Physics-Guided Dimension Reduction for Simulation-Free Operator Learning of Stiff Differential-Algebraic Systems
Pith reviewed 2026-05-10 02:56 UTC · model grok-4.3
The pith
An extended Newton implicit layer embedded in a physics-informed DeepONet recovers fast and algebraic states exactly from slow-state predictions for stiff DAEs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An extended Newton implicit layer enforces algebraic constraints exactly and reduces fast dynamics to their quasi-steady-state values in a single differentiable solve. When embedded in a physics-informed DeepONet, this layer recovers all fast and algebraic states exactly from slow-state predictions alone, removes the per-window stiffness-amplification pathway, and produces a stiffness-scaled Implicit Function Theorem gradient.
What carries the argument
The extended Newton implicit layer, a differentiable solve that finds the quasi-steady-state and algebraic variables consistent with predicted slow states and the DAE equations.
Load-bearing premise
The DAE must have a clear separation into slow states that the network predicts and fast plus algebraic states that the Newton layer can solve exactly in one step.
What would settle it
A stiff DAE where the extended Newton layer fails to converge to the correct quasi-steady-state solution, or where the reduction does not match the true fast dynamics, producing errors larger than those of penalty methods.
Figures






read the original abstract
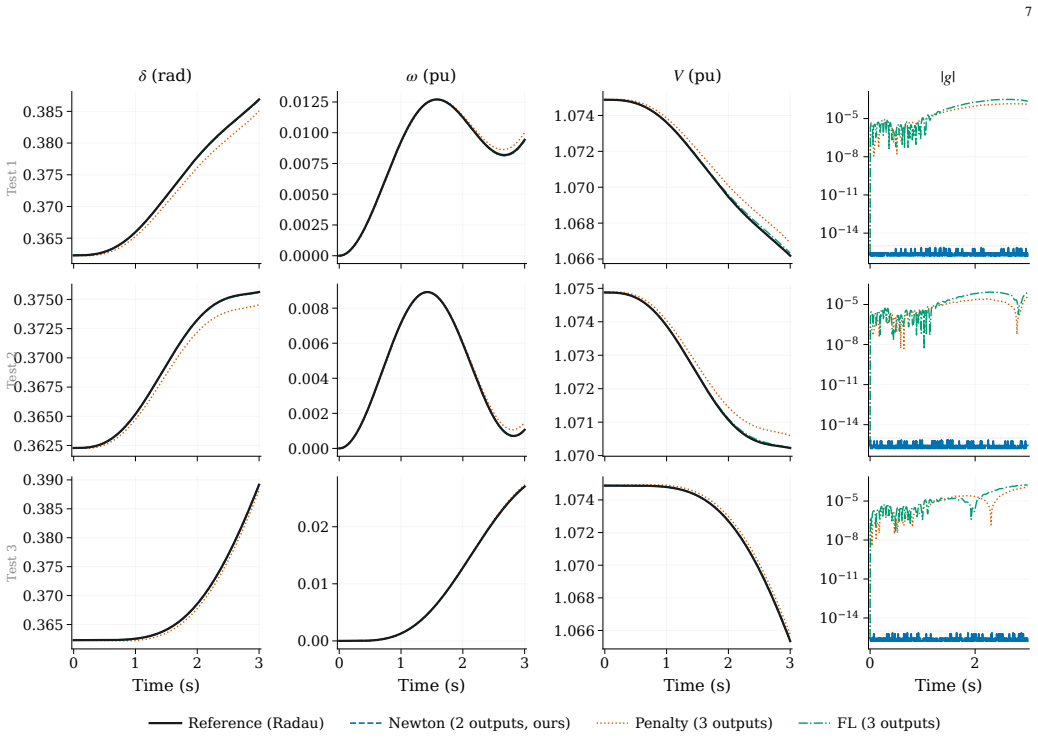
Neural surrogates for stiff differential-algebraic equations (DAEs) face two barriers: soft-constraint methods leave algebraic residuals that stiffness amplifies into errors, and hard-constraint methods require trajectory data from stiff integrators. We introduce an extended Newton implicit layer that enforces algebraic constraints exactly and reduces fast dynamics to their quasi-steady-state values in a single differentiable solve. Embedded in a physics-informed DeepONet, the layer recovers all fast and algebraic states exactly from slow-state predictions, removes the per-window stiffness-amplification pathway, and yields a stiffness-scaled Implicit Function Theorem gradient absent from penalty methods. Cascaded implicit layers extend this to multi-component systems with provable convergence. On a grid-forming inverter (stiffness ratio of about 4712), extended Newton attains 1.42% error versus 39.3% (penalty) and 57.0% (standard Newton); augmented Lagrangian and feedback linearization diverged. Two independently trained models compose without retraining (0.72% to 1.16% error, exact constraint satisfaction). Cross-domain validation on the Robertson stiff DAE (stiffness ratio up to $10^5$) confirms generalization. Conformal prediction provides 90% coverage with automatic out-of-distribution detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce an extended Newton implicit layer embedded in a physics-informed DeepONet for simulation-free operator learning of stiff DAEs. The layer is asserted to recover fast and algebraic states exactly from slow-state predictions by enforcing algebraic constraints exactly and reducing fast dynamics to quasi-steady-state in one differentiable solve, thereby eliminating per-window stiffness amplification and providing a stiffness-scaled IFT gradient. Cascaded layers are said to extend this to multi-component systems with provable convergence. Numerical results show 1.42% error on a grid-forming inverter (stiffness ratio ~4712) versus 39.3% (penalty) and 57.0% (standard Newton), with model composition without retraining, exact constraint satisfaction, and generalization to the Robertson DAE (stiffness up to 10^5) plus conformal prediction for 90% coverage.
Significance. If the claims hold, the work would offer a meaningful advance in neural surrogates for stiff DAEs by avoiding soft-constraint residuals and the need for stiff-integrator trajectory data, while enabling exact constraint satisfaction and cross-model composition. The stiffness-scaled gradient and conformal prediction are additional strengths. However, the significance is limited by the method's dependence on a correct a priori state partitioning whose generality is not established.
major comments (2)
- [Abstract] Abstract: the central claim that the extended Newton layer recovers all fast and algebraic states exactly (and removes the stiffness-amplification pathway) holds only under the assumption of an explicit, stable separation into slow states, fast dynamics reducible to quasi-steady-state, and index-1 algebraic constraints solvable independently; no general procedure is given for discovering or validating this partition, and an incorrect split would render the single-solve recovery inexact.
- [Abstract] Abstract: the assertion of provable convergence for cascaded implicit layers depends on per-component partitions satisfying contraction conditions, yet these conditions are not shown to hold outside the two tested examples (grid-forming inverter and Robertson DAE).
minor comments (1)
- [Abstract] The abstract reports specific error values and stiffness ratios but does not indicate whether error bars or multiple random seeds were used; this should be clarified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their insightful comments. We address each major comment below and have revised the manuscript to add necessary clarifications and qualifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the extended Newton layer recovers all fast and algebraic states exactly (and removes the stiffness-amplification pathway) holds only under the assumption of an explicit, stable separation into slow states, fast dynamics reducible to quasi-steady-state, and index-1 algebraic constraints solvable independently; no general procedure is given for discovering or validating this partition, and an incorrect split would render the single-solve recovery inexact.
Authors: We agree that exact recovery of fast and algebraic states by the extended Newton layer requires a correct a priori partitioning into slow, fast, and algebraic components, with fast dynamics reducible to quasi-steady state and index-1 algebraic constraints. The manuscript assumes this partition is supplied from domain knowledge of the system (as is standard for stiff DAEs in power systems and kinetics) and does not claim or provide a general automated discovery procedure, which would require separate system-identification methods beyond the present scope. We have revised the abstract to state the assumption explicitly and to note that an incorrect partition would yield inexact recovery; we have also added a brief discussion in the introduction on how the partitions are obtained for the reported examples. revision: partial
-
Referee: [Abstract] Abstract: the assertion of provable convergence for cascaded implicit layers depends on per-component partitions satisfying contraction conditions, yet these conditions are not shown to hold outside the two tested examples (grid-forming inverter and Robertson DAE).
Authors: The convergence result for cascaded layers is derived under the per-component contraction conditions required by the implicit-function theorem; these conditions are stated in the manuscript and are verified analytically and numerically for the grid-forming inverter and Robertson DAE. We do not assert that the conditions hold for arbitrary multi-component stiff DAEs. We have revised the abstract to qualify the claim as holding under suitable per-component contraction conditions and have expanded the main-text discussion to emphasize that new applications require verification of the conditions. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper's core construction—an extended Newton implicit layer embedded in a physics-informed DeepONet—relies on the standard Implicit Function Theorem applied to an algebraic solve whose fixed point is independent of the learned slow-state operator. The abstract and described method introduce the layer as a new differentiable component that enforces exact algebraic satisfaction and quasi-steady-state reduction; no equation or claim reduces the reported error metrics, gradient scaling, or convergence statements to a fitted parameter or self-citation by construction. The partitioning into slow/fast/algebraic states is presented as a modeling assumption rather than a derived result, and no load-bearing step collapses to renaming or self-referential fitting. The derivation chain therefore stands on its own mathematical and architectural choices without circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Fast dynamics can be reduced to their quasi-steady-state values given slow states without loss of accuracy for the target systems.
- domain assumption The extended Newton iteration converges to the exact algebraic solution in a differentiable manner.
invented entities (1)
-
extended Newton implicit layer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
PINNSim: A simulator for power system dynamics based on physics-informed neural networks,
J. Stiasny, B. Zhang, and S. Chatzivasileiadis, “PINNSim: A simulator for power system dynamics based on physics-informed neural networks,” Electric Power Systems Research, vol. 235, 2024
work page 2024
-
[2]
K. E. Brenan, S. L. Campbell, and L. R. Petzold,Numerical Solution of Initial-Value Problems in Differential-Algebraic Equations, Classics in Applied Mathematics, vol. 14. SIAM, 1996. 11
work page 1996
-
[3]
E. Hairer and G. Wanner,Solving Ordinary Differential Equations II: Stiff and Differential-Algebraic Problems, 2nd ed. Springer, 1996
work page 1996
-
[4]
The solution of a set of reaction rate equations,
H. H. Robertson, “The solution of a set of reaction rate equations,” inNumerical Analysis: An Introduction, J. Walsh, Ed. London, U.K.: Academic Press, 1966, pp. 178–182
work page 1966
-
[5]
C. Moya and G. Lin, “DAE-PINN: A physics-informed neural network model for simulating differential-algebraic equations with application to power networks,”Neural Computing and Applications, vol. 35, pp. 3789–3804, 2023
work page 2023
-
[6]
Enhanced physics-informed neural networks with augmented Lagrangian relaxation method (AL-PINNs),
H. Son, S. W. Cho, and H. J. Hwang, “Enhanced physics-informed neural networks with augmented Lagrangian relaxation method (AL-PINNs),” Neurocomputing, vol. 548, p. 126424, 2023
work page 2023
-
[7]
DC3: A learning method for optimization with hard constraints,
P. L. Donti, D. Rolnick, and J. Z. Kolter, “DC3: A learning method for optimization with hard constraints,” inProc. ICLR, 2021
work page 2021
-
[8]
Semi-explicit neural DAEs: Learning long-horizon dynamical systems with algebraic constraints,
A. Pal, A. Edelman, and C. Rackauckas, “Semi-explicit neural DAEs: Learning long-horizon dynamical systems with algebraic constraints,” arXiv:2505.20515, 2025
-
[9]
DAE-HardNet: A physics constrained neural network enforcing differential-algebraic hard constraints,
R. Golder, B. N. Roy, and M. M. F. Hasan, “DAE-HardNet: A physics constrained neural network enforcing differential-algebraic hard con- straints,”arXiv:2512.05881, 2025
-
[10]
S. Wang, H. Wang, and P. Perdikaris, “Learning the solution operator of parametric partial differential equations with physics-informed Deep- ONets,”Science Advances, vol. 7, no. 40, 2021
work page 2021
-
[11]
E. N. Spotorno, J. Leal Filho, and A. A. Fr ¨ohlich, “Hard-constrained neural networks with physics-embedded architecture for residual dy- namics learning and invariant enforcement in cyber-physical systems,” arXiv:2511.23307, 2025
-
[12]
C. Moya, S. Zhang, G. Lin, and M. Yue, “DeepONet-Grid-UQ: A trustworthy deep operator framework for predicting the power grid’s post-fault trajectories,”Neurocomputing, vol. 535, pp. 166–182, 2023
work page 2023
-
[13]
arXiv preprint arXiv:2403.12938 , year=
J. Koch, M. Shapiro, H. Sharma, D. Vrabie, and J. Drgo ˇna, “Learn- ing neural differential algebraic equations via operator splitting,” arXiv:2403.12938, 2024
-
[14]
Constrained optimization from a control perspective via feedback linearization,
R. Zhang, A. Raghunathan, J. Shamma, and N. Li, “Constrained optimization from a control perspective via feedback linearization,” in Proc. NeurIPS, 2025
work page 2025
-
[15]
X. Cheng and S. Na, “Physics-informed neural networks with trust- region sequential quadratic programming,”arXiv:2409.10777, 2024
-
[16]
Stabilized neural differential equations for learning dynamics with explicit constraints,
A. White, N. Kilbertus, M. Gelbrecht, and N. Boers, “Stabilized neural differential equations for learning dynamics with explicit constraints,” inProc. NeurIPS, 2023
work page 2023
-
[17]
A simultaneous approach for training neural differential- algebraic systems of equations,
L. R. Lueg, V . Alves, D. Schicksnus, J. R. Kitchin, C. D. Laird, and L. T. Biegler, “A simultaneous approach for training neural differential- algebraic systems of equations,”arXiv:2504.04665, 2025
-
[18]
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators,
L. Lu, P. Jin, G. Pang, Z. Zhang, and G. E. Karniadakis, “Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators,”Nature Machine Intelligence, vol. 3, pp. 218–229, 2021
work page 2021
-
[19]
I. Karampinis, P. Ellinas, J. V orwerk, and S. Chatzivasileiadis, “Neural operators for power systems: A physics-informed framework for mod- eling power system components,”arXiv:2511.05216, 2025
-
[20]
Systems of differential equations containing small parameters in the derivatives,
A. N. Tikhonov, “Systems of differential equations containing small parameters in the derivatives,”Matematicheskii Sbornik, vol. 31, no. 3, pp. 575–586, 1952
work page 1952
-
[21]
P. V . Kokotovi ´c, H. K. Khalil, and J. O’Reilly,Singular Perturbation Methods in Control: Analysis and Design. SIAM, 1999
work page 1999
-
[22]
Towards explicit methods for differential algebraic equa- tions,
C. W. Gear, “Towards explicit methods for differential algebraic equa- tions,”BIT Numerical Mathematics, vol. 46, pp. 505–514, 2006
work page 2006
-
[23]
X. Zhao, M. Netto, and J. Zhao, “A novel discrete-time state-space model for decentralized dynamic state estimation of grid-forming inverters,” IEEE Trans. Power Syst., 2025
work page 2025
-
[24]
Stiff-PINN: Physics- informed neural network for stiff chemical kinetics,
W. Ji, W. Qiu, Z. Shi, S. Pan, and S. Deng, “Stiff-PINN: Physics- informed neural network for stiff chemical kinetics,”J. Phys. Chem. A, vol. 125, no. 36, pp. 8098–8106, 2021
work page 2021
-
[25]
Fast-slow neural networks for learning singu- larly perturbed dynamical systems,
N. Lee and R. Temam, “Fast-slow neural networks for learning singu- larly perturbed dynamical systems,”J. Comput. Phys., 2025
work page 2025
-
[26]
Neural ordinary differential equations for model order reduction of stiff systems,
M. Caldana, P. Mossier, and L. Pareschi, “Neural ordinary differential equations for model order reduction of stiff systems,”Int. J. Numer. Methods Eng., vol. 126, no. 13, e70060, 2025
work page 2025
-
[27]
Conformal prediction: A gentle introduction,
A. N. Angelopoulos and S. Bates, “Conformal prediction: A gentle introduction,”Foundations and Trends in Machine Learning, vol. 16, no. 4, pp. 494–591, 2023
work page 2023
-
[28]
A tutorial on conformal prediction,
G. Shafer and V . V ovk, “A tutorial on conformal prediction,”Journal of Machine Learning Research, vol. 9, no. 3, 2008
work page 2008
-
[29]
Conformalized quantile re- gression,
Y . Romano, E. Patterson, and E. Cand `es, “Conformalized quantile re- gression,”Advances in Neural Information Processing Systems, vol. 32, 2019
work page 2019
-
[30]
Adaptive conformal inference under distribu- tion shift,
I. Gibbs and E. Cand `es, “Adaptive conformal inference under distribu- tion shift,”Advances in Neural Information Processing Systems, vol. 34, pp. 1660–1672, 2021
work page 2021
-
[31]
Conformal time- series forecasting,
K. Stankeviciute, A. M. Alaa, and M. van der Schaar, “Conformal time- series forecasting,”Advances in Neural Information Processing Systems, vol. 34, pp. 6216–6228, 2021
work page 2021
-
[32]
P. M. Anderson and A. A. Fouad,Power Systems Control and Stability, 2nd ed. Wiley-IEEE Press, 2003
work page 2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.