Recognition: unknown
LoRaQ: Optimized Low Rank Approximation for 4-bit Quantization
Pith reviewed 2026-05-10 05:30 UTC · model grok-4.3
The pith
LoRaQ optimizes low-rank branches in a data-free way so they can themselves be quantized, creating the first fully sub-16-bit pipeline for diffusion transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
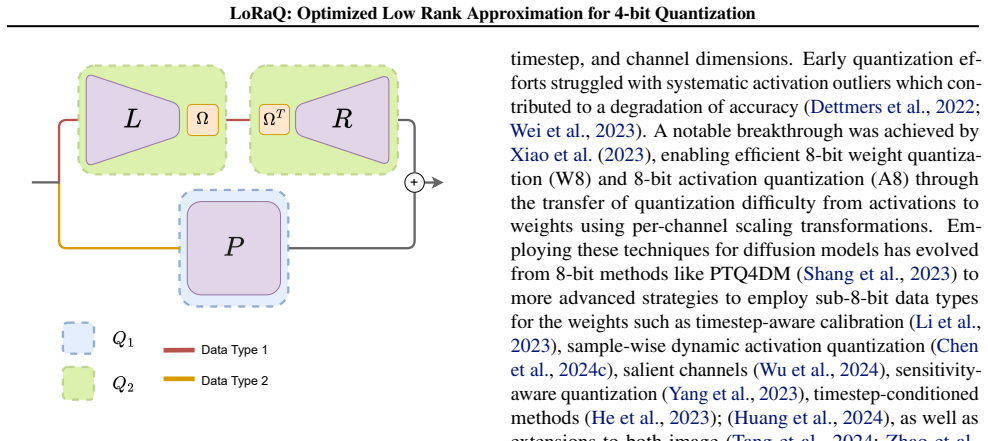
LoRaQ performs data-free optimization of a low-rank approximation branch appended to each linear layer so that the branch compensates for 4-bit quantization error even after the branch itself is quantized to low precision. This produces the first end-to-end sub-16-bit architecture for diffusion transformers. On Pixart-Σ and SANA, the method exceeds the performance of prior low-rank compensation techniques run in their native high-precision configurations while using identical memory overhead, and it supports mixed-precision branch settings such as W8A8, W6A6, or W4A8 that remain fully quantized.
What carries the argument
Data-free optimization of a low-rank approximation branch that minimizes residual quantization error and can itself be quantized without high-precision fallback.
If this is right
- Diffusion transformers can be deployed with every matrix multiplication in sub-16-bit arithmetic.
- Low-rank compensation no longer requires a separate high-precision compute path.
- Memory-constrained hardware can run larger models at 4-bit base precision without the usual quality collapse.
- Mixed-precision schedules become possible where the main layer stays at 4 bits and the branch uses slightly higher but still quantized formats.
- No calibration dataset is needed to initialize or tune the compensation branch.
Where Pith is reading between the lines
- The same optimization could be applied to other transformer families or to lower bit-widths such as 3-bit or 2-bit if the low-rank rank is increased modestly.
- Hardware that supports native low-bit matrix multiplication would gain more from this approach than from methods that still need 16-bit paths.
- Because calibration data is removed, the technique may transfer more readily to on-device or privacy-sensitive settings.
- Combining LoRaQ with other compression stages such as pruning or knowledge distillation could compound the memory savings.
Load-bearing premise
A low-rank approximation found without data can still correct most of the error introduced by 4-bit quantization once that same low-rank branch is also quantized.
What would settle it
Measure generative quality on Pixart-Σ or SANA when the LoRaQ branch is forced to 4-bit weights and activations versus when it is left at 16-bit; if the 4-bit version shows no improvement over plain 4-bit quantization or is clearly worse than the 16-bit version, the central claim fails.
Figures






read the original abstract
Post-training quantization (PTQ) is essential for deploying large diffusion transformers on resource-constrained hardware, but aggressive 4-bit quantization significantly degrades generative performance. Low-rank approximation methods have emerged as a promising solution by appending auxiliary linear branches to restore performance. However, current state-of-the-art approaches assume these branches must retain high precision (W16A16) and rely on heavy, data-dependent calibration for initialization. We challenge both limitations with LoRaQ (Low-Rank Approximated Quantization), a simple, data-free calibration approach that optimizes quantization error compensation. By overcoming the need for high-precision branches, LoRaQ enables the first fully sub-16 bit pipeline, allowing the low-rank branch itself to be quantized. We demonstrate that, at equal memory overhead, LoRaQ outperforms the state-of-the-art methods in their native implementations on Pixart-$\Sigma$ and SANA. We also analyze mixed-precision configurations, showing that setups such as W8A8, W6A6, and W4A8 for the low-rank branch, alongside a W4 main layer, yield superior results while maintaining a fully quantized architecture compatible with modern mixed-precision hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LoRaQ, a data-free post-training quantization method that uses optimized low-rank approximation to compensate for errors in 4-bit quantized weights of diffusion transformers. It claims to remove the need for high-precision (W16A16) auxiliary branches by quantizing the low-rank factors themselves, enabling the first fully sub-16-bit pipeline. Experiments on Pixart-Σ and SANA reportedly show that LoRaQ outperforms prior low-rank PTQ methods at equal memory cost, with additional analysis of mixed-precision configurations (e.g., W8A8/W6A6/W4A8 for the branch alongside W4 main weights).
Significance. If the central claim holds with rigorous evidence, the result would be significant for efficient deployment of large generative models: it removes a key practical barrier (high-precision branches and data-dependent calibration) while maintaining or improving quality at 4-bit, directly enabling hardware-friendly mixed-precision execution. The data-free nature and explicit support for quantizing the compensation branch itself would be a clear advance over existing low-rank PTQ approaches.
major comments (3)
- [§3] §3 (Method), optimization objective: the description of the data-free low-rank solve (minimizing quantization error compensation) does not specify whether the objective includes the quantization operators on the auxiliary factors A and B during optimization or applies them only after the fact. If the latter, the claim that Q(W) + Q(A)Q(B) restores performance requires an explicit error analysis or bound showing that the post-quantization residual remains negligible; without this, the fully sub-16-bit pipeline claim rests on an unverified assumption.
- [§4] §4 (Experiments), quantitative results: the abstract and summary claim outperformance over SOTA at equal memory overhead on Pixart-Σ and SANA, yet the provided text supplies no tables, FID/IS scores, error bars, or ablation details on the low-rank rank choice, calibration data (none), or exact bit-width configurations. These metrics are load-bearing for the central claim and must be presented with full experimental setup to allow assessment.
- [§3.1–3.2] §3.1–3.2, mixed-precision analysis: the paper states that W8A8/W6A6/W4A8 branches with W4 main weights yield superior results while remaining fully quantized, but provides no derivation or ablation demonstrating that the low-rank optimization remains stable under these reduced-precision constraints on the branch; this is required to support the “first fully sub-16-bit pipeline” assertion.
minor comments (2)
- [Abstract] Abstract: the notation “Pixart-Σ” uses an unrendered LaTeX macro; ensure consistent rendering of model names throughout.
- [§3] Notation: define the precise form of the low-rank factors (e.g., whether AB or A·B with specific shapes) and the quantization function Q(·) at first use in §3 to avoid ambiguity when discussing Q(A)Q(B).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify key aspects of our work. We address each major comment point-by-point below, providing clarifications from the manuscript and outlining planned revisions to strengthen the presentation.
read point-by-point responses
-
Referee: [§3] §3 (Method), optimization objective: the description of the data-free low-rank solve (minimizing quantization error compensation) does not specify whether the objective includes the quantization operators on the auxiliary factors A and B during optimization or applies them only after the fact. If the latter, the claim that Q(W) + Q(A)Q(B) restores performance requires an explicit error analysis or bound showing that the post-quantization residual remains negligible; without this, the fully sub-16-bit pipeline claim rests on an unverified assumption.
Authors: In LoRaQ, the low-rank factors A and B are optimized in full precision by minimizing the Frobenius norm of the residual quantization error ||W − Q(W) − AB||_F (data-free, using only the weight matrix itself). Quantization is applied to A and B only after this optimization step, enabling the fully sub-16-bit claim. We acknowledge that an explicit error bound or analysis of the post-quantization residual would strengthen the argument, particularly given the smaller dynamic range of the low-rank correction. We will revise §3 to explicitly state the optimization procedure and add a short paragraph providing either a simple bound (leveraging the fact that the low-rank factors capture only the error residual) or supporting empirical verification. revision: yes
-
Referee: [§4] §4 (Experiments), quantitative results: the abstract and summary claim outperformance over SOTA at equal memory overhead on Pixart-Σ and SANA, yet the provided text supplies no tables, FID/IS scores, error bars, or ablation details on the low-rank rank choice, calibration data (none), or exact bit-width configurations. These metrics are load-bearing for the central claim and must be presented with full experimental setup to allow assessment.
Authors: Section 4 of the manuscript reports FID scores, comparisons against prior low-rank PTQ methods at equal memory cost, and results on both Pixart-Σ and SANA. The data-free nature (no calibration data) and rank choices are described in the experimental setup. However, we agree that additional tables with error bars, explicit rank ablations, and tabulated bit-width configurations would improve accessibility and rigor. We will expand §4 with these details and a more complete experimental protocol in the revision. revision: partial
-
Referee: [§3.1–3.2] §3.1–3.2, mixed-precision analysis: the paper states that W8A8/W6A6/W4A8 branches with W4 main weights yield superior results while remaining fully quantized, but provides no derivation or ablation demonstrating that the low-rank optimization remains stable under these reduced-precision constraints on the branch; this is required to support the “first fully sub-16-bit pipeline” assertion.
Authors: We present empirical results in §3.1–3.2 demonstrating that W8A8, W6A6, and W4A8 branches paired with W4 main weights outperform baselines while keeping the entire model fully quantized. The optimization remains stable because it directly minimizes the error residual in a data-free manner and does not rely on activation statistics that would be sensitive to branch precision. To address the request for further support, we will add targeted ablations in the revision that vary branch precision and report optimization convergence behavior under these constraints. revision: yes
Circularity Check
No circularity in LoRaQ's optimization-based derivation
full rationale
The paper describes LoRaQ as a data-free optimization procedure that minimizes quantization error via low-rank factors, followed by empirical validation on Pixart-Σ and SANA. No equations, uniqueness theorems, or self-citations are invoked in the provided text to force the result by construction. The central claim rests on the empirical performance of the optimized low-rank compensation after quantization, without reducing to a fitted parameter renamed as a prediction or an ansatz smuggled via prior work. The derivation chain is self-contained and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https:// arxiv.org/abs/1801.01401. Black-Forest-Labs. Flux.1,
work page internal anchor Pith review arXiv
-
[2]
Chen, J., Ge, C., Xie, E., Wu, Y ., Yao, L., Ren, X., Wang, Z., Luo, P., Lu, H., and Li, Z
URL https:// blackforestlabs.ai/. Chen, J., Ge, C., Xie, E., Wu, Y ., Yao, L., Ren, X., Wang, Z., Luo, P., Lu, H., and Li, Z. Pixart-sigma: Weak-to-strong training of diffusion transformer for 4k text-to-image gen- eration. InComputer Vision – ECCV 2024: 18th Euro- pean Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part XXXII, pp. 7...
-
[3]
PixArt- Σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation
URL https:// doi.org/10.1007/978-3-031-73411-3_5. Chen, J., Jincheng, Y ., Chongjian, G., Yao, L., Xie, E., Wang, Z., Kwok, J., Luo, P., Lu, H., and Li, Z. Pixart- alpha: Fast training of diffusion transformer for photore- alistic text-to-image synthesis. InICLR, 2024b. Chen, L., Meng, Y ., Tang, C., Ma, X., Jiang, J., Wang, X., Wang, Z., and Zhu, W. Q-di...
-
[4]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
URL https://arxiv.org/abs/ 2208.07339. Esser, P., Kulal, S., Blattmann, A., Entezari, R., M ¨uller, J., Saini, H., Levi, Y ., Lorenz, D., Sauer, A., Boesel, F., Podell, D., Dockhorn, T., English, Z., and Rombach, R. Scaling rectified flow transformers for high-resolution image synthesis. InProceedings of the 41st International Conference on Machine Learni...
work page internal anchor Pith review arXiv
-
[5]
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
URL https://arxiv.org/abs/1706.08500. Ho, J., Jain, A., and Abbeel, P. Denoising diffusion proba- bilistic models. InProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY , USA,
- [6]
-
[7]
U-net: Convolu- tional networks for biomedical image segmentation
Ronneberger, O., Fischer, P., and Brox, T. U-net: Convolu- tional networks for biomedical image segmentation. In Navab, N., Hornegger, J., Wells, W. M., and Frangi, A. F. (eds.),Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, pp. 234–241, Cham,
2015
-
[8]
URL https://proceedings
PMLR. URL https://proceedings. mlr.press/v37/sohl-dickstein15.html. Tang, S., Wang, X., Chen, H., Guan, C., Wu, Z., Tang, Y ., and Zhu, W. Post-training quantization with pro- gressive calibration and activation relaxing for text- to-image diffusion models. InComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024...
2024
-
[9]
Tseng, A., Chee, J., Sun, Q., Kuleshov, V ., and De Sa, C
URL https://doi.org/ 10.1007/978-3-031-72992-8_23. Tseng, A., Chee, J., Sun, Q., Kuleshov, V ., and De Sa, C. Quip#: even better llm quantization with hadamard incoherence and lattice codebooks. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org,
-
[10]
cc/paper_files/paper/2017/file/ 3f5ee243547dee91fbd053c1c4a845aa-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2017/file/ 3f5ee243547dee91fbd053c1c4a845aa-Paper. pdf. Wei, X., Zhang, Y ., Zhang, X., Gong, R., Zhang, S., Zhang, Q., Yu, F., and Liu, X. Outlier suppression: Pushing the limit of low-bit transformer language models,
2017
-
[11]
Wu, J., Wang, H., Shang, Y ., Shah, M., and Yan, Y
URL https://arxiv.org/abs/2209.13325. Wu, J., Wang, H., Shang, Y ., Shah, M., and Yan, Y . Ptq4dit: Post-training quantization for diffusion transformers. In NeurIPS,
-
[12]
URLhttps://arxiv.org/abs/2405.17873. Zhao, T., Fang, T., Huang, H., Wan, R., Soedarmadji, W., Liu, E., Li, S., Lin, Z., Dai, G., Yan, S., Yang, H., Ning, X., and Wang, Y . Vidit-q: Efficient and accu- rate quantization of diffusion transformers for image and 10 LoRaQ: Optimized Low Rank Approximation for 4-bit Quantization video generation. InThe Thirteen...
-
[13]
Smoothing CalibrationFollowing Li et al. (2025), the smoothing calibration, done prior to any other calibration technique, finds a per-channel vectorγ∈R b where∀i∈[0, d[: γi = maxj(|Xj,i|)α maxj(|Wi,j|)β where α and β are migration strengths (Xiao et al., 2023). The best migration strengths are decided for each layer to minimize the output mean squared er...
2025
-
[14]
We thus increase the rank used during the smoothing calibration proportionnaly to the rank of the low-rank matrices optimized by LoRaQ
Section 4.3.2 increases the rank for a fixed data format applied to the low-rank matrices. We thus increase the rank used during the smoothing calibration proportionnaly to the rank of the low-rank matrices optimized by LoRaQ. OptimizationWe optimize Equation 4 with Adam using a learning rate of 10−3 for FP formats and 10−4 for INT format. The optimizatio...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.