Recognition: unknown
Mira-Embeddings-V1: Domain-Adapted Semantic Reranking for Recruitment via LLM-Synthesized Data
Pith reviewed 2026-05-10 04:37 UTC · model grok-4.3
The pith
Adapting embeddings with LLM-synthesized recruitment data improves candidate reranking performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
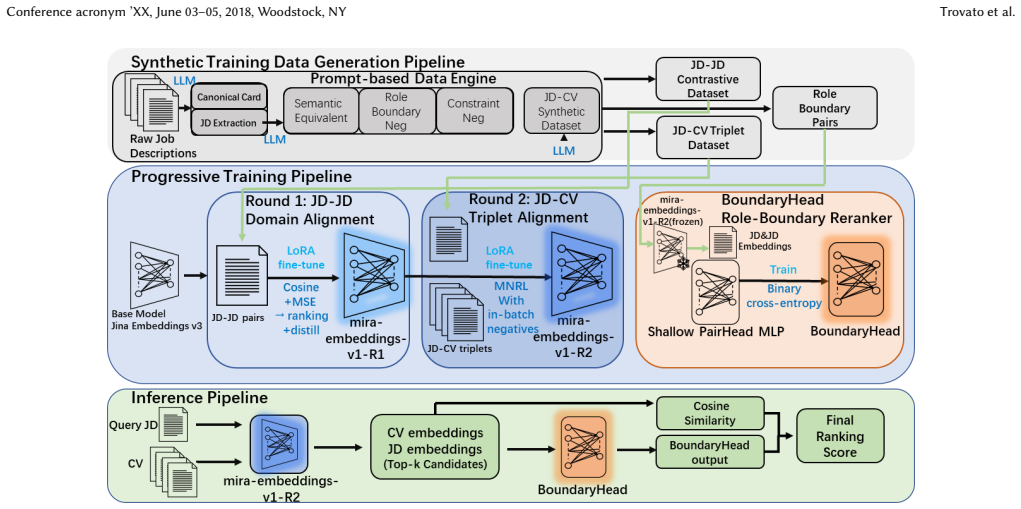
We present mira-embeddings-v1, a semantic reranking system for recruitment that starts from real job descriptions and builds a five-stage prompt pipeline to synthesize diverse positive and hard negative samples. This data enables two-round LoRA adaptation consisting of JD-JD contrastive training followed by JD-CV triplet alignment on heterogeneous text. A BoundaryHead MLP reranks the top-K candidates to distinguish roles sharing titles but differing in scope. On local pools of 300 real JDs the system raises Recall@50 from 68.89 percent to 77.55 percent and Precision@10 from 35.77 percent to 39.62 percent, with similar gains on a global pool of over 44,000 candidates.
What carries the argument
Five-stage LLM prompt pipeline for generating positive and hard-negative samples, combined with two-round LoRA adaptation and BoundaryHead MLP for boundary correction.
If this is right
- Recruiters can identify more qualified candidates within their limited review budgets.
- The approach integrates with existing production retrievers rather than requiring a full system replacement.
- Roles with similar titles but different responsibilities become easier to distinguish in rankings.
- Modest numbers of real job descriptions can be expanded into effective training data through synthesis.
- Performance improvements are shown across both small local evaluation pools and larger global candidate sets.
Where Pith is reading between the lines
- Techniques like this could be adapted for other domains requiring semantic matching with limited labeled data, such as legal contract review or academic collaboration matching.
- The use of a separate lightweight head for boundary cases indicates that hybrid embedding-plus-classifier approaches may offer advantages in precision-sensitive tasks.
- Future work might explore whether smaller or open-source language models can perform the synthesis step with comparable effectiveness.
- Testing the method on data from different industries could reveal how domain-specific the synthesized semantics need to be.
Load-bearing premise
The positive and hard-negative samples produced by the five-stage LLM prompt pipeline accurately represent real recruitment matching patterns, and the metric gains result from the adaptation process rather than from biases in the synthesis or evaluation methods.
What would settle it
Evaluating the mira-embeddings-v1 on a fresh collection of real job descriptions paired with human-judged candidate qualifications, collected independently of the LLM used for synthesis and the Qwen3-32B rubric, to verify if the recall and precision improvements remain consistent.
Figures

read the original abstract
Candidate sourcing for recruiters is best viewed as a two-stage retrieval and reranking pipeline with recall as the primary objective under a limited review budget. An upstream production retriever first returns a candidate shortlist for each job description (JD), and our goal is to rerank that shortlist so that qualified candidates appear as high as possible. We present mira-embeddings-v1, a semantic reranking system for the recruitment domain that reshapes the embedding space with LLM-synthesized training data and corrects boundary confusions with a lightweight reranking head. Starting from real JDs, we build a five-stage prompt pipeline to generate diverse positive and hard negative samples that sculpt the semantic space from multiple angles. We then apply a two-round LoRA adaptation: JD--JD contrastive training followed by JD--CV triplet alignment on a heterogeneous text dataset. Importantly, these gains require no large-scale manually labeled industrial training pairs: a modest set of real JDs is expanded into supervision through LLM synthesis. Finally, a BoundaryHead MLP reranks the Top-K results to distinguish between roles that share the same title but differ in scope. On a local pool of 300 real JDs with candidates from an upstream production retriever, mira-embeddings-v1 improves Recall@50 from 68.89% (baseline) to 77.55% while lifting Precision@10 from 35.77% to 39.62%. On a supportive global pool over 44,138 candidates judged by a Qwen3-32B rubric, it achieves Recall@200 of 0.7047 versus 0.5969 for the baseline. These results show that LLM-synthesized supervision with boundary-aware reranking yields robust gains without a heavy cross-encoder.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents mira-embeddings-v1, a semantic reranking model for recruitment that starts from real job descriptions (JDs), uses a five-stage LLM prompt pipeline to synthesize diverse positives and hard negatives, performs two-round LoRA adaptation (JD-JD contrastive followed by JD-CV triplet alignment), and adds a lightweight BoundaryHead MLP to resolve boundary confusions between similar-titled roles. The central empirical claim is that this yields concrete gains without large-scale manual labels: on a local pool of 300 real JDs with upstream-retriever candidates, Recall@50 rises from 68.89% (baseline) to 77.55% and Precision@10 from 35.77% to 39.62%; on a global pool of 44,138 candidates, Recall@200 improves from 0.5969 to 0.7047 under Qwen3-32B rubric judgments.
Significance. If the metric lifts are shown to be robust and independent of LLM-mediated artifacts, the work provides a practical demonstration that modest real-JD seeds can be expanded via synthesis into effective supervision for domain-adapted embeddings in a production retrieval-reranking pipeline. The explicit use of real JDs as starting points and the addition of the BoundaryHead for scope disambiguation are constructive elements that could reduce reliance on expensive human annotation in HR-tech applications.
major comments (4)
- [Experiments] Local-pool evaluation (described in the Experiments section): the manuscript reports Recall@50 and Precision@10 lifts on 300 real JDs but provides no description of how ground-truth qualified candidates were obtained or labeled, leaving open the possibility that these labels share construction biases with the five-stage synthesis pipeline and thereby weakening the claim that gains reflect true semantic improvement on recruiter judgments.
- [Experiments] Global-pool results (Experiments section): Recall@200 is reported against a Qwen3-32B rubric on 44,138 candidates with no inter-rater agreement statistics, no human validation subset, and no comparison of the synthesis LLM family to the judge model; this setup risks circularity that could inflate the 0.7047 vs 0.5969 lift without confirming generalization beyond LLM stylistic preferences.
- [Method and Experiments] Method and Experiments sections: no ablation studies isolate the contribution of the five-stage pipeline stages, the two-round LoRA schedule, or the BoundaryHead MLP depth; without these, the observed metric improvements cannot be confidently attributed to the proposed adaptation rather than data scale or other uncontrolled factors.
- [Experiments] All reported metrics (local and global pools): the manuscript supplies point estimates without error bars, bootstrap intervals, or statistical significance tests, so it is impossible to determine whether the lifts (e.g., +8.66 pp Recall@50) exceed what would be expected from sampling variance alone.
minor comments (2)
- [Method] The abstract and method description do not specify the exact LLM family, temperature, or full prompt templates used in the five-stage synthesis pipeline, which would aid reproducibility even if the central claim does not depend on them.
- [Method] Notation for the BoundaryHead MLP (depth, hidden size, activation) is introduced without an equation or diagram, making the lightweight reranking head harder to implement from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have reviewed each major comment carefully and provide point-by-point responses below. Where revisions are warranted, we commit to incorporating them in the next version to improve clarity, rigor, and attribution of results.
read point-by-point responses
-
Referee: [Experiments] Local-pool evaluation (described in the Experiments section): the manuscript reports Recall@50 and Precision@10 lifts on 300 real JDs but provides no description of how ground-truth qualified candidates were obtained or labeled, leaving open the possibility that these labels share construction biases with the five-stage synthesis pipeline and thereby weakening the claim that gains reflect true semantic improvement on recruiter judgments.
Authors: We acknowledge that the current manuscript does not describe the ground-truth labeling process for the local pool. In the revised version, we will add a dedicated paragraph in the Experiments section explaining that labels were assigned by a team of five senior recruiters following a standardized qualification rubric developed independently of the LLM synthesis pipeline. While complete semantic independence is difficult in a specialized domain, this addition will clarify the procedural separation and reduce concerns about shared construction biases. revision: yes
-
Referee: [Experiments] Global-pool results (Experiments section): Recall@200 is reported against a Qwen3-32B rubric on 44,138 candidates with no inter-rater agreement statistics, no human validation subset, and no comparison of the synthesis LLM family to the judge model; this setup risks circularity that could inflate the 0.7047 vs 0.5969 lift without confirming generalization beyond LLM stylistic preferences.
Authors: We agree this evaluation setup requires stronger validation. In revision we will (1) explicitly state that the synthesis pipeline primarily used Claude-3.5-Sonnet while judgments used Qwen3-32B, (2) add inter-rater agreement statistics by obtaining human labels on a random subset of 200 candidates and reporting Cohen's kappa against the LLM judge, and (3) include a short discussion of potential stylistic biases and how the two-round adaptation mitigates them. Full human labeling of the entire 44k pool remains impractical, but the added subset and model disclosure will address the core circularity concern. revision: partial
-
Referee: [Method and Experiments] Method and Experiments sections: no ablation studies isolate the contribution of the five-stage pipeline stages, the two-round LoRA schedule, or the BoundaryHead MLP depth; without these, the observed metric improvements cannot be confidently attributed to the proposed adaptation rather than data scale or other uncontrolled factors.
Authors: We concur that ablations are essential for causal attribution. We will add a new Ablations subsection reporting three controlled variants: (i) simplified single-stage synthesis instead of the five-stage pipeline, (ii) single-round LoRA instead of the two-round JD-JD then JD-CV schedule, and (iii) embedding similarity only without the BoundaryHead MLP. These results will quantify the incremental contribution of each component to the reported Recall@50 and Recall@200 lifts. revision: yes
-
Referee: [Experiments] All reported metrics (local and global pools): the manuscript supplies point estimates without error bars, bootstrap intervals, or statistical significance tests, so it is impossible to determine whether the lifts (e.g., +8.66 pp Recall@50) exceed what would be expected from sampling variance alone.
Authors: We accept this limitation. In the revised manuscript we will augment all metric tables with 95% bootstrap confidence intervals (1,000 resamples) for both local and global pools. For the local pool we will additionally report p-values from a paired Wilcoxon signed-rank test comparing mira-embeddings-v1 against the baseline on the same 300 JDs. These statistical measures will allow readers to assess whether the observed improvements exceed sampling variability. revision: yes
Circularity Check
No circularity: empirical gains measured on independent real-JD pools
full rationale
The paper reports metric improvements (Recall@50, Precision@10, Recall@200) from LoRA adaptation on LLM-synthesized positives/hard-negatives derived from real JDs, followed by a BoundaryHead MLP. These are direct empirical comparisons against an unspecified baseline on a local pool of 300 real JDs and a global pool of 44k candidates. No equations, self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation chain; the synthesis and evaluation steps use external LLMs but do not reduce the reported gains to the inputs by construction. The central claim remains a measured outcome on held-out real data rather than a tautology.
Axiom & Free-Parameter Ledger
free parameters (2)
- LoRA rank, alpha, and learning-rate schedule
- BoundaryHead MLP depth and hidden size
axioms (2)
- domain assumption LLM synthesis via five-stage prompts produces diverse, high-quality positive and hard-negative recruitment pairs
- standard math Contrastive and triplet losses on the synthesized pairs improve semantic alignment for downstream reranking
Reference graph
Works this paper leans on
-
[1]
Shuqing Bian, Xu Zhao, Biao Chang, Kaimin Zhou, Sheng Wen, and Weidong Xiao. 2019. Domain Adaptation for Person-Job Fit with Transferable Deep Global Match Network. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 4809–4819. do...
-
[2]
Shuqing Bian, Xu Zhao, Biao Chang, Kaimin Zhou, Sheng Wen, and Weidong Xiao. 2020. Learning to Match Jobs with Resumes from Sparse Interaction Data using Multi-View Co-Teaching Network. InProceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM). 65–74. doi:10.1145/3340531.3411929
-
[3]
Luiz Bonifacio, Hugo Abonizio, Marzieh Fadaee, and Rodrigo Nogueira. 2022. InPars: Unsupervised Dataset Generation for Information Retrieval. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2387–2392. doi:10.1145/3477495.3531863
-
[4]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi- Granularity Text Embeddings Through Self-Knowledge Distillation.arXiv preprint arXiv:2402.03216(2024)
work page internal anchor Pith review arXiv 2024
-
[5]
Zhao, Ji Ma, Yi Luan, Jianmo Ni, Jing Lu, Anton Bakalov, Kelvin Guu, Keith B
Zhuyun Dai, Vincent Y. Zhao, Ji Ma, Yi Luan, Jianmo Ni, Jing Lu, Anton Bakalov, Kelvin Guu, Keith B. Hall, and Ming-Wei Chang. 2023. Promptagator: Few- shot Dense Retrieval From 8 Examples. InThe Eleventh International Confer- ence on Learning Representations (ICLR). https://openreview.net/forum?id= gmL46YMpu2J
2023
-
[6]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. QLoRA: Efficient Finetuning of Quantized Large Language Models. InAdvances in Neural Information Processing Systems 36 (NeurIPS)
2023
-
[7]
Yuan Fang, Lizi Liao, Zhiyuan Zhao, Dou Shen, Min Zhang, and Tat-Seng Chua. 2023. RecruitPro: A Pretrained Language Model with Skill-Aware Prompt Learning for Intelligent Recruitment. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). 3991–4002. doi:10.1145/3580305.3599894
-
[8]
Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. 2023. Precise Zero-Shot Dense Retrieval without Relevance Labels. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL). 1762–1777. doi:10. 18653/v1/2023.acl-long.99
2023
-
[9]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models.arXiv preprint arXiv:2106.09685(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bo- janowski, Armand Joulin, and Edouard Grave. 2022. Unsupervised Dense Infor- mation Retrieval with Contrastive Learning.Transactions on Machine Learning Research(2022). https://openreview.net/forum?id=jKN1pXi7b0
2022
- [11]
-
[12]
Chen Jiang, Hengshu Zhu, Wei Cheng, Tong Xu, Enhong Chen, Hui Xiong, and Le Liu. 2020. Learning Effective Representations for Person-Job Fit by Feature Fusion. InProceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM). 3005–3012. doi:10.1145/3340531.3412793
-
[14]
Omar Khattab and Matei Zaharia. 2020. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 39–48. doi:10.1145/3397271.3401075
-
[15]
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. 2023. Towards General Text Embeddings with Multi-stage Contrastive Learning.arXiv preprint arXiv:2308.03281(2023)
work page internal anchor Pith review arXiv 2023
-
[16]
Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models , url =
Jianmo Ni, Gustavo Hernández Ábrego, Noah Constant, Ji Ma, Keith B. Hall, Daniel Cer, and Yinfei Yang. 2022. Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models. InFindings of the Association for Computational Linguistics: ACL 2022. 1864–1874. doi:10.18653/v1/2022.findings-acl.146
-
[17]
Rodrigo Nogueira and Kyunghyun Cho. 2019. Passage Re-ranking with BERT. arXiv preprint arXiv:1901.04085(2019)
work page internal anchor Pith review arXiv 2019
-
[18]
Rodrigo Nogueira, Zhiying Jiang, Ronak Pradeep, and Jimmy Lin. 2020. Docu- ment Ranking with a Pretrained Sequence-to-Sequence Model. InFindings of the Association for Computational Linguistics: EMNLP 2020. 708–718. doi:10.18653/ v1/2020.findings-emnlp.63
2020
- [19]
-
[20]
Chuan Qin, Hengshu Zhu, Tong Xu, Chen Zhu, Liang Jiang, Enhong Chen, and Hui Xiong. 2018. Enhancing Person-Job Fit for Talent Recruitment: An Ability- aware Neural Network Approach. InProceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval. 25–34. doi:10.1145/3209978.3210025
-
[21]
Chuan Qin, Hengshu Zhu, Tong Xu, Chen Zhu, Chao Ma, Enhong Chen, and Hui Xiong. 2020. An Enhanced Neural Network Approach to Person-Job Fit in Talent Recruitment.ACM Transactions on Information Systems38, 2 (2020), 1–33. doi:10.1145/3376927
-
[22]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 3982–3992. doi:10.18653/v1/ D19-1410
-
[23]
Dazhong Shen, Hengshu Zhu, Chen Zhu, Tong Xu, Chao Ma, and Hui Xiong
-
[24]
A Joint Learning Approach to Intelligent Job Interview Assessment. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI). 3542–3548. doi:10.24963/ijcai.2018/492
- [25]
-
[26]
In: Vlachos, A., Augen- stein, I
Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A. Smith, Luke Zettlemoyer, and Tao Yu. 2023. One Embedder, Any Task: Instruction-Finetuned Text Embeddings. InFindings of the Associa- tion for Computational Linguistics: ACL 2023. 1102–1121. doi:10.18653/v1/2023. findings-acl.71
-
[27]
Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. 2023. Is ChatGPT Good at Search? Investi- gating Large Language Models as Re-Ranking Agents. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 14918–14937. doi:10.18653/v1/2023.emnlp-main.923
-
[28]
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2022. Text Embeddings by Weakly-Supervised Contrastive Pre-training.arXiv preprint arXiv:2212.03533(2022)
work page internal anchor Pith review arXiv 2022
-
[29]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024. Improving Text Embeddings with Large Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 11897–11916. doi:10.18653/v1/2024.acl-long. 642
-
[30]
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. 2023. C-Pack: Packaged Resources To Advance General Chinese Embedding.arXiv preprint arXiv:2309.07597(2023)
work page internal anchor Pith review arXiv 2023
-
[31]
Rui Yan, Ran Le, Yang Song, Tao Zhang, Xiangliang Zhang, and Dongyan Zhao
-
[32]
InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
Interview Choice Reveals Your Preference on the Market: To Improve Job-Resume Matching through Profiling Memories. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 914–922. doi:10.1145/3292500.3330963
- [33]
-
[34]
Zixuan Yu, Qianlong Zhang, Ran Yu, and Wolfgang Nejdl. 2025. ConFit v2: Improving Resume-Job Matching using Hypothetical Resume Embedding and Runner-Up Hard-Negative Mining. InFindings of the Association for Computa- tional Linguistics: ACL 2025
2025
-
[35]
Chen Zhu, Hengshu Zhu, Hui Xiong, Chao Ma, Fang Xie, Pengliang Ding, and Pan Li. 2018. Person-Job Fit: Adapting the Right Talent for the Right Job with Joint Representation Learning.ACM Transactions on Management Information Systems9, 3 (2018), 1–17. doi:10.1145/3234465 Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.