Recognition: unknown
CrossPan: A Comprehensive Benchmark for Cross-Sequence Pancreas MRI Segmentation and Generalization
Pith reviewed 2026-05-10 05:12 UTC · model grok-4.3
The pith
Cross-sequence domain shifts in MRI are far more severe than center variability and collapse segmentation performance for the pancreas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By creating a large multi-sequence, multi-center dataset and running extensive transfer experiments, the authors show that cross-sequence generalization—not model architecture or center diversity—is the primary barrier to clinically deployable pancreas MRI segmentation, as in-domain success does not transfer due to contrast inversions.
What carries the argument
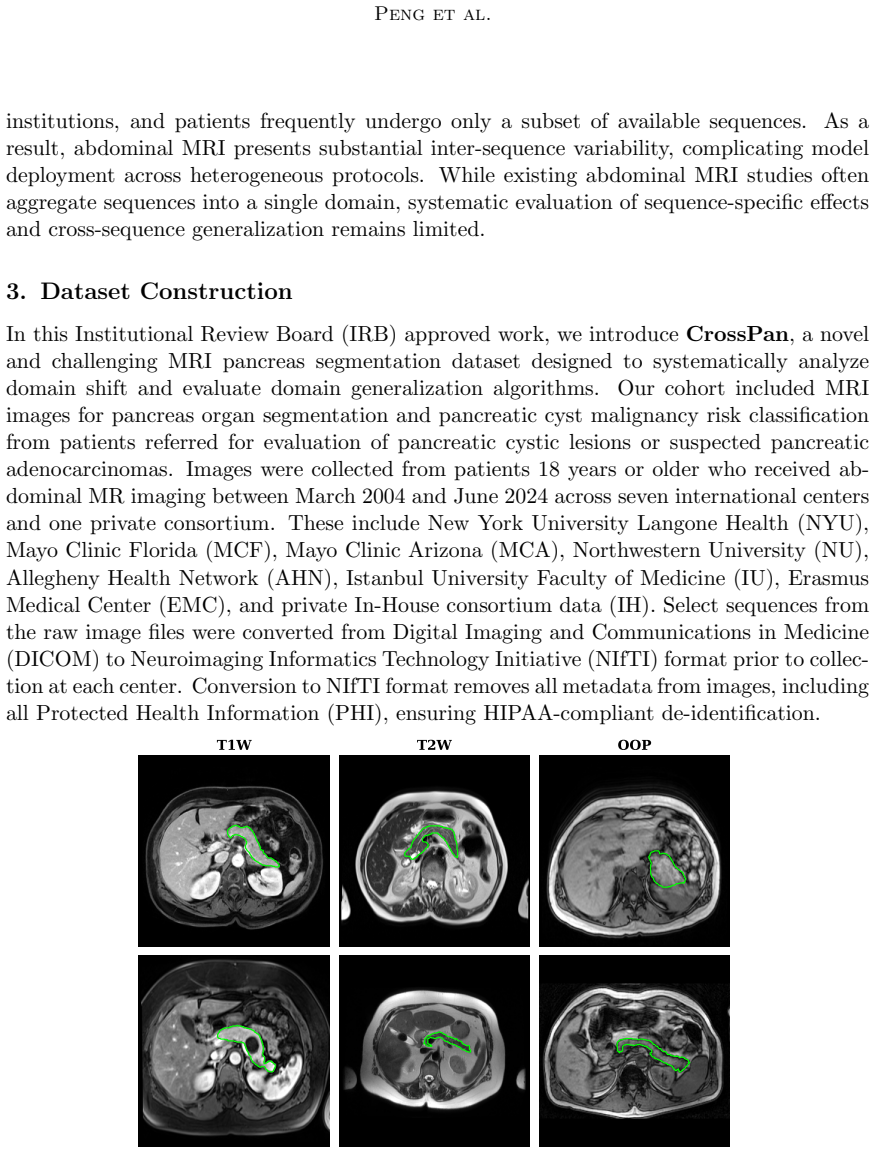
The CrossPan benchmark dataset of 1,386 scans across T1-weighted, T2-weighted, and Out-of-Phase sequences, used to quantify and compare in-domain versus cross-sequence segmentation performance.
If this is right
- Clinically useful pancreas segmentation models must incorporate mechanisms robust to MRI sequence-specific contrast variations.
- Foundation models with shape priors provide a starting point for zero-shot performance across sequences.
- Semi-supervised learning should be applied cautiously only on sequences with consistent intensity profiles.
- Future benchmarks and methods should prioritize cross-sequence testing over just cross-center or cross-institution shifts.
Where Pith is reading between the lines
- Extending this benchmark to other abdominal organs could reveal if pancreas-specific variability is unique or general.
- Developing physics-informed preprocessing to normalize contrast inversions might restore model performance without new architectures.
- Integration of CrossPan into standard medical imaging challenges would push the field toward sequence-agnostic solutions.
- Long-term, this suggests that multi-sequence training data collection should be prioritized in clinical datasets.
Load-bearing premise
That the state-of-the-art domain generalization and semi-supervised methods tested are representative of the best possible approaches, and that failures are due solely to contrast inversions rather than unmeasured data biases.
What would settle it
A new domain generalization technique that achieves Dice scores above 0.5 when transferring from T1-weighted training to T2-weighted testing on the CrossPan dataset without relying on external foundation models or additional labeled data.
Figures








read the original abstract
Automatic pancreas segmentation is fundamental to abdominal MRI analysis, yet deep learning models trained on one MRI sequence often fail catastrophically when applied to another-a challenge that has received little systematic investigation. We introduce CrossPan, a multi-institutional benchmark comprising 1,386 3D scans across three routinely acquired sequences (T1-weighted, T2-weighted, and Out-of-Phase) from eight centers. Our experiments reveal three key findings. First, cross-sequence domain shifts are far more severe than cross-center variability: models achieving Dice scores above 0.85 in-domain collapse to near-zero (<0.02) when transferred across sequences. Second, state-of-the-art domain generalization methods provide negligible benefit under these physics-driven contrast inversions, whereas foundation models like MedSAM2 maintain moderate zero-shot performance through contrast-invariant shape priors. Third, semi-supervised learning offers gains only under stable intensity distributions and becomes unstable on sequences with high intra-organ variability. These results establish cross-sequence generalization-not model architecture or center diversity-as the primary barrier to clinically deployable pancreas MRI segmentation. Dataset and code are available at https://crosspan.netlify.app/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CrossPan, a benchmark with 1,386 3D MRI scans from T1-weighted, T2-weighted, and Out-of-Phase sequences across eight centers for pancreas segmentation. Experiments show in-domain Dice >0.85 collapsing to <0.02 cross-sequence (worse than cross-center shifts), with limited gains from SOTA domain generalization methods, moderate zero-shot results from MedSAM2 via shape priors, and instability in semi-supervised learning on high-variability sequences. It concludes cross-sequence generalization due to physics-driven contrast inversions is the primary barrier to clinical deployment, with dataset and code released publicly.
Significance. If the central empirical findings hold after addressing potential confounds, this benchmark would be a useful contribution to medical image analysis by providing a standardized multi-sequence, multi-center testbed that shifts emphasis toward sequence-invariant techniques and foundation models rather than center adaptation alone. The public data and code release supports reproducibility and follow-on work.
major comments (2)
- [Abstract] Abstract, first key finding: The claim that cross-sequence shifts are far more severe than cross-center variability (Dice collapse to <0.02) is load-bearing for the conclusion that sequence generalization is the primary barrier, yet the reported comparison does not confirm isolation via within-center cross-sequence transfers or balanced sequence labels across centers. This leaves open confounding by center-sequence interactions such as acquisition protocols or patient selection that correlate with sequence type per center.
- [Abstract] Abstract, second key finding: The assessment that state-of-the-art domain generalization methods provide negligible benefit is central to arguing against architecture-focused solutions, but the manuscript does not detail the exact set of methods tested, their hyperparameter tuning, or whether more recent contrast-invariant approaches were included; without this, it is unclear if the failures are due purely to physics-driven inversions or incomplete method coverage.
minor comments (2)
- [Abstract] Abstract: The reference to 'MedSAM2' lacks a citation or brief description of its training data and architecture, which would aid readers in understanding the contrast-invariant shape priors claim.
- [Results] The manuscript would benefit from an explicit table or figure summarizing per-sequence and per-center Dice scores with standard deviations to support the near-zero cross-sequence results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing clarifications from the full experimental design and indicating where revisions will be made to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract] Abstract, first key finding: The claim that cross-sequence shifts are far more severe than cross-center variability (Dice collapse to <0.02) is load-bearing for the conclusion that sequence generalization is the primary barrier, yet the reported comparison does not confirm isolation via within-center cross-sequence transfers or balanced sequence labels across centers. This leaves open confounding by center-sequence interactions such as acquisition protocols or patient selection that correlate with sequence type per center.
Authors: We thank the referee for identifying this potential source of confounding. In the full manuscript, all cross-center experiments were conducted strictly within the same sequence (e.g., T1-to-T1 across centers) to isolate center variability, while cross-sequence experiments aggregated data across centers but always involved sequence changes. To further isolate the effect, we will add a dedicated within-center cross-sequence transfer analysis in the revised version, using the subset of centers that acquired multiple sequences. This controlled comparison will be reported alongside the existing results. The consistent near-zero Dice scores (<0.02) across these transfers, driven by physics-based contrast inversions, remain the dominant observation and are not replicated in within-sequence cross-center settings. revision: yes
-
Referee: [Abstract] Abstract, second key finding: The assessment that state-of-the-art domain generalization methods provide negligible benefit is central to arguing against architecture-focused solutions, but the manuscript does not detail the exact set of methods tested, their hyperparameter tuning, or whether more recent contrast-invariant approaches were included; without this, it is unclear if the failures are due purely to physics-driven inversions or incomplete method coverage.
Authors: We agree that explicit details on the tested methods are required for full transparency. The experiments evaluated a range of domain generalization techniques, including adversarial adaptation (DANN), moment matching (MMD), and several contrast-aware baselines, with hyperparameters selected via grid search on source-domain validation splits. Recent contrast-invariant methods were considered but yielded similarly limited gains under the observed intensity inversions. In the revision, we will expand the methods and experimental sections to list every method with its exact implementation, hyperparameter ranges, and selection rationale, including discussion of why certain newer physics-informed or contrastive approaches were included or omitted. This will confirm that the negligible benefits stem from the fundamental sequence physics rather than incomplete coverage. revision: yes
Circularity Check
No circularity: purely empirical benchmark with direct experimental results
full rationale
The paper introduces the CrossPan dataset and reports segmentation performance metrics from experiments across sequences and centers. No mathematical derivations, equations, fitted parameters, or predictions are present that could reduce to inputs by construction. Central claims about cross-sequence generalization barriers rest on measured Dice scores and comparisons in the new multi-center data, with no self-citation chains or ansatzes invoked as load-bearing justification. The study is self-contained against external benchmarks via its experimental protocol.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MRI sequences exhibit distinct intensity distributions and contrast properties due to acquisition physics
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2503.08373 (2025) 2, 4, 5, 13, 23, 24, 33
Fabian Isensee, Maximilian Rokuss, Lars Kr¨ amer, Stefan Dinkelacker, Ashis Ravindran, Florian Stritzke, Benjamin Hamm, Tassilo Wald, Moritz Langenberg, Constantin Ul- rich, et al. nninteractive: Redefining 3d promptable segmentation.arXiv preprint arXiv:2503.08373,
-
[2]
U-mamba: Enhancing long-range dependency for biomedical image segmentation
Jun Ma, Feifei Li, and Bo Wang. U-mamba: Enhancing long-range dependency for biomed- ical image segmentation.arXiv preprint arXiv:2401.04722,
-
[3]
Medsam2: Segment anything in 3d medical images and videos.arXiv preprint arXiv:2504.03600, 2025
Jun Ma, Zongxin Yang, Sumin Kim, Bihui Chen, Mohammed Baharoon, Adibvafa Fallah- pour, Reza Asakereh, Hongwei Lyu, and Bo Wang. Medsam2: Segment anything in 3d medical images and videos.arXiv preprint arXiv:2504.03600,
-
[4]
doi: 10.1109/TMI.2014.2377694. Andriy Myronenko. 3d mri brain tumor segmentation using autoencoder regularization. In International MICCAI brainlesion workshop, pages 311–320. Springer,
-
[5]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, pages 234–241. Springer,
2015
-
[6]
Reza Safdari, Mohammad-Ali Nikouei Mahani, Mohamad Koohi-Moghadam, and Kyong- tae Tyler Bae
URLhttps://arxiv.org/abs/1506.06448. Reza Safdari, Mohammad-Ali Nikouei Mahani, Mohamad Koohi-Moghadam, and Kyong- tae Tyler Bae. Mixstyleflow: Domain generalization in medical image segmentation us- ing normalizing flows. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 376–385. Springer,
-
[7]
Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst- case generalization.arXiv preprint arXiv:1911.08731,
work page internal anchor Pith review arXiv 1911
-
[8]
Sam-med3d: Towards general- purpose segmentation models for volumetric medical images,
URLhttps://arxiv.org/abs/2310.15161. Jakob Wasserthal, Hanns-Christian Breit, Manfred T Meyer, Maurice Pradella, Daniel Hinck, Alexander W Sauter, Tobias Heye, Daniel T Boll, Joshy Cyriac, Shan Yang, et al. Totalsegmentator: robust segmentation of 104 anatomic structures in ct images. Radiology: Artificial Intelligence, 5(5):e230024,
-
[9]
URLhttps: //arxiv.org/abs/1612.08230. 19 Peng et al. Appendix A. Dataset Details Here, we present the detailed composition of our dataset in Table
-
[10]
Table 7: Statistics of sample distribution across different MRI sequences and centers. Sequence Center Samples T1-weighted (T1W) MCF 151 NYU 162 EMC 50 IU 50 NU 50 T2-weighted (T2W) MCF 143 NYU 162 EMC 102 IU 73 NU 207 AHN 27 MCA 23 Out of Phase (OOP) NU 100 EMC 36 IH 50 20 CrossPan Appendix B. Evaluated Model Architectures Classical 3D architectures.We i...
2015
-
[11]
Both methods leverage unlabeled data and consistency regularization to improve segmentation quality in limited-annotation settings
and Cross Pseudo Supervision (CPS) (Chen et al., 2021). Both methods leverage unlabeled data and consistency regularization to improve segmentation quality in limited-annotation settings. In our comparisons, nnU-Net serves as a self-configuring clinical baseline; other CNN- , transformer-, and Mamba-based models represent diverse supervised architectures ...
2021
-
[12]
All experiments were conducted on a cluster equipped with NVIDIA A100 (80GB) GPUs
No early stopping was employed to ensure convergence across all baselines. All experiments were conducted on a cluster equipped with NVIDIA A100 (80GB) GPUs. To ensure reproducibility, we fixed random seeds for data splitting and network initialization. Data splits.To avoid information leakage across institutions and to keep center dis- tributions balance...
1949
-
[13]
These tables complement the LOSO results in the main text
Table 17 reports the setting where T1W is held out (train on T2W + OOP, test on T1W), and Table 18 reports the set- ting where OOP is held out (train on T1W + T2W, test on OOP). These tables complement the LOSO results in the main text. Table 17: Leave-one-sequence-out benchmark (Train on T2W+OOP→Test on T1W). Model Dice NSD HD95 (mm) General supervised s...
2081
-
[14]
We reported their zero-shot per- formances on all three sequences
and nnInteractive (Isensee et al., 2025). We reported their zero-shot per- formances on all three sequences. Table 19: In-domain Dice performance across T1W, T2W, and OOP MRI sequences. Foundation models are reported in zero-shot mode to highlight their intrinsic transferability, whereas other models are trained on CrossPan. Model T1W Dice T2W Dice OOP Di...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.