Recognition: unknown
SceneOrchestra: Efficient Agentic 3D Scene Synthesis via Full Tool-Call Trajectory Generation
Pith reviewed 2026-05-10 03:19 UTC · model grok-4.3
The pith
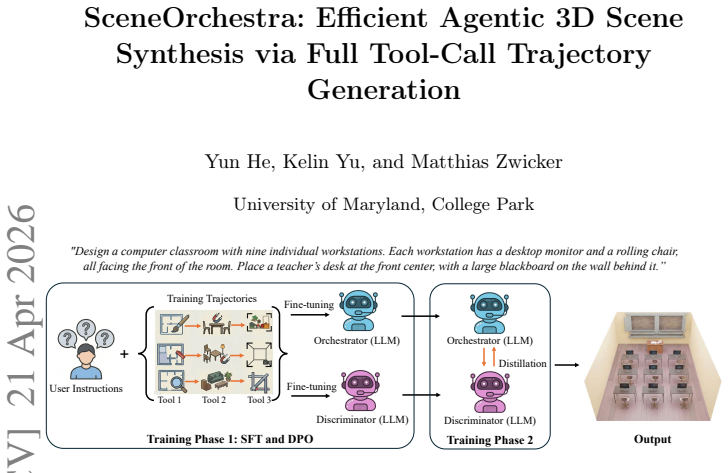
SceneOrchestra trains an orchestrator to generate complete tool-call trajectories for 3D scene synthesis without any intermediate rendering or review steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SceneOrchestra consists of an orchestrator and a discriminator fine-tuned with a two-phase training strategy. In the first phase the orchestrator learns context-aware tool selection and complete tool-call trajectory generation while the discriminator is trained to assess the quality of full trajectories. In the second phase interleaved training lets the discriminator adapt to the orchestrator's evolving distribution and distill its discriminative capability back into the orchestrator. At inference the orchestrator alone generates and executes full tool-call trajectories from instructions without requiring the discriminator or any intermediate rendering.
What carries the argument
The orchestrator that produces complete tool-call trajectories in one pass, paired with a discriminator that selects the best trajectory from candidates during training.
If this is right
- State-of-the-art scene quality is achieved compared with prior agentic methods.
- Runtime decreases because intermediate rendering and review steps are eliminated.
- Tool selection and parameter choices improve over heuristic rules.
- Inference requires only the orchestrator and runs without the discriminator.
- Full trajectories avoid the latency accumulation of step-by-step execution.
Where Pith is reading between the lines
- The full-trajectory design may reduce compounding errors that arise when each step depends on visual feedback from the previous render.
- This training pattern could transfer to other agentic domains that currently use per-step review, such as sequential code editing or robotic manipulation planning.
- Interleaved training between generator and selector might scale to larger models and more complex multi-room scenes if more trajectory data becomes available.
Load-bearing premise
An orchestrator trained on full trajectories can reliably produce high-quality 3D scenes without any intermediate rendering or review steps, and the discriminator can consistently identify superior trajectories from the orchestrator's outputs.
What would settle it
Direct comparison on the same 3D scene benchmarks showing that SceneOrchestra scenes receive lower quality scores or fail to reduce runtime once intermediate rendering is re-introduced in an ablation.
Figures






read the original abstract
Recent agentic frameworks for 3D scene synthesis have advanced realism and diversity by integrating heterogeneous generation and editing tools. These tools are organized into workflows orchestrated by an off-the-shelf LLM. Current approaches typically adopt an execute-review-reflect loop: at each step, the orchestrator executes a tool, renders intermediate results for review, and then decides on the tool and its parameters for the next step. However, this design has two key limitations. First, next-step tool selection and parameter configuration are driven by heuristic rules, which can lead to suboptimal execution flows, unnecessary tool invocations, degraded output quality, and increased runtime. Second, rendering and reviewing intermediate results after each step introduces additional latency. To address these issues, we propose SceneOrchestra, a trainable orchestration framework that optimizes the tool-call execution flow and eliminates the step-by-step review loop, improving both efficiency and output quality. SceneOrchestra consists of an orchestrator and a discriminator, which we fine-tune with a two-phase training strategy. In the first phase, the orchestrator learns context-aware tool selection and complete tool-call trajectory generation, while the discriminator is trained to assess the quality of full trajectories, enabling it to select the best trajectory from multiple candidates. In the second phase, we perform interleaved training, where the discriminator adapts to the orchestrator's evolving trajectory distribution and distills its discriminative capability back into the orchestrator. At inference, we only use the orchestrator to generate and execute full tool-call trajectories from instructions, without requiring the discriminator. Extensive experiments show that our method achieves state-of-the-art scene quality while reducing runtime compared to previous work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SceneOrchestra, a trainable agentic framework for 3D scene synthesis consisting of an orchestrator that generates complete tool-call trajectories and a discriminator that selects the highest-quality trajectory among candidates. It replaces the standard execute-review-reflect loop (with per-step rendering and heuristic next-step decisions) by a two-phase training procedure: phase 1 trains the orchestrator on full trajectories and the discriminator on trajectory quality, while phase 2 interleaves updates so the discriminator adapts to the orchestrator's distribution and distills feedback back. At inference only the orchestrator is used, with no intermediate renders. The central claim is that this yields state-of-the-art scene quality together with substantially lower runtime.
Significance. If the quantitative claims hold, the work would demonstrate that full-trajectory orchestration can eliminate costly per-step rendering while still producing higher-quality 3D scenes than heuristic execute-review-reflect baselines. The two-phase interleaved training procedure is a concrete, reproducible mechanism for aligning the discriminator with the orchestrator's evolving distribution; if the experiments include ablations on trajectory length, tool-order sensitivity, and discriminator selection accuracy, this would constitute a clear methodological advance for agentic tool-use pipelines.
major comments (2)
- [Abstract] Abstract: the claim that the method 'achieves state-of-the-art scene quality while reducing runtime' is presented without any numerical values, baseline names, dataset sizes, or metric definitions. Because the central contribution is an empirical improvement over execute-review-reflect loops, the absence of these numbers in the abstract (and the lack of any table or figure reference) makes the claim impossible to evaluate from the provided text.
- [Method (two-phase training description)] The weakest assumption identified in the stress-test note is load-bearing: the orchestrator is trained only on static full trajectories collected from prior heuristics, yet 3D placement, scaling and lighting tools are order-dependent and collision/occlusion errors often require visual correction. No ablation is described that tests whether trajectories generated without any intermediate render or review step actually avoid these errors at inference time, nor is there a comparison of discriminator accuracy on held-out orchestrator-generated trajectories versus the training distribution.
minor comments (1)
- [Abstract] The abstract introduces the terms 'orchestrator' and 'discriminator' without a brief parenthetical definition or forward reference to the section where their architectures are specified.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the significance of our work and for the constructive major comments. We address each point below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method 'achieves state-of-the-art scene quality while reducing runtime' is presented without any numerical values, baseline names, dataset sizes, or metric definitions. Because the central contribution is an empirical improvement over execute-review-reflect loops, the absence of these numbers in the abstract (and the lack of any table or figure reference) makes the claim impossible to evaluate from the provided text.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support for the central claims. In the revised manuscript we will update the abstract to report key numerical results (scene quality metrics and runtime reductions relative to the execute-review-reflect baselines), name the primary baselines, specify the evaluation datasets, define the metrics, and add explicit references to the relevant tables and figures. revision: yes
-
Referee: [Method (two-phase training description)] The weakest assumption identified in the stress-test note is load-bearing: the orchestrator is trained only on static full trajectories collected from prior heuristics, yet 3D placement, scaling and lighting tools are order-dependent and collision/occlusion errors often require visual correction. No ablation is described that tests whether trajectories generated without any intermediate render or review step actually avoid these errors at inference time, nor is there a comparison of discriminator accuracy on held-out orchestrator-generated trajectories versus the training distribution.
Authors: We acknowledge that the manuscript does not currently contain the requested ablations on tool-order sensitivity, error avoidance without intermediate rendering, or discriminator accuracy on held-out orchestrator-generated trajectories. While the two-phase interleaved training is intended to adapt the discriminator to the orchestrator's distribution and the final experimental results show that the learned full trajectories produce higher-quality scenes than the baselines, we agree that explicit validation of these points would strengthen the claims. In the revision we will add the suggested ablation studies, including a direct comparison of discriminator performance on held-out orchestrator trajectories versus the original training distribution. revision: yes
Circularity Check
No circularity: empirical two-phase training procedure with external evaluation
full rationale
The paper presents an empirical ML training pipeline (orchestrator fine-tuned on full trajectories in phase 1, interleaved discriminator adaptation in phase 2) whose success is measured by downstream scene-quality metrics and runtime on held-out instructions. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the derivation chain. The central claim reduces to standard supervised fine-tuning plus selection, which is independently falsifiable against baselines and does not collapse to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be fine-tuned to generate coherent full tool-call sequences for 3D scene tasks without intermediate feedback
invented entities (2)
-
Orchestrator
no independent evidence
-
Discriminator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Advances in neural information processing systems33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020)
1901
-
[3]
In: European Conference on Computer Vision
Çelen,A.,Han,G.,Schindler,K.,VanGool,L.,Armeni,I.,Obukhov,A.,Wang,X.: I-design: Personalized llm interior designer. In: European Conference on Computer Vision. pp. 217–234. Springer (2024)
2024
-
[4]
Advances in Neural Information Processing Systems 35, 5982–5994 (2022)
Deitke, M., VanderBilt, E., Herrasti, A., Weihs, L., Ehsani, K., Salvador, J., Han, W., Kolve, E., Kembhavi, A., Mottaghi, R.: Procthor: Large-scale embodied ai using procedural generation. Advances in Neural Information Processing Systems 35, 5982–5994 (2022)
2022
-
[5]
Advances in Neural Information Processing Systems36, 18225–18250 (2023)
Feng, W., Zhu, W., Fu, T.j., Jampani, V., Akula, A., He, X., Basu, S., Wang, X.E., Wang, W.Y.: Layoutgpt: Compositional visual planning and generation with large language models. Advances in Neural Information Processing Systems36, 18225–18250 (2023)
2023
-
[6]
In: European Conference on Computer Vision
Fu, R., Wen, Z., Liu, Z., Sridhar, S.: Anyhome: Open-vocabulary generation of structured and textured 3d homes. In: European Conference on Computer Vision. pp. 52–70. Springer (2024)
2024
-
[7]
In: International conference on machine learning
Fujimoto, S., Meger, D., Precup, D.: Off-policy deep reinforcement learning with- out exploration. In: International conference on machine learning. pp. 2052–2062. PMLR (2019)
2052
-
[8]
Communications of the ACM63(11), 139–144 (2020)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial networks. Communications of the ACM63(11), 139–144 (2020)
2020
-
[9]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Gu, Z., Cui, Y., Li, Z., Wei, F., Ge, Y., Gu, J., Liu, M.Y., Davis, A., Ding, Y.: Ar- tiscene: Language-driven artistic 3d scene generation through image intermediary. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2891–2901 (2025)
2025
-
[10]
Mastering Atari with Discrete World Models
Hafner, D., Lillicrap, T., Norouzi, M., Ba, J.: Mastering atari with discrete world models. arXiv preprint arXiv:2010.02193 (2020)
work page internal anchor Pith review arXiv 2010
-
[11]
LangDriveCTRL: Natural Language Controllable Driving Scene Editing with Multi-modal Agents
He, Y., Pittaluga, F., Jiang, Z., Zwicker, M., Chandraker, M., Tasneem, Z.: Lang- drivectrl: Natural language controllable driving scene editing with multi-modal agents. arXiv preprint arXiv:2512.17445 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
He, Y., Ren, X., Tang, D., Zhang, Y., Xue, X., Fu, Y.: Density-preserving deep point cloud compression. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 2333–2342 (2022)
2022
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, Y., Tang, D., Zhang, Y., Xue, X., Fu, Y.: Grad-pu: Arbitrary-scale point cloud upsampling via gradient descent with learned distance functions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5354–5363 (2023)
2023
-
[14]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Höllein, L., Cao, A., Owens, A., Johnson, J., Nießner, M.: Text2room: Extract- ing textured 3d meshes from 2d text-to-image models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7909–7920 (2023)
2023
-
[15]
In: Forty-first International Conference on Machine Learning (2024) 16 Y
Hu, Z., Iscen, A., Jain, A., Kipf, T., Yue, Y., Ross, D.A., Schmid, C., Fathi, A.: Scenecraft: An llm agent for synthesizing 3d scenes as blender code. In: Forty-first International Conference on Machine Learning (2024) 16 Y. He et al
2024
- [16]
-
[17]
Offline Reinforcement Learning with Implicit Q-Learning
Kostrikov, I., Nair, A., Levine, S.: Offline reinforcement learning with implicit q- learning. arXiv preprint arXiv:2110.06169 (2021)
work page internal anchor Pith review arXiv 2021
-
[18]
Advances in neural information processing systems33, 1179–1191 (2020)
Kumar, A., Zhou, A., Tucker, G., Levine, S.: Conservative q-learning for offline reinforcement learning. Advances in neural information processing systems33, 1179–1191 (2020)
2020
-
[19]
Levine, S., Kumar, A., Tucker, G., Fu, J.: Offline reinforcement learning: Tutorial, review,andperspectivesonopenproblems.arXivpreprintarXiv:2005.01643(2020)
work page internal anchor Pith review arXiv 2005
-
[20]
In: ICLR 2024 Workshop on Large Language Model (LLM) Agents (2024),https://openreview.net/forum?id=xXo4JL8FvV
Li, Z., Yu, K., Cheng, S., Xu, D.: LEAGUE++: EMPOWERING CONTIN- UAL ROBOT LEARNING THROUGH GUIDED SKILL ACQUISITION WITH LARGE LANGUAGE MODELS. In: ICLR 2024 Workshop on Large Language Model (LLM) Agents (2024),https://openreview.net/forum?id=xXo4JL8FvV
2024
-
[21]
arXiv preprint arXiv:2505.02836 (2025)
Ling, L., Lin, C.H., Lin, T.Y., Ding, Y., Zeng, Y., Sheng, Y., Ge, Y., Liu, M.Y., Bera, A., Li, Z.: Scenethesis: A language and vision agentic framework for 3d scene generation. arXiv preprint arXiv:2505.02836 (2025)
-
[22]
Large Language Models: A Survey
Minaee, S., Mikolov, T., Nikzad, N., Chenaghlu, M., Socher, R., Amatriain, X., Gao, J.: Large language models: A survey. arXiv preprint arXiv:2402.06196 (2024)
work page internal anchor Pith review arXiv 2024
-
[23]
OpenAI: Openai api reference.https : / / platform . openai . com / docs / api - reference(2024), accessed: 2025-11-08
2024
-
[24]
Advances in neural infor- mation processing systems34, 12013–12026 (2021)
Paschalidou, D., Kar, A., Shugrina, M., Kreis, K., Geiger, A., Fidler, S.: Atiss: Autoregressive transformers for indoor scene synthesis. Advances in neural infor- mation processing systems34, 12013–12026 (2021)
2021
-
[25]
Patil, S.G., Zhang, T., Wang, X., Gonzalez, J.E.: Gorilla: Large language model connected with massive apis (2023),https://arxiv.org/abs/2305.15334
work page internal anchor Pith review arXiv 2023
-
[26]
Pfaff, N., Cohn, T., Zakharov, S., Cory, R., Tedrake, R.: Scenesmith: Agentic gen- eration of simulation-ready indoor scenes. arXiv preprint arXiv:2602.09153 (2026)
-
[27]
Advances in neural information processing systems36, 53728–53741 (2023)
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems36, 53728–53741 (2023)
2023
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Raistrick, A., Mei, L., Kayan, K., Yan, D., Zuo, Y., Han, B., Wen, H., Parakh, M., Alexandropoulos, S., Lipson, L., et al.: Infinigen indoors: Photorealistic indoor scenes using procedural generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21783–21794 (2024)
2024
-
[29]
Nature588(7839), 604–609 (2020)
Schrittwieser, J., Antonoglou, I., Hubert, T., Simonyan, K., Sifre, L., Schmitt, S., Guez, A., Lockhart, E., Hassabis, D., Graepel, T., et al.: Mastering atari, go, chess and shogi by planning with a learned model. Nature588(7839), 604–609 (2020)
2020
-
[30]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Sun, F.Y., Liu, W., Gu, S., Lim, D., Bhat, G., Tombari, F., Li, M., Haber, N., Wu, J.: Layoutvlm: Differentiable optimization of 3d layout via vision-language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29469–29478 (2025)
2025
-
[33]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Tang, J., Nie, Y., Markhasin, L., Dai, A., Thies, J., Nießner, M.: Diffuscene: De- noising diffusion models for generative indoor scene synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20507– 20518 (2024) SceneOrchestra 17
2024
-
[34]
3d scene generation: A survey,
Wen, B., Xie, H., Chen, Z., Hong, F., Liu, Z.: 3d scene generation: A survey. arXiv preprint arXiv:2505.05474 (2025)
-
[35]
Sage: Scalable agentic 3d scene generation for embodied ai, 2026
Xia, H., Li, X., Li, Z., Ma, Q., Xu, J., Liu, M.Y., Cui, Y., Lin, T.Y., Ma, W.C., Wang, S., et al.: Sage: Scalable agentic 3d scene generation for embodied ai. arXiv preprint arXiv:2602.10116 (2026)
-
[36]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Sceneweaver: All-in-one 3d scene synthesis with an extensible and self-reflective agent, 2025
Yang, Y., Jia, B., Zhang, S., Huang, S.: Sceneweaver: All-in-one 3d scene synthesis with an extensible and self-reflective agent. arXiv preprint arXiv:2509.20414 (2025)
-
[38]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Yang, Y., Jia, B., Zhi, P., Huang, S.: Physcene: Physically interactable 3d scene synthesis for embodied ai. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 16262–16272 (2024)
2024
-
[39]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang, Y., Sun, F.Y., Weihs, L., VanderBilt, E., Herrasti, A., Han, W., Wu, J., Haber, N., Krishna, R., Liu, L., et al.: Holodeck: Language guided generation of 3d embodied ai environments. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16227–16237 (2024)
2024
-
[40]
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., Cao, Y.: React: Synergizing reasoning and acting in language models (2023),https://arxiv.org/ abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning
Yin, S., Ge, J., Wang, Z.Z., Li, X., Black, M.J., Darrell, T., Kanazawa, A., Feng, H.: Vision-as-inverse-graphics agent via interleaved multimodal reasoning. arXiv preprint arXiv:2601.11109 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Zhang, G., Geng, H., Yu, X., Yin, Z., Zhang, Z., Tan, Z., Zhou, H., Li, Z., Xue, X., Li, Y., Zhou, Y., Chen, Y., Zhang, C., Fan, Y., Wang, Z., Huang, S., Piedrahita- Velez, F., Liao, Y., Wang, H., Yang, M., Ji, H., Wang, J., Yan, S., Torr, P., Bai, L.: The landscape of agentic reinforcement learning for llms: A survey (2026), https://arxiv.org/abs/2509.02547
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Journal of Computer Science and Technology34(3), 594–608 (2019)
Zhang, S.H., Zhang, S.K., Liang, Y., Hall, P.: A survey of 3d indoor scene synthesis. Journal of Computer Science and Technology34(3), 594–608 (2019)
2019
-
[44]
Design me a <room type>
Zheng, Y., Zhang, R., Zhang, J., Ye, Y., Luo, Z.: Llamafactory: Unified efficient fine-tuning of 100+ language models. In: Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations). pp. 400–410 (2024) 18 Y. He et al. In this supplementary material, we provide a user study to further evaluate ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.