Recognition: unknown
RF-HiT: Rectified Flow Hierarchical Transformer for General Medical Image Segmentation
Pith reviewed 2026-05-10 02:15 UTC · model grok-4.3
The pith
A rectified flow hierarchical transformer segments medical images with high accuracy at low computational cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
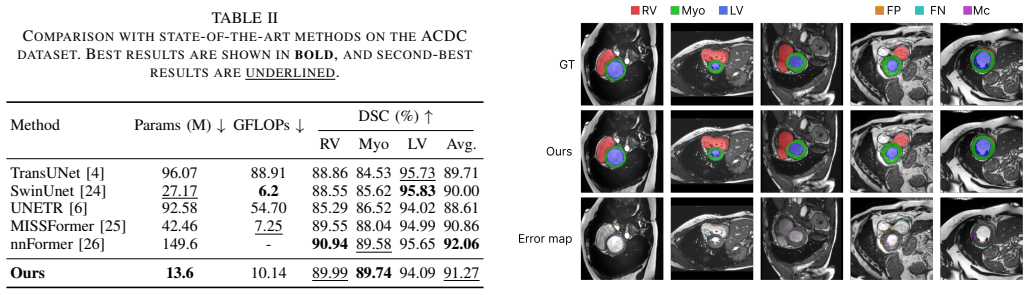
RF-HiT achieves accurate segmentation by integrating an hourglass transformer backbone with a multi-scale hierarchical encoder that conditions features anatomically, and by applying rectified flow to reduce inference to a few discretization steps with linear complexity, resulting in 91.27 percent mean Dice on the ACDC dataset and 87.40 percent on BraTS 2021 using 10.14 GFLOPs and 13.6 million parameters.
What carries the argument
The rectified flow mechanism paired with the hierarchical encoder and learnable interpolation for fusing multi-resolution features.
Load-bearing premise
That the rectified flow with three discretization steps combined with the hierarchical structure can maintain high segmentation accuracy without additional computational steps or model size.
What would settle it
Running the model with one discretization step on the ACDC dataset and checking if the mean Dice score remains above 85 percent.
Figures

read the original abstract
Accurate medical image segmentation requires both long-range contextual reasoning and precise boundary delineation, a task where existing transformer- and diffusion-based paradigms are frequently bottlenecked by quadratic computational complexity and prohibitive inference latency. We propose RF-HiT, a Rectified Flow Hierarchical Transformer that integrates an hourglass transformer backbone with a multi-scale hierarchical encoder for anatomically guided feature conditioning. Unlike prior diffusion-based approaches, RF-HiT leverages rectified flow with efficient transformer blocks to achieve linear complexity while requiring only a few discretization steps. The model further fuses conditioning features across resolutions via learnable interpolation, enabling effective multi-scale representation with minimal computational overhead. As a result, RF-HiT achieves a strong efficiency-performance trade-off, requiring only 10.14 GFLOPs, 13.6M parameters, and inference in as few as three steps. Despite its compact design, RF-HiT attains 91.27% mean Dice on ACDC and 87.40% on BraTS 2021, achieving performance comparable to or exceeding that of significantly more intensive architectures. This demonstrates its strong potential as a robust, computationally efficient foundation for real-time clinical segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RF-HiT, a Rectified Flow Hierarchical Transformer for medical image segmentation. It integrates an hourglass transformer backbone with a multi-scale hierarchical encoder and leverages rectified flow to enable efficient inference in a small number of discretization steps. The central empirical claim is that this yields strong performance (91.27% mean Dice on ACDC, 87.40% on BraTS 2021) at low cost (10.14 GFLOPs, 13.6M parameters) while matching or exceeding more computationally intensive transformer and diffusion baselines.
Significance. If the reported efficiency-performance trade-off is confirmed by the full experimental protocol, baselines, and ablations, the work would be significant for real-time clinical segmentation. It directly targets the quadratic complexity and high inference latency of prior transformer and diffusion approaches by combining rectified flow's few-step property with hierarchical conditioning and learnable multi-scale fusion. The compact design and explicit complexity numbers position it as a practical foundation model for resource-limited medical imaging settings.
major comments (2)
- [§3.2] §3.2 (Rectified Flow Integration): The claim that rectified flow with only three discretization steps preserves boundary precision for segmentation (rather than generation) is load-bearing for the efficiency advantage; an ablation varying the step count and reporting boundary-specific metrics (e.g., Hausdorff distance) is needed to substantiate that fewer steps do not degrade fine anatomical detail.
- [Table 2] Table 2 (Efficiency Comparison): The GFLOPs and parameter counts for RF-HiT must be shown to include the full cost of the hierarchical encoder and learnable interpolation; if these operations are omitted or approximated, the reported 10.14 GFLOPs advantage over baselines would be overstated.
minor comments (3)
- [Abstract] Abstract: The statement 'achieve linear complexity' should be qualified with the specific attention mechanism or hierarchical design that avoids quadratic scaling, as standard transformer blocks remain quadratic.
- [Figure 1] Figure 1: Add explicit labels for the conditioning feature fusion paths and the rectified-flow sampling module to improve readability of the architecture diagram.
- [§4.1] §4.1 (Datasets and Metrics): Confirm that all compared methods were evaluated on identical train/validation/test splits and input resolutions; otherwise the Dice scores are not directly comparable.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and the constructive comments on the rectified flow integration and efficiency reporting. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Rectified Flow Integration): The claim that rectified flow with only three discretization steps preserves boundary precision for segmentation (rather than generation) is load-bearing for the efficiency advantage; an ablation varying the step count and reporting boundary-specific metrics (e.g., Hausdorff distance) is needed to substantiate that fewer steps do not degrade fine anatomical detail.
Authors: We agree that an explicit ablation on discretization steps with boundary metrics would strengthen the evidence for the three-step inference. In the revised manuscript, we will add a new ablation study reporting both mean Dice and Hausdorff distance for 1, 3, 5, and 10 steps on the ACDC and BraTS 2021 datasets. This will demonstrate that performance plateaus after three steps with no meaningful degradation in boundary precision, directly supporting the efficiency claims. revision: yes
-
Referee: [Table 2] Table 2 (Efficiency Comparison): The GFLOPs and parameter counts for RF-HiT must be shown to include the full cost of the hierarchical encoder and learnable interpolation; if these operations are omitted or approximated, the reported 10.14 GFLOPs advantage over baselines would be overstated.
Authors: The 10.14 GFLOPs and 13.6M parameter counts were obtained via full-model profiling that includes the hourglass backbone, multi-scale hierarchical encoder, and all learnable interpolation operations. No components were omitted or approximated. To address the concern explicitly, we will add a clarifying footnote to Table 2 detailing the measurement protocol and confirming inclusion of every module. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces RF-HiT as a novel architecture integrating rectified flow with a hierarchical transformer backbone and multi-scale encoder. Its central claims consist of empirical Dice scores (91.27% on ACDC, 87.40% on BraTS 2021) obtained via standard training and evaluation on public benchmarks, with reported complexity metrics (10.14 GFLOPs, 13.6M parameters, 3 inference steps). No equations, derivations, or self-referential definitions appear that reduce these results to fitted inputs or prior outputs by construction. The description relies on architectural descriptions and benchmark comparisons rather than any load-bearing self-citation chains or ansatz smuggling. The derivation chain is self-contained through experimental validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inInternational Conference on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241
2015
-
[2]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[3]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[4]
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
J. Chen, Y . Lu, Q. Yu, X. Luo, E. Adeli, Y . Wang, L. Lu, A. L. Yuille, and Y . Zhou, “Transunet: Transformers make strong encoders for medical image segmentation,”arXiv preprint arXiv:2102.04306, 2021
work page internal anchor Pith review arXiv 2021
-
[5]
Unetr: Transformers for 3d medical image segmentation,
A. Hatamizadeh, Y . Tang, V . Nath, D. Yang, A. Myronenko, B. Land- man, H. R. Roth, and D. Xu, “Unetr: Transformers for 3d medical image segmentation,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, 2022, pp. 574–584
2022
-
[6]
Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images,
A. Hatamizadeh, V . Nath, Y . Tang, D. Yang, H. R. Roth, and D. Xu, “Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images,” inInternational MICCAI brainlesion workshop. Springer, 2021, pp. 272–284
2021
-
[7]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022
2021
-
[8]
Scalable high-resolution pixel-space image synthesis with hourglass diffusion transformers,
K. Crowson, S. A. Baumann, A. Birch, T. M. Abraham, D. Z. Kaplan, and E. Shippole, “Scalable high-resolution pixel-space image synthesis with hourglass diffusion transformers,” inForty-first International Con- ference on Machine Learning, 2024
2024
-
[9]
Neighborhood attention transformer,
A. Hassani, S. Walton, J. Li, S. Li, and H. Shi, “Neighborhood attention transformer,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 6185–6194
2023
-
[10]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840– 6851, 2020
2020
-
[11]
Diffusion models for implicit image segmentation ensembles,
J. Wolleb, R. Sandk ¨uhler, F. Bieder, P. Valmaggia, and P. C. Cattin, “Diffusion models for implicit image segmentation ensembles,” inIn- ternational conference on medical imaging with deep learning. PMLR, 2022, pp. 1336–1348
2022
-
[12]
Medsegdiff-v2: Diffusion- based medical image segmentation with transformer,
J. Wu, W. Ji, H. Fu, M. Xu, Y . Jin, and Y . Xu, “Medsegdiff-v2: Diffusion- based medical image segmentation with transformer,” inProceedings of the AAAI conference on artificial intelligence, vol. 38, no. 6, 2024, pp. 6030–6038
2024
-
[13]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
X. Liu, C. Gong, and Q. Liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow,”arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review arXiv 2022
-
[14]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4195–4205
2023
-
[16]
Movie Gen: A Cast of Media Foundation Models
A. Polyak, A. Zohar, A. Brown, A. Tjandra, A. Sinha, A. Lee, A. Vyas, B. Shi, C.-Y . Ma, C.-Y . Chuanget al., “Movie gen: A cast of media foundation models,”arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review arXiv 2024
-
[17]
T. Amit, T. Shaharbany, E. Nachmani, and L. Wolf, “Segdiff: Im- age segmentation with diffusion probabilistic models,”arXiv preprint arXiv:2112.00390, 2021
-
[18]
Diff-unet: A diffu- sion embedded network for volumetric segmentation,
Z. Xing, L. Wan, H. Fu, G. Yang, and L. Zhu, “Diff-unet: A diffu- sion embedded network for volumetric segmentation,”arXiv preprint arXiv:2303.10326, 2023
-
[19]
Segdt: A dif- fusion transformer-based segmentation model for medical imaging,
S. E. Bekhouche, G. Maroun, F. Dornaika, and A. Hadid, “Segdt: A dif- fusion transformer-based segmentation model for medical imaging,” in International Conference on Image Analysis and Processing. Springer, 2025, pp. 54–66
2025
-
[20]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European conference on computer vision. Springer, 2020, pp. 213– 229
2020
-
[21]
Transbts: Multimodal brain tumor segmentation using transformer,
W. Wang, C. Chen, M. Ding, H. Yu, S. Zha, and J. Li, “Transbts: Multimodal brain tumor segmentation using transformer,” inInterna- tional conference on medical image computing and computer-assisted intervention. Springer, 2021, pp. 109–119
2021
-
[22]
Deep learning techniques for automatic mri cardiac multi-structures segmentation and diagnosis: is the problem solved?
O. Bernard, A. Lalande, C. Zotti, F. Cervenansky, X. Yang, P.-A. Heng, I. Cetin, K. Lekadir, O. Camara, M. A. G. Ballesteret al., “Deep learning techniques for automatic mri cardiac multi-structures segmentation and diagnosis: is the problem solved?”IEEE transactions on medical imaging, vol. 37, no. 11, pp. 2514–2525, 2018
2018
-
[23]
U. Baid, S. Ghodasara, S. Mohan, M. Bilello, E. Calabrese, E. Colak, K. Farahani, J. Kalpathy-Cramer, F. C. Kitamura, S. Patiet al., “The rsna-asnr-miccai brats 2021 benchmark on brain tumor segmentation and radiogenomic classification,”arXiv preprint arXiv:2107.02314, 2021
work page internal anchor Pith review arXiv 2021
-
[24]
Swin-unet: Unet-like pure transformer for medical image segmenta- tion,
H. Cao, Y . Wang, J. Chen, D. Jiang, X. Zhang, Q. Tian, and M. Wang, “Swin-unet: Unet-like pure transformer for medical image segmenta- tion,” inEuropean conference on computer vision. Springer, 2022, pp. 205–218
2022
-
[25]
Missformer: An effective med- ical image segmentation transformer,
X. Huang, Z. Deng, D. Li, and X. Yuan, “Missformer: An effective med- ical image segmentation transformer,”arXiv preprint arXiv:2109.07162, 2021
-
[26]
nn- former: V olumetric medical image segmentation via a 3d transformer,
H.-Y . Zhou, J. Guo, Y . Zhang, X. Han, L. Yu, L. Wang, and Y . Yu, “nn- former: V olumetric medical image segmentation via a 3d transformer,” IEEE transactions on image processing, vol. 32, pp. 4036–4045, 2023
2023
-
[27]
Swin unet3d: a three-dimensional medical image segmentation network com- bining vision transformer and convolution,
Y . Cai, Y . Long, Z. Han, M. Liu, Y . Zheng, W. Yang, and L. Chen, “Swin unet3d: a three-dimensional medical image segmentation network com- bining vision transformer and convolution,”BMC medical informatics and decision making, vol. 23, no. 1, p. 33, 2023
2023
-
[28]
Diffbts: A lightweight diffusion model for 3d multimodal brain tumor segmentation,
Z. Nie, J. Yang, C. Li, Y . Wang, and J. Tang, “Diffbts: A lightweight diffusion model for 3d multimodal brain tumor segmentation,”Sensors, vol. 25, no. 10, p. 2985, 2025
2025
-
[29]
Segtransvae: Hybrid cnn-transformer with regularization for medical image segmentation,
Q.-D. Pham, H. Nguyen-Truong, N. N. Phuong, K. N. Nguyen, C. D. Nguyen, T. Bui, and S. Q. Truong, “Segtransvae: Hybrid cnn-transformer with regularization for medical image segmentation,” in2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI). IEEE, 2022, pp. 1–5
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.