Neuro-Symbolic Manipulation Understanding with Enriched Semantic Event Chains
Pith reviewed 2026-05-09 23:42 UTC · model grok-4.3
The pith
Enriched semantic event chains function as internal states for neuro-symbolic robotic manipulation understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
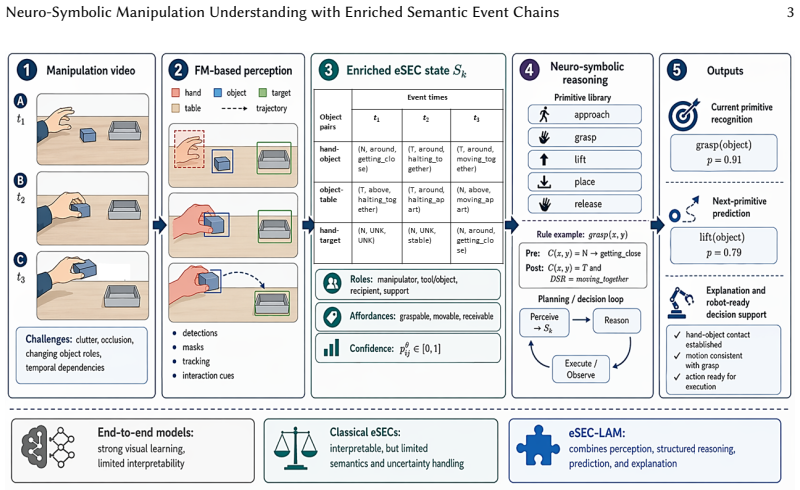
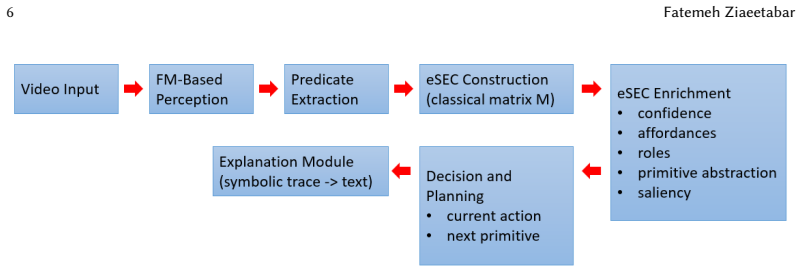
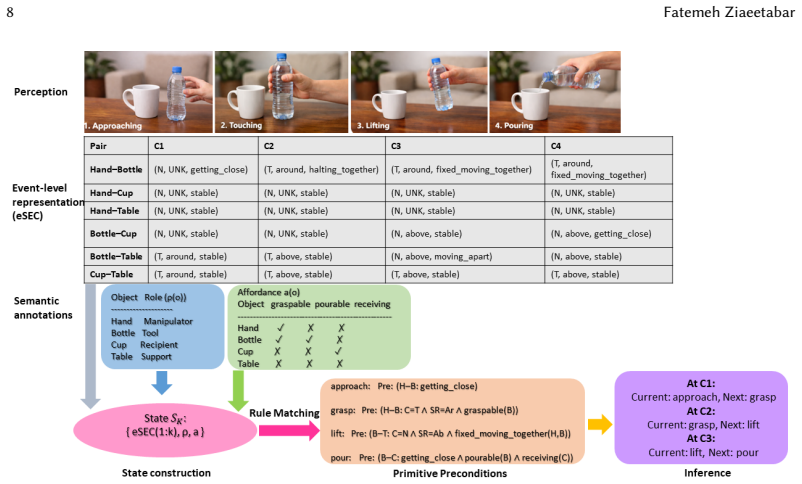
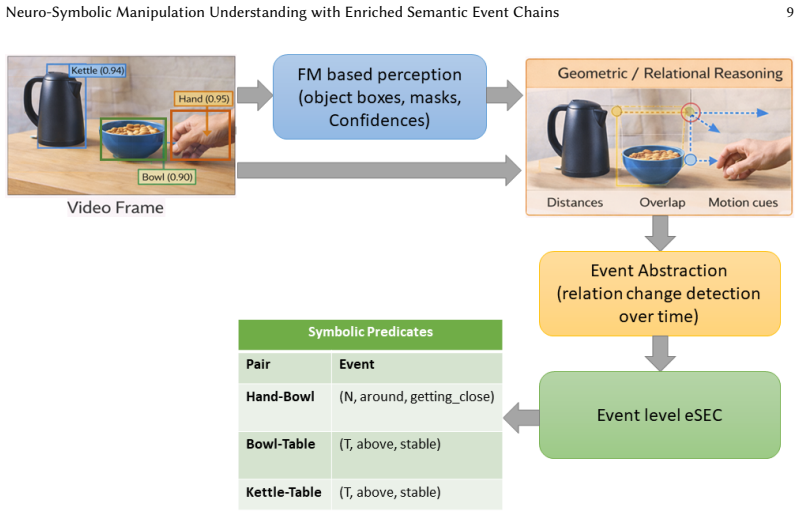
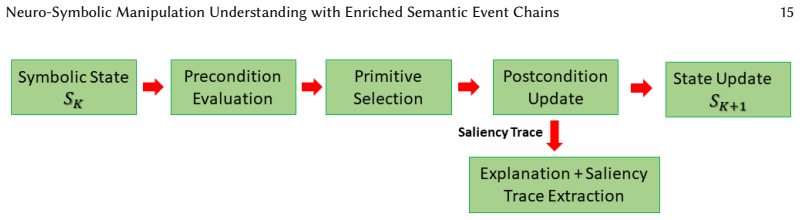
The framework augments enriched Semantic Event Chains with confidence-aware predicates, functional object roles, affordance priors, primitive-level abstraction, and saliency-guided cues to create explicit event-level symbolic states. These states support deterministic extraction from perception and lightweight symbolic reasoning over primitive pre- and post-conditions for current-action inference and next-primitive prediction. The resulting system delivers competitive action recognition, substantially improved next-primitive prediction, enhanced robustness to perceptual degradation, and temporally consistent explanations grounded in relational evidence.
What carries the argument
The enriched semantic event chain serving as an explicit symbolic state that incorporates confidence-aware predicates and affordance priors to support lightweight reasoning over action conditions.
If this is right
- Action recognition reaches levels comparable to existing methods on manipulation videos.
- Accuracy in predicting the next manipulation primitive improves significantly.
- The system maintains performance advantages when visual inputs contain noise or errors.
- Generated explanations stay consistent across time and link directly to observed relations between objects.
Where Pith is reading between the lines
- Such states could support planning by allowing symbolic simulation of future manipulation outcomes.
- The explicit nature might facilitate debugging or verification of robot behaviors in safety-critical settings.
- Extensions could incorporate learned rules to handle more complex or uncertain scenarios beyond fixed conditions.
Load-bearing premise
It assumes that the front-end perception can extract accurate enriched symbolic states with reliable confidence and affordance details, and that reasoning with basic pre- and post-condition rules is adequate for the required inferences and predictions.
What would settle it
Demonstrating that next-primitive prediction accuracy does not exceed that of standard video-based methods, or that performance degrades more than baselines when perception quality drops, would challenge the advantages claimed for the enriched symbolic states.
Figures

read the original abstract
Robotic systems operating in human environments must reason about how object interactions evolve over time, which actions are currently being performed, and what manipulation step is likely to follow. Classical enriched Semantic Event Chains (eSECs) provide an interpretable relational description of manipulation, but remain primarily descriptive and do not directly support uncertainty-aware decision making. In this paper, we propose eSEC-LAM, a neuro-symbolic framework that transforms eSECs into an explicit event-level symbolic state for manipulation understanding. The proposed formulation augments classical eSECs with confidence-aware predicates, functional object roles, affordance priors, primitive-level abstraction, and saliency-guided explanation cues. These enriched symbolic states are derived from a foundation-model-based perception front-end through deterministic predicate extraction, while current-action inference and next-primitive prediction are performed using lightweight symbolic reasoning over primitive pre- and post-conditions. We evaluate the proposed framework on EPIC-KITCHENS-100, EPIC-KITCHENS VISOR, and Assembly101 across action recognition, next-primitive prediction, robustness to perception noise, and explanation consistency. Experimental results show that eSEC-LAM achieves competitive action recognition, substantially improves next-primitive prediction, remains more robust under degraded perceptual conditions than both classical symbolic and end-to-end video baselines, and provides temporally consistent explanation traces grounded in explicit relational evidence. These findings demonstrate that enriched Semantic Event Chains can serve not only as interpretable descriptors of manipulation, but also as effective internal states for neuro-symbolic action reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents eSEC-LAM, a neuro-symbolic framework that augments enriched Semantic Event Chains (eSECs) with confidence-aware predicates, functional object roles, affordance priors, primitive-level abstraction, and saliency-guided explanations. These are extracted deterministically from a foundation-model-based perception front-end. Action recognition and next-primitive prediction are handled via lightweight symbolic reasoning using primitive pre- and post-conditions. The framework is evaluated on EPIC-KITCHENS-100, EPIC-KITCHENS VISOR, and Assembly101 for action recognition, next-primitive prediction, robustness to perception noise, and explanation consistency, claiming competitive performance, substantial improvements in prediction, greater robustness than baselines, and consistent explanations.
Significance. If the experimental claims hold with proper validation, the work could advance neuro-symbolic robotics by turning descriptive eSECs into actionable internal states that support uncertainty-aware inference and temporally consistent explanations. The hybrid design—foundation-model perception feeding deterministic symbolic reasoning over pre-/post-conditions—offers a plausible path to robustness and interpretability that pure end-to-end video models or classical symbolic methods may lack.
major comments (2)
- [Abstract] Abstract: The abstract asserts that eSEC-LAM 'achieves competitive action recognition, substantially improves next-primitive prediction, remains more robust under degraded perceptual conditions than both classical symbolic and end-to-end video baselines,' yet supplies no metrics, baselines, error bars, data splits, or description of how perception noise was simulated. Without these, the support for the central empirical claims cannot be evaluated.
- [Evaluation] Evaluation: The robustness, next-primitive prediction gains, and explanation consistency all rest on the assumption that deterministic predicate extraction from the foundation-model front-end remains reliable under degradation. No predicate-level metrics (e.g., relation extraction F1 or affordance accuracy on clean vs. degraded splits) are reported, leaving open the possibility that downstream symbolic reasoning operates on corrupted inputs.
minor comments (1)
- [Abstract] The acronym 'eSEC-LAM' is introduced without expansion on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major comment point by point below, indicating where revisions will be made to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts that eSEC-LAM 'achieves competitive action recognition, substantially improves next-primitive prediction, remains more robust under degraded perceptual conditions than both classical symbolic and end-to-end video baselines,' yet supplies no metrics, baselines, error bars, data splits, or description of how perception noise was simulated. Without these, the support for the central empirical claims cannot be evaluated.
Authors: We agree that the abstract would be strengthened by including quantitative details. In the revised manuscript, we will update the abstract to report key metrics (e.g., action recognition accuracy on EPIC-KITCHENS-100, relative improvement in next-primitive prediction, and robustness deltas under simulated noise), name the primary baselines, and briefly note the evaluation protocol including data splits and noise simulation approach. These additions will be kept concise while directly supporting the stated claims. revision: yes
-
Referee: [Evaluation] Evaluation: The robustness, next-primitive prediction gains, and explanation consistency all rest on the assumption that deterministic predicate extraction from the foundation-model front-end remains reliable under degradation. No predicate-level metrics (e.g., relation extraction F1 or affordance accuracy on clean vs. degraded splits) are reported, leaving open the possibility that downstream symbolic reasoning operates on corrupted inputs.
Authors: This observation is correct and highlights a useful direction for strengthening the evaluation. While the current results focus on task-level outcomes, we will add predicate-level metrics in the revised manuscript, specifically reporting F1 scores for relation extraction and affordance prediction accuracy on both clean and degraded perceptual splits. This will directly demonstrate the reliability of the deterministic extraction step and confirm that the symbolic reasoning layer receives sufficiently accurate inputs even under noise. revision: yes
Circularity Check
No significant circularity; derivation relies on external perception and independent symbolic rules
full rationale
The paper derives enriched symbolic states via deterministic predicate extraction from an external foundation-model perception front-end and performs inference/prediction via lightweight symbolic reasoning over pre- and post-conditions that are not fitted to the target outputs. No self-definitional loops appear (e.g., no X defined in terms of Y where Y is the claimed result), no fitted parameters are relabeled as predictions, and no load-bearing self-citations or uniqueness theorems reduce the central claims to prior author work. Experimental evaluations on EPIC-KITCHENS and Assembly101 are presented as external benchmarks rather than internal derivations. The framework is therefore self-contained against external inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Foundation-model perception can be used to deterministically extract confidence-aware relational predicates, functional roles, and affordance priors from video
- domain assumption Lightweight symbolic reasoning over primitive pre- and post-conditions is adequate for current-action inference and next-primitive prediction
Forward citations
Cited by 1 Pith paper
-
Trustworthy Visual Predicates for Robust Manipulation Understanding under Degradation
Introduces a structured framework showing that visual predicate failures under degradation are non-uniform, with static predicates more robust than dynamic ones like grasp and release, and quantifies downstream accura...
Reference graph
Works this paper leans on
-
[1]
David Ada Adama, Ahmad Lotfi, Caroline Langensiepen, Kevin Lee, and Pedro Trindade. 2018. Human Activity Learning for Assistive Robotics Using a Classifier Ensemble.Soft Computing22 (2018), 7027–7039
work page 2018
-
[2]
Argall, Sonia Chernova, Manuela Veloso, and Brett Browning
Brenna D. Argall, Sonia Chernova, Manuela Veloso, and Brett Browning. 2009. A Survey of Robot Learning from Demonstration.Robotics and Autonomous Systems57, 5 (2009), 469–483
work page 2009
-
[3]
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Antonino Furnari, Jian Ma, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. 2022. Rescaling Egocentric Vision: Collection, Pipeline and Challenges for EPIC-KITCHENS-100.International Journal of Computer Vision (IJCV)130 (2022), 33–55. https://doi.org/10.1...
-
[4]
Ahmad Darkhalil, Dandan Shan, Bin Zhu, Jian Ma, Amlan Kar, Richard Higgins, Sanja Fidler, David Fouhey, and Dima Damen. 2022. EPIC-KITCHENS VISOR Benchmark: VIdeo Segmentations and Object Relations. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, Vol. 35. 13745–13758
work page 2022
-
[5]
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, et al . 2023. Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
work page 2023
-
[6]
Leslie Pack Kaelbling and Tomás Lozano-Pérez. 2017. Robotic Manipulation of Multiple Objects as a POMDP.Artificial Intelligence247 (2017), 344–369. doi:10.1016/j.artint.2015.04.001
-
[7]
Taein Kwon, Bugra Tekin, Jan Stühmer, Federica Bogo, and Marc Pollefeys. 2021. H2O: Two Hands Manipulating Objects for First Person Interaction Recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 10138–10148
work page 2021
-
[8]
Javier Laplaza, Francesc Moreno, and Alberto Sanfeliu. 2025. Enhancing Robotic Collaborative Tasks Through Contextual Human Motion Prediction and Intention Inference.International Journal of Social Robotics17 (2025), 2077–2096
work page 2025
-
[9]
Xiang Li, Heqian Qiu, Lanxiao Wang, Hanwen Zhang, Chenghao Qi, Linfeng Han, Huiyu Xiong, and Hongliang Li. 2026. Challenges and Trends in Egocentric Vision: A Survey.Machine Intelligence Research23 (2026), 1–33. doi:10.1007/s11633-025-1599-4
-
[10]
Ji Lin, Chuang Gan, and Song Han. 2019. TSM: Temporal Shift Module for Efficient Video Understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
work page 2019
-
[11]
Ziyu Liu, Hongwen Zhang, Zhenghao Chen, Zhiyong Wang, and Wanli Ouyang. 2020. Disentangling and Unifying Graph Convolutions for Skeleton-Based Action Recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 143–152
work page 2020
-
[12]
Fadime Sener, Dibyadip Chatterjee, Daniel Shelepov, Kun He, Dipika Singhania, Robert Wang, and Angela Yao. 2022. Assembly101: A Large-Scale Multi-View Video Dataset for Understanding Procedural Activities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 21096–21106
work page 2022
-
[13]
Md Salman Shamil, Dibyadip Chatterjee, Fadime Sener, Shugao Ma, and Angela Yao. 2024. On the Utility of 3D Hand Poses for Action Recognition. InEuropean Conference on Computer Vision (ECCV)
work page 2024
-
[14]
Tsukasa Shiota, Motohiro Takagi, Kaori Kumagai, Hitoshi Seshimo, and Yushi Aono. 2024. Egocentric Action Recog- nition by Capturing Hand-Object Contact and Object State. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV). 6541–6551
work page 2024
-
[15]
Mohan Sridharan and Ben Meadows. 2019. Towards a Theory of Explanations for Human–Robot Collaboration.KI - Künstliche Intelligenz33 (2019), 331–342
work page 2019
-
[16]
Florentin Wörgötter, Fatemeh Ziaeetabar, S Pfeiffer, O Kaya, T Kulvicius, and M Tamosiunaite. 2020. Humans predict action using grammar-like structures.Scientific reports10, 1 (2020), 3999
work page 2020
-
[17]
Ying Zheng, Lei Yao, Yuejiao Su, Yi Zhang, et al. 2025. A Survey of Embodied Learning for Object-Centric Robotic Manipulation.Machine Intelligence Research22 (2025), 588–626. doi:10.1007/s11633-025-1542-8
-
[18]
Fatemeh Ziaeetabar. 2020.Spatio-temporal reasoning for semantic scene understanding and its application in recognition and prediction of manipulation actions in image sequences. Ph. D. Dissertation. Dissertation, Göttingen, Georg-August Universität, 2019
work page 2020
- [19]
-
[20]
Fatemeh Ziaeetabar, Eren Erdal Aksoy, Florentin Wörgötter, and Minija Tamosiunaite. 2017. Semantic analysis of manipulation actions using spatial relations. In2017 IEEE international conference on robotics and automation (ICRA). IEEE, 4612–4619. , Vol. 1, No. 1, Article . Publication date: April 2026. Neuro-Symbolic Manipulation Understanding with Enriche...
work page 2017
-
[21]
Fatemeh Ziaeetabar, Tomas Kulvicius, Minija Tamosiunaite, and Florentin Wörgötter. 2018. Prediction of manipulation action classes using semantic spatial reasoning. In2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 3350–3357
work page 2018
-
[22]
Fatemeh Ziaeetabar, Tomas Kulvicius, Minija Tamosiunaite, and Florentin Wörgötter. 2018. Recognition and prediction of manipulation actions using enriched semantic event chains.Robotics and Autonomous Systems110 (2018), 173–188
work page 2018
-
[23]
Fatemeh Ziaeetabar, Jennifer Pomp, Stefan Pfeiffer, Nadiya El-Sourani, Ricarda I Schubotz, Minija Tamosiunaite, and Florentin Wörgötter. 2020. Using enriched semantic event chains to model human action prediction based on (minimal) spatial information.Plos one15, 12 (2020), e0243829
work page 2020
-
[24]
Fatemeh Ziaeetabar, Reza Safabakhsh, Saeedeh Momtazi, Minija Tamosiunaite, and Florentin Wörgötter. 2024. Multi sentence description of complex manipulation action videos.Machine Vision and Applications35, 4 (2024), 64
work page 2024
-
[25]
Fatemeh Ziaeetabar, Minija Tamosiunaite, and Florentin Wörgötter. 2024. A hierarchical graph-based approach for recognition and description generation of bimanual actions in videos.IEEE Access(2024)
work page 2024
-
[26]
Fatemeh Ziaeetabar and Florentin Wörgötter. 2025. Adaptive Multimodal Graph Reasoning with Foundation Models for Fine-Grained Action Recognition.IEEE Access13 (nov 2025), 201990–202009. doi:10.1109/ACCESS.2025.3637990 , Vol. 1, No. 1, Article . Publication date: April 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.