Recognition: unknown
Latent Fourier Transform
Pith reviewed 2026-05-10 03:42 UTC · model grok-4.3
The pith
By applying a Fourier transform to latents in a diffusion autoencoder and masking during training, musical structures can be edited and blended according to their timescales at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LatentFT separates musical patterns by timescale using a latent-space Fourier transform on a diffusion autoencoder. Masking latents in the frequency domain during training produces representations that support coherent manipulations at inference, enabling variations and blends that preserve characteristics at user-specified latent frequencies. This provides a continuous frequency axis for conditioning that improves adherence and quality over baselines.
What carries the argument
The latent Fourier transform, which converts the latent representation of a diffusion autoencoder into frequency components corresponding to different musical timescales and allows masking those components.
Load-bearing premise
That masking in the latent frequency domain cleanly separates musical timescales without introducing artifacts or breaking the diffusion generative process.
What would settle it
A listening test where participants rate whether edited outputs actually preserve the intended rhythmic or structural elements from the reference at the chosen timescales, compared to unmasked baselines.
Figures










read the original abstract
We introduce the Latent Fourier Transform (LatentFT), a framework that provides novel frequency-domain controls for generative music models. LatentFT combines a diffusion autoencoder with a latent-space Fourier transform to separate musical patterns by timescale. By masking latents in the frequency domain during training, our method yields representations that can be manipulated coherently at inference. This allows us to generate musical variations and blends from reference examples while preserving characteristics at desired timescales, which are specified as frequencies in the latent space. LatentFT parallels the role of the equalizer in music production: while traditional equalizers operates on audible frequencies to shape timbre, LatentFT operates on latent-space frequencies to shape musical structure. Experiments and listening tests show that LatentFT improves condition adherence and quality compared to baselines. We also present a technique for hearing frequencies in the latent space in isolation, and show different musical attributes reside in different regions of the latent spectrum. Our results show how frequency-domain control in latent space provides an intuitive, continuous frequency axis for conditioning and blending, advancing us toward more interpretable and interactive generative music models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Latent Fourier Transform (LatentFT), a framework combining a diffusion autoencoder with a latent-space Fourier transform to separate musical patterns by timescale. By masking latents in the frequency domain during training, the method produces representations that support coherent manipulations at inference time, enabling generation of musical variations and blends from reference examples while preserving characteristics at user-specified timescales (treated as frequencies in latent space). The approach is analogized to an audio equalizer but operating on latent frequencies to shape musical structure. The authors claim that experiments and listening tests demonstrate improved condition adherence and quality relative to baselines, and they present a technique for isolating and auditioning individual latent frequencies to show that distinct musical attributes occupy different regions of the latent spectrum.
Significance. If the central claims are substantiated by rigorous experiments, LatentFT could offer a valuable contribution to generative music modeling by supplying an intuitive, continuous frequency axis for conditioning and editing. The timescale-separation idea and the equalizer analogy provide a clear conceptual bridge to music production practice, and the ability to manipulate latents without retraining is potentially useful for interactive applications. The work builds directly on diffusion autoencoders and introduces a new manipulation primitive; however, the absence of any equations, implementation specifics, quantitative results, or ablation studies in the supplied manuscript prevents a full evaluation of its technical novelty or practical impact.
major comments (1)
- Abstract: The load-bearing claim that frequency-domain masking during training produces latents that can be 'manipulated coherently at inference' while preserving timescale-specific characteristics rests on the unstated assumption that musical patterns are meaningfully separable in the latent frequency domain. No definition of the Latent Fourier Transform, no equation for the masking operation, and no derivation showing why the inverse transform remains stable after masking are provided, making it impossible to assess whether the generative process remains intact or whether artifacts are introduced.
minor comments (2)
- The abstract states that 'different musical attributes reside in different regions of the latent spectrum' but supplies neither examples of such attributes nor any visualization or quantitative measure of the separation, which would be needed to substantiate the interpretability claim.
- No information is given on the base diffusion autoencoder architecture, training dataset, or exact masking schedule (e.g., which frequency bands are masked and at what probability), all of which are required for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for identifying areas where additional technical detail would strengthen the manuscript. We address the major comment below.
read point-by-point responses
-
Referee: Abstract: The load-bearing claim that frequency-domain masking during training produces latents that can be 'manipulated coherently at inference' while preserving timescale-specific characteristics rests on the unstated assumption that musical patterns are meaningfully separable in the latent frequency domain. No definition of the Latent Fourier Transform, no equation for the masking operation, and no derivation showing why the inverse transform remains stable after masking are provided, making it impossible to assess whether the generative process remains intact or whether artifacts are introduced.
Authors: We agree that the abstract is high-level and omits the formal definition, equation, and stability argument, which limits evaluability. The manuscript body describes the LatentFT procedure, but we will revise to insert the explicit definition (discrete Fourier transform applied to the diffusion autoencoder latents), the masking equation (element-wise multiplication by a binary frequency mask during training), and a short derivation showing that the inverse DFT remains stable because the autoencoder is trained end-to-end with a reconstruction objective that tolerates band-limited perturbations. This also makes the separability assumption explicit: the training objective forces distinct timescale patterns into separate latent-frequency bands. We will further add the quantitative results, implementation specifics, and ablation studies noted in the referee's significance assessment. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces a methodological framework (diffusion autoencoder + latent-space Fourier transform + frequency masking during training) rather than deriving a mathematical result from first principles. No equations, parameter fits, or predictions are presented that reduce to the inputs by construction. The central claim—that masking produces timescale-manipulable latents—is validated externally via experiments and listening tests, not by internal self-definition or self-citation chains. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Latent Fourier Transform (LatentFT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
MusicLM: Generating Music From Text
Andrea Agostinelli, Timo I Denk, Zal ´an Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, et al. Musiclm: Generating music from text.arXiv preprint arXiv:2301.11325,
work page internal anchor Pith review arXiv
-
[2]
Yuval Atzmon, Maciej Bala, Yogesh Balaji, Tiffany Cai, Yin Cui, Jiaojiao Fan, Yunhao Ge, Sid- dharth Gururani, Jacob Huffman, Ronald Isaac, et al. Edify image: High-quality image generation with pixel space laplacian diffusion models.arXiv preprint arXiv:2411.07126,
-
[3]
Unsupervised composable representations for audio.arXiv preprint arXiv:2408.09792,
Giovanni Bindi and Philippe Esling. Unsupervised composable representations for audio.arXiv preprint arXiv:2408.09792,
-
[4]
Maximum filter vibrato suppression for onset detection
Sebastian B ¨ock and Gerhard Widmer. Maximum filter vibrato suppression for onset detection. In Proc. of the 16th Int. Conf. on Digital Audio Effects (DAFx). Maynooth, Ireland (Sept 2013), volume 7, pp
2013
-
[5]
Soundstorm: Efficient parallel audio generation,
Zal´an Borsos, Rapha¨el Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Shar- ifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, et al. Audiolm: a language modeling approach to audio generation.IEEE/ACM transactions on audio, speech, and language processing, 31:2523–2533, 2023a. Zal´an Borsos, Matt Sharifi, Damien...
-
[6]
Rave: A variational autoencoder for fast and high-quality neural audio synthesis,
URLhttps://arxiv.org/abs/2111.05011. Ke Chen, Yusong Wu, Haohe Liu, Marianna Nezhurina, Taylor Berg-Kirkpatrick, and Shlomo Dub- nov. Musicldm: Enhancing novelty in text-to-music generation using beat-synchronous mixup strategies. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Sig- nal Processing (ICASSP), pp. 1206–1210. IEEE,
-
[7]
Jooyoung Choi, Sungwon Kim, Yonghyun Jeong, Youngjune Gwon, and Sungroh Yoon. Ilvr: Con- ditioning method for denoising diffusion probabilistic models.arXiv preprint arXiv:2108.02938,
-
[8]
Music style transfer: A position paper.arXiv preprint arXiv:1803.06841,
Shuqi Dai, Zheng Zhang, and Gus G Xia. Music style transfer: A position paper.arXiv preprint arXiv:1803.06841,
-
[9]
Stable audio open
Zach Evans, Julian D Parker, CJ Carr, Zack Zukowski, Josiah Taylor, and Jordi Pons. Stable audio open. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2025
-
[10]
Hugo Flores Garcia, Prem Seetharaman, Rithesh Kumar, and Bryan Pardo
URLhttps://riffusion.com/about. Hugo Flores Garcia, Prem Seetharaman, Rithesh Kumar, and Bryan Pardo. Vampnet: Music gener- ation via masked acoustic token modeling.arXiv preprint arXiv:2307.04686,
-
[11]
Sketch2sound: Controllable audio generation via time-varying signals and sonic imitations
Hugo Flores Garc ´ıa, Oriol Nieto, Justin Salamon, Bryan Pardo, and Prem Seetharaman. Sketch2sound: Controllable audio generation via time-varying signals and sonic imitations. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2025
-
[12]
arXiv preprint arXiv:2111.13587 , year=
John Guibas, Morteza Mardani, Zongyi Li, Andrew Tao, Anima Anandkumar, and Bryan Catan- zaro. Adaptive fourier neural operators: Efficient token mixers for transformers.arXiv preprint arXiv:2111.13587,
-
[13]
Pixelvae: A latent variable model for natural images.arXiv preprint arXiv:1611.05013,
Ishaan Gulrajani, Kundan Kumar, Faruk Ahmed, Adrien Ali Taiga, Francesco Visin, David Vazquez, and Aaron Courville. Pixelvae: A latent variable model for natural images.arXiv preprint arXiv:1611.05013,
-
[14]
Music tagging with classifier group chains
Takuya Hasumi, Tatsuya Komatsu, and Yusuke Fujita. Music tagging with classifier group chains. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2025
-
[15]
12 Curtis Hawthorne, Andriy Stasyuk, Adam Roberts, Ian Simon, Cheng-Zhi Anna Huang, Sander Dieleman, Erich Elsen, Jesse Engel, and Douglas Eck. Enabling factorized piano music modeling and generation with the maestro dataset.arXiv preprint arXiv:1810.12247,
-
[16]
Ziwei He, Meng Yang, Minwei Feng, Jingcheng Yin, Xinbing Wang, Jingwen Leng, and Zhouhan Lin. Fourier transformer: Fast long range modeling by removing sequence redundancy with fft operator.arXiv preprint arXiv:2305.15099,
-
[17]
Gaussian Error Linear Units (GELUs)
D Hendrycks. Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415,
work page internal anchor Pith review arXiv
-
[18]
Qingqing Huang, Daniel S Park, Tao Wang, Timo I Denk, Andy Ly, Nanxin Chen, Zhengdong Zhang, Zhishuai Zhang, Jiahui Yu, Christian Frank, et al. Noise2music: Text-conditioned music generation with diffusion models.arXiv preprint arXiv:2302.03917,
-
[19]
Tim- bretron: A wavenet (cyclegan (cqt (audio))) pipeline for musical timbre transfer,
Sicong Huang, Qiyang Li, Cem Anil, Xuchan Bao, Sageev Oore, and Roger B Grosse. Tim- bretron: A wavenet (cyclegan (cqt (audio))) pipeline for musical timbre transfer.arXiv preprint arXiv:1811.09620,
-
[20]
Fr\’echet audio distance: A metric for evaluating music enhancement algo- rithms,
Kevin Kilgour, Mauricio Zuluaga, Dominik Roblek, and Matthew Sharifi. Fr\’echet audio distance: A metric for evaluating music enhancement algorithms.arXiv preprint arXiv:1812.08466,
-
[21]
DiffWave: A Versatile Diffusion Model for Audio Synthesis
Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. Diffwave: A versatile diffusion model for audio synthesis.arXiv preprint arXiv:2009.09761,
work page internal anchor Pith review arXiv 2009
-
[22]
High- fidelity music vocoder using neural audio codecs
Luca A Lanzend ¨orfer, Florian Gr ¨otschla, Michael Ungersb ¨ock, and Roger Wattenhofer. High- fidelity music vocoder using neural audio codecs. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2025
-
[23]
BigVGAN: A universal neural vocoder with large-scale training
Sang-gil Lee, Wei Ping, Boris Ginsburg, Bryan Catanzaro, and Sungroh Yoon. Bigvgan: A universal neural vocoder with large-scale training.arXiv preprint arXiv:2206.04658,
-
[24]
Fnet: Mixing tokens with fourier transforms.arXiv preprint arXiv:2105.03824,
James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, and Santiago Ontanon. Fnet: Mixing tokens with fourier transforms.arXiv preprint arXiv:2105.03824,
-
[25]
Controllable music production with diffusion models and guidance gradients,
Mark Levy, Bruno Di Giorgi, Floris Weers, Angelos Katharopoulos, and Tom Nickson. Con- trollable music production with diffusion models and guidance gradients.arXiv preprint arXiv:2311.00613,
-
[26]
Audioldm: Text-to-audio generation with latent diffusion models,
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumbley. Audioldm: Text-to-audio generation with latent diffusion models.arXiv preprint arXiv:2301.12503,
-
[27]
Fast training of convolutional networks through ffts.arXiv preprint arXiv:1312.5851,
Michael Mathieu, Mikael Henaff, and Yann LeCun. Fast training of convolutional networks through ffts.arXiv preprint arXiv:1312.5851,
-
[28]
librosa: Audio and music signal analysis in python.SciPy, 2015:18–24,
Brian McFee, Colin Raffel, Dawen Liang, Daniel PW Ellis, Matt McVicar, Eric Battenberg, and Oriol Nieto. librosa: Audio and music signal analysis in python.SciPy, 2015:18–24,
2015
-
[29]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations.arXiv preprint arXiv:2108.01073,
work page internal anchor Pith review arXiv
-
[30]
A diffusion-based generative equalizer for music restoration.arXiv preprint arXiv:2403.18636,
Eloi Moliner, Maija Turunen, Filip Elvander, and Vesa V ¨alim¨aki. A diffusion-based generative equalizer for music restoration.arXiv preprint arXiv:2403.18636,
-
[31]
Fine-grained and inter- pretable neural speech editing.arXiv preprint arXiv:2407.05471,
Max Morrison, Cameron Churchwell, Nathan Pruyne, and Bryan Pardo. Fine-grained and inter- pretable neural speech editing.arXiv preprint arXiv:2407.05471,
-
[32]
Ditto: Diffusion inference-time t-optimization for music generation.arXiv preprint arXiv:2401.12179,
14 Zachary Novack, Julian McAuley, Taylor Berg-Kirkpatrick, and Nicholas J Bryan. Ditto: Diffusion inference-time t-optimization for music generation.arXiv preprint arXiv:2401.12179,
-
[33]
Stemgen: A music generation model that listens
Julian D Parker, Janne Spijkervet, Katerina Kosta, Furkan Yesiler, Boris Kuznetsov, Ju-Chiang Wang, Matt Avent, Jitong Chen, and Duc Le. Stemgen: A music generation model that listens. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1116–1120. IEEE,
2024
-
[34]
Music2latent: Consistency autoencoders for latent audio compression.arXiv preprint arXiv:2408.06500,
Marco Pasini, Stefan Lattner, and George Fazekas. Music2latent: Consistency autoencoders for latent audio compression.arXiv preprint arXiv:2408.06500,
-
[35]
Pascal Passigan and Vayd Ramkumar. Analyzing the effect ofk-space features in mri classification models.arXiv preprint arXiv:2409.13589,
-
[36]
Ef- ficient autoregressive audio modeling via next-scale prediction.arXiv preprint arXiv:2408.09027,
Kai Qiu, Xiang Li, Hao Chen, Jie Sun, Jinglu Wang, Zhe Lin, Marios Savvides, and Bhiksha Raj. Ef- ficient autoregressive audio modeling via next-scale prediction.arXiv preprint arXiv:2408.09027,
-
[37]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[38]
15 Daniel Stoller, Sebastian Ewert, and Simon Dixon. Wave-u-net: A multi-scale neural network for end-to-end audio source separation.arXiv preprint arXiv:1806.03185,
-
[39]
Subtractive training for music stem insertion using latent diffusion models
Ivan Villa-Renteria, Mason Long Wang, Zachary Shah, Zhe Li, Soohyun Kim, Neelesh Ramachan- dran, and Mert Pilanci. Subtractive training for music stem insertion using latent diffusion models. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pp. 1–5. IEEE,
2025
-
[40]
Heehwan Wang, Joonwoo Kwon, Sooyoung Kim, Shinjae Yoo, Yuewei Lin, and Jiook Cha. A training-free approach for music style transfer with latent diffusion models.arXiv preprint arXiv:2411.15913,
work page internal anchor Pith review arXiv
-
[41]
Learning hierarchical features from generative models.arXiv preprint arXiv:1702.08396,
Shengjia Zhao, Jiaming Song, and Stefano Ermon. Learning hierarchical features from generative models.arXiv preprint arXiv:1702.08396,
-
[42]
Shuoyang Zheng, Anna Xamb ´o Sed ´o, and Nick Bryan-Kinns. A mapping strategy for interacting with latent audio synthesis using artistic materials.arXiv preprint arXiv:2407.04379, 2024a. Tianyi Zheng, Bo Li, Shuang Wu, Ben Wan, Guodong Mu, Shice Liu, Shouhong Ding, and Jia Wang. Mfae: Masked frequency autoencoders for domain generalization face anti-spoof...
-
[43]
Each(80×1) timeframe is passed through an MLP to obtain an80×512latent sequence
A.1 ENCODERS We experiment with three encoders: 1.MLP Encoder.The audio is converted into an80×512mel-spectrogram. Each(80×1) timeframe is passed through an MLP to obtain an80×512latent sequence. Since each timeframe is processed independently, this encoder enforces input-output alignment, and results in no leakage between timeframes. 2.1D U-Net Encoder.T...
2015
-
[44]
The hyperparameters for our MLP encoder are listed in Table
It consists of a series of linear layers with SiLU activations (Hendrycks, 2016), group normalization layers (Wu & He, 2018), and residual connections (He et al., 2016). The hyperparameters for our MLP encoder are listed in Table
2016
-
[45]
Attribute Value Input80×512mel-spectrogram Output80×512latent sequence Architecture Frame-wise MLP Hidden Dim. 512 Num. Hidden Layers 16 Table 2: MLP Encoder Architecture 6https://github.com/maswang32/latentfouriertransform/ 18 A.1.2 1D U-NETENCODERARCHITECTURE Our 1D U-Net encoder is a 1D version of the encoder used in Karras et al. (2022). The convoluti...
2022
-
[46]
First, it creates a 1024×512sequence of continuous embeddings using the encoder of Descript Audio Codec (Kumar et al., 2023)
Attribute Value Input80×512mel-spectrogram Output80×512latent sequence Architecture 1D U-Net Kernel Size 3 Resolutions [512, 256, 128, 64, 32, 16] Channels Per Resolution [512, 512, 512, 768, 768, 1024] Resolutions with Attention [64, 32, 16] Table 3: 1D U-Net Encoder Hyperparameters A.1.3 DAC ENCODERARCHITECTURE The DAC encoder takes in a raw audio wavef...
2023
-
[47]
In addition, following Karras et al
We use a linear warmup for the first 4,000 training steps, and we apply cosine annealing to the learning rate after 350k iterations. In addition, following Karras et al. (2022), we store an exponential moving average of the model weights, which we use for inference. Hyperpa- rameters for this are shown in Table
2022
-
[48]
The dataset is publicly available, and is popular in tasks like neural audio compression, vocod- ing (Lanzend¨orfer et al., 2025), and music-tagging (Hasumi et al., 2025)
is a large-scale collection of over 55,000 spanning diverse genres, like classical, electronic, pop, and rock music. The dataset is publicly available, and is popular in tasks like neural audio compression, vocod- ing (Lanzend¨orfer et al., 2025), and music-tagging (Hasumi et al., 2025). We train our mod- els on a dataset of 2.5 million 5.9-second clips f...
2025
-
[49]
We use GTZAN for the interpretability experiment (Sec
is a standard benchmark for genre classifi- cation, containing 1,000 30-second audio clips evenly distributed across 10 genres (blues, 20 classical, country, disco, hip-hop, jazz, metal, pop, reggae, and rock). We use GTZAN for the interpretability experiment (Sec. 4.6), since we require high-quality genre labels. We show results on more datasets in Appen...
2018
-
[50]
Ability to Blend
21 System 1 System 2p-value, Audio Qualityp-Value, Ability to Blend LATENTFT Cross Synthesis1.59×10 −3 9.54×10 −2∗ LATENTFT ILVR3.83×10 −4 8.84×10 −7 LATENTFT VampNet7.02×10 −10 1.64×10 −10 Cross Synthesis ILVR9.51×10 −2∗ 6.62×10 −4 Cross Synthesis VampNet1.91×10 −6 8.09×10 −10 ILVR VampNet1.55×10 −6 1.69×10 −5 Table 8: Results from a Kruskal-Wallis H tes...
1977
-
[51]
overall accuracy
package. First, we use Essentia’s algorithm to predict the predominant pitch (the pitch of the melody) in a song. Then, we compute the “overall accuracy” metric described in Salamon et al. (2014), to measure how well the pitches of the generated variation match with the reference. Again, we plot the pitch accuracy against 22 the latent frequencies that we...
2014
-
[52]
Ablating any component of the model generally leads to worse audio quality and adherence. Adherence Quality Loudness↑Rhythm↑Timbre↓Harmony↓FAD↓ LATENTFT-MLP0.6780.8751.030 0.1091.371 w/o Freq. Masking 0.5970.9021.152 0.127 4.789 w/o Correlation 0.635 0.885 1.167 0.115 2.534 w/o Log. Scale 0.535 0.827 1.382 0.111 2.119 w/o Encoder 0.030 0.539 4.026 0.1470....
-
[53]
w/o Freq. Masking
Ablating any component of the model generally leads to either significantly worse audio qual- ity, or significantly worse adherence. Ablating Frequency Masking During Training.First, we ablate frequency masking during train- ing, applying only the inference-time user-specified mask. Previous methods apply frequency- masking post-hoc, toanalyzea pretrained...
2020
-
[54]
w/o Correlation
Our strategy of correlating scores results in large, contiguous regions of unmasked and masked bins, which makes the learning task more difficult, and better reflects inference-time, user-specified masks. Tables 9 and 10 (“w/o Correlation”) verify that using an uncorrelated mask results in substantial degradations to audio quality. 24 0 20 40 60 80 100 12...
2048
-
[55]
Although LA- TENTFT performs worse in terms of audio quality compared to our evaluations on MTG-Jamendo, we find that it outperforms our baselines on both GTZAN and Maestro. This indicates that LA- TENTFT can work on recordings that are only piano, or on datasets with a diverse set of genres. Conditional Generation Blending Adherence Quality Adherence to ...
-
[56]
Cross Synthesis also only applies to the blending task
The Masked Token Model and Cross Synthesis baselines do not offer frequency-based controls, so we do not compute adherence. Cross Synthesis also only applies to the blending task. Conditional Generation Blending Adherence Quality Adherence to Both Inputs Quality Loud.↑Rhyth.↑Timb.↓Harm.↓FAD↓Loud.↑Rhyth.↑Timb.↓Harm.↓FAD↓ Vampnet - - - - 11.914 - - - - 14.8...
-
[57]
Chord changes also occur at low frequencies, with peak preservation between 0.25–2 Hz
Across several musical styles, we see the trend that genre tends to lie in the frequency range around 0 Hz, indicating that it is a global characteristic. Chord changes also occur at low frequencies, with peak preservation between 0.25–2 Hz. Tempo and pitch occur at higher la- tent frequencies, since prominent rhythmic and melodic patterns are typically m...
2022
-
[58]
Removing DFT Masking
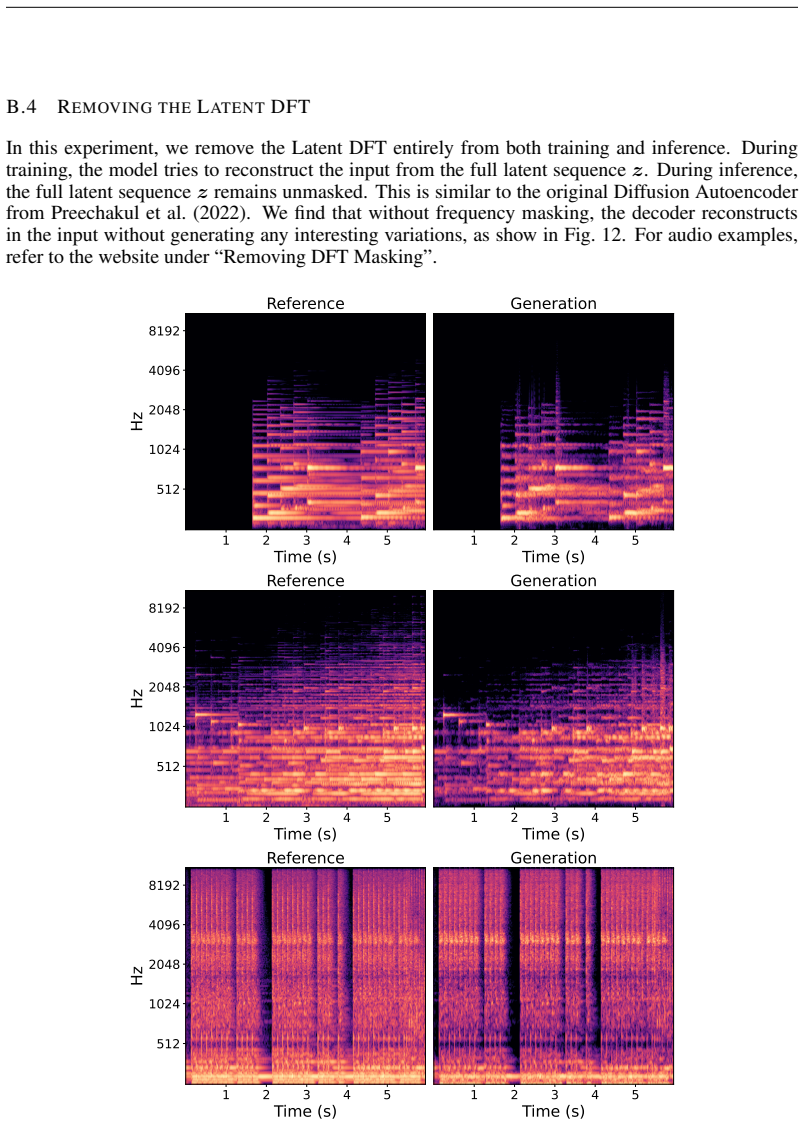
For audio examples, refer to the website under “Removing DFT Masking”. 1 2 3 4 5 Time (s) 512 1024 2048 4096 8192Hz Reference 1 2 3 4 5 Time (s) Generation 1 2 3 4 5 Time (s) 512 1024 2048 4096 8192Hz Reference 1 2 3 4 5 Time (s) Generation 1 2 3 4 5 Time (s) 512 1024 2048 4096 8192Hz Reference 1 2 3 4 5 Time (s) Generation Figure 12: Mel-spectrograms whe...
2048
-
[59]
Generative Audio Equalizer.Similar to our work, Moliner et al
providing anintuitive, non-heuristicway of specifying scales via Hz. Generative Audio Equalizer.Similar to our work, Moliner et al. (2024) introduce a diffusion- based generative audio equalizer. While this work generates content at selectedaudiblefrequencies, we generate content atlatentfrequencies. Other Uses of the Fourier Transform in Deep Learning.Th...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.