Towards a Foundation-Model Paradigm for Aerodynamic Prediction in Three-dimensional Design
Pith reviewed 2026-05-10 05:58 UTC · model grok-4.3
The pith
Pre-training on diverse wing geometries allows accurate aerodynamic predictions on new designs with only 450 fine-tuning samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
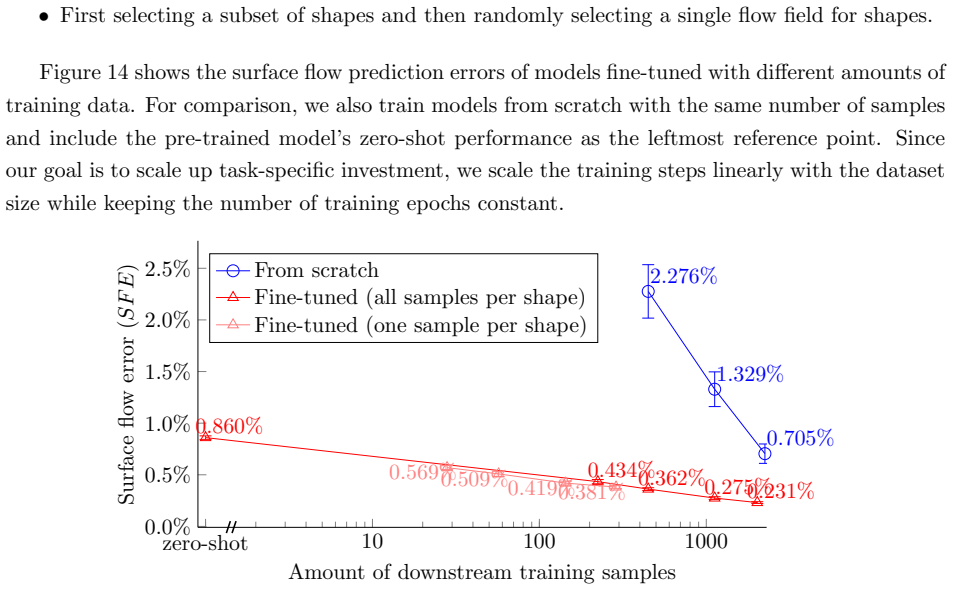
Pre-training AeroTransformer on the SuperWing dataset of nearly 30,000 samples with broad geometric diversity, then fine-tuning on 450 task-specific samples for perturbed Common Research Model wings, achieves 0.36% error on surface-flow prediction, an 84.2% reduction relative to training from scratch.
What carries the argument
AeroTransformer, a Transformer-based architecture designed for large-scale aerodynamic training that learns transferable representations from diverse geometries during pre-training before adapting to task-specific data.
Load-bearing premise
That the pre-training on the broad SuperWing dataset creates representations that transfer well to fine-tuning on perturbed Common Research Model wing shapes without major domain-shift issues.
What would settle it
Demonstrating that fine-tuning the pre-trained model on 450 samples from a new wing geometry family yields error rates comparable to or higher than training from scratch.
Figures

















read the original abstract
Accurate machine-learning models for aerodynamic prediction are essential for accelerating shape optimization, yet remain challenging to develop for complex three-dimensional configurations due to the high cost of generating training data. This work introduces a methodology for efficiently constructing accurate surrogate models for design purposes by first pre-training a large-scale model on diverse geometries and then fine-tuning it with a few more detailed task-specific samples. A Transformer-based architecture, AeroTransformer, is developed and tailored for large-scale training to learn aerodynamics. The methodology is evaluated on transonic wings, where the model is pre-trained on SuperWing, a dataset of nearly 30000 samples with broad geometric diversity, and subsequently fine-tuned to handle specific wing shapes perturbed from the Common Research Model. Results show that, with 450 task-specific samples, the proposed methodology achieves 0.36% error on surface-flow prediction, reducing 84.2% compared to training from scratch. The influence of model configurations and training strategies is also systematically studied to provide guidance on effectively training and deploying such models under limited data and computational budgets. To facilitate reuse, we release the datasets and the pre-trained models at https://github.com/tum-pbs/AeroTransformer. An interactive design tool is also built on the pre-trained model and is available online at https://webwing.pbs.cit.tum.de.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a foundation-model approach for 3D aerodynamic surrogate modeling. A Transformer architecture (AeroTransformer) is pre-trained on the large, geometrically diverse SuperWing dataset of nearly 30,000 samples and then fine-tuned on 450 task-specific samples for perturbed Common Research Model wings under transonic conditions. The central empirical result is a 0.36% error on surface-flow prediction, representing an 84.2% reduction relative to training from scratch; systematic ablation studies on model size and training strategy are included, and the authors release the datasets, pre-trained weights, and an interactive web tool.
Significance. If the surface-flow accuracy is shown to correlate with integrated aerodynamic quantities and optimization performance, the pre-training-plus-fine-tuning paradigm could materially reduce the data-generation cost of high-fidelity 3D aerodynamic surrogates. The public release of the SuperWing dataset, pre-trained models, and reproduction code constitutes a concrete contribution that supports reproducibility and follow-on work in the field.
major comments (2)
- [Evaluation on transonic wings / Results] The headline claim positions the model for “accelerating shape optimization” and “design purposes,” yet the reported metric is a single scalar surface-flow pointwise error (0.36%). In transonic flow, local pressure or velocity discrepancies can integrate to non-negligible errors in lift/drag coefficients or produce inconsistent adjoint gradients; the manuscript should therefore also report errors on integrated forces (Cl, Cd) and, ideally, a simple gradient-based optimization test to anchor the design-utility assertion.
- [Methodology and experimental setup] The 84.2% error reduction is stated relative to “training from scratch.” The exact baseline protocol (identical architecture and capacity, same optimizer schedule, same data-augmentation pipeline, and identical number of gradient steps) must be documented so that the improvement can be unambiguously attributed to pre-training rather than to differences in training budget or hyper-parameter tuning.
minor comments (2)
- [Abstract and §4] The precise definition of the 0.36% error (e.g., relative L2 norm on pressure, velocity, or both; normalization details; whether it is averaged over the surface or volume) should be stated explicitly in the abstract and early in the results section for immediate interpretability.
- [Figures] Figure captions and axis labels should explicitly indicate whether error maps are absolute or relative and which flow variable (pressure, velocity magnitude, etc.) is visualized.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We have revised the paper to include errors on integrated force coefficients and to explicitly document the baseline training protocol, which we believe addresses the concerns while preserving the core contribution of the pre-training paradigm.
read point-by-point responses
-
Referee: The headline claim positions the model for “accelerating shape optimization” and “design purposes,” yet the reported metric is a single scalar surface-flow pointwise error (0.36%). In transonic flow, local pressure or velocity discrepancies can integrate to non-negligible errors in lift/drag coefficients or produce inconsistent adjoint gradients; the manuscript should therefore also report errors on integrated forces (Cl, Cd) and, ideally, a simple gradient-based optimization test to anchor the design-utility assertion.
Authors: We agree that integrated quantities are essential to substantiate claims about design utility. In the revised manuscript we have added a dedicated subsection reporting mean absolute errors on Cl and Cd for both the pre-trained/fine-tuned model and the from-scratch baseline on the same 450-sample test set; the relative improvement remains consistent with the surface-flow result (approximately 80 % reduction). We have also included a simple gradient-based optimization experiment in which the surrogate is used to minimize a weighted combination of Cl and Cd subject to geometric constraints; the pre-trained model yields faster convergence and a lower final objective value than the scratch-trained counterpart. These additions are now presented in Section 4.4. revision: yes
-
Referee: The 84.2% error reduction is stated relative to “training from scratch.” The exact baseline protocol (identical architecture and capacity, same optimizer schedule, same data-augmentation pipeline, and identical number of gradient steps) must be documented so that the improvement can be unambiguously attributed to pre-training rather than to differences in training budget or hyper-parameter tuning.
Authors: We appreciate the request for explicit documentation. The revised experimental-setup section now states that the from-scratch baseline employs the identical AeroTransformer architecture and parameter count, the same AdamW optimizer with identical learning-rate schedule and warm-up, the same data-augmentation pipeline, and exactly the same total number of gradient steps as the fine-tuning stage. A new table (Table 2) summarizes the hyper-parameters side-by-side for the two settings, confirming that the only difference is the initialization from the pre-trained weights. revision: yes
Circularity Check
No circularity: empirical pre-train/fine-tune results on held-out data
full rationale
The paper reports an empirical machine-learning pipeline: pre-training AeroTransformer on the SuperWing dataset of ~30k samples, followed by fine-tuning on 450 task-specific perturbed CRM wing samples, with surface-flow error measured at 0.36% (84.2% reduction vs. scratch training). No derivation chain, equations, or first-principles predictions are claimed; the headline metric is a standard held-out evaluation on separate test configurations. Dataset release and external reproducibility remove any self-referential dependency. No self-citations, ansatzes, or fitted parameters are renamed as predictions. The result is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- fine-tuning sample count
- model configuration and training hyperparameters
axioms (1)
- domain assumption Pre-training on diverse 3D wing geometries produces transferable representations for fine-tuning on perturbed shapes from the same family
invented entities (1)
-
AeroTransformer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Steven L. Brunton, J. Nathan Kutz, Krithika Manohar, Aleksandr Y. Aravkin, Kristi Mor- gansen, Jennifer Klemisch, Nicholas Goebel, James Buttrick, Jeffrey Poskin, Adriana W. Blom-Schieber, Thomas Hogan, and Darren McDonald. Data-driven aerospace engineering: Reframing the industry with machine learning.AIAA Journal, pages 1–26, 2021
work page 2021
-
[2]
Joaquim R.R.A. Martins. Aerodynamic design optimization: Challenges and perspectives. Computers & Fluids, 239:105391, May 2022
work page 2022
-
[3]
Yunjia Yang, Runze Li, Yufei Zhang, and Haixin Chen. Fast Buffet-Onset Prediction and Opti- mization Method Based on Pretrained Flowfield Prediction Model.AIAA Journal, 62(8):2979– 95, August 2024
work page 2024
-
[4]
Aerodynamic Robust Design Research Using Adjoint-Based Optimization under Operating Uncertainties
Yuhang Ma, Jiecheng Du, Tihao Yang, Yayun Shi, Libo Wang, and Wei Wang. Aerodynamic Robust Design Research Using Adjoint-Based Optimization under Operating Uncertainties. Aerospace, 10(10):831, September 2023
work page 2023
-
[5]
Gaetan K. W. Kenway and Joaquim R. R. A. Martins. Multipoint Aerodynamic Shape Opti- mization Investigations of the Common Research Model Wing.AIAA Journal, 54(1):113–128, January 2016
work page 2016
-
[6]
Jichao Li, Xiaosong Du, and Joaquim R.R.A. Martins. Machine learning in aerodynamic shape optimization.Progress in Aerospace Sciences, 134:100849, October 2022
work page 2022
-
[7]
Nils Thuerey, Konstantin Weissenow, Lukas Prantl, and Xiangyu Hu. Deep learning methods for reynolds-averaged navier–stokes simulations of airfoil flows.AIAA Journal, 58(1):25–36, 2020
work page 2020
-
[8]
Li-Wei Chen and Nils Thuerey. Towards high-accuracy deep learning inference of compressible flows over aerofoils.Computers & Fluids, 250:105707, 2023
work page 2023
-
[9]
Ashwin Renganathan, Romit Maulik, and Jai Ahuja
S. Ashwin Renganathan, Romit Maulik, and Jai Ahuja. Enhanced data efficiency using deep neural networks and Gaussian processes for aerodynamic design optimization.Aerospace Sci- ence and Technology, 111:106522, April 2021
work page 2021
-
[10]
Konstantina G. Kovani, Marina G. Kontou, Varvara G. Asouti, and Kyriakos C. Giannakoglou. DNN-Driven Gradient-Based Shape Optimization in Fluid Mechanics. In Lazaros Iliadis, Ilias 37 Maglogiannis, Serafin Alonso, Chrisina Jayne, and Elias Pimenidis, editors,Engineering Appli- cations of Neural Networks, volume 1826, pages 379–390. Springer Nature Switzer...
work page 2023
-
[11]
Data-based approach for wing shape design optimization
Jichao Li and Mengqi Zhang. Data-based approach for wing shape design optimization. Aerospace Science and Technology, 112:106639, May 2021
work page 2021
-
[12]
Li-Wei Chen, Berkay A Cakal, Xiangyu Hu, and Nils Thuerey. Numerical investigation of min- imum drag profiles in laminar flow using deep learning surrogates.Journal of Fluid Mechanics, 919, 2021
work page 2021
- [13]
-
[14]
Jichao Li, Mohamed Amine Bouhlel, and Joaquim R. R. A. Martins. Data-Based Approach for Fast Airfoil Analysis and Optimization.AIAA Journal, 57(2):581–596, February 2019
work page 2019
-
[15]
Mohamed Amine Bouhlel, Sicheng He, and Joaquim R. R. A. Martins. Scalable gradi- ent–enhanced artificial neural networks for airfoil shape design in the subsonic and transonic regimes.Structural and Multidisciplinary Optimization, 61(4):1363–1376, April 2020
work page 2020
-
[16]
Jiehua Tian, Feng Qu, Di Sun, and Qing Wang. Novel Pressure-Based Optimization Method Using Deep Learning Techniques.AIAA Journal, 62(2):708–724, February 2024
work page 2024
-
[17]
Generalizable Multifidelity Aerodynamic Wing Shape Design Optimization.Journal of Aircraft, 2025
Aobo Yang, Jichao Li, and Rhea P Liem. Generalizable Multifidelity Aerodynamic Wing Shape Design Optimization.Journal of Aircraft, 2025
work page 2025
-
[18]
Neil Wu, Charles A. Mader, and Joaquim R. R. A. Martins. Sensitivity-Based Geometric Parametrization and Automatic Scaling for Aerodynamic Shape Optimization.AIAA Journal, 62(1):231–246, January 2024
work page 2024
-
[19]
Yan Chen, Jichao Li, and Jinsheng Cai. Aerodynamic shape optimization of hypersonic aircraft using data-driven generative nonlinear parameterization.Chinese Journal of Aeronautics, page 103924, November 2025
work page 2025
-
[20]
Yunjia Yang, Runze Li, Yufei Zhang, and Haixin Chen. Uncertainty-aware data-based method for fast and reliable shape optimization.Structural and Multidisciplinary Optimization, 69(4):95, April 2026
work page 2026
-
[21]
Nobuyuki Umetani and Bernd Bickel. Learning three-dimensional flow for interactive aerody- namic design.ACM Transactions on Graphics, 37(4):1–10, August 2018. 38
work page 2018
-
[22]
Fabian Paischer, Leo Cotteleer, Yann Dreze, Richard Kurle, Dylan Rubini, Maurits Bleeker, Tobias Kronlachner, and Johannes Brandstetter. Going with the speed of sound: Pushing neural surrogates into highly-turbulent transonic regimes, 2025
work page 2025
-
[23]
Neil Ashton, Charles Mockett, Marian Fuchs, Louis Fliessbach, Hendrik Hetmann, Thilo Knacke, Norbert Sch¨ onwald, Vangelis Skaperdas, Grigoris Fotiadis, Astrid Walle, Burkhard Hupertz, Danielle C. Maddix, and Peter Yu. DrivAerML: High-Fidelity Computational Fluid Dynamics Dataset for Road-Car External Aerodynamics. InForty-second International Con- ferenc...
work page 2025
-
[24]
Jacques Peter, Quentin Bennehard, S´ ebastien Heib, Jean-Luc Hantrais-Gervois, and Fr´ ed´ eric Mo¨ ens. ONERA’s CRM WBPN database for machine learning activities, related regression challenge and first results.Computers & Fluids, 302:106838, November 2025
work page 2025
-
[25]
Transolver: A fast transformer solver for PDEs on general geometries
Haixu Wu, Huakun Luo, Haowen Wang, Jianmin Wang, and Mingsheng Long. Transolver: A fast transformer solver for PDEs on general geometries. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[26]
Poseidon: Efficient foundation models for pdes
Maximilian Herde, Bogdan Raonic, Tobias Rohner, Roger K¨ appeli, Roberto Molinaro, Em- manuel de B´ ezenac, and Siddhartha Mishra. Poseidon: Efficient foundation models for pdes. InNeurIPS, 2024
work page 2024
-
[27]
Bonan Xu, Yuanye Zhou, and Xin Bian. Self-supervised learning based on Transformer for flow reconstruction and prediction.Physics of Fluids, 36(2):023607, February 2024
work page 2024
-
[28]
PDE-transformer: Efficient and versatile transformers for physics simulations
Benjamin Holzschuh, Qiang Liu, Georg Kohl, and Nils Thuerey. PDE-transformer: Efficient and versatile transformers for physics simulations. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[29]
Unisolver: PDE- conditional transformers towards universal neural PDE solvers
Hang Zhou, Yuezhou Ma, Haixu Wu, Haowen Wang, and Mingsheng Long. Unisolver: PDE- conditional transformers towards universal neural PDE solvers. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[30]
Mmet: A multi-input and multi-scale transformer for efficient pdes solving
Yichen Luo, Jia Wang, Dapeng Lan, Yu Liu, and Zhibo Pang. Mmet: A multi-input and multi-scale transformer for efficient pdes solving. InIJCAI, pages 7634–7642, 2025
work page 2025
-
[31]
Yang Shen, Hao Zhang, Wei Huang, Chao-yang Liu, and Zhen-guo Wang. Geometric- perspective transfer learning for fast aerodynamic prediction in few-shot tasks.Physical Review Fluids, 9(10):104101, October 2024
work page 2024
-
[32]
Hao Zhang, Yang Shen, Wei Huang, Zan Xie, and Yao-bin Niu. Deep transfer learning for three-dimensional aerodynamic pressure prediction under data scarcity.Theoretical and Applied Mechanics Letters, 15(2):100571, March 2025. 39
work page 2025
-
[33]
Haitao Lin, Xu Wang, and Weiwei Zhang. Transferable scaling function learning method for knowledge embedded aerodynamic database construction.Aerospace Science and Technology, 176:112097, September 2026
work page 2026
-
[34]
Bingchen Du, Zhiliang Lu, Tongqing Guo, Di Zhou, and Qiaozhong Li. Modification of the Class-Shape-Transformation Parameterization Based on Radial Basis Functions.Journal of Aircraft, 61(2):451–469, March 2024
work page 2024
-
[35]
Hairun Xie, Jing Wang, and Miao Zhang. Parametric generative schemes with geometric constraints for encoding and synthesizing airfoils.Engineering Applications of Artificial Intel- ligence, 128:107505, February 2024
work page 2024
-
[36]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In31st Conference on Neural Information Processing Systems (NIPS 2017), pages 1–11, 2017
work page 2017
-
[37]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInternational Conference on Learning Representations, 2021
work page 2021
-
[38]
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9992–10002, Mon- treal, QC, Canada, October 2021. IEEE
work page 2021
-
[39]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable Diffusion Models with Transformers. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 4172–4182, Paris, France, October 2023. IEEE
work page 2023
-
[40]
ConFIG: Towards Conflict-free Training of Physics Informed Neural Networks
Qiang Liu, Mengyu Chu, and Nils Thuerey. ConFIG: Towards Conflict-free Training of Physics Informed Neural Networks. InThe Thirteenth International Conference on Learning Repre- sentations, 2025
work page 2025
-
[41]
On the difficulty of training recurrent neural networks
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks. In Sanjoy Dasgupta and David McAllester, editors,Proceedings of the 30th International Conference on Machine Learning, volume 28 ofProceedings of Machine Learning Research, pages 1310–1318. PMLR, 2013
work page 2013
-
[42]
To- wards a Unified View of Parameter-Efficient Transfer Learning
Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. To- wards a Unified View of Parameter-Efficient Transfer Learning. InICLR 2022, 2022. 40
work page 2022
-
[43]
Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. In International Conference on Learning Representations, 2022
work page 2022
-
[44]
Su- perwing: a comprehensive transonic wing dataset for data-driven aerodynamic design, 2025
Yunjia Yang, Weishao Tang, Mengxin Liu, Nils Thuerey, Yufei Zhang, and Haixin Chen. Su- perwing: a comprehensive transonic wing dataset for data-driven aerodynamic design, 2025
work page 2025
-
[45]
Development of a Common Research Model for Applied CFD Validation Studies
John Vassberg, Mark Dehaan, Melissa Rivers, and Richard Wahls. Development of a Common Research Model for Applied CFD Validation Studies. In26th AIAA Applied Aerodynamics Conference, Honolulu, Hawaii, August 2008. American Institute of Aeronautics and Astronau- tics
work page 2008
-
[46]
Charles A. Mader, Gaetan K. W. Kenway, Anil Yildirim, and Joaquim R. R. A. Martins. AD- flow: An Open-Source Computational Fluid Dynamics Solver for Aerodynamic and Multidis- ciplinary Optimization.Journal of Aerospace Information Systems, 17(9):508–527, September 2020
work page 2020
-
[47]
Yunjia Yang, Runze Li, Yufei Zhang, Lu Lu, and Haixin Chen. Transferable machine learning model for the aerodynamic prediction of swept wings.Physics of Fluids, 36(7):076105, July 2024
work page 2024
-
[48]
Yunjia Yang, Runze Li, Yufei Zhang, Lu Lu, and Haixin Chen. Rapid aerodynamic prediction of swept wings via physics-embedded transfer learning.AIAA Journal, 63(6):2545–2559, 2025. Publisher: American Institute of Aeronautics and Astronautics
work page 2025
-
[49]
Rapid aerodynamic prediction for wings via physics-embedded transformer
Yunjia Yang, Weishao Tang, Haixin Chen, and Yufei Zhang. Rapid aerodynamic prediction for wings via physics-embedded transformer. In11th European Conference for Aeronautics and Space Sciences (EUCASS), 2025
work page 2025
-
[50]
Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020
work page 2020
-
[51]
Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008. Appendix A. Dimensionality reduction analysis of the wing shapes In the proposed framework, the pre-training dataset is designed to cover a broad range of wing geometries with moderate geometric fidelity, while the fine-tuning datase...
work page 2008
-
[52]
We perform PCA on the flattened grid points of the wing shapes
PCA PCA provides a linear estimate of the intrinsic dimensionality of the dataset by analyzing the variance captured by orthogonal modes. We perform PCA on the flattened grid points of the wing shapes. Before applying PCA, all parameters are standardized to zero mean and unit variance to ensure that parameters with different physical scales contribute equ...
-
[53]
Visualization witht-distributed Stochastic Neighbor Embedding To further examine the relationship between the pre-training and fine-tuning datasets, we employ t-distributed Stochastic Neighbor Embedding (t-SNE) [51], a nonlinear dimensionality reduction method that is particularly effective at preserving local neighborhood structure in high-dimensional da...
-
[54]
Baseline models for prediction of surface flow We use the U-Net, ViT, and the Transolver for the baseline of surface-flow prediction. Consid- ering the principle above, we control all model capacity by adjusting the hidden dimensionN hidden 43 such that the total number of trainable parameters is of the same order (approximately 1M) as the S-size AeroTran...
work page 2048
-
[55]
They directly predict aerodynamic co- efficients from geometric parameters rather than from meshes
Baseline models for prediction of aerodynamic coefficients Random Forest (RF) and Light Gradient Boosting Machine (LGBM) are used as two non-neural baselines for the geometry-to-performance prediction task. They directly predict aerodynamic co- efficients from geometric parameters rather than from meshes. To ensure all inputs and outputs were on the same ...
-
[56]
Total training steps To assess the effect of training steps on the performance of the pre-trained model, we conducted a pre-experiment using the L-size AeroTransformer on the full pre-training dataset. Models are trained with different numbers of optimization steps, ranging from 36.6k to 585.6k, while all other training settings remain identical. Figure C...
-
[57]
Gradient clipping The stability of the gradient plays a critical role in training, especially for large models. In Fig. C2, we show the loss on the validation samples during the training of an S-size and L- size AeroTransformer with a full pre-training dataset. The two models are trained with the same settings, i.e., a maximum learning rate of 10−3, the d...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.