Bayesian experimental design: grouped geometric pooled posterior via ensemble Kalman methods
Pith reviewed 2026-05-10 03:19 UTC · model grok-4.3
The pith
Grouping outer samples into group-specific pooled posteriors via tailored ensemble Kalman inversion yields more accurate and stable expected information gain estimators at amortized cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a grouped geometric pooled posterior framework that partitions outer samples into groups and constructs a pooled proposal for each group. While such grouping strategy would normally require generating separate proposal samples for different groups, our tailored ensemble Kalman inversion (EKI) formulation generates these samples without extra forward-model evaluation cost. We also introduce a conservative diagnostic to assess importance-sampling quality to guide grouping. This grouping strategy improves within-group proposal-target alignment, yielding more accurate and stable estimators while keeping the cost comparable to amortized approaches.
What carries the argument
The grouped geometric pooled posterior framework, realized through a tailored ensemble Kalman inversion formulation that produces group-specific proposal samples by reusing forward-model evaluations already performed for the outer loop.
If this is right
- Expected information gain estimators become more accurate and stable than those obtained from fully amortized inference across all outer samples.
- Total computational cost, measured in forward-model evaluations, remains comparable to standard amortized approaches.
- Within-group proposal-target alignment improves, reducing the degradation that occurs when a single proposal is forced to cover highly heterogeneous posteriors.
- The framework applies directly to both simple Gaussian-linear settings and complex high-dimensional model discrepancy calibration tasks.
Where Pith is reading between the lines
- If the diagnostic and zero-cost generation hold across problems, the method could make Bayesian experimental design feasible for a wider range of physical systems where full nested sampling has been computationally prohibitive.
- The reuse pattern in the ensemble Kalman formulation suggests similar grouping tactics could improve efficiency in other ensemble-based inverse problems that face heterogeneous targets.
- Adaptive or data-driven grouping rules derived from the same diagnostic might further tighten the accuracy-cost tradeoff beyond the fixed partitioning explored here.
Load-bearing premise
The tailored ensemble Kalman inversion must generate the necessary group-specific proposal samples at zero extra forward-model cost, and the conservative diagnostic must correctly identify groupings where the improved alignment actually raises estimator quality above the fully amortized baseline.
What would settle it
A controlled run on the high-dimensional network-based calibration problem in which the grouped method produces EIG estimator variance no lower than the amortized baseline, or requires additional forward-model calls to maintain the same accuracy, would falsify the central efficiency-accuracy claim.
Figures
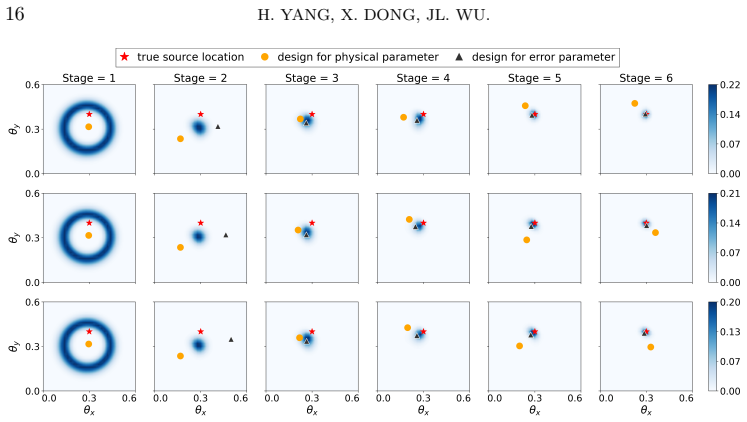





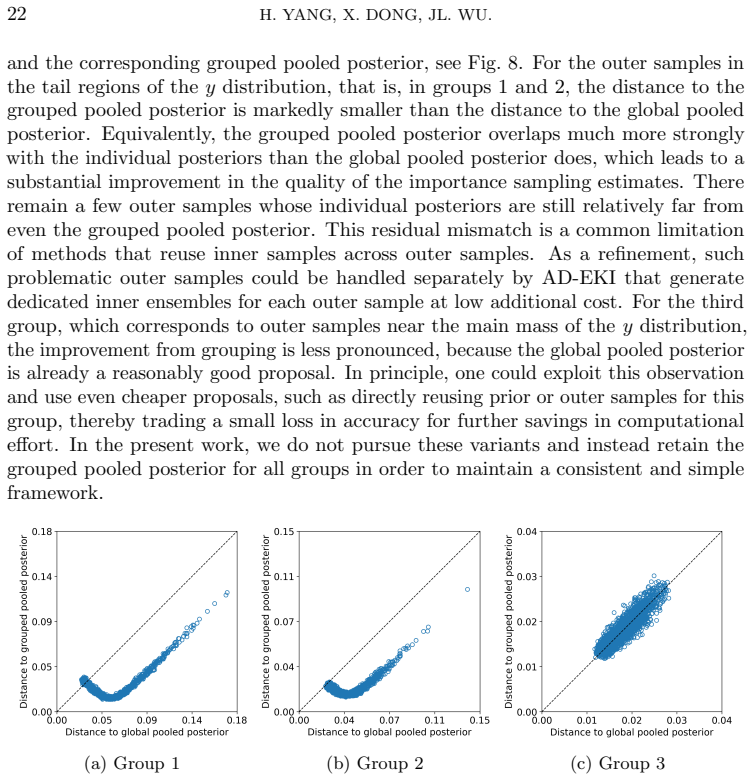

read the original abstract
Bayesian experimental design (BED) for complex physical systems is often limited by the nested inference required to estimate the expected information gain (EIG) or its gradients. Each outer sample induces a different posterior, creating a large and heterogeneous set of inference targets. Existing methods have to sacrifice either accuracy or efficiency: they either perform per-outer-sample posterior inference, which yields higher fidelity but at prohibitive computational cost, or amortize the inner inference across all outer samples for computational reuse, at the risk of degraded accuracy under posterior heterogeneity. To improve accuracy and maintain cost at the amortized level, we propose a grouped geometric pooled posterior framework that partitions outer samples into groups and constructs a pooled proposal for each group. While such grouping strategy would normally require generating separate proposal samples for different groups, our tailored ensemble Kalman inversion (EKI) formulation generates these samples without extra forward-model evaluation cost. We also introduce a conservative diagnostic to assess importance-sampling quality to guide grouping. This grouping strategy improves within-group proposal-target alignment, yielding more accurate and stable estimators while keeping the cost comparable to amortized approaches. We evaluate the performance of our method on both Gaussian-linear and high-dimensional network-based model discrepancy calibration problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a grouped geometric pooled posterior framework for Bayesian experimental design to estimate expected information gain. Outer samples are partitioned into groups, each with a pooled proposal constructed via a tailored ensemble Kalman inversion (EKI) formulation that is claimed to incur no extra forward-model evaluations compared to fully amortized single-proposal baselines. A conservative diagnostic is introduced to assess importance-sampling quality and guide grouping. The approach is asserted to yield more accurate and stable estimators under posterior heterogeneity while preserving amortized-level cost, with supporting evaluations on Gaussian-linear problems and high-dimensional network-based model discrepancy calibration.
Significance. If the no-extra-cost property of the tailored EKI holds without hidden reductions in ensemble size or iterations, and the reported accuracy gains prove robust, the work would meaningfully advance practical BED for complex physical systems by addressing the accuracy-efficiency tradeoff in nested inference. The dual evaluation on linear-Gaussian and high-dimensional network settings provides a reasonable initial validation of the grouping strategy.
major comments (1)
- Abstract and Methods: The pivotal claim that the tailored EKI formulation 'generates these samples without extra forward-model evaluation cost' must be substantiated with the explicit update rule or shared-ensemble construction. Standard EKI costs scale with ensemble size times iterations; the manuscript needs to show precisely how group-specific proposals reuse the identical forward evaluations as the single amortized baseline, without implicit trade-offs such as smaller per-group ensembles or fewer iterations, since this directly determines whether accuracy gains can be attributed to improved within-group alignment.
minor comments (2)
- Notation section: The term 'geometric pooled posterior' should be defined with an explicit equation contrasting it to standard importance-weighted pooling to avoid ambiguity in the grouping construction.
- Results: The high-dimensional network experiments would benefit from reporting the number of groups chosen by the diagnostic and the corresponding within-group alignment metrics to allow readers to assess the practical impact of the conservative diagnostic.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address the single major comment below and will revise the manuscript to provide the requested substantiation.
read point-by-point responses
-
Referee: Abstract and Methods: The pivotal claim that the tailored EKI formulation 'generates these samples without extra forward-model evaluation cost' must be substantiated with the explicit update rule or shared-ensemble construction. Standard EKI costs scale with ensemble size times iterations; the manuscript needs to show precisely how group-specific proposals reuse the identical forward evaluations as the single amortized baseline, without implicit trade-offs such as smaller per-group ensembles or fewer iterations, since this directly determines whether accuracy gains can be attributed to improved within-group alignment.
Authors: We agree that explicit details on the no-extra-cost property are necessary to support our claims. In the revised manuscript we will add a new subsection in Methods that presents the tailored EKI update rule, including the precise form of the Kalman gain and the geometric pooling operator. The construction reuses a single shared ensemble of forward-model evaluations (identical size and iteration count to the amortized baseline) that is computed once; group-specific proposals are then obtained by post-processing this ensemble with the pooling step, which requires no additional model runs. We will also include a complexity table and pseudocode confirming that forward evaluations, ensemble size, and iteration count are unchanged relative to the single-proposal baseline. This revision will make clear that accuracy improvements arise from improved within-group alignment rather than any hidden computational trade-offs. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a grouped geometric pooled posterior framework and a tailored ensemble Kalman inversion (EKI) formulation as algorithmic constructions for Bayesian experimental design. The claims center on partitioning outer samples into groups, constructing pooled proposals, and generating samples without extra forward-model evaluations via the tailored EKI. These are presented as novel methodological contributions with a conservative diagnostic for importance-sampling quality, evaluated empirically on Gaussian-linear and network-based problems. No derivation steps reduce by construction to inputs, fitted parameters renamed as predictions, or load-bearing self-citations. The framework is self-contained against external benchmarks and does not rely on self-referential definitions or uniqueness theorems from prior author work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard assumptions of Bayesian experimental design and importance sampling hold for the outer and inner loops.
- domain assumption Ensemble Kalman inversion can be formulated to produce group-specific samples without additional forward evaluations.
Reference graph
Works this paper leans on
-
[1]
Alexanderian,Optimal experimental design for infinite-dimensional bayesian inverse problems governed by pdes: A review, Inverse Problems, 37 (2021), p
A. Alexanderian,Optimal experimental design for infinite-dimensional bayesian inverse problems governed by pdes: A review, Inverse Problems, 37 (2021), p. 043001
2021
-
[2]
Ao and J
Z. Ao and J. Li,On estimating the gradient of the expected information gain in bayesian experimental design, in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, 2024, pp. 20311–20319
2024
- [3]
-
[4]
J. Beck, B. M. Dia, L. F. Espath, Q. Long, and R. Tempone,Fast bayesian experimental design: Laplace-based importance sampling for the expected information gain, Computer Methods in Applied Mechanics and Engineering, 334 (2018), pp. 523–553
2018
-
[5]
Callahan, A
J. Callahan, A. Chin, J. Pacheco, and T. Catanach,Reverse-annealed sequential monte carlo for efficient bayesian optimal experiment design, in The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[6]
K. Chaloner and I. Verdinelli,Bayesian experimental design: A review, Statistical Science, 10 (1995), pp. 273–304, https://doi.org/10.1214/ss/1177009939, https://projecteuclid.org/ journals/statistical-science/volume-10/issue-3/Bayesian-Experimental-Design-A-Review/ 10.1214/ss/1177009939.full (accessed 2024-06-05). Publisher: Institute of Mathematical Statistics
-
[7]
Ding and Q
Z. Ding and Q. Li,Ensemble kalman inversion: mean-field limit and convergence analysis, Statistics and Computing, 31 (2021), pp. 1–21
2021
-
[8]
J. Dong, C. Jacobsen, M. Khalloufi, M. Akram, W. Liu, K. Duraisamy, and X. Huan, Variational bayesian optimal experimental design with normalizing flows, Computer Methods in Applied Mechanics and Engineering, 433 (2025), p. 117457. 28H. YANG, X. DONG, JL. WU
2025
- [9]
-
[10]
C. C. Drovandi, J. M. McGree, and A. N. Pettitt,A sequential monte carlo algorithm to incorporate model uncertainty in bayesian sequential design, Journal of Computational and Graphical Statistics, 23 (2014), pp. 3–24
2014
-
[11]
M. R. Ebers, K. M. Steele, and J. N. Kutz,Discrepancy modeling framework: Learning missing physics, modeling systematic residuals, and disambiguating between deterministic and random effects, SIAM Journal on Applied Dynamical Systems, 23 (2024), pp. 440–469
2024
-
[12]
Englezou, T
Y. Englezou, T. W. Waite, and D. C. Woods,Approximate laplace importance sampling for the estimation of expected shannon information gain in high-dimensional bayesian design for nonlinear models, Statistics and Computing, 32 (2022), p. 82
2022
-
[13]
C. Feng,Optimal Bayesian experimental design in the presence of model error, thesis, Massachu- setts Institute of Technology, 2015, https://dspace.mit.edu/handle/1721.1/97790 (accessed 2024-07-09). Accepted: 2015-07-17T19:46:48Z
2015
-
[14]
A layered multiple importance sampling scheme for focused optimal Bayesian experimental design
C. Feng and Y. M. Marzouk,A layered multiple importance sampling scheme for focused optimal bayesian experimental design, arXiv preprint arXiv:1903.11187, (2019)
work page Pith review arXiv 1903
-
[15]
A. Foster, D. R. Ivanova, I. Malik, and T. Rainforth,Deep adaptive design: Amortizing sequential Bayesian experimental design, June 2021, https://doi.org/10.48550/arXiv.2103. 02438, http://arxiv.org/abs/2103.02438 (accessed 2024-06-05). arXiv:2103.02438 [cs, stat]
-
[16]
Foster, M
A. Foster, M. Jankowiak, M. O’Meara, Y. W. Teh, and T. Rainforth,A unified stochastic gradient approach to designing bayesian-optimal experiments, in International Conference on Artificial Intelligence and Statistics, PMLR, 2020, pp. 2959–2969
2020
-
[17]
Go and P
J. Go and P. Chen,Sequential infinite-dimensional Bayesian optimal experimental design with derivative-informed latent attention neural operator, Journal of Computational Physics, (2025), p. 113976
2025
-
[18]
T. Goda, T. Hironaka, W. Kitade, and A. Foster,Unbiased mlmc stochastic gradient-based optimization of bayesian experimental designs, SIAM Journal on Scientific Computing, 44 (2022), pp. A286–A311
2022
-
[19]
R. B. Grosse, S. Ancha, and D. M. Roy,Measuring the reliability of mcmc inference with bidirectional monte carlo, Advances in Neural Information Processing Systems, 29 (2016)
2016
-
[20]
X. Huan, J. Jagalur, and Y. Marzouk,Optimal experimental design: Formulations and computations, Acta Numerica, 33 (2024), pp. 715–840
2024
-
[21]
Simulation-based optimal Bayesian experimental design for nonlinear systems,
X. Huan and Y. M. Marzouk,Simulation-based optimal Bayesian experimental design for nonlinear systems, Journal of Computational Physics, 232 (2013), pp. 288–317, https://doi.org/10.1016/j.jcp.2012.08.013, https://www.sciencedirect.com/science/article/ pii/S0021999112004597 (accessed 2024-07-30)
-
[22]
Huan and Y
X. Huan and Y. M. Marzouk,Gradient-based stochastic optimization methods in Bayesian experimental design, International Journal for Uncertainty Quantification, 4 (2014)
2014
-
[23]
Huang, Y
D. Huang, Y. Guo, L. Acerbi, and S. Kaski,Amortized bayesian experimental design for decision-making, Advances in Neural Information Processing Systems, 37 (2024), pp. 109460– 109486
2024
- [24]
-
[25]
M. Jones, M. Goldstein, P. Jonathan, and D. Randell,Bayes linear analysis for Bayesian optimal experimental design, Journal of Statistical Planning and Inference, 171 (2016), pp. 115–129, https://doi.org/10.1016/j.jspi.2015.10.011, https://www.sciencedirect.com/ science/article/pii/S0378375815001950 (accessed 2024-07-23)
-
[26]
M. C. Kennedy and A. O’Hagan,Bayesian calibration of computer models, Journal of the Royal Statistical Society Series B: Statistical Methodology, 63 (2001), pp. 425–464, https://doi. org/10.1111/1467-9868.00294, https://academic.oup.com/jrsssb/article/63/3/425/7083367 (accessed 2024-07-09)
-
[27]
N. B. Kovachki and A. M. Stuart,Ensemble Kalman inversion: a derivative-free technique for machine learning tasks, Inverse Problems, 35 (2019), p. 095005, https://doi.org/10.1088/ 1361-6420/ab1c3a, https://dx.doi.org/10.1088/1361-6420/ab1c3a (accessed 2024-10-18). Publisher: IOP Publishing
-
[28]
Levine and A
M. Levine and A. Stuart,A framework for machine learning of model error in dynamical systems, Communications of the American Mathematical Society, 2 (2022), pp. 283–344
2022
-
[29]
D. V. Lindley,On a measure of the information provided by an experiment, The Annals of Math- ematical Statistics, 27 (1956), pp. 986–1005, https://doi.org/10.1214/aoms/1177728069, https://projecteuclid.org/journals/annals-of-mathematical-statistics/volume-27/ issue-4/On-a-Measure-of-the-Information-Provided-by-an-Experiment/10.1214/aoms/ GROUPED POOLED PO...
-
[30]
Q. Long, M. Scavino, R. Tempone, and S. Wang,Fast estimation of expected information gains for bayesian experimental designs based on laplace approximations, Computer Methods in Applied Mechanics and Engineering, 259 (2013), pp. 24–39
2013
-
[31]
R. M. Neal,Annealed importance sampling, Statistics and computing, 11 (2001), pp. 125–139
2001
-
[32]
J. N. Neuberger, A. Alexanderian, and B. van Bloemen Waanders,Goal oriented optimal design of infinite-dimensional bayesian inverse problems using quadratic approximations, Journal of Scientific Computing, 105 (2025), p. 55
2025
-
[33]
M. L. Parks, E. De Sturler, G. Mackey, D. D. Johnson, and S. Maiti,Recycling krylov subspaces for sequences of linear systems, SIAM Journal on Scientific Computing, 28 (2006), pp. 1651–1674
2006
-
[34]
Rainforth, A
T. Rainforth, A. Foster, D. R. Ivanova, and F. Bickford Smith,Modern Bayesian experimental design, Statistical Science, 39 (2024), pp. 100–114
2024
-
[35]
E. G. Ryan, C. C. Drovandi, J. M. McGree, and A. N. Pettitt,A review of modern computational algorithms for Bayesian optimal design, International Statistical Review, 84 (2016), pp. 128–154, https://doi.org/10.1111/insr.12107, https://onlinelibrary.wiley.com/ doi/10.1111/insr.12107 (accessed 2024-04-22)
-
[36]
K. J. Ryan,Estimating expected information gains for experimental designs with application to the random fatigue-limit model, Journal of Computational and Graphical Statistics, 12 (2003), pp. 585–603. [38]D. Sanz-Alonso and Z. Wang,Bayesian update with importance sampling: Required sample size, Entropy, 23 (2020), p. 22
2003
-
[37]
W. Shen and X. Huan,Bayesian sequential optimal experimental design for nonlinear models using Policy gradient reinforcement learning, Computer Methods in Applied Mechanics and Engineering, 416 (2023), p. 116304, https://doi.org/10.1016/j.cma.2023.116304, http: //arxiv.org/abs/2110.15335 (accessed 2024-04-22). arXiv:2110.15335 [cs, stat]
-
[38]
J.-L. Wu, M. E. Levine, T. Schneider, and A. Stuart,Learning about structural errors in models of complex dynamical systems, Journal of Computational Physics, (2024), p. 113157
2024
-
[39]
K. Wu, P. Chen, and O. Ghattas,A fast and scalable computational framework for large-scale high-dimensional Bayesian optimal experimental design, SIAM/ASA Journal on Uncertainty Quantification, 11 (2023), pp. 235–261
2023
-
[40]
H. Yang, C. Chen, and J.-L. Wu,Active learning of model discrepancy with bayesian experimental design, Computer Methods in Applied Mechanics and Engineering, 446 (2025), p. 118198, https://doi.org/https://doi.org/10.1016/j.cma.2025.118198, https:// www.sciencedirect.com/science/article/pii/S0045782525004700
-
[41]
H. Yang, X. Dong, and J.-L. Wu,Bayesian experimental design for model discrepancy calibra- tion: An auto-differentiable ensemble kalman inversion approach, Journal of Computational Physics, 545 (2026), p. 114469, https://doi.org/https://doi.org/10.1016/j.jcp.2025.114469, https://www.sciencedirect.com/science/article/pii/S002199912500751X
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.