Recognition: unknown
HaS: Accelerating RAG through Homology-Aware Speculative Retrieval
Pith reviewed 2026-05-09 23:21 UTC · model grok-4.3
The pith
HaS accelerates RAG retrieval by running quick speculative searches in limited scopes and accepting the results when the current query matches a prior homologous one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HaS performs low-latency speculative retrieval over restricted scopes to obtain candidate documents, followed by validating whether they contain the required knowledge. The validation, grounded in the homology relation between queries, is formulated as a homologous query re-identification task: once a previously observed query is identified as a homologous re-encounter of the incoming query, the draft is deemed acceptable, allowing the system to bypass slow full-database retrieval. Benefiting from the prevalence of homologous queries under real-world popularity patterns, HaS achieves substantial efficiency gains.
What carries the argument
The homologous query re-identification task that decides acceptance of a speculative document draft by matching the current query to a prior homologous query.
If this is right
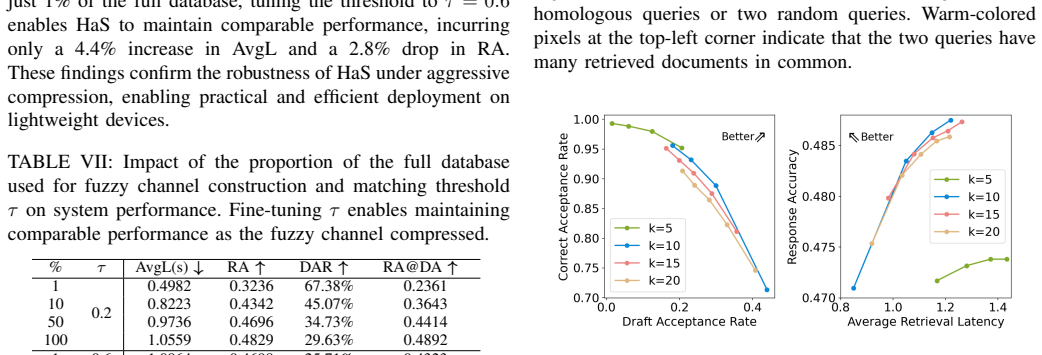
- Retrieval latency falls 23.74 percent to 36.99 percent on the evaluated datasets.
- Answer accuracy declines by only 1 to 2 percent.
- Complex multi-hop queries inside agentic RAG pipelines complete faster without any modification to the underlying retriever or generator.
- The approach functions as a drop-in layer that leaves existing RAG code unchanged.
Where Pith is reading between the lines
- Query logs could be mined offline to pre-build larger sets of homology-linked drafts, further increasing the hit rate.
- The method may combine naturally with approximate nearest-neighbor indexes, because the speculative stage already operates on restricted scopes.
- In production settings the savings would grow when the same homology cache is shared across many users with overlapping interests.
Load-bearing premise
Real-world queries often share close homology with earlier ones, and matching to such an earlier query reliably shows that its documents already contain everything the new query needs.
What would settle it
A workload of mostly unique queries with no detectable homologues, or a direct count of cases in which the homology check accepts documents that later prove insufficient for correct generation.
Figures













read the original abstract
Retrieval-Augmented Generation (RAG) expands the knowledge boundary of large language models (LLMs) at inference by retrieving external documents as context. However, retrieval becomes increasingly time-consuming as the knowledge databases grow in size. Existing acceleration strategies either compromise accuracy through approximate retrieval, or achieve marginal gains by reusing results of strictly identical queries. We propose HaS, a homology-aware speculative retrieval framework that performs low-latency speculative retrieval over restricted scopes to obtain candidate documents, followed by validating whether they contain the required knowledge. The validation, grounded in the homology relation between queries, is formulated as a homologous query re-identification task: once a previously observed query is identified as a homologous re-encounter of the incoming query, the draft is deemed acceptable, allowing the system to bypass slow full-database retrieval. Benefiting from the prevalence of homologous queries under real-world popularity patterns, HaS achieves substantial efficiency gains. Extensive experiments demonstrate that HaS reduces retrieval latency by 23.74% and 36.99% across datasets with only a 1-2% marginal accuracy drop. As a plug-and-play solution, HaS also significantly accelerates complex multi-hop queries in modern agentic RAG pipelines. Source code is available at: https://github.com/ErrEqualsNil/HaS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HaS, a homology-aware speculative retrieval framework for RAG systems. It performs low-latency speculative retrieval over restricted scopes to obtain candidate documents, then validates them via a homologous query re-identification task that allows bypassing full-database retrieval when a prior query is deemed homologous. The approach leverages real-world query popularity patterns and is presented as plug-and-play, with experiments claiming 23.74% and 36.99% latency reductions across datasets at a 1-2% accuracy cost, plus gains on multi-hop agentic queries.
Significance. If the homology validation proves reliable, HaS could offer a practical efficiency boost for large-scale RAG without heavy accuracy trade-offs, particularly valuable as knowledge bases grow and for complex multi-hop pipelines. The open-source code at the provided GitHub link supports reproducibility and is a clear strength.
major comments (3)
- [§3] §3 (Method, homology definition and re-identification task): The central bypass decision rests on identifying 'homologous re-encounters' as sufficient to confirm that restricted-scope candidates contain all required knowledge. However, no formal definition of homology in terms of knowledge overlap or information need is provided, nor are precision/recall metrics for the re-identification classifier reported. This leaves the 1-2% accuracy claim unanchored and risks accepting insufficient candidate sets, especially for multi-hop queries where partial coverage can break reasoning chains.
- [§4] §4 (Experiments): The reported latency reductions (23.74% and 36.99%) and accuracy drops are presented as aggregate results without breakdowns by query similarity buckets, homology strength, or multi-hop vs. single-hop cases. No details on the validation procedure, raw data, or statistical tests are given, making it impossible to confirm that measurements support the claims or rule out post-hoc tuning.
- [§4.2] §4.2 (Multi-hop evaluation): The claim that HaS 'significantly accelerates complex multi-hop queries' is load-bearing for the agentic RAG use case, yet no per-hop accuracy or failure-mode analysis is shown. If homology detection accepts partial document sets, chain-level accuracy could degrade more than the marginal 1-2% aggregate suggests.
minor comments (2)
- [Abstract] The abstract and introduction use 'homology' without an initial informal definition or example, which could confuse readers unfamiliar with the term in this IR context.
- [§4] Table or figure captions for latency/accuracy results should explicitly state the number of runs, confidence intervals, and exact datasets used to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method, homology definition and re-identification task): The central bypass decision rests on identifying 'homologous re-encounters' as sufficient to confirm that restricted-scope candidates contain all required knowledge. However, no formal definition of homology in terms of knowledge overlap or information need is provided, nor are precision/recall metrics for the re-identification classifier reported. This leaves the 1-2% accuracy claim unanchored and risks accepting insufficient candidate sets, especially for multi-hop queries where partial coverage can break reasoning chains.
Authors: We agree that a formal definition of homology grounded in knowledge overlap would improve clarity. In the revised manuscript we will add an explicit definition: two queries are homologous if the document set sufficient to answer the first query is also sufficient to answer the second (i.e., their information needs are covered by the same restricted-scope candidates). We will also report precision and recall of the re-identification classifier on a held-out query-pair validation set in Section 3, together with a brief discussion of failure cases for multi-hop queries. These additions will better anchor the reported accuracy figures. revision: yes
-
Referee: [§4] §4 (Experiments): The reported latency reductions (23.74% and 36.99%) and accuracy drops are presented as aggregate results without breakdowns by query similarity buckets, homology strength, or multi-hop vs. single-hop cases. No details on the validation procedure, raw data, or statistical tests are given, making it impossible to confirm that measurements support the claims or rule out post-hoc tuning.
Authors: We will expand Section 4 with breakdowns by query-similarity buckets, homology strength, and separate single-hop versus multi-hop results. We will also add a description of the validation procedure (training and evaluation of the re-identification model), report statistical significance (paired t-tests) for the latency and accuracy differences, and point readers to the already-public GitHub repository for raw per-query logs. A supplementary table summarizing per-bucket statistics will be included if space allows. revision: yes
-
Referee: [§4.2] §4.2 (Multi-hop evaluation): The claim that HaS 'significantly accelerates complex multi-hop queries' is load-bearing for the agentic RAG use case, yet no per-hop accuracy or failure-mode analysis is shown. If homology detection accepts partial document sets, chain-level accuracy could degrade more than the marginal 1-2% aggregate suggests.
Authors: We will augment Section 4.2 with per-hop accuracy metrics and a failure-mode analysis that isolates cases where homology detection may accept partial document sets. This will quantify whether the aggregate 1-2% drop masks larger per-hop degradations and will include concrete examples of successful and unsuccessful multi-hop chains. Any observed limitations will be reported transparently. revision: yes
Circularity Check
No circularity: empirical claims rest on external measurements
full rationale
The paper presents HaS as an empirical framework whose latency and accuracy gains are demonstrated through experiments on datasets, with no derivation chain, fitted parameters renamed as predictions, or load-bearing self-citations. The homology re-identification task is introduced as a formulation whose validity is checked experimentally rather than by construction from prior results or definitions within the paper itself. No equations or self-referential reductions appear in the provided description.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Homologous queries are prevalent under real-world popularity patterns
- domain assumption Homology-based validation accurately identifies when speculative candidates contain the required knowledge
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K¨uttler, M. Lewis, W.-t. Yih, T. Rockt¨aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive nlp tasks,” in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 9459–9474
2020
-
[2]
Cacheblend: Fast large language model serving for rag with cached knowledge fusion,
J. Yao, H. Li, Y . Liu, S. Ray, Y . Cheng, Q. Zhang, K. Du, S. Lu, and J. Jiang, “Cacheblend: Fast large language model serving for rag with cached knowledge fusion,” inProceedings of the Twentieth European Conference on Computer Systems, 2025, p. 94–109
2025
-
[3]
RAG- Cache: Efficient knowledge caching for retrieval-augmented generation,
C. Jin, Z. Zhang, X. Jiang, F. Liu, S. Liu, X. Liu, and X. Jin, “RAG- Cache: Efficient knowledge caching for retrieval-augmented generation,” ACM Trans. Comput. Syst., vol. 44, no. 1, Nov. 2025
2025
-
[4]
xrag: Extreme context compression for retrieval-augmented generation with one token,
X. Cheng, X. Wang, X. Zhang, T. Ge, S.-Q. Chen, F. Wei, H. Zhang, and D. Zhao, “xrag: Extreme context compression for retrieval-augmented generation with one token,” inAdvances in Neural Information Process- ing Systems, vol. 37, 2024, pp. 109 487–109 516
2024
-
[5]
Accelerating retrieval-augmented generation,
D. Quinn, M. Nouri, N. Patel, J. Salihu, A. Salemi, S. Lee, H. Za- mani, and M. Alian, “Accelerating retrieval-augmented generation,” in Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, 2025, p. 15–32
2025
-
[6]
Auto-RAG: Autonomous Retrieval-Augmented Generation for Large Language Models,
T. Yu, S. Zhang, and Y . Feng, “Auto-RAG: Autonomous retrieval- augmented generation for large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2411.19443
-
[7]
RA-ISF: Learning to answer and understand from retrieval augmentation via it- erative self-feedback,
Y . Liu, X. Peng, X. Zhang, W. Liu, J. Yin, J. Cao, and T. Du, “RA-ISF: Learning to answer and understand from retrieval augmentation via it- erative self-feedback,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 4730–4749
2024
-
[8]
Im-rag: Multi-round retrieval-augmented generation through learning inner monologues,
D. Yang, J. Rao, K. Chen, X. Guo, Y . Zhang, J. Yang, and Y . Zhang, “Im-rag: Multi-round retrieval-augmented generation through learning inner monologues,” inProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024, p. 730–740
2024
-
[9]
Modular RAG: Transforming RAG systems into LEGO-like reconfigurable frameworks,
Y . Gao, Y . Xiong, M. Wang, and H. Wang, “Modular RAG: Transforming RAG systems into LEGO-like reconfigurable frameworks,” 2024. [Online]. Available: https://arxiv.org/abs/2407.21059
-
[10]
Accelerating large-scale inference with anisotropic vector quantization,
R. Guo, P. Sun, E. Lindgren, Q. Geng, D. Simcha, F. Chern, and S. Kumar, “Accelerating large-scale inference with anisotropic vector quantization,” inProceedings of the 37th International Conference on Machine Learning, vol. 119, 2020, pp. 3887–3896
2020
-
[11]
Caching historical embeddings in conversational search,
O. Frieder, I. Mele, C. I. Muntean, F. M. Nardini, R. Perego, and N. Tonellotto, “Caching historical embeddings in conversational search,” ACM Trans. Web, vol. 18, no. 4, 2024
2024
-
[12]
Leveraging approximate caching for faster retrieval- augmented generation,
S. A. Bergman, Z. Ji, A.-M. Kermarrec, D. Petrescu, R. Pires, M. Randl, and M. de V os, “Leveraging approximate caching for faster retrieval- augmented generation,” inProceedings of the 5th Workshop on Machine Learning and Systems, 2025, p. 66–73
2025
-
[13]
Cache-craft: Managing chunk-caches for efficient retrieval-augmented generation,
S. Agarwal, S. Sundaresan, S. Mitra, D. Mahapatra, A. Gupta, R. Sharma, N. J. Kapu, T. Yu, and S. Saini, “Cache-craft: Managing chunk-caches for efficient retrieval-augmented generation,”Proc. ACM Manag. Data, vol. 3, no. 3, 2025
2025
-
[14]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan et al., “The Llama 3 herd of models,” 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mistral 7b,” 2023. [Online]. Available: https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
The faiss library,
M. Douze, A. Guzhva, C. Deng, J. Johnson, G. Szilvasy, P.-E. Mazar ´e, M. Lomeli, L. Hosseini, and H. J ´egou, “The faiss library,”IEEE Transactions on Big Data, 2025
2025
-
[18]
Dense passage retrieval for open-domain question an- swering,
V . Karpukhin, B. Oguz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W.-t. Yih, “Dense passage retrieval for open-domain question an- swering,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 6769–6781
2020
-
[19]
Narrowing the knowledge eval- uation gap: Open-domain question answering with multi-granularity answers,
G. Yona, R. Aharoni, and M. Geva, “Narrowing the knowledge eval- uation gap: Open-domain question answering with multi-granularity answers,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 6737– 6751
2024
-
[20]
Simple entity-centric questions challenge dense retrievers,
C. Sciavolino, Z. Zhong, J. Lee, and D. Chen, “Simple entity-centric questions challenge dense retrievers,” inProceedings of the 2021 Con- ference on Empirical Methods in Natural Language Processing, 2021, pp. 6138–6148
2021
-
[21]
When not to trust language models: Investigating effectiveness of para- metric and non-parametric memories,
A. Mallen, A. Asai, V . Zhong, R. Das, D. Khashabi, and H. Hajishirzi, “When not to trust language models: Investigating effectiveness of para- metric and non-parametric memories,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 9802–9822
2023
-
[22]
Self-rag: Learning to retrieve, generate, and critique through self-reflection,
A. Asai, Z. Wu, Y . Wang, A. Sil, and H. Hajishirzi, “Self-rag: Learning to retrieve, generate, and critique through self-reflection,” inThe Twelfth International Conference on Learning Representations, 2023
2023
-
[23]
Min- Cache: A hybrid cache system for efficient chatbots with hierarchical embedding matching and LLM,
K. Haqiq, M. V . Jahan, S. A. Farimani, and S. M. F. Masoom, “Min- Cache: A hybrid cache system for efficient chatbots with hierarchical embedding matching and LLM,”Future Generation Computer Systems, vol. 170, p. 107822, 2025
2025
-
[24]
Corrective Retrieval Augmented Generation
S.-Q. Yan, J.-C. Gu, Y . Zhu, and Z.-H. Ling, “Corrective retrieval augmented generation,” 2024. [Online]. Available: https://arxiv.org/abs/ 2401.15884
work page internal anchor Pith review arXiv 2024
-
[25]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension,
M. Joshi, E. Choi, D. S. Weld, and L. Zettlemoyer, “Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension,”
-
[26]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
[Online]. Available: https://arxiv.org/abs/1705.03551
work page internal anchor Pith review arXiv
-
[27]
SQuAD: 100,000+ questions for machine comprehension of text,
P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang, “SQuAD: 100,000+ questions for machine comprehension of text,” inProceedings of the 2016 Conference on Empirical Methods in Natural Language Process- ing, 2016, pp. 2383–2392
2016
-
[28]
Long-context LLMs meet RAG: Overcoming challenges for long inputs in RAG,
B. Jin, J. Yoon, J. Han, and S. O. Arik, “Long-context LLMs meet RAG: Overcoming challenges for long inputs in RAG,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[29]
Unsupervised Dense Information Retrieval with Contrastive Learning
G. Izacard, M. Caron, L. Hosseini, S. Riedel, P. Bojanowski, A. Joulin, and E. Grave, “Unsupervised dense information retrieval with contrastive learning,” 2022. [Online]. Available: https://arxiv.org/abs/2112.09118
work page internal anchor Pith review arXiv 2022
-
[30]
C-Pack: Packed Resources For General Chinese Embeddings
S. Xiao, Z. Liu, P. Zhang, N. Muennighoff, D. Lian, and J.-Y . Nie, “C-Pack: Packed resources for general chinese embeddings,” 2024. [Online]. Available: https://arxiv.org/abs/2309.07597
work page internal anchor Pith review arXiv 2024
-
[31]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
L. Wang, N. Yang, X. Huang, B. Jiao, L. Yang, D. Jiang, R. Majumder, and F. Wei, “Text embeddings by weakly-supervised contrastive pre- training,” 2024. [Online]. Available: https://arxiv.org/abs/2212.03533
work page internal anchor Pith review arXiv 2024
-
[32]
RECOMP: Improving retrieval-augmented LMs with context compression and selective augmentation,
F. Xu, W. Shi, and E. Choi, “RECOMP: Improving retrieval-augmented LMs with context compression and selective augmentation,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[33]
Speculative RAG: Enhancing retrieval augmented generation through drafting,
Z. Wang, Z. Wang, L. Le, S. Zheng, S. Mishra, V . Perot, Y . Zhang, A. Mattapalli, A. Taly, J. Shang, C.-Y . Lee, and T. Pfister, “Speculative RAG: Enhancing retrieval augmented generation through drafting,” in The Thirteenth International Conference on Learning Representations, 2025
2025
-
[34]
TurboRAG: Ac- celerating retrieval-augmented generation with precomputed KV caches for chunked text,
S. Lu, H. Wang, Y . Rong, Z. Chen, and Y . Tang, “TurboRAG: Ac- celerating retrieval-augmented generation with precomputed KV caches for chunked text,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 6588–6601
2025
-
[35]
Efficient and robust approxi- mate nearest neighbor search using hierarchical navigable small world graphs,
Y . A. Malkov and D. A. Yashunin, “Efficient and robust approxi- mate nearest neighbor search using hierarchical navigable small world graphs,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, vol. 42, no. 4, pp. 824–836, 2020
2020
-
[36]
Z. Hei, W. Liu, W. Ou, J. Qiao, J. Jiao, G. Song, T. Tian, and Y . Lin, “DR-RAG: Applying dynamic document relevance to retrieval-augmented generation for question-answering,” 2024. [Online]. Available: https://arxiv.org/abs/2406.07348
-
[37]
Accelerating inference of retrieval- augmented generation via sparse context selection,
Y . Zhu, J.-C. Gu, C. Sikora, H. Ko, Y . Liu, C.-C. Lin, L. Shu, L. Luo, L. Meng, B. Liu, and J. Chen, “Accelerating inference of retrieval- augmented generation via sparse context selection,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[38]
EACO-RAG: Edge- Assisted and Collaborative RAG with Adaptive Knowledge Update,
J. Li, C. Xu, L. Jia, F. Wang, C. Zhang, and J. Liu, “EACO-RAG: Edge- Assisted and Collaborative RAG with Adaptive Knowledge Update,” Oct. 2024
2024
-
[39]
Federated retrieval augmented generation for multi-product question answering,
P. Shojaee, S. S. Harsha, D. Luo, A. Maharaj, T. Yu, and Y . Li, “Federated retrieval augmented generation for multi-product question answering,” inProceedings of the 31st International Conference on Computational Linguistics: Industry Track, 2025, pp. 387–397
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.