Recognition: unknown
Context-Aware Search and Retrieval Under Token Erasure
Pith reviewed 2026-05-10 03:27 UTC · model grok-4.3
The pith
Similarity margins converge to a multivariate Gaussian under token-erased TF-IDF retrieval with importance-weighted redundancy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under term-frequency query representations with semantically adaptive redundancy and TF-IDF retrieval, the vector of similarity margins converges to a multivariate Gaussian distribution. This yields an explicit approximation for the retrieval error probability together with computable upper bounds. The analysis is supported by numerical results, and the importance-aware redundancy principle is shown to carry over to embedding-based retrieval on real-world data.
What carries the argument
Convergence of the similarity margins vector to a multivariate Gaussian distribution, which supplies the error-probability approximation and bounds.
If this is right
- Retrieval error probabilities admit a Gaussian approximation whose parameters follow directly from query statistics and erasure rate.
- Allocating higher redundancy to important features lowers the chance of incorrect document selection.
- Explicit upper bounds let system designers set performance guarantees in advance.
- The same importance-based redundancy rule improves reliability in embedding-based retrieval pipelines.
Where Pith is reading between the lines
- Redundancy allocation could be optimized by solving for the minimal total redundancy that keeps error below a target using the Gaussian formula.
- The Gaussian limit may extend to other vector-space retrieval models or to cosine similarity in embedding spaces.
- Dynamic encoders could estimate feature importance on the fly and protect tokens accordingly when erasure probability varies.
- The setup resembles unequal-error-protection coding in which semantic weight replaces bit importance.
Load-bearing premise
That term-frequency features with importance-based redundancy assignment cause the similarity margins to converge to a multivariate Gaussian under the TF-IDF model.
What would settle it
A large-scale simulation in which the empirical distribution of similarity margins deviates from normality for increasing numbers of query terms under the described redundancy scheme.
Figures


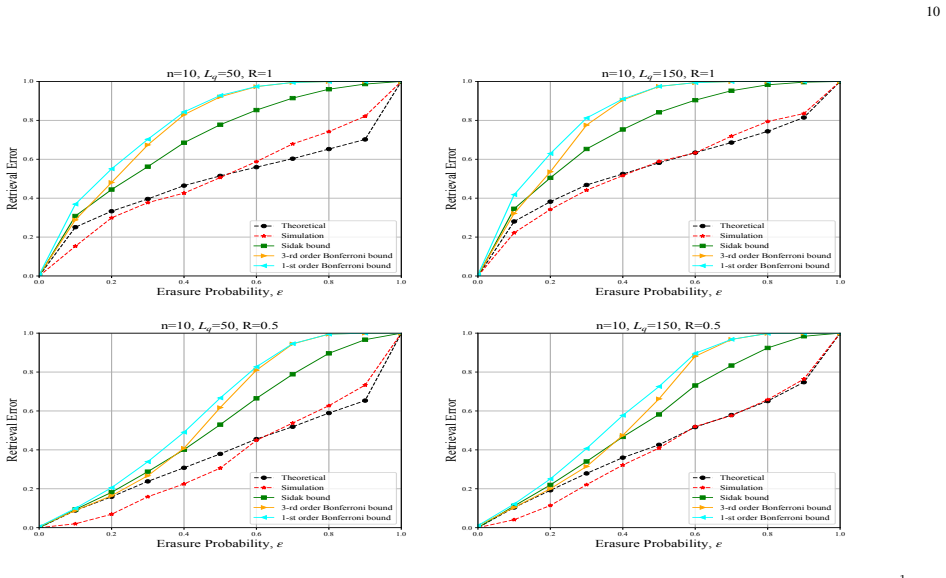


read the original abstract
This paper introduces and analyzes a search and retrieval model for RAG-like systems under {token} erasures. We provide an information-theoretic analysis of remote document retrieval when query representations are only partially preserved. The query is represented using term-frequency-based features, and semantically adaptive redundancy is assigned according to feature importance. Retrieval is performed using TF-IDF-weighted similarity. We characterize the retrieval error probability by showing that the vector of similarity margins converges to a multivariate Gaussian distribution, yielding an explicit approximation and computable upper bounds. Numerical results support the analysis, while a separate data-driven evaluation using embedding-based retrieval on real-world data shows that the same importance-aware redundancy principles extend to modern retrieval pipelines. Overall, the results show that assigning higher redundancy to semantically important query features improves retrieval reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces and analyzes a search and retrieval model for RAG-like systems under token erasures. It uses term-frequency-based features with semantically adaptive redundancy assigned according to feature importance, performs retrieval via TF-IDF-weighted similarity, and characterizes the retrieval error probability by proving convergence of the similarity margins vector to a multivariate Gaussian distribution. This yields an explicit approximation and computable upper bounds. The claims are supported by numerical results and a data-driven evaluation on embedding-based retrieval with real-world data, showing benefits of importance-aware redundancy.
Significance. If the multivariate Gaussian convergence holds under the paper's conditions, the work provides a rigorous information-theoretic framework for bounding retrieval errors under partial query preservation, which can guide the design of redundancy mechanisms in unreliable or distributed retrieval settings. The numerical and empirical validations add credibility, and the extension to modern embedding pipelines suggests broader applicability beyond classical TF-IDF models. This contributes to understanding reliability in context-aware retrieval systems.
major comments (1)
- [Abstract] The central claim that the vector of similarity margins converges to a multivariate Gaussian distribution (yielding explicit approximations and bounds on retrieval error probability) is load-bearing. This relies on applying the multivariate CLT to the sum of per-term contributions modulated by erasure indicators with probabilities depending on feature importance. For typical queries with small numbers of distinct terms, heterogeneous erasure probabilities may violate the Lindeberg condition, leading to slow convergence and inaccurate bounds. The abstract and numerical results do not specify the term-count regime or verify approximation quality for realistic small-n cases.
minor comments (2)
- [Numerical results] The numerical results would benefit from explicit reporting of the number of terms in simulated queries, error bar details, and direct comparison between the Gaussian approximation and empirical error rates to assess accuracy in the small-n regime.
- Clarify in the model description whether feature importance for assigning adaptive redundancy is assumed known a priori or derived from the same data, to avoid potential circularity in the analysis.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments on our manuscript. The feedback highlights important considerations for the applicability of our central theoretical result. We provide a point-by-point response below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract] The central claim that the vector of similarity margins converges to a multivariate Gaussian distribution (yielding explicit approximations and bounds on retrieval error probability) is load-bearing. This relies on applying the multivariate CLT to the sum of per-term contributions modulated by erasure indicators with probabilities depending on feature importance. For typical queries with small numbers of distinct terms, heterogeneous erasure probabilities may violate the Lindeberg condition, leading to slow convergence and inaccurate bounds. The abstract and numerical results do not specify the term-count regime or verify approximation quality for realistic small-n cases.
Authors: We thank the referee for pointing out this important caveat regarding the central claim. The convergence to the multivariate Gaussian relies on the multivariate central limit theorem applied to the sum of independent random variables (the per-term contributions times erasure indicators). The Lindeberg condition requires that no single variable dominates the variance in the limit. In our model, since erasure probabilities are heterogeneous but bounded (between some p_min >0 and p_max <1), and the number of terms n is the dimension, for fixed n the convergence is not asymptotic, but the paper presents it as an approximation tool. We acknowledge that the abstract does not explicitly state the term-count regime. Our numerical results are generated with varying numbers of terms, including smaller values, and show that the Gaussian approximation provides reasonable bounds even for n around 10-20. To address the concern, we will revise the abstract to specify that the analysis assumes a sufficient number of terms for the CLT to provide a good approximation and include additional experiments in the revised manuscript that compare the approximated error probability to the exact value computed via enumeration or Monte Carlo for small-n queries. This will verify the quality of the approximation in realistic settings. revision: yes
Circularity Check
No circularity: standard CLT application to independently defined model
full rationale
The central derivation applies the multivariate central limit theorem to the vector of similarity margins under a TF-IDF model with per-feature erasure probabilities. The abstract states that redundancy is assigned according to feature importance, but nothing in the provided text indicates that these importances are fitted from the same retrieval-error data being predicted or that the Gaussian limit is defined in terms of the target error probability. No self-citations are invoked to justify uniqueness or an ansatz, and no parameter is fitted on a subset then relabeled as a prediction. The numerical results and separate embedding-based evaluation are presented as supporting evidence rather than as the source of the claimed convergence. The derivation is therefore self-contained against external benchmarks (CLT) and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Term-frequency-based features adequately represent the query for redundancy assignment and TF-IDF retrieval
- ad hoc to paper The vector of similarity margins converges to a multivariate Gaussian distribution
Reference graph
Works this paper leans on
-
[1]
Buttcher, C
S. Buttcher, C. L. Clarke, and G. V . Cormack,Information retrieval: Implementing and evaluating search engines. MIT Press, 2016
2016
-
[2]
Improving the domain adaptation of retrieval aug- mented generation (RAG) models for open domain question answering,
S. Siriwardhana, R. Weerasekera, E. Wen, T. Kaluarachchi, R. Rana, and S. Nanayakkara, “Improving the domain adaptation of retrieval aug- mented generation (RAG) models for open domain question answering,” Transactions of the Association for Computational Linguistics, vol. 11, pp. 1–17, 2023
2023
-
[3]
A survey on question an- swering systems over linked data and documents,
E. Dimitrakis, K. Sgontzos, and Y . Tzitzikas, “A survey on question an- swering systems over linked data and documents,”Journal of Intelligent Information Systems, vol. 55, no. 2, pp. 233–259, 2020
2020
-
[4]
Retrieving and reading: A comprehensive survey on open-domain question answering
F. Zhu, W. Lei, C. Wang, J. Zheng, S. Poria, and T.-S. Chua, “Re- trieving and reading: A comprehensive survey on open-domain question answering,”arXiv preprint arXiv:2101.00774, 2021
-
[5]
What is semantic communication? A view on conveying meaning in the era of machine intelligence,
Q. Lan, D. Wen, Z. Zhang, Q. Zeng, X. Chen, P. Popovski, and K. Huang, “What is semantic communication? A view on conveying meaning in the era of machine intelligence,”Journal of Communications and Information Networks, vol. 6, no. 4, pp. 336–371, 2021
2021
-
[6]
Retrieval-Augmented Generation for Large Language Models: A Survey
Y . Gao, Y . Xiong, X. Gao, K. Jia, J. Pan, Y . Bi, Y . Dai, J. Sun, and H. Wang, “Retrieval-augmented generation for large language models: A survey,”arXiv preprint arXiv:2312.10997, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Evaluating retrieval quality in retrieval- augmented generation,
A. Salemi and H. Zamani, “Evaluating retrieval quality in retrieval- augmented generation,” inProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Re- trieval, 2024, pp. 2395–2400
2024
-
[8]
arXiv preprint arXiv:2403.10446 (2024)
J. Li, Y . Yuan, and Z. Zhang, “Enhancing llm factual accuracy with rag to counter hallucinations: A case study on domain-specific queries in private knowledge-bases,”arXiv preprint arXiv:2403.10446, 2024
-
[9]
Hybrid retrieval for retrieval augmented generation in the german language production domain,
S. Knollmeyer, S. Pfaff, M. U. Akmal, L. Koval, S. Asif, S. G. Mathias, and D. Großmann, “Hybrid retrieval for retrieval augmented generation in the german language production domain,”Journal of Advances in Information Technology, vol. 16, no. 6, 2025
2025
-
[10]
From semantic communication to semantic-aware networking: Model, architecture, and open problems,
G. Shi, Y . Xiao, Y . Li, and X. Xie, “From semantic communication to semantic-aware networking: Model, architecture, and open problems,” IEEE Communications Magazine, vol. 59, no. 8, pp. 44–50, 2021
2021
-
[11]
Semantic communications: Overview, open issues, and future research directions,
X. Luo, H.-H. Chen, and Q. Guo, “Semantic communications: Overview, open issues, and future research directions,”IEEE Wireless Communi- cations, vol. 29, no. 1, pp. 210–219, 2022
2022
-
[12]
Semantics-empowered communications: A tutorial-cum-survey,
Z. Lu, R. Li, K. Lu, X. Chen, E. Hossain, Z. Zhao, and H. Zhang, “Semantics-empowered communications: A tutorial-cum-survey,”IEEE Communications Surveys & Tutorials, 2023
2023
-
[13]
Semantic communications for future internet: Fundamentals, applications, and challenges,
W. Yang, H. Du, Z. Q. Liew, W. Y . B. Lim, Z. Xiong, D. Niyato, X. Chi, X. Shen, and C. Miao, “Semantic communications for future internet: Fundamentals, applications, and challenges,”IEEE Communications Surveys & Tutorials, vol. 25, no. 1, pp. 213–250, 2022
2022
-
[14]
Less data, more knowledge: Building next generation semantic communication networks,
C. Chaccour, W. Saad, M. Debbah, Z. Han, and H. V . Poor, “Less data, more knowledge: Building next generation semantic communication networks,”IEEE Communications Surveys & Tutorials, 2024
2024
-
[15]
Semantic importance-aware communications using pre-trained language models,
S. Guo, Y . Wang, S. Li, and N. Saeed, “Semantic importance-aware communications using pre-trained language models,”IEEE Communi- cations Letters, vol. 27, no. 9, pp. 2328–2332, 2023
2023
-
[16]
Token communications: A large model-driven framework for cross-modal context-aware semantic communications,
L. Qiao, M. B. Mashhadi, Z. Gao, R. Tafazolli, M. Bennis, and D. Niyato, “Token communications: A large model-driven framework for cross-modal context-aware semantic communications,”IEEE Wireless Communications, vol. 32, no. 5, pp. 80–88, 2025
2025
-
[17]
Text-guided token communication for wireless image transmission,
B. Liu, L. Qiao, Y . Wang, Z. Gao, Y . Ma, K. Ying, and T. Qin, “Text-guided token communication for wireless image transmission,” in 2025 IEEE/CIC International Conference on Communications in China (ICCC), 2025, pp. 1–6
2025
-
[18]
Vector search with openai embeddings: Lucene is all you need,
J. Xian, T. Teofili, R. Pradeep, and J. Lin, “Vector search with openai embeddings: Lucene is all you need,” inProceedings of the 17th ACM International Conference on Web Search and Data Mining, 2024, pp. 1090–1093
2024
-
[19]
Gosling grows up: Retrieval with learned dense and sparse representations using anserini,
J. Lin, A. H. Chen, C. Lassance, X. Ma, R. Pradeep, T. Teofili, J. Xian, J.-H. Yang, B. Zhong, and V . Zhong, “Gosling grows up: Retrieval with learned dense and sparse representations using anserini,” inProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2025, pp. 3223–3233
2025
-
[20]
Balancing the blend: An experimental analysis of trade-offs in hybrid search,
M. Wang, B. Tan, Y . Gao, H. Jin, Y . Zhang, X. Ke, X. Xu, and Y . Zhu, “Balancing the blend: An experimental analysis of trade-offs in hybrid search,”arXiv preprint arXiv:2508.01405, 2025
-
[21]
Context-aware search and retrieval over erasure channels,
S. Ghasvarianjahromi, Y . Yakimenka, and J. Kliewer, “Context-aware search and retrieval over erasure channels,” in2025 IEEE Information Theory Workshop (ITW), 2025, pp. 821–826
2025
-
[22]
Zipf’s word frequency law in natural language: A critical review and future directions,
S. T. Piantadosi, “Zipf’s word frequency law in natural language: A critical review and future directions,”Psychonomic Bulletin & Review, vol. 21, pp. 1112–1130, 2014
2014
-
[23]
Analysis of TF-IDF model and its variant for document retrieval,
A. Mishra and S. Vishwakarma, “Analysis of TF-IDF model and its variant for document retrieval,” in2015 international Conference on Computational Intelligence and Communication Networks (CICN), 2015, pp. 772–776
2015
-
[24]
A review on recent research in information retrieval,
S. Ibrihich, A. Oussous, O. Ibrihich, and M. Esghir, “A review on recent research in information retrieval,”Procedia Computer Science, vol. 201, pp. 777–782, 2022
2022
-
[25]
A stop list for general text,
C. Fox, “A stop list for general text,” inAcm Sigir Forum, vol. 24, no. 1-2. ACM New York, NY , USA, 1989, pp. 19–21
1989
-
[26]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th Inter- national Joint Conference on Natural Language Processing (EMNLP- IJCNLP), 2019, pp. 3982–3992
2019
-
[27]
Efficient Estimation of Word Representations in Vector Space
T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,”arXiv preprint arXiv:1301.3781, 2013
work page internal anchor Pith review arXiv 2013
-
[28]
Bellman,Dynamic Programming
R. Bellman,Dynamic Programming. Princeton University Press, 1957
1957
-
[29]
Feller,An Introduction to Probability Theory and its Applications, Volume 2
W. Feller,An Introduction to Probability Theory and its Applications, Volume 2. John Wiley & Sons, 1991, vol. 2
1991
-
[30]
Rectangular confidence regions for the means of multivariate normal distributions,
Z. ˇSid´ak, “Rectangular confidence regions for the means of multivariate normal distributions,”Journal of the American Statistical Association, vol. 62, no. 318, pp. 626–633, 1967
1967
-
[31]
A. W. Van der Vaart,Asymptotic statistics. Cambridge University Press, 2000, vol. 3
2000
-
[32]
Billingsley,Convergence of Probability Measures
P. Billingsley,Convergence of Probability Measures. John Wiley & Sons, 2013
2013
-
[33]
Natural questions: a benchmark for question answering research,
T. Kwiatkowski, J. Palomaki, O. Redfield, M. Collins, A. Parikh, C. Alberti, D. Epstein, I. Polosukhin, J. Devlin, K. Leeet al., “Natural questions: a benchmark for question answering research,”Transactions of the Association for Computational Linguistics, vol. 7, pp. 453–466, 2019
2019
-
[34]
The llama 3 herd of models,
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fanet al., “The llama 3 herd of models,”arXiv e-prints, pp. arXiv–2407, 2024
2024
-
[35]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes, J. Healy, and J. Melville, “UMAP: Uniform manifold approximation and projection for dimension reduction,”arXiv preprint arXiv:1802.03426, 2018
work page internal anchor Pith review arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.