SDLLMFuzz: Dynamic-static LLM-assisted greybox fuzzing for structured input programs
Pith reviewed 2026-05-10 05:18 UTC · model grok-4.3
The pith
SDLLMFuzz combines LLM-generated inputs with static crash analysis to discover bugs faster in structured-input programs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a dynamic-static feedback loop, where LLMs produce syntactically valid and semantically diverse seeds while static analysis of core dumps and execution traces supplies semantic guidance, enables more efficient exploration of complex program behaviors in structured-input programs.
What carries the argument
The dynamic-static feedback loop that refines LLM inputs based on semantic information extracted from crash artifacts.
If this is right
- Greater success in finding vulnerabilities within programs that process structured data like XML, PNG, and audio files.
- Shorter intervals between starting the fuzzer and detecting the first bug.
- Improved ability to generate inputs that satisfy syntactic constraints without relying solely on manual grammars or mutations.
- More effective use of runtime crash information beyond simple coverage metrics.
Where Pith is reading between the lines
- Such hybrid systems may reduce the need for program-specific customizations in fuzzing tools.
- Advances in LLM capabilities could further amplify the effectiveness of this feedback approach.
- Similar techniques might apply to testing other constrained systems, such as network protocols or configuration parsers.
Load-bearing premise
Large language models can reliably produce syntactically valid and semantically diverse inputs, and static analysis of crash artifacts provides rich semantic information that guides effective subsequent input generation.
What would settle it
Repeating the Magma benchmark experiments and observing no significant gains in the number of bugs discovered or the time to first bug over traditional greybox fuzzers and other LLM baselines.
Figures






read the original abstract
Fuzzing has become a widely adopted technique for vulnerability discovery, yet it remains ineffective for structured-input programs due to strict syntactic constraints and limited semantic awareness. Traditional greybox fuzzers rely on mutation-based strategies and coarse-grained coverage feedback, which often fail to generate valid inputs and explore deep execution paths. Recent advances in large language models (LLMs) have shown promise in improving input generation, but existing approaches primarily focus on seed generation and largely overlook the effective use of runtime feedback. In this paper, we propose SDLLMFuzz, a dynamic-static LLM-assisted greybox fuzzing framework for structured-input programs. Our approach integrates LLM-based structure-aware seed generation with static crash analysis, forming a unified feedback loop that iteratively refines test inputs. Specifically, we leverage LLMs to generate syntactically valid and semantically diverse inputs, while extracting rich semantic information from crash artifacts (e.g., core dumps and execution traces) to guide subsequent input generation. This dynamic-static feedback mechanism enables more efficient exploration of complex program behaviors. We evaluate SDLLMFuzz on the Magma benchmark across multiple structured-input programs, including libxml2, libpng, and libsndfile. Experimental results show that SDLLMFuzz significantly outperforms traditional greybox fuzzers and LLM-assisted baselines in terms of bug discovery and time-to-bug. These results demonstrate that combining semantic input generation with feedback-driven refinement is an effective direction for improving fuzzing performance on structured-input programs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SDLLMFuzz, a greybox fuzzing framework for structured-input programs that combines LLM-based generation of syntactically valid and semantically diverse seeds with static analysis of crash artifacts (core dumps and execution traces) to create a dynamic-static feedback loop. The approach is evaluated on the Magma benchmark for programs including libxml2, libpng, and libsndfile, with the abstract claiming significant outperformance over traditional greybox fuzzers and LLM-assisted baselines in bug discovery and time-to-bug.
Significance. If the empirical claims hold with proper quantification, the work could advance fuzzing for complex input formats by showing how LLM generation plus static crash-derived semantics can improve upon coverage-only feedback. The dynamic-static loop idea addresses a known limitation in greybox fuzzing, and the Magma evaluation target is appropriate for structured programs.
major comments (3)
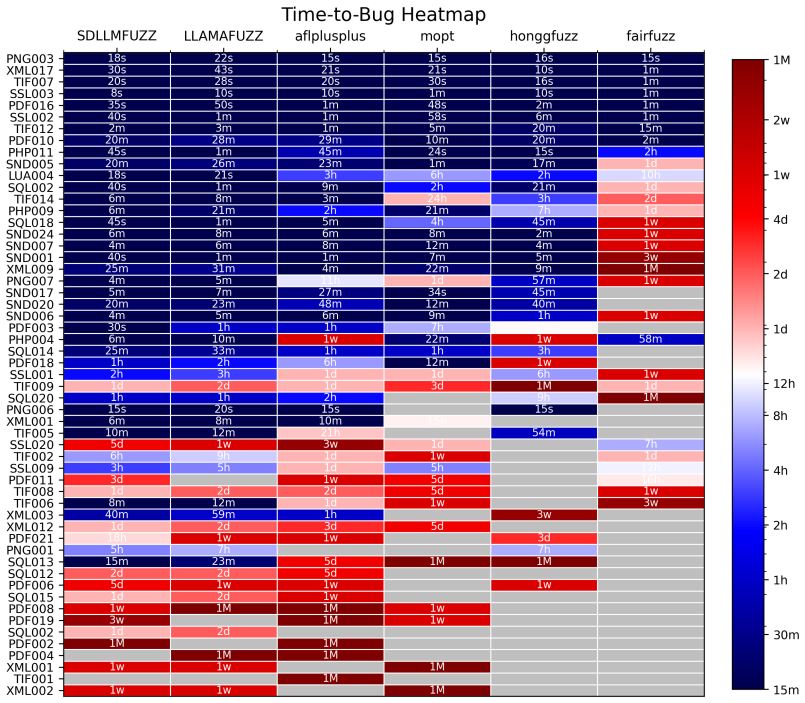
- [Abstract] Abstract: The headline claim that 'Experimental results show that SDLLMFuzz significantly outperforms traditional greybox fuzzers and LLM-assisted baselines in terms of bug discovery and time-to-bug' is unsupported by any quantitative metrics, statistical details, error bars, baseline configurations, run counts, or methodology specifics anywhere in the manuscript.
- [Approach] Approach description: No validity-rate statistics, syntactic correctness measurements, or diversity metrics are reported for the LLM-generated inputs on formats such as XML, PNG, or sound files, leaving the core assumption that LLMs reliably produce usable seeds unverified and load-bearing for the claimed gains.
- [Evaluation] Evaluation: The manuscript contains no ablation isolating the static crash-analysis component from standard dynamic coverage feedback, nor any comparison of time-to-bug or unique bugs found with and without the static signals; without this, it is impossible to attribute outperformance to the proposed dynamic-static loop rather than engineering or run-time differences.
minor comments (1)
- [Abstract] The abstract and approach sections use terms such as 'rich semantic information' and 'unified feedback loop' without defining how the extracted crash data is encoded or fed back to the LLM.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify how to strengthen the presentation of our results. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that 'Experimental results show that SDLLMFuzz significantly outperforms traditional greybox fuzzers and LLM-assisted baselines in terms of bug discovery and time-to-bug' is unsupported by any quantitative metrics, statistical details, error bars, baseline configurations, run counts, or methodology specifics anywhere in the manuscript.
Authors: We agree that the abstract would be stronger with explicit quantitative support. In the revised version we will update the abstract to report concrete metrics from our Magma experiments, including the number of unique bugs found per target, mean time-to-bug with standard deviation, the number of independent runs (10 per fuzzer), and the statistical test used for significance. Baseline configurations and run-time settings will also be summarized briefly so the claim is self-contained. revision: yes
-
Referee: [Approach] Approach description: No validity-rate statistics, syntactic correctness measurements, or diversity metrics are reported for the LLM-generated inputs on formats such as XML, PNG, or sound files, leaving the core assumption that LLMs reliably produce usable seeds unverified and load-bearing for the claimed gains.
Authors: We acknowledge the omission. We will add a new table and accompanying text in the evaluation section that reports, for each target format, the syntactic validity rate of LLM-generated seeds (percentage that parse without error), the number of unique structural variants produced, and a simple diversity measure such as the count of distinct semantic categories observed across 1,000 samples. These measurements will be obtained from the same generation pipeline used in the main experiments. revision: yes
-
Referee: [Evaluation] Evaluation: The manuscript contains no ablation isolating the static crash-analysis component from standard dynamic coverage feedback, nor any comparison of time-to-bug or unique bugs found with and without the static signals; without this, it is impossible to attribute outperformance to the proposed dynamic-static loop rather than engineering or run-time differences.
Authors: We agree that an explicit ablation is necessary to attribute gains to the static component. We will add an ablation study that disables the static crash-analysis feedback while retaining all other components (LLM generation and dynamic coverage) and reports the resulting change in unique bugs discovered and time-to-bug on the same Magma targets and run configuration. The new results will appear in a dedicated subsection of the evaluation. revision: yes
Circularity Check
No circularity: purely empirical evaluation with no derivation chain
full rationale
The paper proposes an LLM-assisted fuzzing framework and supports its claims solely via experimental results on the external Magma benchmark (libxml2, libpng, libsndfile). No equations, fitted parameters, self-referential definitions, or load-bearing self-citations appear in the provided text. The central performance claims are falsifiable against independent baselines and do not reduce to quantities defined by the paper's own choices.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models can be used to generate syntactically valid and semantically diverse inputs for structured data formats
- domain assumption Static analysis of crash artifacts such as core dumps and execution traces provides rich semantic information that can guide effective subsequent input generation
Reference graph
Works this paper leans on
-
[1]
Nautilus: Fishing for deep bugs with grammars
Cornelius Aschermann, Tommaso Frassetto, and Thorsten Holz. Nautilus: Fishing for deep bugs with grammars. In NDSS, 2019
work page 2019
-
[2]
Fuzzing: Challenges and reflec- tions
Marcel Böhme, Cristian Cadar, and Abhik Roychoudhury. Fuzzing: Challenges and reflec- tions. IEEE Software , 38(3):79–86, 2020
work page 2020
-
[3]
Marcel Böhme, Van-Thuan Pham, Manh-Dung Nguyen, et al. Directed greybox fuzzing. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, pages 2329–2344, 2017
work page 2017
-
[4]
Cristian Cadar, Daniel Dunbar, and Dawson R. Engler. Klee: Unassisted and automatic generation of high-coverage tests for complex systems programs. In OSDI, volume 8, pages 209–224, 2008
work page 2008
-
[5]
Hawkeye: Towards a desired directed grey-box fuzzer
Hongxu Chen, Yinxing Xue, Yang Li, et al. Hawkeye: Towards a desired directed grey-box fuzzer. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Commu- nications Security, pages 2095–2108, 2018
work page 2018
-
[6]
Compiler fuzzing through deep learning
Chris Cummins, Pavlos Petoumenos, Alastair Murray, et al. Compiler fuzzing through deep learning. In Proceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis , pages 95–105, 2018
work page 2018
-
[7]
Yanjun Deng, Chunqiu Steven Xia, Hao Peng, et al. Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models. In Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis , pages 423–435, 2023
work page 2023
-
[8]
Large language models are edge-case fuzzers: Testing deep learning libraries via fuzzgpt
Yanjun Deng, Chunqiu Steven Xia, Cheng Yang, et al. Large language models are edge- case fuzzers: Testing deep learning libraries via fuzzgpt. arXiv preprint arXiv:2304.02014 , 2023
-
[9]
Machine learning for black-box fuzzing of network protocols
Rui Fan and Yu Chang. Machine learning for black-box fuzzing of network protocols. In Information and Communications Security: 19th International Conference, ICICS 2017 , pages 621–632. Springer International Publishing, 2018
work page 2017
-
[10]
Patrice Godefroid, Adam Kiezun, and Michael Y. Levin. Grammar-based whitebox fuzzing. In Proceedings of the 29th ACM SIGPLAN Conference on Programming Language Design and Implementation , pages 206–215, 2008. 14
work page 2008
-
[11]
Patrice Godefroid, Michael Y. Levin, and David Molnar. Automated whitebox fuzz testing. In NDSS, volume 8, pages 151–166, 2008
work page 2008
-
[12]
Learn&fuzz: Machine learning for input fuzzing
Patrice Godefroid, Hila Peleg, and Rishabh Singh. Learn&fuzz: Machine learning for input fuzzing. In 2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE) , pages 50–59. IEEE, 2017
work page 2017
-
[13]
Ganfuzz: A gan-based industrial network protocol fuzzing framework
Zhifeng Hu, Jing Shi, Yu-Heng Huang, et al. Ganfuzz: A gan-based industrial network protocol fuzzing framework. In Proceedings of the 15th ACM International Conference on Computing Frontiers, pages 138–145, 2018
work page 2018
-
[14]
Jian Li, Bo Zhao, and Chao Zhang. Fuzzing: A survey. Cybersecurity, 1(1):1–13, 2018
work page 2018
-
[15]
Deepfuzz: Automatic generation of syn- tax valid c programs for fuzz testing
Xuefeng Liu, Xiaoting Li, Rohan Prajapati, et al. Deepfuzz: Automatic generation of syn- tax valid c programs for fuzz testing. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 1044–1051, 2019
work page 2019
-
[16]
Miller, Lars Fredriksen, and Bryan So
Barton P. Miller, Lars Fredriksen, and Bryan So. An empirical study of the reliability of unix utilities. Communications of the ACM , 33(12):32–44, 1990
work page 1990
-
[17]
Matthias Sablotny, Bjørn S. Jensen, and Chris W. Johnson. Recurrent neural networks for fuzz testing web browsers. In Information Security and Cryptology–ICISC 2018 , pages 354–370. Springer International Publishing, 2019
work page 2018
-
[18]
Fuzzing: Brute Force Vulnerability Discovery
Michael Sutton, Adam Greene, and Pedram Amini. Fuzzing: Brute Force Vulnerability Discovery. Pearson Education, 2007
work page 2007
-
[19]
Superion: Grammar-aware greybox fuzzing
Junjie Wang, Bihuan Chen, Lei Wei, et al. Superion: Grammar-aware greybox fuzzing. In 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE) , pages 724–735. IEEE, 2019
work page 2019
-
[20]
Universal fuzzing via large language models
Chunqiu Steven Xia, Michele Paltenghi, Jie Tian, et al. Fuzz4all: Universal fuzzing with large language models. arXiv preprint arXiv:2308.04748 , 2024
-
[21]
Format-aware learn&fuzz: Deep test data generation for efficient fuzzing
Mohammad Zakeri Nasrabadi, Saeed Parsa, and Alireza Kalaee. Format-aware learn&fuzz: Deep test data generation for efficient fuzzing. Neural Computing and Applications , 33:1497–1513, 2021
work page 2021
-
[22]
LLAMAFUZZ: Large Language Model Enhanced Greybox Fuzzing
Hongyu Zhang, Yicheng Rong, Yuxuan He, et al. Llamafuzz: Large language model en- hanced greybox fuzzing. arXiv preprint arXiv:2406.07714 , 2024
-
[23]
Seqfuzzer: An industrial protocol fuzzing framework from a deep learning perspective
Hong Zhao, Zhen Li, Hao Wei, et al. Seqfuzzer: An industrial protocol fuzzing framework from a deep learning perspective. In 2019 12th IEEE Conference on Software Testing, Validation and Verification (ICST) , pages 59–67. IEEE, 2019
work page 2019
-
[24]
Xiaogang Zhu, Sheng Wen, Seyit Camtepe, et al. Fuzzing: A survey for roadmap. ACM Computing Surveys , 54(11s):1–36, 2022. 15
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.