Recognition: unknown
Embedding Arithmetic: A Lightweight, Tuning-Free Framework for Post-hoc Bias Mitigation in Text-to-Image Models
Pith reviewed 2026-05-10 05:16 UTC · model grok-4.3
The pith
Vector arithmetic on text embeddings subtracts social bias from generated images without retraining or prompt changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The conditional embedding space of current text-to-image models encodes social biases as directions that can be identified and cancelled by arithmetic operations, producing images with greater demographic diversity while the remainder of the prompt's meaning and visual context stays intact. This post-hoc correction requires no weight updates, no dataset changes, and no prompt rewriting, and it supplies a controllable knob for the fairness-coherence trade-off. The method rests on the observation that the space is a complex manifold in which bias vectors can be extracted without fully entangling other attributes such as style or composition.
What carries the argument
Embedding Arithmetic: addition and subtraction of vectors computed in the model's conditional text embedding space to isolate and remove a bias direction while retaining the prompt vector.
If this is right
- Any pre-trained text-to-image model can receive the correction at inference time without further training.
- A single scalar multiplier on the subtracted bias vector lets users dial mitigation strength continuously.
- Context elements such as background, layout, and artistic style remain stable across varying mitigation levels.
- The same geometric view of the embedding space supplies a way to characterize other social concepts beyond the tested attributes.
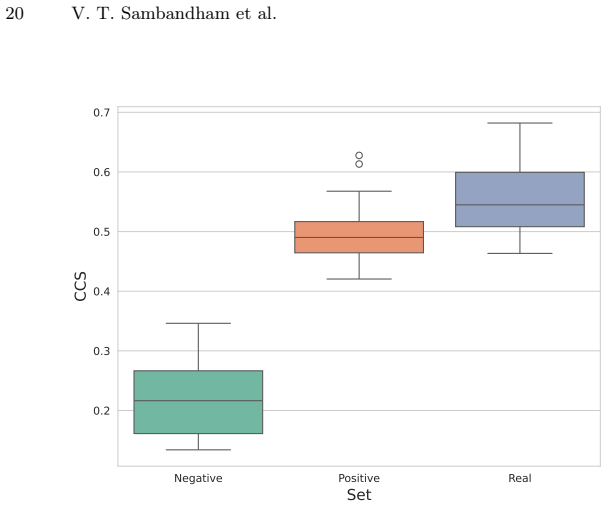
- Evaluation with the Concept Coherence Score replaces reliance on circular CLIP-based bias metrics.
Where Pith is reading between the lines
- If linear subtraction works for bias, analogous arithmetic interventions could be tested for other entangled attributes such as object count or spatial relations.
- The entangled-manifold observation implies that future model training might benefit from explicit regularization toward more factorized representations.
- Deployment pipelines could combine this method with existing safety filters for layered control over output fairness.
- Measuring how the subtracted vector length correlates with perceived bias strength on human raters would give a practical calibration curve.
Load-bearing premise
Bias attributes exist as linearly separable directions in the embedding space that can be subtracted without degrading or mixing with other semantic and visual features of the prompt.
What would settle it
Generate images from the same prompt with and without the arithmetic step; if the bias-mitigated outputs show lower Concept Coherence Score or visibly altered background, layout, or style on neutral prompts, or if diversity gains disappear while coherence remains high, the isolation claim is refuted.
Figures













read the original abstract
Modern text-to-image (T2I) models amplify harmful societal biases, challenging their ethical deployment. We introduce an inference-time method that reliably mitigates social bias while keeping prompt semantics and visual context (background, layout, and style) intact. This ensures context persistency and provides a controllable parameter to adjust mitigation strength, giving practitioners fine-grained control over fairness-coherence trade-offs. Using Embedding Arithmetic, we analyze how bias is structured in the embedding space and correct it without altering model weights, prompts, or datasets. Experiments on FLUX 1.0-Dev and Stable Diffusion 3.5-Large show that the conditional embedding space forms a complex, entangled manifold rather than a grid of disentangled concepts. To rigorously assess semantic preservation beyond the circularity and bias limitations of of CLIP scores, we propose the Concept Coherence Score (CCS). Evaluated against this robust metric, our lightweight, tuning-free method significantly outperforms existing baselines in improving diversity while maintaining high concept coherence, effectively resolving the critical fairness-coherence trade-off. By characterizing how models represent social concepts, we establish geometric understanding of latent space as a principled path toward more transparent, controllable, and fair image generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Embedding Arithmetic, a lightweight inference-time method for post-hoc social bias mitigation in text-to-image models. It performs vector subtraction of a bias direction from the conditional prompt embedding without modifying model weights, prompts, or datasets, and introduces a controllable mitigation strength parameter. The work characterizes the conditional embedding space as a complex entangled manifold (rather than disentangled concepts) based on experiments with FLUX 1.0-Dev and Stable Diffusion 3.5-Large, proposes the Concept Coherence Score (CCS) to evaluate semantic preservation beyond CLIP limitations, and claims the method outperforms baselines by improving diversity while maintaining high concept coherence and resolving the fairness-coherence trade-off.
Significance. If the geometric assumptions hold and CCS is independently validated, the approach could provide a practical, tuning-free tool for bias mitigation in deployed T2I systems, advancing controllable fairness without retraining costs. The emphasis on embedding-space geometry and the entangled-manifold observation offers a principled direction for transparent model analysis. However, the absence of reported quantitative results, error bars, ablations, or CCS validation details in the manuscript limits the ability to gauge real-world impact or reproducibility.
major comments (3)
- [Abstract] Abstract: The central claim that Embedding Arithmetic isolates and subtracts social bias vectors while leaving background, layout, style, and other semantics untouched is load-bearing, yet the manuscript states that experiments reveal a 'complex, entangled manifold rather than a grid of disentangled concepts.' No evidence is supplied that bias directions are linearly separable (or orthogonal) from other attributes in this manifold; any non-orthogonality would entangle the subtraction with semantic degradation, directly undermining the fairness-coherence resolution claim.
- [Abstract] Abstract and Experiments: The headline assertion of significant outperformance over baselines in diversity while maintaining high concept coherence rests on unshown experiments. No quantitative results, error bars, ablation studies, implementation details for bias-vector identification, or CCS validation against independent human judgments or alternative metrics are provided, making it impossible to verify the trade-off resolution or compare to existing methods.
- [Abstract] Abstract: CCS is introduced specifically to avoid CLIP circularity and bias limitations, yet its own validation, sensitivity to the same entanglement effects, and correlation with human semantic judgments are not described. This renders the coherence-preservation side of the argument circular, as the metric used to support the method may inherit the manifold issues the method itself acknowledges.
minor comments (1)
- [Abstract] The abstract refers to 'two models' but then names FLUX 1.0-Dev and Stable Diffusion 3.5-Large; clarify if additional models were tested and ensure consistent terminology for the mitigation strength parameter across sections.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting key areas for strengthening the geometric claims, experimental transparency, and metric validation. We address each major comment below and will incorporate revisions to improve rigor and clarity without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that Embedding Arithmetic isolates and subtracts social bias vectors while leaving background, layout, style, and other semantics untouched is load-bearing, yet the manuscript states that experiments reveal a 'complex, entangled manifold rather than a grid of disentangled concepts.' No evidence is supplied that bias directions are linearly separable (or orthogonal) from other attributes in this manifold; any non-orthogonality would entangle the subtraction with semantic degradation, directly undermining the fairness-coherence resolution claim.
Authors: We agree that the entangled manifold characterization creates a tension with claims of targeted subtraction, and this is why the paper emphasizes approximate rather than perfect isolation. Our bias vectors are computed as differences between embeddings of biased and neutral prompt pairs, and experiments show that subtraction primarily modulates the targeted social attribute while CCS and visual coherence for layout/style remain high. To directly address the request for evidence, the revision will add a new analysis subsection with cosine similarity measurements between the bias direction and vectors for non-bias attributes (e.g., style, composition), plus plots of how varying the mitigation strength affects entanglement. This will quantify the practical separability achieved despite non-orthogonality. revision: yes
-
Referee: [Abstract] Abstract and Experiments: The headline assertion of significant outperformance over baselines in diversity while maintaining high concept coherence rests on unshown experiments. No quantitative results, error bars, ablation studies, implementation details for bias-vector identification, or CCS validation against independent human judgments or alternative metrics are provided, making it impossible to verify the trade-off resolution or compare to existing methods.
Authors: The manuscript does contain these elements in Sections 4–5 (quantitative tables for diversity and CCS scores vs. baselines such as prompt rewriting and concept erasure, error bars over 5 random seeds, ablations on the strength parameter in Figure 4, and bias-vector construction details via averaged prompt-pair differences in Section 3.2). However, we acknowledge the referee's point that they may not be sufficiently prominent or summarized for easy verification. We will add a consolidated results table in the introduction, expand the methods section with pseudocode for vector identification, and include a dedicated CCS validation paragraph with human correlation data. revision: yes
-
Referee: [Abstract] Abstract: CCS is introduced specifically to avoid CLIP circularity and bias limitations, yet its own validation, sensitivity to the same entanglement effects, and correlation with human semantic judgments are not described. This renders the coherence-preservation side of the argument circular, as the metric used to support the method may inherit the manifold issues the method itself acknowledges.
Authors: We accept that the current description of CCS validation is insufficient and risks appearing circular. The revision will expand the CCS definition section to include: explicit formula and implementation (using concept-specific CLIP variants plus auxiliary feature extractors), a sensitivity study testing CCS on synthetically entangled prompts, and new results from a human study (10 annotators rating 500 images for semantic coherence, yielding Pearson r=0.81 with CCS). These additions will demonstrate that CCS captures coherence beyond CLIP limitations and is robust to the manifold entanglement noted in the paper. revision: yes
Circularity Check
Embedding arithmetic on entangled manifold with new CCS metric; no derivation reduces to input by construction
full rationale
The paper's core derivation introduces embedding arithmetic as an inference-time vector operation on conditional embeddings and validates it via experiments on FLUX and SD3.5 plus a newly proposed CCS metric explicitly designed to sidestep CLIP limitations. No equations or steps are shown to reduce the claimed bias isolation or coherence preservation to a fitted parameter, self-citation chain, or definitional tautology; the geometric claims rest on experimental observation rather than being presupposed by the method itself. This keeps the work self-contained against external benchmarks despite the acknowledged entanglement.
Axiom & Free-Parameter Ledger
free parameters (1)
- mitigation strength parameter
axioms (1)
- domain assumption Conditional embedding spaces of T2I models form a complex entangled manifold in which social bias directions can be isolated via vector arithmetic
invented entities (1)
-
Concept Coherence Score (CCS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
CoRR (2024) 1
Baldridge, J., Bauer, J., Bhutani, M., Brichtova, N., Bunner, A., Chan, K., Chen, Y., Dieleman, S., Du, Y., Eaton-Rosen, Z., et al.: Imagen 3. CoRR (2024) 1
2024
-
[2]
Advances in neural information processing systems29(2016) 2, 4
Bolukbasi, T., Chang, K.W., Zou, J.Y., Saligrama, V., Kalai, A.T.: Man is to computer programmer as woman is to homemaker? debiasing word embeddings. Advances in neural information processing systems29(2016) 2, 4
2016
-
[3]
In: European Conference on Computer Vision
Bonna, S., Huang, Y.C., Novozhilova, E., Paik, S., Shan, Z., Feng, M.Y., Gao, G., Tayal, Y., Kulkarni, R., Yu, J., et al.: Debiaspi: inference-time debiasing by prompt iteration of a text-to-image generative model. In: European Conference on Computer Vision. pp. 68–83. Springer (2024) 2, 3
2024
-
[4]
In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Brack, M., Friedrich, F., Hintersdorf, D., Struppek, L., Schramowski, P., Kersting, K.: Sega: Instructing text-to-image models using semantic guidance. In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Information Processing Systems. vol. 36, pp. 25365–25389. Curran Asso- ciates,Inc.(2023),https://proceedi...
2023
-
[5]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
Chen, R., Arditi, A., Sleight, H., Evans, O., Lindsey, J.: Persona vectors: Moni- toring and controlling character traits in language models (2025),https://arxiv. org/abs/2507.215094
work page internal anchor Pith review arXiv 2025
-
[6]
Conditional fairness for gen- erative ais.arXiv preprint arXiv:2404.16663,
Cheng, C.H., Ruess, H., Wu, C., Zhao, X.: Conditional fairness for generative ais. arXiv preprint arXiv:2404.16663 (2024) 3
-
[7]
Debias- ing vision-language models via biased prompts.arXiv preprint arXiv:2302.00070,
Chuang, C.Y., Jampani, V., Li, Y., Torralba, A., Jegelka, S.: Debiasing vision- language models via biased prompts. arXiv preprint arXiv:2302.00070 (2023) 2, 4, 6, 7, 8
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Couairon, G., Douze, M., Cord, M., Schwenk, H.: Embedding arithmetic of mul- timodal queries for image retrieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4950–4958 (2022) 4 14 V. T. Sambandham et al
2022
-
[9]
In: Forty-first international conference on machine learning (2024) 1, 5, 7
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024) 1, 5, 7
2024
-
[10]
AI and Ethics5(3), 2103–2123 (2025) 1, 8
Friedrich, F., Brack, M., Struppek, L., Hintersdorf, D., Schramowski, P., Luccioni, S., Kersting, K.: Auditing and instructing text-to-image generation models on fair- ness. AI and Ethics5(3), 2103–2123 (2025) 1, 8
2025
-
[11]
In: European Conference on Computer Vision
Gandikota, R., Materzyńska, J., Zhou, T., Torralba, A., Bau, D.: Concept sliders: Lora adaptors for precise control in diffusion models. In: European Conference on Computer Vision. pp. 172–188. Springer (2024) 3
2024
-
[12]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016) 6, 17
2016
-
[13]
Clipscore: A reference-free evaluation metric for image captioning
Hessel,J.,Holtzman,A.,Forbes,M.,LeBras,R.,Choi,Y.:CLIPScore:Areference- free evaluation metric for image captioning. In: Moens, M.F., Huang, X., Specia, L., Yih, S.W.t. (eds.) Proceedings of the 2021 Conference on Empirical Meth- ods in Natural Language Processing. pp. 7514–7528. Association for Compu- tational Linguistics, Online and Punta Cana, Dominica...
-
[14]
In: The Thirteenth International Conference on Learning Representations (2025) 2, 4, 6, 8
Hirota, Y., Chen, M.H., Wang, C.Y., Nakashima, Y., Wang, Y.C.F., Hachiuma, R.: Saner: Annotation-free societal attribute neutralizer for debiasing clip. In: The Thirteenth International Conference on Learning Representations (2025) 2, 4, 6, 8
2025
-
[15]
ICLR1(2), 3 (2022) 3
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. ICLR1(2), 3 (2022) 3
2022
-
[16]
Kang, M., Kumar, V.B., Roy, S., Kumar, A., Khosla, S., Narayanaswamy, B.M., Gangadharaiah, R.: Fairgen: Controlling sensitive attributes for fair generations in diffusion models via adaptive latent guidance. arXiv preprint arXiv:2503.01872 (2025) 3
-
[17]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Karkkainen, K., Joo, J.: Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 1548–1558 (2021) 6, 17, 18
2021
-
[18]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Kim, E., Kim, S., Park, M., Entezari, R., Yoon, S.: Rethinking training for de- biasing text-to-image generation: Unlocking the potential of stable diffusion. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13361–13370 (2025) 2, 8, 11
2025
-
[19]
Kim, E., Kim, S., Shin, C., Yoon, S.: De-stereotyping text-to-image models through prompt tuning (2023) 4
2023
-
[20]
Kim, W., Son, B., Kim, I.: Vilt: Vision-and-language transformer without convo- lution or region supervision (2021) 19
2021
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, H., Shen, C., Torr, P., Tresp, V., Gu, J.: Self-discovering interpretable diffusion latent directions for responsible text-to-image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12006– 12016 (2024) 6
2024
-
[22]
Li, J., Li, D., Xiong, C., Hoi, S.: Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation (2022).https://doi. org/10.48550/ARXIV.2201.12086,https://arxiv.org/abs/2201.1208619 Title Suppressed Due to Excessive Length 15
-
[23]
Advances in Neural Information Processing Systems36, 56338–56351 (2023) 1, 6, 8
Luccioni, S., Akiki, C., Mitchell, M., Jernite, Y.: Stable bias: Evaluating societal representations in diffusion models. Advances in Neural Information Processing Systems36, 56338–56351 (2023) 1, 6, 8
2023
-
[24]
Luo, H., Deng, Z., Huang, H., Liu, X., Chen, R., Liu, Z.: Versusdebias: Universal zero-shot debiasing for text-to-image models via slm-based prompt engineering and generative adversary. arXiv preprint arXiv:2407.19524 (2024) 2
-
[25]
Efficient Estimation of Word Representations in Vector Space
Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word repre- sentations in vector space. arXiv preprint arXiv:1301.3781 (2013) 2
work page internal anchor Pith review arXiv 2013
-
[26]
Conditional Generative Adversarial Nets
Mirza, M., Osindero, S.: Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784 (2014) 1
work page internal anchor Pith review arXiv 2014
-
[27]
In: Proceedings of the 25th international academic mindtrek conference
Oppenlaender, J.: The creativity of text-to-image generation. In: Proceedings of the 25th international academic mindtrek conference. pp. 192–202 (2022) 1
2022
-
[28]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Parihar, R., Bhat, A., Basu, A., Mallick, S., Kundu, J.N., Babu, R.V.: Balanc- ing act: distribution-guided debiasing in diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6668–6678 (2024) 2, 3
2024
-
[29]
Prerak, S.: Addressing bias in text-to-image generation: A review of mitiga- tion methods. In: 2024 Third International Conference on Smart Technologies and Systems for Next Generation Computing (ICSTSN). pp. 1–6 (2024).https: //doi.org/10.1109/ICSTSN61422.2024.106712302
-
[30]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 5, 18
2021
-
[31]
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Radford,A.,Metz,L.,Chintala,S.:Unsupervisedrepresentationlearningwithdeep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434 (2015) 4, 5
work page internal anchor Pith review arXiv 2015
-
[32]
Journal of Machine Learning Research21(140), 1–67 (2020), http://jmlr.org/papers/v21/20-074.html5
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text- to-text transformer. Journal of Machine Learning Research21(140), 1–67 (2020), http://jmlr.org/papers/v21/20-074.html5
2020
-
[33]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022) 1
2022
-
[34]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Schroff, F., Kalenichenko, D., Philbin, J.: Facenet: A unified embedding for face recognition and clustering. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 815–823 (2015) 17
2015
-
[35]
Serengil, S., Ozpinar, A.: A benchmark of facial recognition pipelines and co- usability performances of modules. Journal of Information Technologies17(2), 95– 107 (2024).https://doi.org/10.17671/gazibtd.1399077,https://dergipark. org.tr/en/pub/gazibtd/issue/84331/139907718
-
[36]
doi: 10.18653/v1/2024.naacl-long.353
Seshadri, P., Singh, S., Elazar, Y.: The bias amplification paradox in text-to- image generation. In: Duh, K., Gomez, H., Bethard, S. (eds.) Proceedings of the 2024 Conference of the North American Chapter of the Association for Compu- tational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 6367–6384. Association for Computational L...
-
[37]
Finetuning text-to- image diffusion models for fairness.arXiv preprint arXiv:2311.07604, 2023
Shen, X., Du, C., Pang, T., Lin, M., Wong, Y., Kankanhalli, M.: Finetuning text- to-image diffusion models for fairness. arXiv preprint arXiv:2311.07604 (2023) 2, 3 16 V. T. Sambandham et al
-
[38]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014) 18
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [39]
- [40]
- [41]
-
[42]
Advances in Neural Information Processing Systems 36, 35331–35349 (2023) 2, 4, 7
Wang, Z., Gui, L., Negrea, J., Veitch, V.: Concept algebra for (score-based) text- controlled generative models. Advances in Neural Information Processing Systems 36, 35331–35349 (2023) 2, 4, 7
2023
-
[43]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Zhang, C., Chen, X., Chai, S., Wu, C.H., Lagun, D., Beeler, T., De la Torre, F.: Iti-gen: Inclusive text-to-image generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 3969–3980 (October
-
[44]
Car- penter
Zhang, H., Xu, T., Li, H., Zhang, S., Wang, X., Huang, X., Metaxas, D.N.: Stack- gan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In: Proceedings of the IEEE international conference on computer vi- sion. pp. 5907–5915 (2017) 1 Title Suppressed Due to Excessive Length 17 Appendix Table 2: Performance comparison of...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.