Recognition: unknown
LiquidTAD: Efficient Temporal Action Detection via Parallel Liquid-Inspired Temporal Relaxation
Pith reviewed 2026-05-10 05:35 UTC · model grok-4.3
The pith
LiquidTAD turns liquid neural dynamics into a parallel operator that matches strong temporal action detection accuracy at much lower parameter and compute cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LiquidTAD distills the exponential relaxation prior of liquid neural dynamics into a fully vectorized Parallel Liquid-inspired Relaxation operator that avoids recursive ODE integration, then pairs it with a Hierarchical Decay-Rate Sharing Strategy across feature-pyramid levels to stabilize training and offset temporal downsampling.
What carries the argument
The Parallel Liquid-inspired Relaxation operator, a non-recursive matrix formulation that applies the liquid-style exponential decay to entire temporal feature sequences at once using only standard convolutions and activations.
If this is right
- Temporal action detectors can run on ordinary hardware without custom ODE solvers or heavy parameter budgets.
- Model size drops by more than 60 percent relative to ActionFormer while accuracy on THUMOS-14 remains competitive.
- Complexity grows only linearly with video length, allowing longer untrimmed sequences to be processed at fixed cost.
- Decay-rate sharing across pyramid levels compensates for compression in deeper temporal layers without extra parameters.
Where Pith is reading between the lines
- The same parallel relaxation could be tested on other long-sequence tasks such as video forecasting or audio event detection.
- Hierarchical decay sharing may offer a lightweight alternative to attention mechanisms for stabilizing multi-scale temporal networks.
- Combining the operator with quantization or pruning could push FLOPs still lower while preserving the reported accuracy.
Load-bearing premise
The parallel non-recursive version of liquid relaxation keeps the same ability to localize action boundaries that full sequential liquid dynamics would provide.
What would settle it
Replace the parallel operator inside LiquidTAD with an equivalent sequential liquid-neural-network implementation, retrain on THUMOS-14, and check whether average mAP rises, stays flat, or falls below 69.46 percent.
Figures


read the original abstract
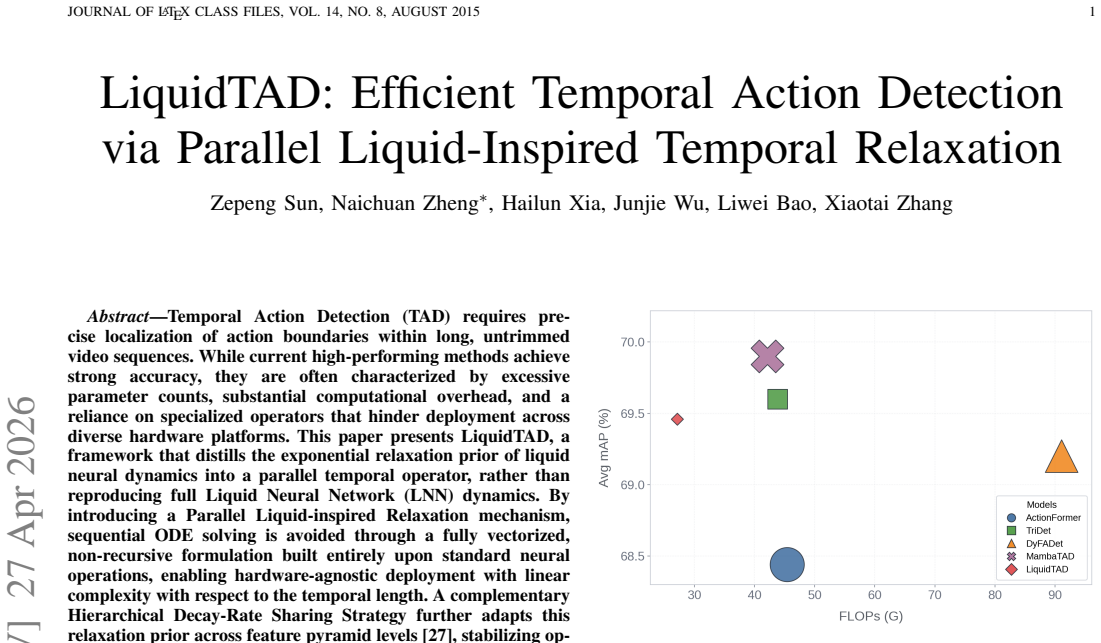
Temporal Action Detection (TAD) requires precise localization of action boundaries within long, untrimmed video sequences. While current high-performing methods achieve strong accuracy, they are often characterized by excessive parameter counts, substantial computational overhead, and a reliance on specialized operators that hinder deployment across diverse hardware platforms. This paper presents LiquidTAD, a framework that distills the exponential relaxation prior of liquid neural dynamics into a parallel temporal operator, rather than reproducing full Liquid Neural Network (LNN) dynamics. By introducing a Parallel Liquid-inspired Relaxation mechanism, sequential ODE solving is avoided through a fully vectorized, non-recursive formulation built entirely upon standard neural operations, enabling hardware-agnostic deployment with linear complexity with respect to the temporal length. A complementary Hierarchical Decay-Rate Sharing Strategy further adapts this relaxation prior across feature pyramid levels, stabilizing optimization and implicitly compensating for temporal compression in deeper layers. Experimental evaluations on THUMOS-14 and ActivityNet-1.3 demonstrate that LiquidTAD achieves accuracy competitive with strong baselines while substantially lowering the model footprint. Specifically, on THUMOS-14, LiquidTAD achieves 69.46\% average mAP with only 10.82M parameters and 27.17G FLOPs, reducing the parameter count by over 60\% compared with ActionFormer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LiquidTAD, a temporal action detection framework that distills the exponential relaxation prior of liquid neural networks into a Parallel Liquid-inspired Relaxation operator. This operator uses a fully vectorized, non-recursive formulation based on standard neural operations to avoid sequential ODE solving while maintaining linear complexity in temporal length. A Hierarchical Decay-Rate Sharing Strategy adapts the relaxation across feature pyramid levels. On THUMOS-14 the method reports 69.46% average mAP using 10.82M parameters and 27.17G FLOPs (over 60% parameter reduction versus ActionFormer), with competitive results also claimed on ActivityNet-1.3.
Significance. If the parallel relaxation operator and decay-rate sharing demonstrably retain the long-range temporal modeling advantages of full liquid neural dynamics, the work would offer a practical route to hardware-agnostic, low-footprint TAD models. The headline efficiency numbers are attractive, but the absence of ablations isolating the liquid-inspired components and the lack of any derivation or trajectory comparison leave the source of the reported accuracy unclear.
major comments (3)
- [Method section (Parallel Liquid-inspired Relaxation mechanism)] The central claim that the Parallel Liquid-inspired Relaxation preserves the temporal modeling power of liquid neural dynamics for boundary localization rests on an unverified approximation. No derivation is supplied showing that the vectorized non-recursive form yields hidden-state trajectories or long-range decay behavior comparable to sequential ODE integration (see the method description of the operator and the skeptic note on approximation quality).
- [Experiments section] No ablation studies isolate the contribution of the proposed mechanisms versus a plain efficient convolution or standard feature-pyramid baseline. Without such controls it is impossible to attribute the 69.46% mAP on THUMOS-14 to the distilled liquid prior rather than other architectural choices.
- [Experiments section (THUMOS-14 and ActivityNet-1.3 tables)] Reported results give single-point average mAP figures without error bars, multiple random seeds, or statistical tests, undermining confidence in the claimed competitiveness and efficiency gains.
minor comments (1)
- [Abstract] The abstract states linear complexity with respect to temporal length but does not specify the exact big-O notation or compare it to the complexity of the baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which have helped clarify several aspects of our work. We address each major comment point by point below, indicating where revisions have been made to the manuscript.
read point-by-point responses
-
Referee: [Method section (Parallel Liquid-inspired Relaxation mechanism)] The central claim that the Parallel Liquid-inspired Relaxation preserves the temporal modeling power of liquid neural dynamics for boundary localization rests on an unverified approximation. No derivation is supplied showing that the vectorized non-recursive form yields hidden-state trajectories or long-range decay behavior comparable to sequential ODE integration (see the method description of the operator and the skeptic note on approximation quality).
Authors: We acknowledge that the original manuscript did not provide an explicit derivation linking the parallel vectorized operator to the sequential liquid dynamics. In the revised version, we have added a derivation in Section 3.2 demonstrating that the non-recursive formulation arises from unrolling the discretized exponential relaxation ODE, which preserves the essential long-range decay properties for temporal boundary localization. We have also included a supplementary figure with trajectory comparisons on synthetic inputs to empirically support the approximation quality. revision: yes
-
Referee: [Experiments section] No ablation studies isolate the contribution of the proposed mechanisms versus a plain efficient convolution or standard feature-pyramid baseline. Without such controls it is impossible to attribute the 69.46% mAP on THUMOS-14 to the distilled liquid prior rather than other architectural choices.
Authors: We agree that isolating the liquid-inspired components via ablations is necessary to substantiate their contribution. The revised manuscript now includes dedicated ablation experiments in the Experiments section. These compare the full LiquidTAD against (i) a variant using standard 1D convolutions in place of the parallel relaxation operator and (ii) the model without hierarchical decay-rate sharing. The results show incremental gains attributable to each proposed mechanism, supporting that the distilled liquid prior drives the reported efficiency-accuracy trade-off. revision: yes
-
Referee: [Experiments section (THUMOS-14 and ActivityNet-1.3 tables)] Reported results give single-point average mAP figures without error bars, multiple random seeds, or statistical tests, undermining confidence in the claimed competitiveness and efficiency gains.
Authors: The observation regarding single-run reporting is valid and limits statistical confidence. The original submission used single-run results owing to the substantial compute required for TAD training. For the revision, we have re-evaluated the model across three random seeds on THUMOS-14 and updated the tables to report mean mAP with standard deviations. While formal statistical tests were not added due to the modest number of runs, the observed low variance bolsters reliability of the efficiency claims. revision: partial
Circularity Check
No circularity: external prior distilled via standard operations
full rationale
The paper frames LiquidTAD as distilling the exponential relaxation prior from external liquid neural dynamics (LNN) literature into a parallel non-recursive operator built on standard neural ops, avoiding ODE integration. No equations, fitting procedures, or self-referential definitions appear in the abstract or described method; the parallel relaxation and hierarchical decay sharing are presented as design choices rather than derivations that reduce to the inputs by construction. Performance claims rest on empirical benchmarks (THUMOS-14 mAP, parameter counts) against external baselines like ActionFormer, with no load-bearing self-citation chain or renamed fitted quantities. The derivation chain is self-contained against external priors and benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- decay rates
axioms (1)
- domain assumption Exponential relaxation dynamics from liquid neural networks provide useful inductive bias for modeling temporal dependencies in video features.
invented entities (1)
-
Parallel Liquid-inspired Relaxation mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
OpenTAD: A Unified Framework and Comprehensive Study of Temporal Action Detection,
S. Liu, C. Zhao, F. Zohra, M. Soldan, A. Pardo, M. Xu, L. Alssum, M. Ramazanova, J. L. Alc´azar, A. Cioppa, S. Giancola, C. Hinojosa, and B. Ghanem, “OpenTAD: A Unified Framework and Comprehensive Study of Temporal Action Detection,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), 2025, pp. 2625–2635
2025
-
[2]
Temporal Ac- tion Detection with Structured Segment Networks,
Y . Zhao, Y . Xiong, L. Wang, Z. Wu, X. Tang, and D. Lin, “Temporal Ac- tion Detection with Structured Segment Networks,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Venice, Italy, 2017, pp. 2914–2923
2017
-
[3]
BSN: Boundary Sensitive Network for Temporal Action Proposal Generation,
T. Lin, X. Zhao, H. Su, C. Wang, and M. Yang, “BSN: Boundary Sensitive Network for Temporal Action Proposal Generation,” inProc. Eur . Conf. Comput. Vis. (ECCV), Munich, Germany, 2018, pp. 3–21
2018
-
[4]
BMN: Boundary-Matching Network for Temporal Action Proposal Generation,
T. Lin, X. Liu, X. Li, E. Ding, and S. Wen, “BMN: Boundary-Matching Network for Temporal Action Proposal Generation,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Seoul, Korea, 2019, pp. 3889–3898
2019
-
[5]
Fast Learning of Temporal Action Proposal via Dense Boundary Generator,
C. Lin, J. Li, Y . Wang, Y . Tai, D. Luo, Z. Cui, C. Wang, J. Li, F. Huang, and R. Ji, “Fast Learning of Temporal Action Proposal via Dense Boundary Generator,” inProc. AAAI Conf. Artif. Intell. (AAAI), 2020, pp. 11499–11506
2020
-
[6]
G-TAD: Sub- Graph Localization for Temporal Action Detection,
M. Xu, C. Zhao, D. S. Rojas, A. Thabet, and B. Ghanem, “G-TAD: Sub- Graph Localization for Temporal Action Detection,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2020, pp. 10156–10165
2020
-
[7]
Learning Salient Boundary Feature for Anchor-free Temporal Action Localization,
C. Lin, C. Xu, D. Luo, Y . Wang, Y . Tai, C. Wang, J. Li, F. Huang, and Y . Fu, “Learning Salient Boundary Feature for Anchor-free Temporal Action Localization,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021, pp. 3320–3329
2021
-
[8]
Relaxed Transformer Decoders for Direct Action Proposal Generation,
J. Tan, J. Tang, L. Wang, and G. Wu, “Relaxed Transformer Decoders for Direct Action Proposal Generation,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 13526–13535
2021
-
[9]
Temporal Context Aggregation Network for Temporal Action Proposal Refinement,
Z. Qing, H. Su, W. Gan, D. Wang, W. Wu, X. Wang, Y . Qiao, J. Yan, C. Gao, and N. Sang, “Temporal Context Aggregation Network for Temporal Action Proposal Refinement,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021, pp. 485–494
2021
-
[10]
PointTAD: Multi-Label Temporal Action Detection with Learnable Query Points,
J. Tan, X. Zhao, X. Shi, B. Kang, and L. Wang, “PointTAD: Multi-Label Temporal Action Detection with Learnable Query Points,” inAdv. Neural Inf. Process. Syst. (NeurIPS), 2022
2022
-
[11]
ActionFormer: Localizing Moments of Actions with Transformers,
C.-L. Zhang, J. Wu, and Y . Li, “ActionFormer: Localizing Moments of Actions with Transformers,” inProc. Eur . Conf. Comput. Vis. (ECCV), Tel Aviv, Israel, 2022, pp. 492–510
2022
-
[12]
End-to- End Temporal Action Detection with Transformer,
X. Liu, Q. Wang, Y . Hu, X. Tang, S. Zhang, S. Bai, and X. Bai, “End-to- End Temporal Action Detection with Transformer,”IEEE Trans. Image Process., vol. 31, pp. 5427–5441, 2022
2022
-
[13]
TALLFormer: Temporal Action Localiza- tion with a Long-Memory Transformer,
F. Cheng and G. Bertasius, “TALLFormer: Temporal Action Localiza- tion with a Long-Memory Transformer,” inProc. Eur . Conf. Comput. Vis. (ECCV), Tel Aviv, Israel, 2022, pp. 503–521
2022
-
[14]
TriDet: Tem- poral Action Detection with Relative Boundary Modeling,
D. Shi, Y . Zhong, Q. Cao, L. Ma, J. Li, and D. Tao, “TriDet: Tem- poral Action Detection with Relative Boundary Modeling,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Vancouver, Canada, 2023, pp. 18857–18866
2023
-
[15]
Temporalmaxer: Maximize temporal context with only max pooling for temporal action localization,
T. N. Tang, K. Kim, and K. Sohn, “TemporalMaxer: Maximize Temporal Context with only Max Pooling for Temporal Action Localization,” arXiv preprint arXiv:2303.09055, 2023
-
[16]
DyFADet: Dynamic Feature Aggregation for Temporal Action Detection,
L. Yang, Z. Zheng, Y . Han, H. Cheng, S. Song, G. Huang, and F. Li, “DyFADet: Dynamic Feature Aggregation for Temporal Action Detection,” inComputer Vision–ECCV 2024, Lecture Notes in Computer Science, vol. 15104, Springer, 2025, pp. 305–322
2024
-
[17]
S. Liu, L. Sui, C.-L. Zhang, F. Mu, C. Zhao, and B. Ghanem, “Har- nessing Temporal Causality for Advanced Temporal Action Detection,” arXiv preprint arXiv:2407.17792, 2024
-
[18]
TSI: Temporal Scale Invariant Network for Action Proposal Generation,
S. Liu, X. Zhao, H. Su, and Z. Hu, “TSI: Temporal Scale Invariant Network for Action Proposal Generation,” inComputer Vision–ACCV 2020, Lecture Notes in Computer Science, vol. 12626, Springer, 2021, pp. 530–546
2020
-
[19]
Efficiently Modeling Long Sequences with Structured State Spaces,
A. Gu, K. Goel, and C. R ´e, “Efficiently Modeling Long Sequences with Structured State Spaces,” inProc. Int. Conf. Learn. Represent. (ICLR), 2022
2022
-
[20]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-Time Sequence Modeling with Selective State Spaces,”arXiv preprint arXiv:2312.00752, 2023
work page Pith review arXiv 2023
-
[21]
MambaTAD: When State-Space Models Meet Long-Range Temporal Action Detection,
H. Lu, Y . Yu, S. Lu, D. Rajan, B. P. Ng, A. C. Kot, and X. Jiang, “MambaTAD: When State-Space Models Meet Long-Range Temporal Action Detection,”IEEE Trans. Multimedia, 2025
2025
-
[22]
VideoMamba: State Space Model for Efficient Video Understanding,
K. Li, X. Li, Y . Wang, Y . He, Y . Wang, L. Wang, and Y . Qiao, “VideoMamba: State Space Model for Efficient Video Understanding,” inProc. Eur . Conf. Comput. Vis. (ECCV), 2024
2024
-
[23]
Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding,
G. Chen, Y . Huang, J. Xu, B. Pei, J. Wang, Z. Chen, Z. Li, T. Lu, K. Li, and L. Wang, “Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding,”Int. J. Comput. Vis., vol. 134, Art. no. 20, 2026, doi: 10.1007/s11263-025-02597-y
-
[24]
Liquid Time- Constant Networks,
R. Hasani, M. Lechner, A. Amini, D. Rus, and R. Grosu, “Liquid Time- Constant Networks,” inProc. AAAI Conf. Artif. Intell. (AAAI), 2021, pp. 7657–7666
2021
-
[25]
Closed-Form Continuous-Time Neural Networks,
R. Hasani, M. Lechner, A. Amini, L. Liebenwein, A. Ray, M. Tschaikowski, G. Teschl, and D. Rus, “Closed-Form Continuous-Time Neural Networks,”Nat. Mach. Intell., vol. 4, pp. 992–1003, 2022
2022
-
[26]
Neural Ordinary Differential Equations,
R. T. Q. Chen, Y . Rubanova, J. Bettencourt, and D. K. Duvenaud, “Neural Ordinary Differential Equations,” inAdv. Neural Inf. Process. Syst. (NeurIPS), 2018, pp. 6571–6583. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 8
2018
-
[27]
Feature Pyramid Networks for Object Detection,
T.-Y . Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature Pyramid Networks for Object Detection,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Honolulu, HI, USA, 2017, pp. 2117–2125
2017
-
[28]
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset,
J. Carreira and A. Zisserman, “Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Honolulu, HI, USA, 2017, pp. 6299–6308
2017
-
[29]
SlowFast Networks for Video Recognition,
C. Feichtenhofer, H. Fan, J. Malik, and K. He, “SlowFast Networks for Video Recognition,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Seoul, Korea, 2019, pp. 6202–6211
2019
-
[30]
TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks,
H. Alwassel, S. Giancola, and B. Ghanem, “TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks,” inProc. IEEE/CVF Int. Conf. Comput. Vis. Workshops (ICCVW), 2021, pp. 3173– 3183
2021
-
[31]
The THUMOS Challenge on Action Recognition for Videos ‘In the Wild’,
H. Idrees, A. R. Zamir, Y .-G. Jiang, A. Gorban, I. Laptev, R. Sukthankar, and M. Shah, “The THUMOS Challenge on Action Recognition for Videos ‘In the Wild’,”Comput. Vis. Image Underst., vol. 155, pp. 1–23, 2017
2017
-
[32]
Activi- tyNet: A Large-Scale Video Benchmark for Human Activity Understand- ing,
F. Caba Heilbron, V . Escorcia, B. Ghanem, and J. C. Niebles, “Activi- tyNet: A Large-Scale Video Benchmark for Human Activity Understand- ing,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Boston, MA, USA, 2015, pp. 961–970
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.