Recognition: unknown
Understanding the Prompt Sensitivity
Pith reviewed 2026-05-10 04:37 UTC · model grok-4.3
The pith
Large language models disperse meaning-preserving prompts rather than clustering them, which produces an excessively high upper bound on next-token log-probability differences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
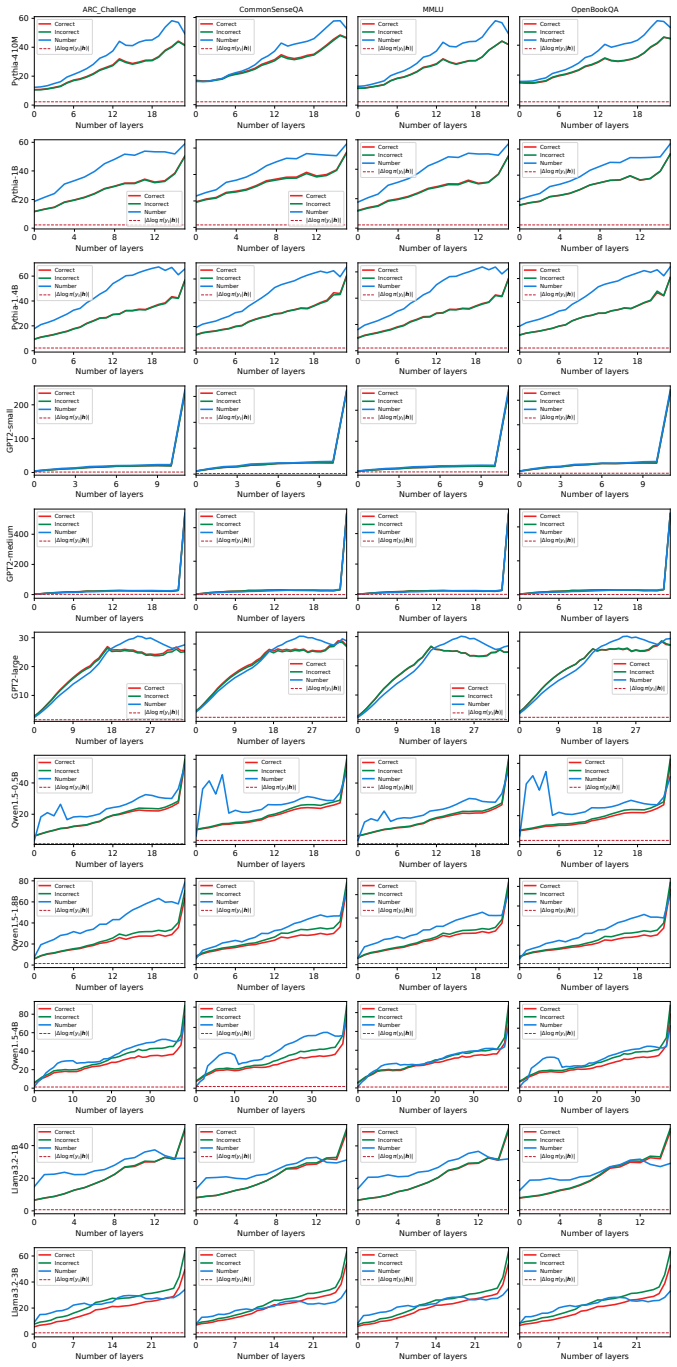
By modeling the LLM as a function and expanding the next-token log-probability around a base prompt to first order, the difference for a meaning-preserving variant is bounded above by the product of the gradient norm and the prompt difference norm via Cauchy-Schwarz. The analysis establishes that LLMs disperse rather than cluster similar inputs, yielding an upper bound that remains large and difficult to reduce to zero. Prompt templates are shown to exert stronger influence on logits than the questions themselves, and the bound correlates with PromptSensiScore while identifying higher-risk variant types.
What carries the argument
The first-order Taylor expansion of the next-token log-probability function together with the Cauchy-Schwarz inequality, which together bound probability differences in terms of input dispersion.
If this is right
- Certain categories of meaning-preserving prompt variants carry higher risk of introducing sensitivity.
- The derived upper bound correlates strongly with the existing PromptSensiScore metric.
- Prompt templates exert greater influence on logits than the questions themselves.
- The dispersing behavior prevents the log-probability difference from being reduced effectively to zero.
Where Pith is reading between the lines
- Techniques that reduce dispersion of equivalent inputs in gradient space could lower sensitivity without changing model weights.
- The same expansion and bound could be applied to diagnose sensitivity in other autoregressive sequence models.
- Measuring dispersion directly might provide a pre-deployment check for prompt stability on new models or domains.
Load-bearing premise
The first-order Taylor expansion around a prompt sufficiently approximates the relationship between meaning-preserving prompt variants and changes in next-token log probabilities for the derived bound to be informative.
What would settle it
A direct measurement of internal representations or gradients showing that meaning-preserving prompts cluster tightly rather than disperse, or a set of prompt pairs where the observed log-probability difference consistently exceeds the derived upper bound.
Figures















read the original abstract
Prompt sensitivity, which refers to how strongly the output of a large language model (LLM) depends on the exact wording of its input prompt, raises concerns among users about the LLM's stability and reliability. In this work, we consider LLMs as multivariate functions and perform a first-order Taylor expansion, thereby analyzing the relationship between meaning-preserving prompts, their gradients, and the log probabilities of the model's next token. We derive an upper bound on the difference between log probabilities using the Cauchy-Schwarz inequality. We show that LLMs do not internally cluster similar inputs like smaller neural networks do, but instead disperse them. This dispersing behavior leads to an excessively high upper bound on the difference of log probabilities between two meaning-preserving prompts, making it difficult to effectively reduce to 0. In our analysis, we also show which types of meaning-preserving prompt variants are more likely to introduce prompt sensitivity risks in LLMs. In addition, we demonstrate that the upper bound is strongly correlated with an existing prompt sensitivity metric, PromptSensiScore. Moreover, by analyzing the logit variance, we find that prompt templates typically exert a greater influence on logits than the questions themselves. Overall, our results provide a general interpretation for why current LLMs can be highly sensitive to prompts with the same meaning, offering crucial evidence for understanding the prompt sensitivity of LLMs. Code for experiments is available at https://github.com/ku-nlp/Understanding_the_Prompt_Sensitivity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models LLMs as multivariate functions and applies a first-order Taylor expansion around a prompt to relate meaning-preserving variants to changes in next-token log probabilities. It derives an upper bound on |Δlog p| via the Cauchy-Schwarz inequality, claims that LLMs disperse similar inputs (unlike smaller networks) producing an excessively high bound that cannot be reduced to zero, shows this bound correlates with PromptSensiScore, and reports that prompt templates exert greater influence on logits than the questions themselves.
Significance. If the linear approximation is valid and the dispersion claim is substantiated, the work supplies a general theoretical account of prompt sensitivity grounded in gradient behavior and logit variance, with the reported correlation to an existing metric and public code as reproducibility strengths. This could guide prompt design and stability analysis, though the significance depends on whether the bound is shown to be tight rather than merely mathematical.
major comments (2)
- [Derivation of upper bound] The derivation section (first-order Taylor expansion and Cauchy-Schwarz application): the claim that dispersing gradients produce an 'excessively high' upper bound preventing reduction to zero requires that the linear term dominate the remainder for discrete prompt edits. No quantitative bound on the Taylor remainder or empirical check of approximation error for typical meaning-preserving variants is provided, leaving open whether the bound characterizes actual Δlog p or is merely loose.
- [Empirical validation] The correlation analysis with PromptSensiScore: the paper presents the upper bound as strongly correlated with the metric but supplies no details on sample size, statistical significance testing, or controls, which weakens its role as supporting evidence for the dispersion explanation.
minor comments (2)
- [Analysis of input dispersion] Clarify the precise definition and measurement of 'dispersing behavior' versus clustering in smaller networks, including any distance metric or visualization used.
- [Logit variance analysis] The logit variance comparison between templates and questions would benefit from explicit statistical tests or effect sizes to support the claim that templates exert greater influence.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will revise the paper to incorporate additional empirical checks and statistical details where appropriate, while preserving the core theoretical contribution on gradient dispersion in LLMs.
read point-by-point responses
-
Referee: [Derivation of upper bound] The derivation section (first-order Taylor expansion and Cauchy-Schwarz application): the claim that dispersing gradients produce an 'excessively high' upper bound preventing reduction to zero requires that the linear term dominate the remainder for discrete prompt edits. No quantitative bound on the Taylor remainder or empirical check of approximation error for typical meaning-preserving variants is provided, leaving open whether the bound characterizes actual Δlog p or is merely loose.
Authors: We acknowledge that the first-order Taylor expansion is an approximation and that the remainder term may not be negligible for discrete prompt edits. Our derivation intentionally uses the linear term to obtain a closed-form upper bound via Cauchy-Schwarz that highlights the effect of gradient dispersion; the bound is not presented as a tight characterization of every observed Δlog p but as a theoretical explanation for why sensitivity persists even when prompts are meaning-preserving. The dispersion claim itself is supported by direct measurements of gradient and embedding distances in the paper. In the revision we will add a new subsection with quantitative checks: we will compute the actual Δlog p versus the linear approximation error for representative meaning-preserving variants (e.g., paraphrases and template swaps) across several models and report the relative magnitude of the remainder, thereby clarifying the regime in which the bound remains informative. revision: partial
-
Referee: [Empirical validation] The correlation analysis with PromptSensiScore: the paper presents the upper bound as strongly correlated with the metric but supplies no details on sample size, statistical significance testing, or controls, which weakens its role as supporting evidence for the dispersion explanation.
Authors: We agree that additional statistical rigor is needed. The reported correlation was obtained over a collection of LLMs and prompt pairs, yet the manuscript omitted the precise sample size, correlation coefficient with p-value, and any baseline controls. In the revised version we will explicitly state the number of prompt pairs and models used, report Pearson/Spearman coefficients together with p-values, and include controls such as (i) correlations with randomly perturbed (non-meaning-preserving) prompts and (ii) comparisons against logit variance alone. These additions will strengthen the evidential link between the derived bound and observed prompt sensitivity. revision: yes
Circularity Check
No significant circularity; derivation uses standard inequalities on empirical dispersion observations
full rationale
The paper treats the LLM as a multivariate function f, applies a first-order Taylor expansion around a prompt, and invokes the Cauchy-Schwarz inequality to obtain an upper bound on |Δlog p| between meaning-preserving variants. This bound is a direct mathematical consequence of the expansion and inequality, independent of any fitted quantities or self-citations. Dispersion of similar inputs is reported as an empirical observation (via internal activations or gradients), which is then interpreted as producing a loose bound; the correlation with PromptSensiScore is offered only as supporting evidence. No equation reduces to a definitional identity, no parameter is fitted on a subset and renamed a prediction, and no uniqueness theorem or ansatz is smuggled via self-citation. The central claim remains an interpretive link between observed dispersion and bound looseness rather than a tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption First-order Taylor expansion sufficiently approximates the change in next-token log probability for meaning-preserving prompt perturbations
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
Interpreting Language Models with Contrastive Explanations
Yin, Kayo and Neubig, Graham. Interpreting Language Models with Contrastive Explanations. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.14
-
[5]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
Deep inside convolutional networks: Visualising image classification models and saliency maps , author=. arXiv preprint arXiv:1312.6034 , year=
-
[6]
Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
Visualizing and Understanding Neural Models in NLP , author=. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2016
-
[7]
Proceedings of the ieee/cvf conference on computer vision and pattern recognition , pages=
Enriching imagenet with human similarity judgments and psychological embeddings , author=. Proceedings of the ieee/cvf conference on computer vision and pattern recognition , pages=
-
[8]
Problems with Cosine as a Measure of Embedding Similarity for High Frequency Words
Zhou, Kaitlyn and Ethayarajh, Kawin and Card, Dallas and Jurafsky, Dan. Problems with Cosine as a Measure of Embedding Similarity for High Frequency Words. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2022. doi:10.18653/v1/2022.acl-short.45
-
[9]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. arXiv preprint arXiv:2506.05176 , year=
work page internal anchor Pith review arXiv
-
[10]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[11]
Finetuned Language Models Are Zero-Shot Learners
Finetuned language models are zero-shot learners , author=. arXiv preprint arXiv:2109.01652 , year=
work page internal anchor Pith review arXiv
-
[12]
The Twelfth International Conference on Learning Representations , year=
Evaluating the Zero-shot Robustness of Instruction-tuned Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[13]
P ro SA : Assessing and understanding the prompt sensitivity of LLM s
Zhuo, Jingming and Zhang, Songyang and Fang, Xinyu and Duan, Haodong and Lin, Dahua and Chen, Kai. P ro SA : Assessing and Understanding the Prompt Sensitivity of LLM s. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.108
-
[14]
POSIX : A Prompt Sensitivity Index For Large Language Models
Chatterjee, Anwoy and Renduchintala, H S V N S Kowndinya and Bhatia, Sumit and Chakraborty, Tanmoy. POSIX : A Prompt Sensitivity Index For Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.852
-
[15]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[16]
Learning multiple layers of features from tiny images , author=
-
[17]
Liu, Ziche and Ke, Rui and Liu, Yajiao and Jiang, Feng and Li, Haizhou. Take the essence and discard the dross: A Rethinking on Data Selection for Fine-Tuning Large Language Models. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)...
-
[18]
How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition
Dong, Guanting and Yuan, Hongyi and Lu, Keming and Li, Chengpeng and Xue, Mingfeng and Liu, Dayiheng and Wang, Wei and Yuan, Zheng and Zhou, Chang and Zhou, Jingren. How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume...
-
[19]
Zero-shot Approach to Overcome Perturbation Sensitivity of Prompts
Chakraborty, Mohna and Kulkarni, Adithya and Li, Qi. Zero-shot Approach to Overcome Perturbation Sensitivity of Prompts. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.313
-
[20]
Diploma, Technische Universit
Untersuchungen zu dynamischen neuronalen Netzen , author=. Diploma, Technische Universit
-
[21]
IEEE transactions on neural networks , volume=
Learning long-term dependencies with gradient descent is difficult , author=. IEEE transactions on neural networks , volume=. 1994 , publisher=
1994
-
[22]
2012 , publisher=
Machine learning: a probabilistic perspective , author=. 2012 , publisher=
2012
-
[23]
Mathematics of control, signals and systems , volume=
Approximation by superpositions of a sigmoidal function , author=. Mathematics of control, signals and systems , volume=. 1989 , publisher=
1989
-
[24]
Neural networks , volume=
Multilayer feedforward networks are universal approximators , author=. Neural networks , volume=. 1989 , publisher=
1989
-
[25]
Are Transformers universal approximators of sequence-to-sequence functions? , author=
-
[26]
IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS , volume=
G-Softmax: Improving Intraclass Compactness and Interclass Separability of Features , author=. IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS , volume=
-
[27]
Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48 , pages =
Liu, Weiyang and Wen, Yandong and Yu, Zhiding and Yang, Meng , title =. Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48 , pages =. 2016 , publisher =
2016
-
[28]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Chen, Ting and Kornblith, Simon and Norouzi, Mohammad and Hinton, Geoffrey , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
2020
-
[29]
arXiv preprint arXiv:2206.00330 , year=
On layer normalizations and residual connections in transformers , author=. arXiv preprint arXiv:2206.00330 , year=
-
[30]
International conference on machine learning , pages=
On layer normalization in the transformer architecture , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[31]
ResiDual: Transformer with Dual Residual Connections.arXiv:2304.14802, 2024
Residual: Transformer with dual residual connections , author=. arXiv preprint arXiv:2304.14802 , year=
-
[32]
The Twelfth International Conference on Learning Representations , year=
Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting , author=. The Twelfth International Conference on Learning Representations , year=
-
[33]
2015 , publisher=
Neural networks and deep learning , author=. 2015 , publisher=
2015
-
[34]
nature , volume=
Deep learning , author=. nature , volume=. 2015 , publisher=
2015
-
[35]
nature , volume=
Learning representations by back-propagating errors , author=. nature , volume=. 1986 , publisher=
1986
-
[36]
Proceedings of the 27th international conference on machine learning (ICML-10) , pages=
Rectified linear units improve restricted boltzmann machines , author=. Proceedings of the 27th international conference on machine learning (ICML-10) , pages=
-
[37]
Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=
Deep sparse rectifier neural networks , author=. Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=. 2011 , organization=
2011
-
[38]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Talmor, Alon and Herzig, Jonathan and Lourie, Nicholas and Berant, Jonathan. C ommonsense QA : A Question Answering Challenge Targeting Commonsense Knowledge. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/...
-
[40]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[41]
EMNLP , year=
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering , author=. EMNLP , year=
-
[42]
Transformer-based Causal Language Models Perform Clustering
Wu, Xinbo and Varshney, Lav R. Transformer-based Causal Language Models Perform Clustering. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.296
-
[43]
Fine-Tuned Transformers Show Clusters of Similar Representations Across Layers
Phang, Jason and Liu, Haokun and Bowman, Samuel R. Fine-Tuned Transformers Show Clusters of Similar Representations Across Layers. Proceedings of the Fourth BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP. 2021. doi:10.18653/v1/2021.blackboxnlp-1.42
-
[44]
Forty-second International Conference on Machine Learning , year=
On the Emergence of Position Bias in Transformers , author=. Forty-second International Conference on Machine Learning , year=
-
[45]
Cours d'analyse de l'
Cauchy, Augustin Louis Baron , year=. Cours d'analyse de l'
-
[46]
Ueber ein die Fl
Schwarz, Hermann Amandus , booktitle=. Ueber ein die Fl. 1890 , publisher=
-
[47]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Note on regression and inheritance in the case of two parents , author=
VII. Note on regression and inheritance in the case of two parents , author=. proceedings of the royal society of London , volume=. 1895 , publisher=
-
[50]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[51]
2019 , url=
Language Models are Unsupervised Multitask Learners , author=. 2019 , url=
2019
-
[52]
Liu , title =
Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu , title =. Journal of Machine Learning Research , year =
-
[53]
Making Pre-trained Language Models Better Few-shot Learners
Gao, Tianyu and Fisch, Adam and Chen, Danqi. Making Pre-trained Language Models Better Few-shot Learners. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.295
-
[54]
arXiv preprint arXiv:2312.04945 , year=
The icl consistency test , author=. arXiv preprint arXiv:2312.04945 , year=
-
[55]
What Makes Good In-Context Examples for
Liu, Jiachang and Shen, Dinghan and Zhang, Yizhe and Dolan, Bill and Carin, Lawrence and Chen, Weizhu. What Makes Good In-Context Examples for GPT -3?. Proceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures. 2022. doi:10.18653/v1/2022.deelio-1.10
-
[56]
The Eleventh International Conference on Learning Representations , year=
Selective Annotation Makes Language Models Better Few-Shot Learners , author=. The Eleventh International Conference on Learning Representations , year=
-
[57]
Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
Lu, Yao and Bartolo, Max and Moore, Alastair and Riedel, Sebastian and Stenetorp, Pontus. Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.556
-
[58]
Proceedings of the 38th International Conference on Machine Learning , pages =
Calibrate Before Use: Improving Few-shot Performance of Language Models , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[59]
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
Min, Sewon and Lyu, Xinxi and Holtzman, Ari and Artetxe, Mikel and Lewis, Mike and Hajishirzi, Hannaneh and Zettlemoyer, Luke. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.759
-
[60]
Robustness of Learning from Task Instructions
Gu, Jiasheng and Zhao, Hongyu and Xu, Hanzi and Nie, Liangyu and Mei, Hongyuan and Yin, Wenpeng. Robustness of Learning from Task Instructions. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.875
-
[61]
Mind Your Format: Towards Consistent Evaluation of In-Context Learning Improvements
Voronov, Anton and Wolf, Lena and Ryabinin, Max. Mind Your Format: Towards Consistent Evaluation of In-Context Learning Improvements. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.375
-
[62]
State of what art? a call for multi-prompt LLM evaluation
Mizrahi, Moran and Kaplan, Guy and Malkin, Dan and Dror, Rotem and Shahaf, Dafna and Stanovsky, Gabriel. State of What Art? A Call for Multi-Prompt LLM Evaluation. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00681
-
[63]
arXiv e-prints , pages=
Promptbench: Towards evaluating the robustness of large language models on adversarial prompts , author=. arXiv e-prints , pages=
-
[64]
arXiv preprint arXiv:2111.02840 , year=
Adversarial glue: A multi-task benchmark for robustness evaluation of language models , author=. arXiv preprint arXiv:2111.02840 , year=
-
[65]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[66]
ACM computing surveys , volume=
Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing , author=. ACM computing surveys , volume=. 2023 , publisher=
2023
-
[67]
Advances in Neural Information Processing Systems , volume=
Faith and fate: Limits of transformers on compositionality , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
Lindberg , title =
David C. Lindberg , title =. 1992 , address =
1992
-
[69]
2007 , publisher=
A history of Chinese mathematics , author=. 2007 , publisher=
2007
-
[70]
1981 , publisher=
A history of Greek mathematics , author=. 1981 , publisher=
1981
-
[71]
Tercentenary Memorial Volume
James Gregory. Tercentenary Memorial Volume. Edited by HW Turnbull. Pp. viii, 524; 5 plates. 25s. 1939.(Published for the Royal Society of Edinburgh by G. Bell & Sons) , author=. The Mathematical Gazette , volume=. 1940 , publisher=
1939
-
[72]
Methodus incrementorum directa , author=
-
[73]
International Conference on Learning Representations , year=
Are Transformers universal approximators of sequence-to-sequence functions? , author=. International Conference on Learning Representations , year=
-
[74]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
On the Alignment of Large Language Models with Global Human Opinion , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[76]
International Conference on Machine Learning , pages=
Pythia: A suite for analyzing large language models across training and scaling , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[77]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[78]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[79]
Hashimoto , title =
Rohan, Taori and Ishaan, Gulrajani and Tianyi, Zhang and Yann, Dubois and Xuechen, Li and Carlos, Guestrin and Percy, Liang and Tatsunori, B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[80]
Introducing GPT-5 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.