Recognition: unknown
Exploring Language-Agnosticity in Function Vectors: A Case Study in Machine Translation
Pith reviewed 2026-05-10 02:46 UTC · model grok-4.3
The pith
Translation function vectors extracted from one English-to-target direction transfer to improve token ranking in other languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across three decoder-only multilingual LLMs, translation FVs extracted from a single English→Target direction transfer to other target languages, consistently improving the rank of correct translation tokens across multiple unseen languages. Ablation results show that removing the FV degrades translation across languages with limited impact on unrelated tasks. Base-model FVs transfer to instruction-tuned variants and partially generalize from word-level to sentence-level translation.
What carries the argument
Function vectors extracted from model activations during in-context learning, tested for their ability to carry translation behavior independently of the specific target language.
If this is right
- A single FV extraction can support translation into multiple target languages without new extractions.
- Removing the FV specifically harms translation performance while leaving unrelated tasks mostly intact.
- Vectors from base models remain useful after instruction tuning.
- The effect holds from isolated word translations to full sentences in limited tests.
Where Pith is reading between the lines
- This pattern could lower the cost of building multilingual translation systems by reusing one vector across languages.
- Similar language-agnostic behavior might appear in other task vectors such as summarization or reasoning.
- Future work could test whether the same vectors work when source and target languages both differ from the extraction pair.
Load-bearing premise
Observed gains in token ranking come from the language-agnostic properties of the extracted vectors rather than from the in-context examples or other setup details.
What would settle it
A controlled test showing that random vectors or in-context examples alone produce equal or larger rank improvements than the extracted FVs when applied to new target languages.
Figures







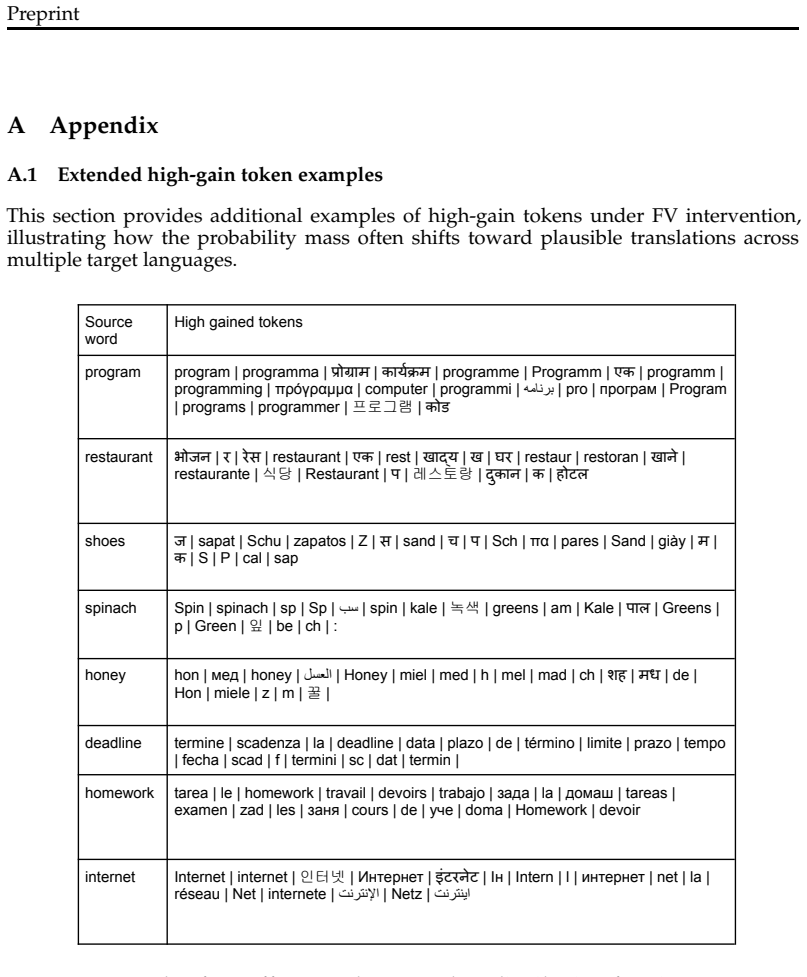




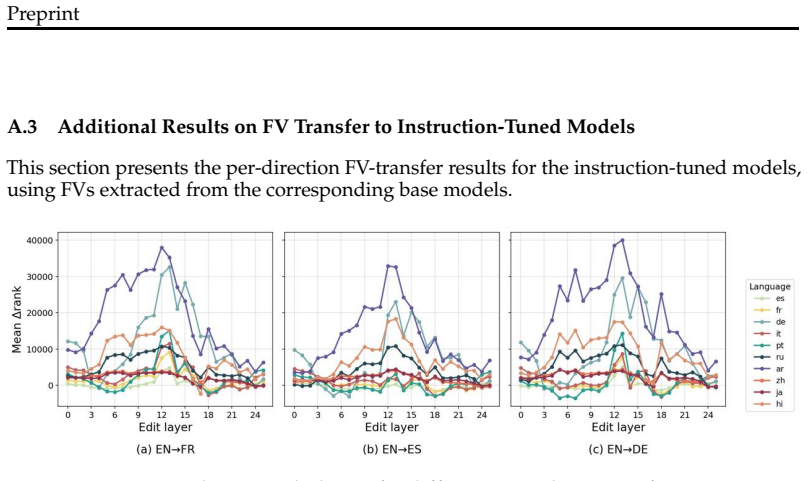
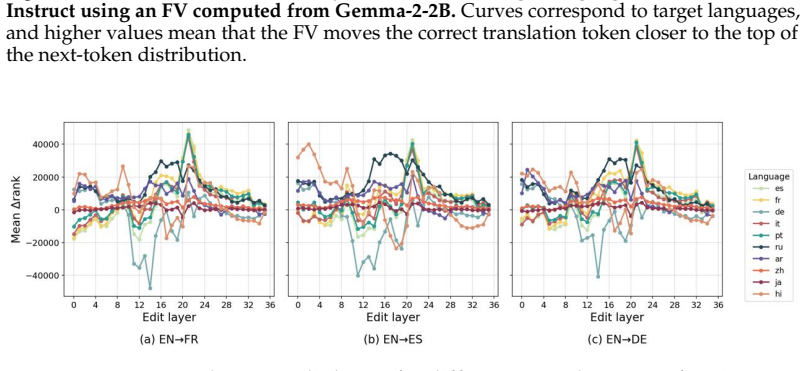
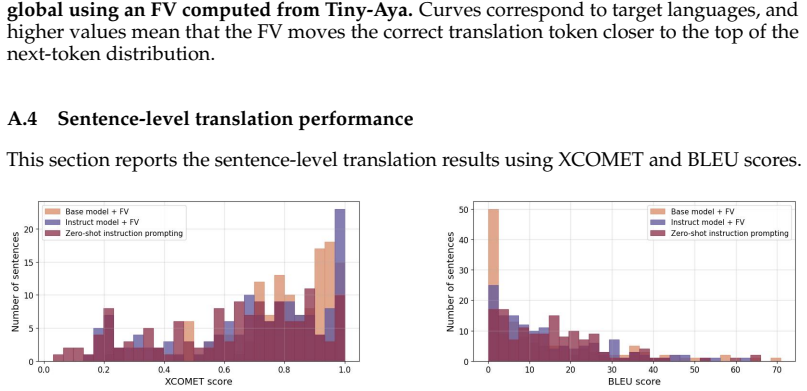
read the original abstract
Function vectors (FVs) are vector representations of tasks extracted from model activations during in-context learning. While prior work has shown that multilingual model representations can be language-agnostic, it remains unclear whether the same holds for function vectors. We study whether FVs exhibit language-agnosticity, using machine translation as a case study. Across three decoder-only multilingual LLMs, we find that translation FVs extracted from a single English$\rightarrow$Target direction transfer to other target languages, consistently improving the rank of correct translation tokens across multiple unseen languages. Ablation results show that removing the FV degrades translation across languages with limited impact on unrelated tasks. We further show that base-model FVs transfer to instruction-tuned variants and partially generalize from word-level to sentence-level translation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates language-agnosticity of function vectors (FVs) extracted from decoder-only multilingual LLMs during in-context learning, using machine translation as a case study. It claims that FVs derived from a single English-to-target direction transfer to improve the rank of correct translation tokens on multiple unseen target languages across three models, with ablations showing performance degradation on translation when the FV is removed but limited impact on unrelated tasks; additional results indicate transfer to instruction-tuned variants and partial generalization from word- to sentence-level translation.
Significance. If the central claim holds after addressing controls, the work would strengthen evidence that FVs can encode transferable, language-independent task functions in LLMs, with potential implications for cross-lingual model editing and efficient multilingual in-context learning. The consistency of results across three models and the use of ablation experiments to isolate the FV contribution are notable empirical strengths.
major comments (2)
- [Methods / Experimental Setup] The experimental setup does not include a control condition that holds the in-context examples, prompt format, and model fixed while substituting the extracted FV with an orthogonal or random vector. This is load-bearing for the language-agnostic interpretation, as improvements in correct-token rank on unseen targets could arise from the shared examples or model biases rather than properties of the FV itself (see abstract and skeptic note on weakest assumption).
- [Results / Ablations] Ablation results are reported as degrading translation performance, but without details on the exact ablation method (e.g., zeroing vs. replacing with noise), statistical significance tests, or per-language effect sizes, it is difficult to confirm that the FV effect is isolated from other factors.
minor comments (2)
- [Methods] Clarify the precise definition and extraction procedure for FVs in the methods section, including any hyperparameters or layer choices, to aid reproducibility.
- [Abstract] The abstract mentions 'consistent improvements' but does not specify the magnitude or variance; adding quantitative summaries (e.g., average rank improvement) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the strength of evidence for language-agnosticity in function vectors. We address each major point below and commit to revisions that strengthen the experimental controls and reporting without altering the core claims.
read point-by-point responses
-
Referee: The experimental setup does not include a control condition that holds the in-context examples, prompt format, and model fixed while substituting the extracted FV with an orthogonal or random vector. This is load-bearing for the language-agnostic interpretation, as improvements in correct-token rank on unseen targets could arise from the shared examples or model biases rather than properties of the FV itself (see abstract and skeptic note on weakest assumption).
Authors: We agree that a direct control substituting the extracted FV with a random or orthogonal vector (while fixing examples, prompt, and model) would more rigorously isolate the FV's contribution from prompt or model biases. Our current ablations demonstrate performance degradation upon FV removal, and the cross-lingual transfer to unseen targets provides supporting evidence that the effect is not solely from the English-to-single-target examples. Nevertheless, to address the concern directly, we will add the requested control experiments in the revised manuscript, including comparisons to random vectors sampled from the activation distribution and to orthogonal vectors in the same subspace. revision: yes
-
Referee: Ablation results are reported as degrading translation performance, but without details on the exact ablation method (e.g., zeroing vs. replacing with noise), statistical significance tests, or per-language effect sizes, it is difficult to confirm that the FV effect is isolated from other factors.
Authors: We appreciate this observation on reporting clarity. The ablation in the current manuscript consists of zeroing the FV activations at the relevant layers during inference. We will revise the Methods section to specify this procedure explicitly, add statistical significance tests (e.g., paired comparisons across multiple seeds or languages), and report per-language effect sizes for the change in correct-token rank. These details will be included in the revised results and supplementary material. revision: yes
Circularity Check
No circularity: empirical transfer results independent of inputs
full rationale
The paper reports experimental findings on function vector extraction and transfer across languages in decoder-only LLMs, using ablation studies and token-rank improvements as evidence. No derivations, equations, or first-principles predictions are presented that reduce to fitted parameters, self-definitions, or self-citation chains. Claims rest on observable outcomes from controlled transfer and ablation setups rather than any renaming, ansatz smuggling, or uniqueness imported from prior author work. The central language-agnosticity conclusion is tested via cross-lingual generalization, which does not collapse to the extraction procedure by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Function vectors extracted from activations during in-context learning capture task-specific functions in a language-independent way.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Advances in Neural Information Processing Systems , year =
Training language models to follow instructions with human feedback , author =. Advances in Neural Information Processing Systems , year =
-
[9]
Advances in Neural Information Processing Systems , year=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , year=
-
[10]
The Twelfth International Conference on Learning Representations , year=
Function Vectors in Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[11]
2024 , howpublished =
google/gemma-2-2b-it: Model Card , author =. 2024 , howpublished =
2024
-
[12]
2024 , howpublished =
Llama 3.2: Model Cards and Prompt Formats , author =. 2024 , howpublished =
2024
-
[13]
2024 , journal =
Gemma 2: Improving Open Language Models at a Practical Size , author =. 2024 , journal =
2024
-
[14]
2024 , howpublished =
meta-llama/Llama-3.2-3B-Instruct: Model Card , author =. 2024 , howpublished =
2024
-
[15]
Findings of the Association for Computational Linguistics: EMNLP 2023 , year =
In-Context Learning Creates Task Vectors , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , year =
2023
-
[16]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Steering Llama 2 via Contrastive Activation Addition , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[17]
Editing Models with Task Arithmetic
Editing Models with Task Arithmetic , author =. arXiv preprint arXiv:2212.04089 , year =
work page internal anchor Pith review arXiv
-
[19]
Linear Representations of Sentiment in Large Language Models
Linear Representations of Sentiment in Large Language Models , author =. arXiv preprint arXiv:2310.15154 , year =
work page internal anchor Pith review arXiv
-
[20]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
Persona Vectors: Monitoring and Controlling Character Traits in Language Models , author =. arXiv preprint arXiv:2507.21509 , year =
work page internal anchor Pith review arXiv
-
[21]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[22]
arXiv preprint arXiv:2205.05124 , year=
Extracting Latent Steering Vectors from Pretrained Language Models , author =. Findings of the Association for Computational Linguistics: ACL , year =. 2205.05124 , archivePrefix =
-
[23]
Steering Language Models With Activation Engineering
Steering Language Models With Activation Engineering , author =. 2023 , url =. 2308.10248 , archivePrefix =
work page internal anchor Pith review arXiv 2023
-
[24]
In-context Vectors: Making In Context Learning More Effective and Controllable Through Latent Space Steering , author =. 2023 , url =. 2311.06668 , archivePrefix =
-
[25]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou and Long Phan and Sarah Chen and James Campbell and Phillip Guo and Richard Ren and Ian Reynolds and Aditi Raghunathan and Percy Liang and Tatsunori Hashimoto and others , year =. Representation Engineering: A Top-Down Approach to. 2310.01405 , archivePrefix =
work page internal anchor Pith review arXiv
-
[26]
Gao, Leo and Tow, Jonathan and Abbasi, Stella Biderman and others , booktitle=. The
-
[27]
ACL , year=
HellaSwag: Can a Machine Really Finish Your Sentence? , author=. ACL , year=
-
[28]
AAAI , year=
PIQA: Reasoning about Physical Commonsense in Natural Language , author=. AAAI , year=
-
[29]
Think You Have Solved Question Answering? Try
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and others , booktitle=. Think You Have Solved Question Answering? Try
-
[30]
EMNLP , year=
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering , author=. EMNLP , year=
-
[31]
Workshops at EMNLP , year=
Crowdsourcing Multiple Choice Science Questions , author=. Workshops at EMNLP , year=
-
[32]
AAAI , year=
WinoGrande: An Adversarial Winograd Schema Challenge at Scale , author=. AAAI , year=
-
[33]
NAACL , year=
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions , author=. NAACL , year=
-
[34]
AAAI Spring Symposium , year=
Choice of Plausible Alternatives: An Evaluation of Commonsense Causal Reasoning , author=. AAAI Spring Symposium , year=
-
[35]
How Multilingual is Multilingual BERT ?
Pires, Telmo and Schlinger, Eva and Garrette, Dan , booktitle =. How Multilingual is Multilingual. 2019 , address =. doi:10.18653/v1/P19-1493 , pages =
-
[36]
Beto, bentz, becas: The surprising cross-lingual effectiveness of BERT
Wu, Shijie and Dredze, Mark , booktitle =. Beto, Bentz, Becas: The Surprising Cross-Lingual Effectiveness of. 2019 , address =. doi:10.18653/v1/D19-1077 , pages =
-
[37]
Separating Tongue from Thought: Activation Patching Reveals Language-Agnostic Concept Representations in Transformers , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = jul, year =. doi:10.18653/v1/2025.acl-long.1536 , pages =
-
[38]
2026 , howpublished =
2026
-
[39]
2024 , eprint =
The Llama 3 Herd of Models , author =. 2024 , eprint =
2024
-
[40]
2024 , howpublished =
Gemma 2: Improving Open Language Models at a Practical Size , author =. 2024 , howpublished =
2024
-
[41]
2024 , howpublished =
Llama 3.2 Model Cards and Prompt Formats , author =. 2024 , howpublished =
2024
-
[42]
Goyal, Naman and Gao, Cynthia and Chaudhary, Vishrav and Chen, Peng-Jen and Wenzek, Guillaume and Ju, Da and Krishnan, Sanjana and Ranzato, Marc'Aurelio and Guzm. The. 2022 , eprint =
2022
-
[43]
No Language Left Behind: Scaling Human-Centered Machine Translation
No Language Left Behind: Scaling Human-Centered Machine Translation , author =. arXiv preprint arXiv:2207.04672 , year =
work page internal anchor Pith review arXiv
-
[44]
2025 , booktitle =
Exploring the Translation Mechanism of Large Language Models , author =. 2025 , booktitle =
2025
-
[45]
Disentangling meaning from language in LLM-based machine translation , author =. 2026 , journal =. 2602.04613 , archivePrefix=
-
[46]
The Thirteenth International Conference on Learning Representations , year=
Improving Instruction-Following in Language Models through Activation Steering , author=. The Thirteenth International Conference on Learning Representations , year=
-
[47]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[48]
Prompting P a LM for Translation: Assessing Strategies and Performance
Vilar, David and Freitag, Markus and Cherry, Colin and Luo, Jiaming and Ratnakar, Viresh and Foster, George. Prompting P a LM for Translation: Assessing Strategies and Performance. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.859
-
[49]
Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers
Wendler, Chris and Veselovsky, Veniamin and Monea, Giovanni and West, Robert. Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.820
-
[50]
2024 , eprint=
The Platonic Representation Hypothesis , author=. 2024 , eprint=
2024
-
[51]
On the Similarity of Circuits across Languages: a Case Study on the Subject-verb Agreement Task
Ferrando, Javier and Costa-juss \`a , Marta R. On the Similarity of Circuits across Languages: a Case Study on the Subject-verb Agreement Task. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.591
-
[52]
Brinkmann, Jannik and Wendler, Chris and Bartelt, Christian and Mueller, Aaron. Large Language Models Share Representations of Latent Grammatical Concepts Across Typologically Diverse Languages. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1:...
-
[53]
The Thirteenth International Conference on Learning Representations , year=
The Same but Different: Structural Similarities and Differences in Multilingual Language Modeling , author=. The Thirteenth International Conference on Learning Representations , year=
-
[54]
Lindsey, Jack and Gurnee, Wes and Ameisen, Emmanuel and Chen, Brian and Pearce, Adam and Turner, Nicholas L. and Citro, Craig and Abrahams, David and Carter, Shan and Hosmer, Basil and Marcus, Jonathan and Sklar, Michael and Templeton, Adly and Bricken, Trenton and McDougall, Callum and Cunningham, Hoagy and Henighan, Thomas and Jermyn, Adam and Jones, An...
-
[55]
How Do Multilingual Language Models Remember Facts?
Fierro, Constanza and Foroutan, Negar and Elliott, Desmond and S gaard, Anders. How Do Multilingual Language Models Remember Facts?. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.827
-
[56]
2021 , pages =
Xue, Linting and Constant, Noah and Roberts, Adam and Kale, Mihir and Al-Rfou, Rami and Siddhant, Aditya and Barua, Aditya and Raffel, Colin , booktitle =. 2021 , pages =
2021
-
[57]
Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model , author =. arXiv preprint arXiv:2402.07827 , year =
-
[58]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Revealing the Parallel Multilingual Learning within Large Language Models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=. 2024 , address=
2024
-
[59]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2024 , address=
2024
-
[60]
A Question of Degree: Exploring the Role of Language Proficiency in
Wenhao Zhu and Hongyi Liu and Shujian Huang and Lei Li and Jiajun Chen and Fei Yuan , booktitle=. A Question of Degree: Exploring the Role of Language Proficiency in. 2024 , address=
2024
-
[61]
Explainability and Interpretability of Multilingual Large Language Models: A Survey
Resck, Lucas and Augenstein, Isabelle and Korhonen, Anna. Explainability and Interpretability of Multilingual Large Language Models: A Survey. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1033
-
[62]
BLEU : a Method for Automatic Evaluation of Machine Translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. BLEU : a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002
2002
-
[63]
and Rei, Ricardo and Ferrer, Cristina and de Souza, Jos \'e G
Guerreiro, Nuno M. and Rei, Ricardo and Ferrer, Cristina and de Souza, Jos \'e G. C. and Martins, Andr \'e F. T. xCOMET : Transparent Machine Translation Evaluation through Fine-grained Error Detection. Transactions of the Association for Computational Linguistics. 2024
2024
-
[64]
2024 , eprint=
A Primer on the Inner Workings of Transformer-based Language Models , author=. 2024 , eprint=
2024
-
[65]
Unsupervised Cross-lingual Representation Learning at Scale
Conneau, Alexis and Khandelwal, Kartikay and Goyal, Naman and Chaudhary, Vishrav and Wenzek, Guillaume and Guzm \'a n, Francisco and Grave, Edouard and Ott, Myle and Zettlemoyer, Luke and Stoyanov, Veselin. Unsupervised Cross-lingual Representation Learning at Scale. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. ...
-
[66]
Analyzing the Mono- and Cross-Lingual Pretraining Dynamics of Multilingual Language Models
Blevins, Terra and Gonen, Hila and Zettlemoyer, Luke. Analyzing the Mono- and Cross-Lingual Pretraining Dynamics of Multilingual Language Models. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.234
-
[67]
Proceedings of the 41st International Conference on Machine Learning , pages =
A Closer Look at the Limitations of Instruction Tuning , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.