Recognition: unknown
From Experience to Skill: Multi-Agent Generative Engine Optimization via Reusable Strategy Learning
Pith reviewed 2026-05-10 02:01 UTC · model grok-4.3
The pith
A multi-agent system distills successful edits into reusable engine-specific skills to optimize generative engine outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
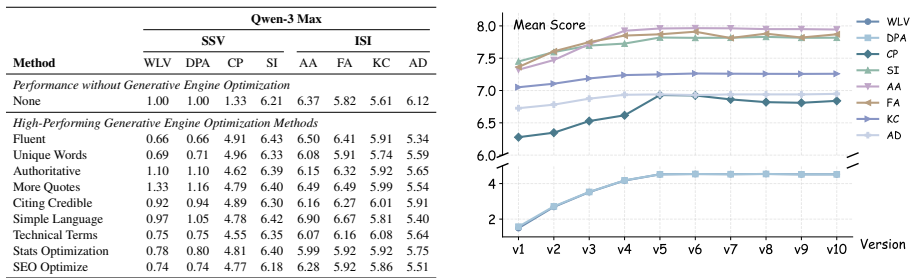
MAGEO reframes generative engine optimization as a strategy-learning problem in which a multi-agent execution layer of planning, editing, and fidelity-aware evaluation produces content edits, after which validated patterns are distilled into reusable, engine-specific optimization skills. On the introduced MSME-GEO-Bench the resulting system improves both semantic visibility and citation fidelity over heuristic baselines, with ablations attributing the gains primarily to engine-specific preference modeling and the reuse of learned strategies.
What carries the argument
Progressive distillation of validated editing patterns into reusable, engine-specific optimization skills, carried out by a multi-agent layer of coordinated planning, editing, and evaluation agents.
If this is right
- MAGEO outperforms heuristic baselines in both visibility and citation fidelity on three mainstream engines.
- Ablations confirm that engine-specific preference modeling and strategy reuse drive the performance gains.
- The Twin Branch Evaluation Protocol enables causal attribution of specific edits to measured improvements.
- The DSV-CF metric combines semantic visibility and attribution accuracy into a single evaluation score.
- A learning-driven approach that accumulates experience offers a scalable route to trustworthy generative engine optimization.
Where Pith is reading between the lines
- Production systems could initialize optimization with a library of previously learned skills rather than starting from scratch for every query.
- The same pattern-distillation idea could be applied to related generative tasks such as prompt refinement or response polishing.
- If the skills prove broadly transferable, repeated per-query computation could be reduced in deployed generative engines.
Load-bearing premise
That validated editing patterns can be distilled into reusable engine-specific skills that transfer across tasks and engines without overfitting to the benchmark.
What would settle it
Running the learned skills on a new set of queries or an unseen generative engine and finding no improvement over simple heuristic baselines.
Figures




read the original abstract
Generative engines (GEs) are reshaping information access by replacing ranked links with citation-grounded answers, yet current Generative Engine Optimization (GEO) methods optimize each instance in isolation, unable to accumulate or transfer effective strategies across tasks and engines. We reframe GEO as a strategy learning problem and propose MAGEO, a multi-agent framework in which coordinated planning, editing, and fidelity-aware evaluation serve as the execution layer, while validated editing patterns are progressively distilled into reusable, engine-specific optimization skills. To enable controlled assessment, we introduce a Twin Branch Evaluation Protocol for causal attribution of content edits and DSV-CF, a dual-axis metric that unifies semantic visibility with attribution accuracy. We further release MSME-GEO-Bench, a multi-scenario, multi-engine benchmark grounded in real-world queries. Experiments on three mainstream engines show that MAGEO substantially outperforms heuristic baselines in both visibility and citation fidelity, with ablations confirming that engine-specific preference modeling and strategy reuse are central to these gains, suggesting a scalable learning-driven paradigm for trustworthy GEO. Code is available at https://github.com/Wu-beining/MAGEO
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reframes Generative Engine Optimization (GEO) as a strategy learning problem rather than per-instance optimization. It proposes MAGEO, a multi-agent framework with coordinated planning, editing, and fidelity-aware evaluation agents that distill validated editing patterns into reusable, engine-specific optimization skills. The work introduces a Twin Branch Evaluation Protocol for causal attribution of edits, the DSV-CF metric unifying semantic visibility and attribution accuracy, and the MSME-GEO-Bench benchmark grounded in real-world queries. Experiments on three mainstream engines report that MAGEO outperforms heuristic baselines in visibility and citation fidelity, with ablations attributing gains to engine-specific preference modeling and strategy reuse.
Significance. If the central claims hold, this work could establish a scalable, learning-driven paradigm for GEO by enabling accumulation and transfer of effective strategies across tasks and engines, improving efficiency and trustworthiness over isolated optimization. The public release of code at https://github.com/Wu-beining/MAGEO and the new benchmark support reproducibility and community follow-up.
major comments (2)
- [Abstract and Experiments section] The abstract and experiments section report outperformance and ablation results but provide no quantitative details, error bars, dataset sizes, or statistical tests. This makes it impossible to assess the magnitude and reliability of the claimed gains in visibility and fidelity.
- [§5 (Ablations) and Benchmark construction] The claim that strategy reuse is causal to the gains (and that skills transfer across tasks/engines) rests on ablations within MSME-GEO-Bench, which is constructed from the same real-world queries used for skill distillation. Without explicit held-out query sets, cross-engine transfer tests on unseen distributions, or ablation isolating reuse from per-instance multi-agent optimization, the results risk overfitting to the benchmark's scenario distribution rather than demonstrating progressive, reusable skill learning.
minor comments (2)
- [Methods] Clarify the precise computation of the DSV-CF metric and its relation to the Twin Branch Evaluation Protocol in the methods section.
- [Introduction] The introduction should expand on the skill storage, retrieval, and application mechanism to make the distillation process reproducible from the description alone.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects of presentation and experimental rigor that we address point by point below. We have revised the manuscript where the concerns are valid and provide explanations for the design choices that remain.
read point-by-point responses
-
Referee: [Abstract and Experiments section] The abstract and experiments section report outperformance and ablation results but provide no quantitative details, error bars, dataset sizes, or statistical tests. This makes it impossible to assess the magnitude and reliability of the claimed gains in visibility and fidelity.
Authors: We agree that the current abstract is high-level and that additional quantitative details would improve interpretability. In the revised version we will incorporate specific metrics (e.g., mean visibility and DSV-CF improvements across engines), report dataset sizes (number of queries and scenarios per engine in MSME-GEO-Bench), include error bars from repeated runs, and reference the statistical tests performed. These elements were summarized in the supplementary material; they will now appear in the main abstract and Experiments section. revision: yes
-
Referee: [§5 (Ablations) and Benchmark construction] The claim that strategy reuse is causal to the gains (and that skills transfer across tasks/engines) rests on ablations within MSME-GEO-Bench, which is constructed from the same real-world queries used for skill distillation. Without explicit held-out query sets, cross-engine transfer tests on unseen distributions, or ablation isolating reuse from per-instance multi-agent optimization, the results risk overfitting to the benchmark's scenario distribution rather than demonstrating progressive, reusable skill learning.
Authors: The concern about potential overfitting is well-taken. The existing §5 ablations already isolate strategy reuse by comparing the full MAGEO system (with skill library) against a per-instance multi-agent baseline that performs editing without reuse; the Twin Branch Evaluation Protocol further enables causal attribution of individual edits. Nevertheless, to strengthen evidence of generalization, the revision will add (i) results on an explicitly held-out query set withheld from skill distillation and (ii) cross-engine transfer experiments using queries drawn from distributions distinct from the original benchmark scenarios. These additions directly address the risk of distribution-specific overfitting. revision: partial
Circularity Check
No significant circularity; derivation rests on experimental validation rather than self-referential definitions.
full rationale
The paper reframes GEO as a strategy-learning problem and introduces MAGEO (multi-agent planning/editing/evaluation with progressive distillation of validated edits into reusable engine-specific skills), plus new evaluation tools (Twin Branch Protocol, DSV-CF metric) and MSME-GEO-Bench. All central claims are grounded in comparative experiments across three engines and ablations that isolate components such as preference modeling and strategy reuse. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described framework; the reported gains are presented as empirical outcomes, not tautological consequences of the inputs. This satisfies the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Geo: Generative engine optimization , author=. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[10]
2025 , eprint=
CC-GSEO-Bench: A Content-Centric Benchmark for Measuring Source Influence in Generative Search Engines , author=. 2025 , eprint=
2025
-
[12]
arXiv preprint arXiv:2510.11438 , year=
What Generative Search Engines Like and How to Optimize Web Content Cooperatively , author=. arXiv preprint arXiv:2510.11438 , year=
-
[13]
arXiv preprint arXiv:2409.15730 (2024)
A systematic review of key retrieval-augmented generation (rag) systems: Progress, gaps, and future directions , author=. arXiv preprint arXiv:2507.18910 , year=
-
[14]
Future Internet , volume=
Chatgpt and open-ai models: A preliminary review , author=. Future Internet , volume=. 2023 , publisher=
2023
-
[17]
Applied System Innovation , volume=
Blockchain and Digital Marketing: An Innovative System for Detecting Fake Comments in Search Engine Optimization Techniques and Enhancing Trust in Digital Markets , author=. Applied System Innovation , volume=. 2025 , publisher=
2025
-
[18]
2021 , eprint=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. 2021 , eprint=
2021
-
[19]
IEEE Transactions on Multimedia , year=
Autogeo: Automating geometric image dataset creation for enhanced geometry understanding , author=. IEEE Transactions on Multimedia , year=
-
[20]
Journal of Sustainability, Policy, and Practice , volume=
AI-Driven SEM Keyword Optimization and Consumer Search Intent Prediction: An Intelligent Approach to Search Engine Marketing , author=. Journal of Sustainability, Policy, and Practice , volume=
-
[21]
AI & SOCIETY , volume=
Chatbots, search engines, and the sealing of knowledges , author=. AI & SOCIETY , volume=. 2025 , publisher=
2025
-
[22]
Proceedings of the 30th International Conference on Intelligent User Interfaces , pages=
Limitations of the llm-as-a-judge approach for evaluating llm outputs in expert knowledge tasks , author=. Proceedings of the 30th International Conference on Intelligent User Interfaces , pages=
-
[23]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
work page internal anchor Pith review arXiv
-
[24]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[25]
Investment in Human Capital: A Theoretical Analysis
Aggarwal, Pranjal and Murahari, Vishvak and Rajpurohit, Tanmay and Kalyan, Ashwin and Narasimhan, Karthik and Deshpande, Ameet , title =. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =. 2024 , isbn =. doi:10.1145/3637528.3671900 , abstract =
-
[26]
Information Processing & Management , volume=
Large language models for scholarly ontology generation: An extensive analysis in the engineering field , author=. Information Processing & Management , volume=. 2026 , publisher=
2026
-
[27]
2025 , eprint=
DeepThink: Aligning Language Models with Domain-Specific User Intents , author=. 2025 , eprint=
2025
-
[29]
Data Science and Engineering , pages=
Retrieval-augmented generation for ai-generated content: A survey , author=. Data Science and Engineering , pages=. 2026 , publisher=
2026
-
[30]
International Conference on Information and Communication Technologies in Education, Research, and Industrial Applications , year=
Theoretical Fundamentals of Search Engine Optimization Based on Machine Learning , author=. International Conference on Information and Communication Technologies in Education, Research, and Industrial Applications , year=
-
[31]
2010 , url=
Everyday Life Information Seeking , author=. 2010 , url=
2010
-
[32]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages =
REPLUG: Retrieval-Augmented Black-Box Language Models , author =. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages =. 2024 , doi =
2024
-
[33]
The Twelfth International Conference on Learning Representations , year =
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection , author =. The Twelfth International Conference on Learning Representations , year =
-
[34]
Advances in Neural Information Processing Systems , volume =
RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs , author =. Advances in Neural Information Processing Systems , volume =. 2024 , url =
2024
-
[35]
Advances in Neural Information Processing Systems , volume =
xRAG: Extreme Context Compression for Retrieval-augmented Generation with One Token , author =. Advances in Neural Information Processing Systems , volume =. 2024 , url =
2024
-
[36]
Advances in Neural Information Processing Systems , volume =
RAGCHECKER: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation , author =. Advances in Neural Information Processing Systems , volume =. 2024 , url =
2024
-
[37]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages =
Search-o1: Agentic Search-Enhanced Large Reasoning Models , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages =. 2025 , doi =
2025
-
[38]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Hierarchical Document Refinement for Long-context Retrieval-augmented Generation , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2025 , doi =
2025
-
[39]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
MetaReflection: Learning Instructions for Language Agents using Past Reflections , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =. 2024 , doi =
2024
-
[40]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =. 2024 , doi =
2024
-
[41]
Advances in Neural Information Processing Systems , volume =
Reflective Multi-Agent Collaboration based on Large Language Models , author =. Advances in Neural Information Processing Systems , volume =. 2024 , url =
2024
-
[42]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
MemoryBank: Enhancing Large Language Models with Long-Term Memory , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2024 , url =
2024
-
[43]
Findings of the Association for Computational Linguistics: ACL 2025 , pages =
R ^3 Mem: Bridging Memory Retention and Retrieval via Reversible Compression , author =. Findings of the Association for Computational Linguistics: ACL 2025 , pages =. 2025 , doi =
2025
-
[44]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
LLM-Rubric: A Multidimensional, Calibrated Approach to Automated Evaluation of Natural Language Texts , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , doi =
2024
-
[45]
The Thirteenth International Conference on Learning Representations , year =
JudgeBench: A Benchmark for Evaluating LLM-Based Judges , author =. The Thirteenth International Conference on Learning Representations , year =
-
[47]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
LungNoduleAgent: A Collaborative Multi-Agent System for Precision Diagnosis of Lung Nodules , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[51]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
SE-Agent: Self-Evolution Trajectory Optimization in Multi-Step Reasoning with LLM-Based Agents , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[54]
AAAI 2026 , year=
Decoupling Continual Semantic Segmentation , author=. AAAI 2026 , year=
2026
-
[56]
Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, and Ameet Deshpande. 2024. Geo: Generative engine optimization. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5--16
2024
-
[57]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. https://openreview.net/forum?id=hSyW5go0v8 Self-rag: Learning to retrieve, generate, and critique through self-reflection . In The Twelfth International Conference on Learning Representations
2024
-
[58]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, and 1 others. 2023. Qwen technical report. arXiv preprint arXiv:2309.16609
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [59]
-
[60]
Xiaohe Bo, Zeyu Zhang, Quanyu Dai, Xueyang Feng, Lei Wang, Rui Li, Xu Chen, and Ji-Rong Wen. 2024. https://proceedings.neurips.cc/paper_files/paper/2024/file/fa54b0edce5eef0bb07654e8ee800cb4-Paper-Conference.pdf Reflective multi-agent collaboration based on large language models . In Advances in Neural Information Processing Systems, volume 37
2024
-
[61]
Qiyuan Chen, Jiahe Chen, Hongsen Huang, Qian Shao, Jintai Chen, Renjie Hua, Hongxia Xu, Ruijia Wu, Ren Chuan, and Jian Wu. 2025 a . https://arxiv.org/abs/2509.05607 Cc-gseo-bench: A content-centric benchmark for measuring source influence in generative search engines . Preprint, arXiv:2509.05607
- [62]
-
[63]
Ruining Chong, Cunliang Kong, Liu Wu, Zhenghao Liu, Ziye Jin, Liner Yang, Yange Fan, Hanghang Fan, and Erhong Yang. 2023. https://doi.org/10.18653/v1/2023.acl-short.105 Leveraging prefix transfer for multi-intent text revision . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 1219-...
-
[64]
Godlevsky, Sergey V
Michael D. Godlevsky, Sergey V. Orekhov, and Elena Orekhova. 2017. https://api.semanticscholar.org/CorpusID:34134110 Theoretical fundamentals of search engine optimization based on machine learning . In International Conference on Information and Communication Technologies in Education, Research, and Industrial Applications
2017
-
[65]
Yifu Guo, Jiaye Lin, Huacan Wang, Yuzhen Han, Sen Hu, Ziyi Ni, Licheng Wang, and Mingguang Chen. 2025 a . Se-agent: Self-evolution trajectory optimization in multi-step reasoning with llm-based agents. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[66]
Yifu Guo, Yuquan Lu, Wentao Zhang, Zishan Xu, Dexia Chen, Siyu Zhang, Yizhe Zhang, and Ruixuan Wang. 2025 b . Decoupling continual semantic segmentation. AAAI 2026
2025
-
[67]
Priyanshu Gupta, Shashank Kirtania, Ananya Singha, Sumit Gulwani, Arjun Radhakrishna, Gustavo Soares, and Sherry Shi. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.477 Metareflection: Learning instructions for language agents using past reflections . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8369-...
-
[68]
Zihan Huang, Tao Wu, Wang Lin, Shengyu Zhang, Jingyuan Chen, and Fei Wu. 2025. Autogeo: Automating geometric image dataset creation for enhanced geometry understanding. IEEE Transactions on Multimedia
2025
-
[69]
Jiajie Jin, Xiaoxi Li, Guanting Dong, Yuyao Zhang, Yutao Zhu, Yongkang Wu, Zhonghua Li, Ye Qi, and Zhicheng Dou. 2025. https://doi.org/10.18653/v1/2025.acl-long.176 Hierarchical document refinement for long-context retrieval-augmented generation . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa...
-
[70]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2021. https://arxiv.org/abs/2005.11401 Retrieval-augmented generation for knowledge-intensive nlp tasks . Preprint, arXiv:2005.11401
work page internal anchor Pith review arXiv 2021
-
[71]
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. 2025 a . https://doi.org/10.18653/v1/2025.emnlp-main.276 Search-o1: Agentic search-enhanced large reasoning models . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5420--5438, Suzhou, China
- [72]
-
[73]
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.992 Encouraging divergent thinking in large language models through multi-agent debate . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17889--179...
-
[74]
Nora Freya Lindemann. 2025. Chatbots, search engines, and the sealing of knowledges. AI & SOCIETY, 40(6):5063--5076
2025
- [75]
-
[76]
Konstantinos I Roumeliotis and Nikolaos D Tselikas. 2023. Chatgpt and open-ai models: A preliminary review. Future Internet, 15(6):192
2023
-
[77]
Dongyu Ru, Lin Qiu, Xiangkun Hu, Tianhang Zhang, Peng Shi, Shuaichen Chang, Cheng Jiayang, Cunxiang Wang, Shichao Sun, Huanyu Li, Zizhao Zhang, Binjie Wang, Jiarong Jiang, Tong He, Zhiguo Wang, Pengfei Liu, Yue Zhang, and Zheng Zhang. 2024. https://proceedings.neurips.cc/paper_files/paper/2024/file/27245589131d17368cccdfa990cbf16e-Paper-Datasets_and_Bench...
-
[78]
Reijo Savolainen. 2010. https://api.semanticscholar.org/CorpusID:197539279 Everyday life information seeking
2010
-
[79]
Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Richard James, Mike Lewis, Luke Zettlemoyer, and Wen tau Yih. 2024. https://doi.org/10.18653/v1/2024.naacl-long.463 Replug: Retrieval-augmented black-box language models . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Langu...
-
[80]
Me Sun and Le Yu. 2025. Ai-driven sem keyword optimization and consumer search intent prediction: An intelligent approach to search engine marketing. Journal of Sustainability, Policy, and Practice, 1(3):26--39
2025
-
[81]
Annalisa Szymanski, Noah Ziems, Heather A Eicher-Miller, Toby Jia-Jun Li, Meng Jiang, and Ronald A Metoyer. 2025. Limitations of the llm-as-a-judge approach for evaluating llm outputs in expert knowledge tasks. In Proceedings of the 30th International Conference on Intelligent User Interfaces, pages 952--966
2025
-
[82]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, and 1 others. 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[83]
Xiaoqiang Wang, Suyuchen Wang, Yun Zhu, and Bang Liu. 2025. https://doi.org/10.18653/v1/2025.findings-acl.235 R ^3 mem: Bridging memory retention and retrieval via reversible compression . In Findings of the Association for Computational Linguistics: ACL 2025, pages 4541--4557, Vienna, Austria
- [84]
-
[85]
Cheng Yang, Hui Jin, Xinlei Yu, Zhipeng Wang, Yaoqun Liu, Fenglei Fan, Dajiang Lei, Gangyong Jia, Changmiao Wang, and Ruiquan Ge. 2026. Lungnoduleagent: A collaborative multi-agent system for precision diagnosis of lung nodules. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 29793--29801
2026
- [86]
-
[87]
Zhiyuan Yao, Zishan Xu, Yifu Guo, Zhiguang Han, Cheng Yang, Shuo Zhang, Weinan Zhang, Xingshan Zeng, and Weiwen Liu. 2026. Toolace-mcp: Generalizing history-aware routing from mcp tools to the agent web. ACL 2026, arXiv preprint arXiv:2601.08276
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [88]
-
[89]
Xinlei Yu, Chengming Xu, Zhangquan Chen, Yudong Zhang, Shilin Lu, Cheng Yang, Jiangning Zhang, Shuicheng Yan, and Xiaobin Hu. 2025. Visual document understanding and reasoning: A multi-agent collaboration framework with agent-wise adaptive test-time scaling. arXiv preprint arXiv:2508.03404
-
[90]
Yue Yu, Wei Ping, Zihan Liu, Boxin Wang, Jiaxuan You, Chao Zhang, Mohammad Shoeybi, and Bryan Catanzaro. 2024. https://proceedings.neurips.cc/paper_files/paper/2024/hash/db93ccb6cf392f352570dd5af0a223d3-Abstract-Conference.html Rankrag: Unifying context ranking with retrieval-augmented generation in llms . In Advances in Neural Information Processing Syst...
2024
-
[91]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. https://ojs.aaai.org/index.php/AAAI/article/view/29946 Memorybank: Enhancing large language models with long-term memory . In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19724--19731
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.