Recognition: unknown
A Mechanism and Optimization Study on the Impact of Information Density on User-Generated Content Named Entity Recognition
Pith reviewed 2026-05-10 03:21 UTC · model grok-4.3
The pith
Low information density independently causes attention blunting and poor named entity recognition on user-generated content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hierarchical confounding-controlled resampling experiments establish information density as an independent factor that degrades NER performance on UGC by inducing attention blunting, quantified through Attention Spectrum Analysis. The Window-Aware Optimization Module then locates low-density regions and uses selective back-translation to increase semantic density without changing the underlying model, producing up to 4.5% absolute F1 improvement and new state-of-the-art results on WNUT2017 while remaining effective across mainstream architectures on WNUT2017, Twitter-NER, and WNUT2016.
What carries the argument
The Window-Aware Optimization Module (WOM) that detects information-sparse windows and applies selective back-translation to directionally raise semantic density, together with Attention Spectrum Analysis (ASA) that quantifies the resulting attention blunting.
If this is right
- Information density must be treated as a distinct variable when diagnosing why NER models collapse on user-generated text.
- Attention blunting in sparse regions directly lowers entity boundary detection and type classification.
- The WOM approach can be layered on top of existing NER architectures to improve results on social media without retraining the base model.
- Selective density enhancement generalizes across WNUT2017, Twitter-NER, and WNUT2016 while achieving new state-of-the-art scores on WNUT2017.
Where Pith is reading between the lines
- The same density measurement and targeted enrichment could be tested on other sequence-labeling tasks that suffer from sparse or noisy input.
- If density is the unifying cause, then pre-processing pipelines that raise information density before training might reduce the need for task-specific fine-tuning on UGC.
- Extending the selective back-translation step to languages or domains beyond English social media would test whether the mechanism holds more broadly.
Load-bearing premise
The hierarchical resampling experiments fully separate information density from entity rarity and annotation consistency, and performance gains come specifically from the density enhancement rather than other side effects of back-translation.
What would settle it
A dataset in which information density is varied while entity rarity, annotation consistency, and surface noise are held exactly constant, followed by measurement of whether NER F1 changes in the direction predicted by the attention-blunting account.
Figures










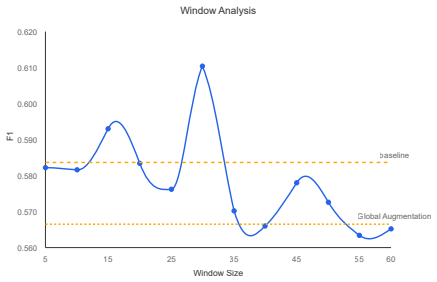
read the original abstract
Named Entity Recognition (NER) models trained on clean, high-resource corpora exhibit catastrophic performance collapse when deployed on noisy, sparse User-Generated Content (UGC), such as social media. Prior research has predominantly focused on point-wise symptom remediation -- employing customized fine-tuning to address issues like neologisms, alias drift, non-standard orthography, long-tail entities, and class imbalance. However, these improvements often fail to generalize because they overlook the structural sparsity inherent in UGC. This study reveals that surface-level noise symptoms share a unified root cause: low Information Density (ID). Through hierarchical confounding-controlled resampling experiments (specifically controlling for entity rarity and annotation consistency), this paper identifies ID as an independent key factor. We introduce Attention Spectrum Analysis (ASA) to quantify how reduced ID causally leads to ``attention blunting,'' ultimately degrading NER performance. Informed by these mechanistic insights, we propose the Window-Aware Optimization Module (WOM), an LLM-empowered, model-agnostic framework. WOM identifies information-sparse regions and utilizes selective back-translation to directionally enhance semantic density without altering model architecture. Deployed atop mainstream architectures on standard UGC datasets (WNUT2017, Twitter-NER, WNUT2016), WOM yields up to 4.5\% absolute F1 improvement, demonstrating robustness and achieving new state-of-the-art (SOTA) results on WNUT2017.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that low Information Density (ID) is the unifying root cause of NER performance collapse on noisy UGC, distinct from symptoms like neologisms or class imbalance. Through hierarchical resampling experiments that control for entity rarity and annotation consistency, it identifies ID as an independent causal factor. It introduces Attention Spectrum Analysis (ASA) to quantify how low ID produces 'attention blunting' in transformer models. Informed by this, the authors propose the Window-Aware Optimization Module (WOM), an LLM-based, model-agnostic module that applies selective back-translation to raise semantic density in sparse windows. On WNUT2017, Twitter-NER, and WNUT2016, WOM yields up to 4.5% absolute F1 gains and new SOTA results on WNUT2017.
Significance. If the causal isolation and performance gains are substantiated, the work would supply a mechanistic account of UGC NER failures and a practical, architecture-independent intervention. The emphasis on controlled resampling and the introduction of ASA represent an attempt to move beyond ad-hoc fixes. The reported SOTA on WNUT2017 and model-agnostic design could influence augmentation strategies in low-resource or noisy NLP settings, provided the attribution to density enhancement is isolated from incidental augmentation effects.
major comments (3)
- [Abstract / Resampling Experiments] The abstract states that hierarchical confounding-controlled resampling isolates ID after controlling for entity rarity and annotation consistency, yet supplies no description of the resampling procedure, balance diagnostics, or statistical tests confirming that the controls succeeded. This detail is load-bearing for the central claim that ID is an independent factor.
- [WOM Framework / Experiments] The WOM description asserts that selective back-translation directionally enhances semantic density and produces the 4.5% F1 gain, but no ablation is reported that compares WOM against standard (non-selective) back-translation or other density-agnostic augmentations. Without this separation, the performance improvement cannot be attributed specifically to the ASA-derived density mechanism rather than incidental syntactic or contextual changes.
- [Attention Spectrum Analysis] Attention Spectrum Analysis is introduced to quantify 'attention blunting' caused by reduced ID, but the abstract and available description contain no formal definition, equation, or pseudocode for how the spectrum is extracted from model attention maps or how blunting is measured. This prevents verification of the claimed causal link.
minor comments (2)
- [Abstract] The abstract lists datasets as 'WNUT2017, Twitter-NER, WNUT2016' without specifying exact splits, preprocessing, or whether standard benchmark partitions were used; a table of dataset statistics would improve clarity.
- [Introduction] The acronym 'ID' for Information Density risks collision with other common NLP usages (e.g., information diffusion); an explicit first-use definition or alternative phrasing would reduce ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify important areas where additional clarity and evidence will strengthen the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract / Resampling Experiments] The abstract states that hierarchical confounding-controlled resampling isolates ID after controlling for entity rarity and annotation consistency, yet supplies no description of the resampling procedure, balance diagnostics, or statistical tests confirming that the controls succeeded. This detail is load-bearing for the central claim that ID is an independent factor.
Authors: We agree that explicit details on the resampling procedure are necessary to substantiate the claim that ID operates as an independent factor. Although the manuscript summarizes the hierarchical confounding-controlled approach, we will expand the description in the revised version to include the full procedure (stratification by entity frequency bins and annotation agreement thresholds), balance diagnostics (pre- and post-resampling distribution comparisons), and statistical tests (e.g., Kolmogorov-Smirnov tests for distributional equivalence). These additions will appear in the main text with supporting tables in an appendix. revision: yes
-
Referee: [WOM Framework / Experiments] The WOM description asserts that selective back-translation directionally enhances semantic density and produces the 4.5% F1 gain, but no ablation is reported that compares WOM against standard (non-selective) back-translation or other density-agnostic augmentations. Without this separation, the performance improvement cannot be attributed specifically to the ASA-derived density mechanism rather than incidental syntactic or contextual changes.
Authors: This observation is correct and highlights a gap in isolating the contribution of selective density enhancement. The current results demonstrate WOM's overall gains, but we did not include the requested ablations. In the revision we will add experiments comparing WOM to non-selective back-translation (applied uniformly across windows) and to density-agnostic baselines such as random synonym replacement. These results will be reported with statistical significance tests to show that the selective, ASA-informed component drives the observed improvements beyond incidental augmentation effects. revision: yes
-
Referee: [Attention Spectrum Analysis] Attention Spectrum Analysis is introduced to quantify 'attention blunting' caused by reduced ID, but the abstract and available description contain no formal definition, equation, or pseudocode for how the spectrum is extracted from model attention maps or how blunting is measured. This prevents verification of the claimed causal link.
Authors: We acknowledge that a formal definition is required for reproducibility and verification of the causal claim. The manuscript provides a high-level description of ASA, but we will add the precise mathematical formulation (including the equation for spectrum extraction from attention weight matrices and the blunting metric based on attention entropy or variance across windows), together with pseudocode in the appendix. This will allow readers to replicate the analysis and confirm the link between low ID and attention blunting. revision: yes
Circularity Check
No circularity: claims rest on controlled experiments and empirical gains, not definitional reductions
full rationale
The paper's central claims—that ID is an independent factor identified via hierarchical resampling controlling for rarity and consistency, that ASA quantifies attention blunting, and that WOM yields F1 gains via selective back-translation—are presented as outcomes of empirical procedures and performance measurements on standard datasets. No equations, fitted parameters renamed as predictions, or self-citations appear in the provided text that reduce these results to inputs by construction. The derivation chain is self-contained against external benchmarks (WNUT2017 etc.) and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Attention mechanisms in transformer-based NER models can be meaningfully analyzed via spectrum methods to detect blunting caused by input sparsity
- domain assumption Selective back-translation can increase semantic density in information-sparse windows without introducing new noise or altering entity labels
invented entities (3)
-
Information Density (ID)
no independent evidence
-
Attention Spectrum Analysis (ASA)
no independent evidence
-
Window-Aware Optimization Module (WOM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
W. L. Seow, I. Chaturvedi, A. Hogarth, R. Mao, E. Cambria, A re- view of named entity recognition: from learning methods to modelling paradigms and tasks, Artificial Intelligence Review 58 (10) (2025) 1–87
2025
-
[2]
Ushio, F
A. Ushio, F. Barbieri, V. Sousa, L. Neves, J. Camacho-Collados, Named entity recognition in twitter: A dataset and analysis on short-term tem- poral shifts, in: Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Vol- ume ...
2022
- [3]
- [4]
-
[5]
X. Li, H. Yan, X. Qiu, X. Huang, FLAT: Chinese NER Using Flat- Lattice Transformer, in: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020, pp. 1–12
2020
-
[6]
Y. Lu, Q. Liu, D. Dai, X. Xiao, H. Lin, X. Han, L. Sun, H. Wu, Unified structure generation for universal information extraction, in: Proceed- ings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 5755–5772
2022
-
[7]
Brisson, A
C. Brisson, A. Kahfy, M. Bui, F. Constant, Named entity recognition in context: Edit dunhuang team technical report for evahan2025 ner com- petition, in: Proceedings of the Second Workshop on Ancient Language Processing, 2025, pp. 176–181
2025
-
[8]
M. M. Mahtab, F. A. Khan, M. E. Islam, M. S. M. Chowdhury, L. I. Chowdhury, S. Afrin, H. Ali, M. M. O. Rashid, N. Mohammed, M. R. Amin, Bannerd: A benchmark dataset and context-driven approach for bangla named entity recognition, in: Findings of the Association for Computational Linguistics: NAACL 2025, 2025, pp. 6807–6828. 35
2025
-
[9]
J. Li, X. Cao, H. Zhang, B. Zheng, Z. Yang, A Multi-Granularity Word Fusion Method for Chinese NER, Applied Sciences 13 (2023) 2789
2023
-
[10]
W. Chen, H. Jiang, Q. Wu, B. F. Karlsson, Y. Guan, AdvPicker: Effectively Leveraging Unlabeled Data via Adversarial Discriminator for Cross-Lingual NER, in: Proceedings of the 59th Annual Meet- ing of the Association for Computational Linguistics and the 11th In- ternational Joint Conference on Natural Language Processing (ACL- IJCNLP), 2021, pp. 754–765
2021
-
[11]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al., Chain-of-thought prompting elicits reasoning in large language models, Advances in neural information processing systems 35 (2022) 24824–24837
2022
-
[12]
Derczynski, E
L. Derczynski, E. Nichols, M. van Erp, N. Limsopatham, Results of the WNUT2017 shared task on novel and emerging entity recognition, in: Proceedings of the 3rd Workshop on Noisy User-generated Text, Association for Computational Linguistics, 2017, pp. 140–147
2017
-
[13]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, Advances in Neural Information Processing Systems 30 (2017)
2017
-
[14]
Devlin, M.-W
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, BERT: Pre-training of deep bidirectional transformers for language understanding, in: Pro- ceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technolo- gies, Volume 1 (Long and Short Papers), Association for Computational Linguistics, ...
2019
-
[15]
Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, V. Stoyanov, RoBERTa: A robustly optimized BERT pretraining approach, arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[16]
Yamada, A
I. Yamada, A. Asai, H. Shindo, H. Takeda, Y. Matsumoto, LUKE: Deep contextualized entity representations with entity-aware self-attention, in: Proceedings of the 2020 Conference on Empirical Methods in Natu- ral Language Processing (EMNLP), Association for Computational Lin- guistics, 2020. 36
2020
-
[17]
P. He, X. Liu, J. Gao, W. Chen, DEBERTA: Decoding-enhanced BERT with disentangled attention, in: International Conference on Learning Representations, 2021
2021
-
[18]
J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C. H. So, J. Kang, BioBERT: a pre-trained biomedical language representation model for biomedical text mining, Bioinformatics 36 (4) (2020) 1234–1240
2020
-
[19]
Srivastava, P
A. Srivastava, P. Makhija, A. Gupta, Noisy text data: Achilles’ heel of BERT, in: Proceedings of the Sixth Workshop on Noisy User-generated Text (W-NUT 2020), 2020, pp. 16–21
2020
-
[20]
Esmaail, N
N. Esmaail, N. Omar, M. Mohd, Named entity recognition in user- generated text (english twitter): A systematic literature review, IEEE Access (2024)
2024
-
[21]
LLMs in biomedicine: a study on clinical named entity recognition,
M. Monajatipoor, J. Yang, J. Stremmel, M. Emami, F. Mohaghegh, M. Rouhsedaghat, K.-W. Chang, Llms in biomedicine: A study on clin- ical named entity recognition, arXiv preprint arXiv:2404.07376 (2024)
-
[22]
E. E. Akkaya, B. Can, Transfer learning for turkish named entity recog- nition on noisy text, Natural Language Engineering 27 (1) (2021) 35–64
2021
-
[23]
Zhang, D
S. Zhang, D. Wan, Extractive is not faithful: An investigation of broad unfaithfulness problems in extractive summarization, in: Association for Computational Linguistics (ACL), 2023
2023
-
[24]
Kirsch, J
L. Kirsch, J. Harrison, C. D. Freeman, J. Sohl-Dickstein, J. Schmidhu- ber, Towards general-purpose in-context learning agents, in: NeurIPS 2023 Workshop on Distribution Shifts: New Frontiers with Foundation Models, 2023
2023
-
[25]
S. E. Whang, Y. Roh, H. Song, J.-G. Lee, Data collection and quality challenges in deep learning: A data-centric AI perspective, The VLDB Journal 32 (4) (2023) 791–813. doi:10.1007/s00778-022-00775-9
-
[26]
D. Zha, Z. P. Bhat, K.-H. Lai, et al., Data-centric artificial intelligence: A survey, ACM Computing Surveys 57 (5) (2025) 1–42
2025
-
[27]
Y. Zhu, Y. Ye, M. Li, J. Zhang, O. Wu, Investigating annotation noise for named entity recognition, Neural Computing and Applications 35 (1) (2023) 993–1007. doi:10.1007/s00521-022-07733-0. 37
-
[28]
Eisape, V
T. Eisape, V. Gangireddy, R. Levy, Y. Kim, Probing for incremental parse states in autoregressive language models, in: Findings of the As- sociation for Computational Linguistics: EMNLP 2022, 2022, pp. 2801– 2813
2022
-
[29]
Xiaobo, Y
J. Xiaobo, Y. Chen, Relation enhancement for noise resistance in open- world link prediction, Expert Systems with Applications 273 (2025) 126773
2025
-
[30]
D. Lai, J. Xiaobo, Y. Chen, D. Hu, A mechanistic study on the impact of entity degree distribution in open-world link prediction, Information Processing & Management 63 (3) (2026) 104565
2026
-
[31]
Y. Xu, L. Zhang, Drilling risk named entity recognition based on roberta-bilstm-crf, in: Third International Conference on Machine Vi- sion, Automatic Identification, and Detection (MVAID 2024), Vol. 13230, SPIE, 2024, pp. 246–251
2024
-
[32]
J. Fu, X. Huang, P. Liu, SpanNER: Named entity re-/recognition as span prediction, in: Proceedings of the 59th Annual Meeting of the As- sociation for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021, pp. 7183–7195
2021
- [33]
-
[34]
X. Wang, S. Dou, L. Xiong, Y. Zou, Q. Zhang, T. Gui, X. Huang, MINER: Improving out-of-vocabulary named entity recognition from an information theoretic perspective, in: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 5590–5600
2022
-
[35]
Sainz, I
O. Sainz, I. García-Ferrero, R. Agerri, O. L. de Lacalle, G. Rigau, E. Agirre, Gollie: Annotation guidelines improve zero-shot information- extraction, in: ICLR, 2024
2024
- [36]
-
[37]
X. Wang, Y. Jiang, N. Bach, T. Wang, Z. Huang, F. Huang, K. Tu, Improving named entity recognition by external context retrieving and cooperative learning, in: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Pa- pers), 2021, p...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.