The GaoYao Benchmark: A Comprehensive Framework for Evaluating Multilingual and Multicultural Abilities of Large Language Models
Pith reviewed 2026-05-10 00:45 UTC · model grok-4.3
The pith
GaoYao benchmark uses expert localization to evaluate LLMs in 19 languages and across 34 cultures with a three-layer framework.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GaoYao categorizes evaluation into General Multilingual, Cross-cultural, and Monocultural layers along with nine cognitive sub-layers, achieves native-quality data expansion by expert localization of subjective benchmarks into 19 languages and synthesis of cross-cultural sets for 34 cultures, and performs in-depth analysis on 20+ LLMs to identify geographical disparities and task gaps.
What carries the argument
The unified framework with three cultural layers (General Multilingual, Cross-cultural, Monocultural) and nine cognitive sub-layers, supported by expert-localized test data.
If this is right
- Models exhibit significant differences in performance across different geographical regions.
- Clear gaps exist between performance on various task types within the benchmark.
- The benchmark supplies a detailed diagnostic tool to guide future development of LLMs.
- Expanded coverage surpasses previous benchmarks by as much as 111% in some areas.
Where Pith is reading between the lines
- Similar layered frameworks could improve evaluations in other domains like vision or reasoning models.
- Emphasizing expert localization over machine translation may become a standard for cultural AI assessments.
- Developers could use the identified gaps to prioritize training data from underrepresented cultures.
Load-bearing premise
Expert localization of subjective benchmarks into multiple languages and synthesis for various cultures accurately reflects authentic cultural nuances rather than just surface-level adaptations.
What would settle it
If re-running the diagnostic analysis on the same models using only machine-translated versions of the tests yields the same geographical disparities and task gaps as the expert-localized versions.
Figures








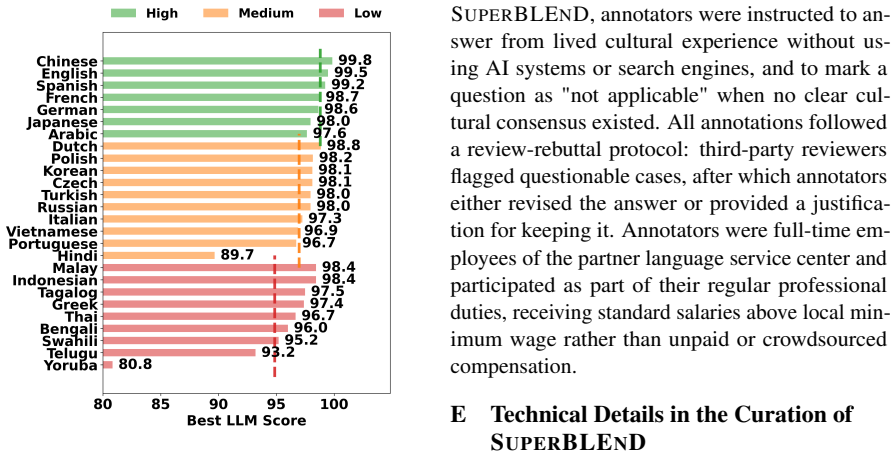
read the original abstract
Evaluating the multilingual and multicultural capabilities of Large Language Models (LLMs) is essential for their global utility. However, current benchmarks face three critical limitations: (1) fragmented evaluation dimensions that often neglect deep cultural nuances; (2) insufficient language coverage in subjective tasks relying on low-quality machine translation; and (3) shallow analysis that lacks diagnostic depth beyond simple rankings. To address these, we introduce GaoYao, a comprehensive benchmark with 182.3k samples, 26 languages and 51 nations/areas. First, GaoYao proposes a unified framework categorizing evaluation tasks into three cultural layers (General Multilingual, Cross-cultural, Monocultural) and nine cognitive sub-layers. Second, we achieve native-quality expansion by leveraging experts to rigorously localize subjective benchmarks into 19 languages and synthesizing cross-cultural test sets for 34 cultures, surpassing prior coverage by up to 111%. Third, we conduct an in-depth diagnostic analysis on 20+ flagship and compact LLMs. Our findings reveal significant geographical performance disparities and distinct gaps between tasks, offering a reliable map for future work. We release the benchmark (https://github.com/lunyiliu/GaoYao).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce GaoYao, a comprehensive benchmark with 182.3k samples across 26 languages and 51 nations/areas for evaluating LLMs' multilingual and multicultural abilities. It categorizes tasks into three cultural layers (General Multilingual, Cross-cultural, Monocultural) and nine cognitive sub-layers. The key innovation is achieving native-quality expansion through expert localization of subjective benchmarks into 19 languages and synthesizing cross-cultural test sets for 34 cultures, surpassing prior coverage by up to 111%. Additionally, it provides an in-depth diagnostic analysis on 20+ LLMs revealing geographical disparities and task gaps.
Significance. If the localization process successfully captures deep cultural nuances, this benchmark could significantly improve the evaluation of LLMs for global use by offering greater language and cultural coverage than existing resources. The layered framework and diagnostic analysis provide a structured way to identify specific weaknesses in models, which could inform targeted improvements. The release of the benchmark data would be a positive contribution to the field.
major comments (1)
- [Abstract and benchmark construction] The assertion of 'native-quality expansion' via expert localization into 19 languages and synthesis for 34 cultures (Abstract) lacks any reported quantitative validation, such as inter-expert agreement rates, comparison to machine-translation baselines, or metrics demonstrating preservation of deep cultural nuances versus surface-level adaptations. This is load-bearing for the central claim, as the three-layer framework, the 111% coverage superiority, and all downstream diagnostic findings on LLMs are only interpretable if the test items genuinely reflect cultural distinctions rather than translation artifacts or imposed categories.
minor comments (2)
- [Abstract] The 111% coverage claim is presented without a clear baseline benchmark, exact comparison metric, or supporting table/figure; adding this would clarify the scale of the advance.
- [Framework description] The nine cognitive sub-layers are referenced but would benefit from explicit definitions or examples in the main text to aid reader understanding of the framework.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address the single major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and benchmark construction] The assertion of 'native-quality expansion' via expert localization into 19 languages and synthesis for 34 cultures (Abstract) lacks any reported quantitative validation, such as inter-expert agreement rates, comparison to machine-translation baselines, or metrics demonstrating preservation of deep cultural nuances versus surface-level adaptations. This is load-bearing for the central claim, as the three-layer framework, the 111% coverage superiority, and all downstream diagnostic findings on LLMs are only interpretable if the test items genuinely reflect cultural distinctions rather than translation artifacts or imposed categories.
Authors: We agree that quantitative validation of the localization process is important for supporting the central claims. Section 3.2 of the manuscript describes the expert-driven localization workflow, in which native speakers and cultural experts from each of the 19 languages performed rigorous adaptation of subjective items to preserve intent, nuance, and cultural appropriateness, while cross-cultural test sets for 34 cultures were synthesized through consultation with domain experts. However, we did not include explicit inter-expert agreement statistics or direct machine-translation baselines in the submitted version. In the revised manuscript we will add: (1) inter-annotator agreement rates (Cohen’s kappa) computed on a 10% overlap subset of localized items; (2) a controlled comparison on 500 sampled items between expert-localized and machine-translated versions, reporting both automatic semantic similarity and expert-rated cultural fidelity scores; and (3) a brief discussion of how the three-layer framework was applied during localization to avoid imposed categories. These additions will directly address the load-bearing concern and improve interpretability of the coverage numbers (Table 1) and the diagnostic results. We believe the core methodology remains sound but accept that the requested metrics will make the evidence more robust. revision: yes
Circularity Check
No circularity: benchmark construction via external data collection
full rationale
The paper presents a new evaluation benchmark (GaoYao) built by proposing a three-layer cultural framework, recruiting experts for localization of existing subjective tasks into 19 languages, synthesizing cross-cultural sets for 34 cultures, and running diagnostic tests on LLMs. No equations, parameter fitting, predictions, or derivations appear in the abstract or described claims. The coverage increase (up to 111%) and 'native-quality' assertions are presented as outcomes of the described collection protocol rather than reductions to self-defined inputs or self-citations. The framework is an organizing taxonomy, not a result derived from prior work by the same authors. This matches the default case of a self-contained benchmark paper whose value rests on external data rather than internal circular logic.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InFindings of the Association for Computational Linguistics: EACL 2024, pages 1347–1356
Monolingual or multilingual instruction tun- ing: Which makes a better alpaca. InFindings of the Association for Computational Linguistics: EACL 2024, pages 1347–1356. Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anasta- sios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, et al. 2024. Chatbot arena: A...
work page 2024
-
[2]
Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261. DeepSeek. 2025. Deepseek-v3.1 release. https:// api-docs.deepseek.com/news/news250821. DeepSeek-AI. 2025. Deepseek-r1: Incentivizing rea- soning capability in llms via reinforcement learning. In...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
InFirst Conference on Language Modeling
Continual pre-training for cross-lingual llm adaptation: Enhancing japanese language capabili- ties. InFirst Conference on Language Modeling. Naman Goyal, Cynthia Gao, Vishrav Chaudhary, Peng- Jen Chen, Guillaume Wenzek, Da Ju, Sanjana Kr- ishnan, Marc’Aurelio Ranzato, Francisco Guzmán, and Angela Fan. 2022. The flores-101 evaluation benchmark for low-res...
-
[4]
InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 4297–4308
Revisiting catastrophic forgetting in large lan- guage model tuning. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 4297–4308. Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Alpacaeval: An au- tomatic evaluator of instruction-following mo...
-
[5]
Multilingual!= multicultural: Evaluating gaps between multilingual capabilities and cultural align- ment in llms.arXiv preprint arXiv:2502.16534. Edgar H Schein. 2010.Organizational culture and leadership, volume 2. John Wiley & Sons. Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush V osoughi, Hyung Won Chung, Yi Tay, Sebastian...
-
[6]
InProceedings of the 62th Annual Meeting of the Association for Computational Linguistics
Plug: Leveraging pivot language in cross- lingual instruction tuning. InProceedings of the 62th Annual Meeting of the Association for Computational Linguistics. ACL. Qiguang Zhao. 1988.A study of dragonology, East and West. University of Massachusetts Amherst. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Z...
work page 1988
-
[7]
Extrapolating large lan- guage models to non-english by aligning languages,
Overcoming language barriers via machine translation with sparse mixture-of-experts fusion of large language models.Information Processing & Management, 62(3):104078. Wenhao Zhu, Yunzhe Lv, Qingxiu Dong, Fei Yuan, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, and Lei Li. 2023. Extrapolating large language models to non-english by aligning langua...
-
[8]
refer- ence (correctness, richness, comprehen- siveness, etc.)
Judge compares candidate vs. refer- ence (correctness, richness, comprehen- siveness, etc.)
-
[9]
Accuracy Rule- based Human (Open Source)
Win Rate=#win+#tie/2 #all Belebele MCQ Obj. Accuracy Rule- based Human (Open Source)
-
[10]
Reading comprehension, 4-option regex match (A-D)
-
[11]
Accuracy Rule- based Human (Open Source)
Accuracy=#correct #all INCLUDE MCQ Obj. Accuracy Rule- based Human (Open Source)
-
[12]
Encyclopedic knowledge, 4-option regex match (A-D)
-
[13]
Accuracy Rule- based Human and LLM Hybrid
Accuracy=#correct #all SuperBLEnD MCQ Obj. Accuracy Rule- based Human and LLM Hybrid
-
[14]
Regional culture knowledge, 4-option regex match (A-D)
-
[15]
Accuracy Rule- based Human (Open Source)
Accuracy=#correct #all MGSM Math Obj. Accuracy Rule- based Human (Open Source)
-
[16]
Math reasoning, regex match for inte- ger answers
-
[17]
Accuracy Rule- based Human and LLM Hybrid (Open Source)
Accuracy=#correct #all MMMLU MCQ Obj. Accuracy Rule- based Human and LLM Hybrid (Open Source)
- [18]
-
[19]
Comet wmt22 comet -da Human Trans- lated Wiki
Accuracy=#correct #all Flores-101 TranslationObj. Comet wmt22 comet -da Human Trans- lated Wiki
-
[20]
Mixed Deep Seek V3.1 Qwen3- max
Comet Score SAGE MCQ+ T/F+ QA Subj.+ Obj. Mixed Deep Seek V3.1 Qwen3- max
-
[21]
QA use LLM to recognize cul- ture points mentioned in the answer; 3
MCQ and T/F uses accuracy as score; 2. QA use LLM to recognize cul- ture points mentioned in the answer; 3. weighted sum score is used as final score. CultureScopeMCQ+ T/F+ QA Subj.+ Obj. Mixed Deep Seek V3.1 Human Expert
-
[22]
QA use LLM to recognize cul- ture points mentioned in the answer; 3
MCQ and T/F uses accuracy as score; 2. QA use LLM to recognize cul- ture points mentioned in the answer; 3. weighted sum score is used as final score. S-MT-Bench QA Subj. Win Rate Deep Seek V3.1 Qwen3- 235B- A22B
-
[23]
Judge comparison (multi-turn aver- aged)
-
[24]
Task types include Multiple Choice Questions (MCQ), True/False (T/F), and Open-ended Q&A (QA)
Win Rate=#win+#tie/2 #all Table 6: Summary of evaluation methodologies. Task types include Multiple Choice Questions (MCQ), True/False (T/F), and Open-ended Q&A (QA). Evaluation types distinguish between subjective (Subj.) LLM-judged approaches and objective (Obj.) rule-based approaches. MGSM only generate Integer as final answer. Model Model Version Reso...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.