiyama, Hiroki and Tanaka, Masayuki and Okutomi, Masatoshi , booktitle=. Pseudo four-channel image denoising for noisy. 2015 , volume=
2015
-
[9]
SIAM Journal on Imaging Sciences , volume =
Facciolo, Gabriele and Pierazzo, Nicola and Morel, Jean-Michel , title =. SIAM Journal on Imaging Sciences , volume =. 2017 , doi =
2017
-
[10]
Improving Denoising Algorithms via a Multi-scale Meta-procedure , booktitle=
Burger, Harold Christopher and Harmeling, Stefan , editor=. Improving Denoising Algorithms via a Multi-scale Meta-procedure , booktitle=. 2011 , publisher=
2011
-
[11]
Medical Image Computing and Computer-Assisted Intervention (MICCAI) , year=
Ronneberger, Olaf and Fischer, Philipp and Brox, Thomas , editor=. Medical Image Computing and Computer-Assisted Intervention (MICCAI) , year=
-
[12]
Deep Residual Learning for Image Recognition , year=
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , booktitle=. Deep Residual Learning for Image Recognition , year=
-
[13]
How to best combine demosaicing and denoising? , journal =. 2023 , issn =. doi:10.3934/ipi.2023044 , author =
-
[14]
A Review of an Old Dilemma: Demosaicking First, or Denoising First? , year =
Jin, Qiyu and Facciolo, Gabriele and Morel, Jean-Michel , booktitle =. A Review of an Old Dilemma: Demosaicking First, or Denoising First? , year =
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Self-supervision versus synthetic datasets: which is the lesser evil in the context of video denoising? , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[16]
ACM SIGGRAPH 2005 Papers , pages =
Video enhancement using per-pixel virtual exposures , author =. ACM SIGGRAPH 2005 Papers , pages =
2005
-
[17]
Proceedings of the 29th annual conference on Computer graphics and interactive techniques , pages =
Fast bilateral filtering for the display of high-dynamic-range images , author =. Proceedings of the 29th annual conference on Computer graphics and interactive techniques , pages =
-
[18]
Proceedings of the European Conference on Computer Vision (ECCV) , pages =
A high-quality video denoising algorithm based on reliable motion estimation , author =. Proceedings of the European Conference on Computer Vision (ECCV) , pages =. 2010 , organization =
2010
-
[19]
IEEE International Conference on Image Processing , pages =
A new approach for very dark video denoising and enhancement , author =. IEEE International Conference on Image Processing , pages =. 2010 , organization =
2010
-
[20]
Visual Communications and Image Processing , pages =
Video denoising algorithm via multi-scale joint luma-chroma bilateral filter , author =. Visual Communications and Image Processing , pages =. 2015 , organization =
2015
-
[21]
Image Processing: Algorithms and Systems XIII , volume =
Multiview image sequence enhancement , author =. Image Processing: Algorithms and Systems XIII , volume =. 2015 , organization =
2015
-
[22]
IEEE Transactions on Circuits and Systems for Video Technology , volume =
Enhancement of noisy and compressed videos by optical flow and non-local denoising , author =. IEEE Transactions on Circuits and Systems for Video Technology , volume =. 2019 , publisher =
2019
-
[23]
IEEE Transactions on Image Processing , title=
Buades, Antoni and Lisani, Jos. IEEE Transactions on Image Processing , title=. 2016 , volume=
2016
-
[24]
SIAM Journal on Imaging Sciences , volume =
Photographing paintings by image fusion , author =. SIAM Journal on Imaging Sciences , volume =. 2012 , publisher =
2012
-
[25]
ACM Transactions on Graphics , volume =
Fast burst images denoising , author =. ACM Transactions on Graphics , volume =. 2014 , publisher =
2014
-
[26]
Bilateral filtering for gray and color images , year=
Tomasi, Carlo and Manduchi, Roberto , booktitle=. Bilateral filtering for gray and color images , year=
-
[27]
A non-local algorithm for image denoising , year=
Buades, Antoni and Coll, Bartomeu and Morel, Jean-Michel , booktitle=. A non-local algorithm for image denoising , year=
-
[28]
Image Denoising by Sparse
Dabov, Kostadin and Foi, Alessandro and Katkovnik, Vladimir and Egiazarian, Karen , journal=. Image Denoising by Sparse. 2007 , volume=
2007
-
[29]
A nonlocal
Lebrun, Marc and Buades, Antoni and Morel, Jean-Michel , journal =. A nonlocal. 2013 , publisher =
2013
-
[30]
Multiscale Image Blind Denoising , year=
Lebrun, Marc and Colom, Miguel and Morel, Jean-Michel , journal=. Multiscale Image Blind Denoising , year=
-
[31]
A ConvNet for the 2020s , year=
Liu, Zhuang and Mao, Hanzi and Wu, Chao-Yuan and Feichtenhofer, Christoph and Darrell, Trevor and Xie, Saining , booktitle=. A ConvNet for the 2020s , year=
-
[32]
Video denoising using separable
Maggioni, Matteo and Boracchi, Giacomo and Foi, Alessandro and Egiazarian, Karen , booktitle =. Video denoising using separable. 2011 , organization =
2011
-
[33]
IEEE Transactions on Image Processing , title=
Kervrann, Charles and Boulanger, J. IEEE Transactions on Image Processing , title=. 2006 , volume=
2006
-
[34]
Kernel Regression for Image Processing and Reconstruction , year=
Takeda, Hiroyuki and Farsiu, Sina and Milanfar, Peyman , journal=. Kernel Regression for Image Processing and Reconstruction , year=
-
[35]
IEEE transactions on pattern analysis and machine intelligence , volume =
Space-time adaptation for patch-based image sequence restoration , author =. IEEE transactions on pattern analysis and machine intelligence , volume =. 2007 , publisher =
2007
-
[36]
Video denoising by sparse 3D transform-domain collaborative filtering [C] , author =. Proc. 15th European Signal Processing Conference , volume =
-
[37]
Advanced Concepts for Intelligent Vision Systems: 16th International Conference, ACIVS 2015, Catania, Italy, October 26-29, 2015
Towards a bayesian video denoising method , author =. Advanced Concepts for Intelligent Vision Systems: 16th International Conference, ACIVS 2015, Catania, Italy, October 26-29, 2015. Proceedings 16 , pages =. 2015 , organization =
2015
-
[38]
Journal of Mathematical Imaging and Vision , volume =
Video denoising via empirical bayesian estimation of space-time patches , author =. Journal of Mathematical Imaging and Vision , volume =. 2017 , publisher =
2017
-
[39]
Expert Systems with Applications , volume =
Color video denoising using epitome and sparse coding , author =. Expert Systems with Applications , volume =. 2015 , publisher =
2015
-
[40]
Multiscale Modeling & Simulation , volume =
Learning multiscale sparse representations for image and video restoration , author =. Multiscale Modeling & Simulation , volume =. 2008 , publisher =
2008
-
[41]
IEEE transactions on Image Processing , volume =
Image sequence denoising via sparse and redundant representations , author =. IEEE transactions on Image Processing , volume =. 2008 , publisher =
2008
-
[42]
IEEE International Conference on Image Processing , pages =
Video denoising by online 3D sparsifying transform learning , author =. IEEE International Conference on Image Processing , pages =. 2015 , organization =
2015
-
[43]
SIAM Journal on Imaging Sciences , volume =
Robust video restoration by joint sparse and low rank matrix approximation , author =. SIAM Journal on Imaging Sciences , volume =. 2011 , publisher =
2011
-
[44]
IEEE Computer Society Conference on Computer Vision and Pattern Recognition , pages =
Robust video denoising using low rank matrix completion , author =. IEEE Computer Society Conference on Computer Vision and Pattern Recognition , pages =. 2010 , organization =
2010
-
[45]
Signal processing , volume =
Generalized multihypothesis motion compensated filter for grayscale and color video denoising , author =. Signal processing , volume =. 2013 , publisher =
2013
-
[46]
IEEE Transactions on Image Processing , volume =
Image denoising by exploring external and internal correlations , author =. IEEE Transactions on Image Processing , volume =. 2015 , publisher =
2015
-
[47]
2019 , organization =
Tassano, Matias and Delon, Julie and Veit, Thomas , booktitle =. 2019 , organization =
2019
-
[48]
A non-local
Davy, Axel and Ehret, Thibaud and Morel, Jean-Michel and Arias, Pablo and Facciolo, Gabriele , booktitle =. A non-local. 2019 , organization =
2019
-
[49]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
Patch craft: Video denoising by deep modeling and patch matching , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
-
[50]
SIAM Journal on Imaging Sciences , volume =
Elad, Michael and Kawar, Bahjat and Vaksman, Gregory , title =. SIAM Journal on Imaging Sciences , volume =. 2023 , doi =
2023
-
[51]
and Bouman, Charles A
Venkatakrishnan, Singanallur V. and Bouman, Charles A. and Wohlberg, Brendt , booktitle=. Plug-and-Play priors for model based reconstruction , year=
-
[52]
SIAM Journal on Imaging Sciences , volume =
Romano, Yaniv and Elad, Michael and Milanfar, Peyman , title =. SIAM Journal on Imaging Sciences , volume =. 2017 , doi =
2017
-
[53]
Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume =
Milanfar, Peyman and Delbracio, Mauricio , title =. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume =. 2025 , doi =
2025
-
[54]
A Tour of Modern Image Filtering: New Insights and Methods, Both Practical and Theoretical , year=
Milanfar, Peyman , journal=. A Tour of Modern Image Filtering: New Insights and Methods, Both Practical and Theoretical , year=
-
[55]
Tassano, Matias and Delon, Julie and Veit, Thomas , booktitle =. Fast
-
[56]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages =
Self-supervised training for blind multi-frame video denoising , author =. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages =
-
[57]
Low-light Raw Video Denoising with a High-quality Realistic Motion Dataset , year =
Fu, Ying and Wang, Zichun and Zhang, Tao and Zhang, Jun , journal =. Low-light Raw Video Denoising with a High-quality Realistic Motion Dataset , year =
-
[58]
International journal of computer vision , volume =
Nonlocal image and movie denoising , author =. International journal of computer vision , volume =. 2008 , publisher =
2008
-
[59]
Video denoising using motion compensated
Yu, Shigong and Ahmad, M Omair and Swamy, MNS , journal =. Video denoising using motion compensated. 2010 , publisher =
2010
-
[60]
IEEE transactions on circuits and systems for video technology , volume =
Video denoising based on a spatiotemporal Gaussian scale mixture model , author =. IEEE transactions on circuits and systems for video technology , volume =. 2010 , publisher =
2010
-
[61]
IEEE International Conference on Image Processing , pages =
Real-time video denoising on mobile phones , author =. IEEE International Conference on Image Processing , pages =. 2018 , organization =
2018
-
[62]
Applications of Digital Image Processing XXXIX , editor =
Xinyuan Chen and Li Song and Xiaokang Yang , title =. Applications of Digital Image Processing XXXIX , editor =. 2016 , doi =
2016
-
[63]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , year =
Clause, Michele and van Gemert, Jan , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , year =
-
[64]
International Journal of Computer Vision , volume =
Video Enhancement with Task-Oriented Flow , author =. International Journal of Computer Vision , volume =. 2019 , doi =
2019
-
[65]
Unidirectional Video Denoising by Mimicking Backward Recurrent Modules with Look-Ahead Forward Ones , booktitle =
Li, Junyi and Wu, Xiaohe and Niu, Zhenxing and Zuo, Wangmeng , editor =. Unidirectional Video Denoising by Mimicking Backward Recurrent Modules with Look-Ahead Forward Ones , booktitle =. 2022 , publisher =
2022
-
[66]
ACM MM , year =
Real-time Streaming Video Denoising with Bidirectional Buffers , author =. ACM MM , year =
-
[67]
International Journal of Computer Vision , volume =
Efficient Burst Raw Denoising with Variance Stabilization and Multi-frequency Denoising Network , author =. International Journal of Computer Vision , volume =. 2022 , doi =
2022
-
[68]
Song, Mingyang and Zhang, Yang and Ayd. Temp. 2022 , publisher =. doi:10.1007/978-3-031-19800-7_28 , booktitle =
-
[69]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Li, Dasong and Shi, Xiaoyu and Zhang, Yi and Cheung, Ka Chun and See, Simon and Wang, Xiaogang and Qin, Hongwei and Li, Hongsheng , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[70]
2017 , volume=
Agustsson, Eirikur and Timofte, Radu , booktitle=. 2017 , volume=
2017
-
[71]
Waterloo Exploration Database: New Challenges for Image Quality Assessment Models , year=
Ma, Kede and Duanmu, Zhengfang and Wu, Qingbo and Wang, Zhou and Yong, Hongwei and Li, Hongliang and Zhang, Lei , journal=. Waterloo Exploration Database: New Challenges for Image Quality Assessment Models , year=
-
[72]
Enhanced Deep Residual Networks for Single Image Super-Resolution , year=
Lim, Bee and Son, Sanghyun and Kim, Heewon and Nah, Seungjun and Lee, Kyoung Mu , booktitle=. Enhanced Deep Residual Networks for Single Image Super-Resolution , year=
-
[73]
Pre-Trained Image Processing Transformer , year=
Chen, Hanting and Wang, Yunhe and Guo, Tianyu and Xu, Chang and Deng, Yiping and Liu, Zhenhua and Ma, Siwei and Xu, Chunjing and Xu, Chao and Gao, Wen , booktitle=. Pre-Trained Image Processing Transformer , year=
-
[74]
2022 , volume=
Yin, Haitao and Ma, Siyuan , journal=. 2022 , volume=
2022
-
[75]
Neural Networks , volume =. 2024 , issn =. doi:10.1016/j.neunet.2024.106378 , author =
-
[76]
Zhou, Yubo and Lin, Jin and Ye, Fangchen and Qu, Yanyun and Xie, Yuan , title =. 2024 , isbn =. doi:10.1609/aaai.v38i7.28604 , booktitle =
-
[77]
Single image denoising with a feature-enhanced network , journal =. 2023 , issn =. doi:10.1016/j.neunet.2023.08.056 , author =
-
[78]
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows , year=
Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining , booktitle=. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows , year=
-
[79]
2021 , volume=
Liang, Jingyun and Cao, Jiezhang and Sun, Guolei and Zhang, Kai and Van Gool, Luc and Timofte, Radu , booktitle=. 2021 , volume=
2021
-
[80]
Uformer: A General
Wang, Zhendong and Cun, Xiaodong and Bao, Jianmin and Zhou, Wengang and Liu, Jianzhuang and Li, Houqiang , booktitle=. Uformer: A General. 2022 , volume=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.