Multi-Objective Reinforcement Learning for Generating Covalent Inhibitor Candidates
Pith reviewed 2026-05-10 02:35 UTC · model grok-4.3
The pith
A multi-objective reinforcement learning pipeline generates covalent inhibitor candidates including novel warhead motifs absent from its training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
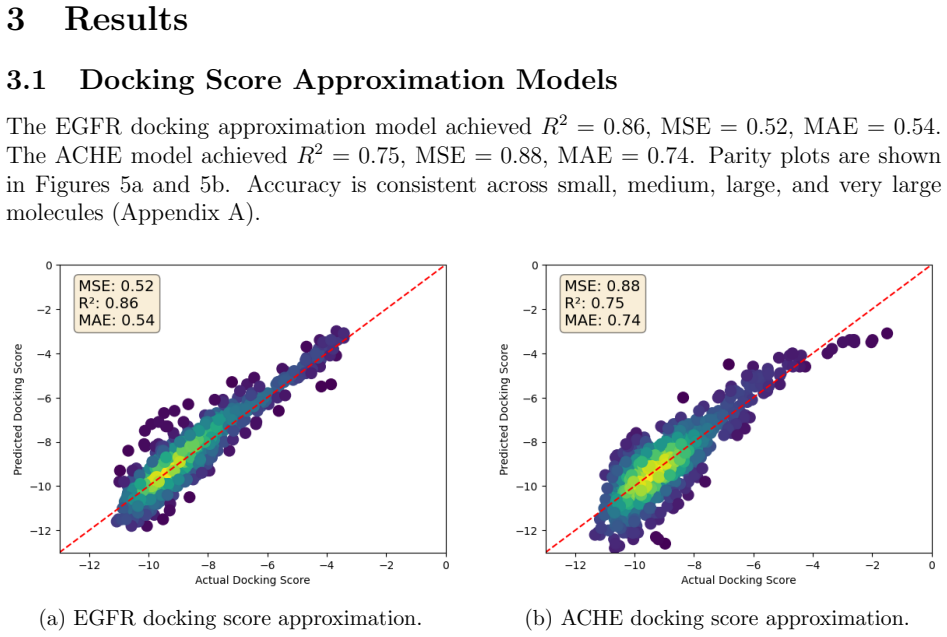
The pipeline rediscovers known covalent inhibitors at rates of up to 0.50 percent for EGFR and 0.74 percent for ACHE in 10,000-structure runs, with some candidates achieving warhead-to-residue distances as short as 3.2 angstrom after docking screening. More notably, it spontaneously generates structures bearing warhead motifs absent from the training data, including allenes, 3-oxo-β-sultams, and α-methylene-β-lactones, all of which have independent literature support as covalent warheads. These outcomes indicate that RL-guided generation can explore covalent chemical space beyond its training distribution.
What carries the argument
Multi-objective policy-gradient reinforcement learning with Pareto crowding distance applied to a pretrained LSTM SMILES generator, guided by four competing scoring functions for synthetic accessibility, predicted covalent activity, residue affinity, and approximated docking score.
If this is right
- The method recovers known covalent inhibitors for EGFR and ACHE at rates of 0.50 percent and 0.74 percent in 10,000-structure runs.
- Generated candidates can reach short warhead-to-residue distances after additional docking-based filtering.
- RL-guided generation can produce valid covalent warhead types not present in the original training distribution.
- The pipeline supplies a tool that medicinal chemists could use for covalent drug discovery on additional targets.
Where Pith is reading between the lines
- The same multi-objective setup could be applied to other protein targets or to larger generative models without retraining from scratch.
- Laboratory synthesis of the highest-scoring novel structures would provide a direct test of whether the generated warheads translate to real activity.
- Combining this RL approach with experimental feedback loops could iteratively improve the accuracy of the proxy scores.
Load-bearing premise
The scoring functions for synthetic accessibility, predicted covalent activity, residue affinity, and approximated docking score serve as sufficiently accurate proxies for real molecular properties to guide generation toward viable inhibitors without excessive false positives.
What would settle it
Synthesis and experimental assay of one or more generated molecules containing a novel warhead motif to confirm actual covalent inhibition of the target protein.
Figures














read the original abstract
Rational design of covalent inhibitors requires simultaneously optimizing multiple properties, such as binding affinity, target selectivity, or electrophilic reactivity. This presents a multi-objective problem not easily addressed by screening alone. Here we present a machine learning pipeline for generating covalent inhibitor candidates using multi-objective reinforcement learning (RL), applied to two targets: epidermal growth factor receptor (EGFR) and acetylcholinesterase (ACHE). A SMILES-based pretrained LSTM serves as the generative model, optimized via policy gradient RL with Pareto crowding distance to balance competing scoring functions including synthetic accessibility, predicted covalent activity, residue affinity, and an approximated docking score. The pipeline rediscovers known covalent inhibitors at rates of up to 0.50% (EGFR) and 0.74% (ACHE) in 10,000-structure runs, with candidate structures achieving warhead-to-residue distances as short as 5.5 angstrom (EGFR) and 3.2 angstrom (ACHE) after further docking-based screening. More notably, the pipeline spontaneously generates structures bearing warhead motifs absent from the training data - including allenes, 3-oxo-$\beta$-sultams, and $\alpha$-methylene-$\beta$-lactones - all of which have independent literature support as covalent warheads. These results suggest that RL-guided generation can explore covalent chemical space beyond its training distribution, and may be useful as a tool for medicinal chemists working on covalent drug discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes a multi-objective reinforcement learning approach using a pretrained LSTM to generate covalent inhibitor candidates for EGFR and ACHE. The generative model is optimized via policy gradients with Pareto crowding to balance synthetic accessibility, predicted covalent activity, residue affinity, and docking scores. It achieves rediscovery rates of 0.50% for EGFR and 0.74% for ACHE, produces candidates with short warhead-residue distances, and generates novel warhead motifs (allenes, 3-oxo-β-sultams, α-methylene-β-lactones) absent from training data but validated in literature.
Significance. If the scoring functions prove reliable, this demonstrates that multi-objective RL can steer generative models to explore covalent chemical space beyond the training distribution, including novel electrophilic motifs with literature support. The concrete rediscovery rates and cross-checked novel examples represent a promising proof-of-concept for RL in covalent drug design, though the low rates and validation gaps limit broader impact.
major comments (2)
- The performance of the 'predicted covalent activity' scorer on out-of-distribution warhead motifs (allenes, 3-oxo-β-sultams, α-methylene-β-lactones) is not evaluated or reported (Abstract and Results). This is load-bearing for the central claim, as the assertion that RL-guided generation explores beyond the training distribution requires evidence that this scorer correctly assigns high activity to truly novel motifs rather than incidental generation.
- Rediscovery rates (0.50% EGFR, 0.74% ACHE) are reported as single values from 10,000-structure runs without error bars, number of independent trials, or comparisons to a non-RL baseline such as unoptimized LSTM sampling (Abstract and Results). This makes it difficult to determine whether the multi-objective optimization (policy gradient + Pareto crowding) meaningfully contributes to the results.
minor comments (2)
- Clarify the exact number of independent runs, total structures sampled, and variance in rediscovery rates to support statistical interpretation of the reported percentages.
- The abstract uses LaTeX notation for chemical motifs (e.g., 3-oxo-$β$-sultams); ensure consistent rendering and add a brief table or figure caption defining all scoring functions for clarity.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We believe the suggested revisions will improve the clarity and rigor of our work, and we address each point below.
read point-by-point responses
-
Referee: The performance of the 'predicted covalent activity' scorer on out-of-distribution warhead motifs (allenes, 3-oxo-β-sultams, α-methylene-β-lactones) is not evaluated or reported (Abstract and Results). This is load-bearing for the central claim, as the assertion that RL-guided generation explores beyond the training distribution requires evidence that this scorer correctly assigns high activity to truly novel motifs rather than incidental generation.
Authors: We acknowledge that a direct evaluation of the scorer on these specific out-of-distribution motifs is not included in the current manuscript. The scorer was trained on a broad set of covalent compounds, and while the novel motifs generated align with literature-supported covalent warheads, we agree this leaves some uncertainty. In the revised version, we will add a paragraph in the Results section describing the scorer's architecture and training distribution, and explicitly discuss the potential for OOD performance as a limitation, suggesting it as an area for future validation experiments. revision: yes
-
Referee: Rediscovery rates (0.50% EGFR, 0.74% ACHE) are reported as single values from 10,000-structure runs without error bars, number of independent trials, or comparisons to a non-RL baseline such as unoptimized LSTM sampling (Abstract and Results). This makes it difficult to determine whether the multi-objective optimization (policy gradient + Pareto crowding) meaningfully contributes to the results.
Authors: The reported rates are from the primary experimental runs described. To provide better statistical context, the revised manuscript will include results averaged over five independent runs with standard deviations for the rediscovery rates. We will also add a direct comparison to a non-RL baseline consisting of 10,000 samples drawn from the pretrained LSTM without policy gradient optimization, which yields rediscovery rates of approximately 0.1% or lower, thereby illustrating the impact of the multi-objective RL approach. revision: yes
Circularity Check
No significant circularity; derivation relies on external scorers and empirical observation
full rationale
The paper's core pipeline consists of a pretrained LSTM generative model optimized by standard policy-gradient RL (with Pareto crowding) using four externally defined scoring functions: synthetic accessibility, a separate predicted covalent activity model, residue affinity, and approximated docking. Novel warhead motifs are reported as an empirical outcome of generation runs, cross-checked against independent literature rather than being defined into existence by the method itself. No equations or steps reduce the claimed exploration of covalent space to a tautological fit or self-referential definition; the rediscovery rates and warhead distances are post-hoc measurements on generated samples. The skeptic concern about scorer generalization on out-of-distribution motifs is a validity issue, not a circularity reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Thomas A. Baillie. Targeted Covalent Inhibitors for Drug Design.Angewandte Chemie (International Ed. in English), 55(43):13408–13421, 2016
work page 2016
-
[2]
Co- valent Inhibition in Drug Discovery.ChemMedChem, 14(9):889–906, 2019
Avick Kumar Ghosh, Indranil Samanta, Anushree Mondal, and Wenshe Ray Liu. Co- valent Inhibition in Drug Discovery.ChemMedChem, 14(9):889–906, 2019
work page 2019
-
[3]
Paul A. Jackson, John C. Widen, Daniel A. Harki, and Kay M. Brummond. Covalent Modifiers: A Chemical Perspective on the Reactivity ofα,β-Unsaturated Carbonyls with Thiols via Hetero-Michael Addition Reactions.Journal of Medicinal Chemistry, 60(3):839–885, 2017
work page 2017
-
[4]
Akintunde Akinleye, Yamei Chen, Nikhil Mukhi, Yongping Song, and Delong Liu. Ibru- tinib and novel BTK inhibitors in clinical development.Journal of Hematology & On- cology, 6(1):59, 2013
work page 2013
-
[5]
Sarah L. Greig. Osimertinib: First Global Approval.Drugs, 76(2):263–273, 2016
work page 2016
-
[6]
Eyal Mazuz, Guy Shtar, Bracha Shapira, and Lior Rokach. Molecule generation using transformers and policy gradient reinforcement learning.Scientific Reports, 13(1):8799, 2023
work page 2023
-
[7]
Giovanni Bolcato, Esther Heid, and Jonas Bostr¨ om. On the Value of Using 3D Shape and Electrostatic Similarities in Deep Generative Methods.Journal of Chemical Information and Modeling, 62(6):1388–1398, 2022
work page 2022
-
[8]
Woosung Jeon and Dongsup Kim. Autonomous molecule generation using reinforce- ment learning and docking to develop potential novel inhibitors.Scientific Reports, 10(1):22104, 2020
work page 2020
-
[9]
Renee Gil and Christopher N. Rowley. Graph neural networks for identifying protein- reactive compounds.Digital Discovery, 3(9):1776–1792, 2024
work page 2024
-
[10]
van den Maagdenberg, Linde Schoenmaker, Olivier J
Martin ˇS´ ıcho, Sohvi Luukkonen, Helle W. van den Maagdenberg, Linde Schoenmaker, Olivier J. M. B´ equignon, and Gerard J. P. van Westen. DrugEx: Deep Learning Models and Tools for Exploration of Drug-Like Chemical Space.Journal of Chemical Informa- tion and Modeling, 63(12):3629–3636, 2023
work page 2023
-
[11]
Long Short-Term Memory.Neural Compu- tation, 9(8):1735–1780, 1997
Sepp Hochreiter and J¨ urgen Schmidhuber. Long Short-Term Memory.Neural Compu- tation, 9(8):1735–1780, 1997
work page 1997
-
[12]
O. J. M. B´ equignon, B. J. Bongers, W. Jespers, A. P. IJzerman, B. van der Water, and G. J. P. van Westen. Papyrus: A large-scale curated dataset aimed at bioactivity predictions.Journal of Cheminformatics, 15(1):3, 2023
work page 2023
-
[13]
Anna Gaulton, Louisa J. Bellis, A. Patricia Bento, Jon Chambers, Mark Davies, Anne Hersey, Yvonne Light, Shaun McGlinchey, David Michalovich, Bissan Al-Lazikani, and John P. Overington. ChEMBL: A large-scale bioactivity database for drug discovery. Nucleic Acids Research, 40(D1):D1100–D1107, 2011. 25
work page 2011
-
[14]
Sunghwan Kim, Paul A. Thiessen, Evan E. Bolton, Jie Chen, Gang Fu, Asta Gindulyte, Lianyi Han, Jane He, Siqian He, Benjamin A. Shoemaker, Jiyao Wang, Bo Yu, Jian Zhang, and Stephen H. Bryant. PubChem substance and compound databases.Nucleic Acids Research, 44(D1):D1202–D1213, 2015
work page 2015
-
[15]
Renxiao Wang, Xueliang Fang, Yipin Lu, Chao-Yie Yang, and Shaomeng Wang. The PDBbind Database: Methodologies and Updates.Journal of Medicinal Chemistry, 48(12):4111–4119, 2005
work page 2005
-
[16]
Tiqing Liu, Yuhmei Lin, Xin Wen, Robert N. Jorissen, and Michael K. Gilson. Bind- ingDB: A web-accessible database of experimentally determined protein-ligand binding affinities.Nucleic Acids Research, 35(Database issue):D198–201, 2007-01, 2007
work page 2007
-
[17]
Peter Ertl and Ansgar Schuffenhauer. Estimation of synthetic accessibility score of drug-like molecules based on molecular complexity and fragment contributions.Journal of Cheminformatics, 1(1):8, 2009
work page 2009
-
[18]
RDKit: Open-source cheminformatics, 2023
Greg Landrum. RDKit: Open-source cheminformatics, 2023
work page 2023
-
[19]
G. Richard Bickerton, Gaia V. Paolini, J´ er´ emy Besnard, Sorel Muresan, and Andrew L. Hopkins. Quantifying the chemical beauty of drugs.Nature Chemistry, 4(2):90–98, 2012
work page 2012
-
[20]
Miguel Garc´ ıa-Orteg´ on, Gregor N. C. Simm, Austin J. Tripp, Jos´ e Miguel Hern´ andez- Lobato, Andreas Bender, and Sergio Bacallado. DOCKSTRING: Easy Molecular Dock- ing Yields Better Benchmarks for Ligand Design.Journal of Chemical Information and Modeling, 62(15):3486–3502, 2022
work page 2022
-
[21]
Alexander Kensert, Gert Desmet, and Deirdre Cabooter. MolGraph: A Python package for the implementation of molecular graphs and graph neural networks with TensorFlow and Keras.arXiv:2208.09944, 2022
-
[22]
Yuliana Yosaatmadja, Shevan Silva, James M. Dickson, Adam V. Patterson, Jeff B. Smaill, Jack U. Flanagan, Mark J. McKeage, and Christopher J. Squire. Binding mode of the breakthrough inhibitor AZD9291 to epidermal growth factor receptor revealed. Journal of Structural Biology, 192(3):539–544, 2015
work page 2015
-
[23]
Hongyan Du, Junbo Gao, Gaoqi Weng, Junjie Ding, Xin Chai, Jinping Pang, Yu Kang, Dan Li, Dongsheng Cao, and Tingjun Hou. CovalentInDB: A comprehensive database facilitating the discovery of covalent inhibitors.Nucleic Acids Research, 49(D1):D1122– D1129, 2021-01-08, 2021
work page 2021
-
[24]
Pope, Soheil Kolouri, Mohammad Rostami, Charles E
Phillip E. Pope, Soheil Kolouri, Mohammad Rostami, Charles E. Martin, and Heiko Hoffmann. Explainability methods for graph convolutional neural networks. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10764–10773, 2019-06, 2019. 26
work page 2019
-
[25]
Riel, Bekim Bajrami, Bin Deng, Amy R
Lei Wang, Louis P. Riel, Bekim Bajrami, Bin Deng, Amy R. Howell, and Xudong Yao. α-Methylene-β-Lactone Scaffold for Developing Chemical Probes at the Two Ends of the Selectivity Spectrum.ChemBioChem, 22(3):505–515, 2021
work page 2021
-
[26]
G. Guillerm, D. Guillerm, C. Vandenplas-Witkowki, H. Rogniaux, N. Carte, E. Leize, A. Van Dorsselaer, E. De Clercq, and C. Lambert. Synthesis, mechanism of action, and antiviral activity of a new series of covalent mechanism-based inhibitors of S-adenosyl- L-homocysteine hydrolase.Journal of Medicinal Chemistry, 44(17):2743–2752, 2001
work page 2001
-
[27]
Yildiz Tasdan, Gautham Balaji, Naureen Akhtar, Olga Ilyichova, Taylor Cunliffe, Beg- ona Heras, Loic Le Strat, James Murray, Ben Capuano, Martin Scanlon, and Bradley Doak. Identification of an Allene Warhead that Selectively Targets a Histidine Residue in the Escherichia coli Oxidoreductase Enzyme DsbA.ChemRxiv, 2024
work page 2024
-
[28]
Lu´ ıs A. R. Carvalho, Vanessa T. Almeida, Jos´ e A. Brito, Kenneth M. Lum, Tˆ ania F. Oliveira, Rita C. Guedes, L´ ıdia M. Gon¸ calves, Susana D. Lucas, Benjamin F. Cravatt, Margarida Archer, and Rui Moreira. 3-Oxo-β-sultam as a Sulfonylating Chemotype for Inhibition of Serine Hydrolases and Activity-Based Protein Profiling.ACS Chemical Biology, 15(4):87...
work page 2020
-
[29]
Wing-Yin Tsang, Naveed Ahmed, Karl Hemming, and Michael I. Page. Reactivity and selectivity in the inhibition of elastase by 3-oxo-β-sultams and in their hydrolysis. Organic & Biomolecular Chemistry, 5(24):3993–4000, 2007. 27
work page 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.