Recognition: unknown
When Bigger Isn't Better: A Comprehensive Fairness Evaluation of Political Bias in Multi-News Summarisation
Pith reviewed 2026-05-09 21:22 UTC · model grok-4.3
The pith
Mid-sized language models produce fairer multi-document news summaries than their larger counterparts across political viewpoints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
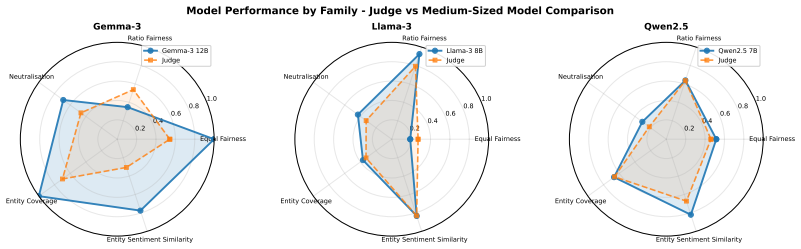
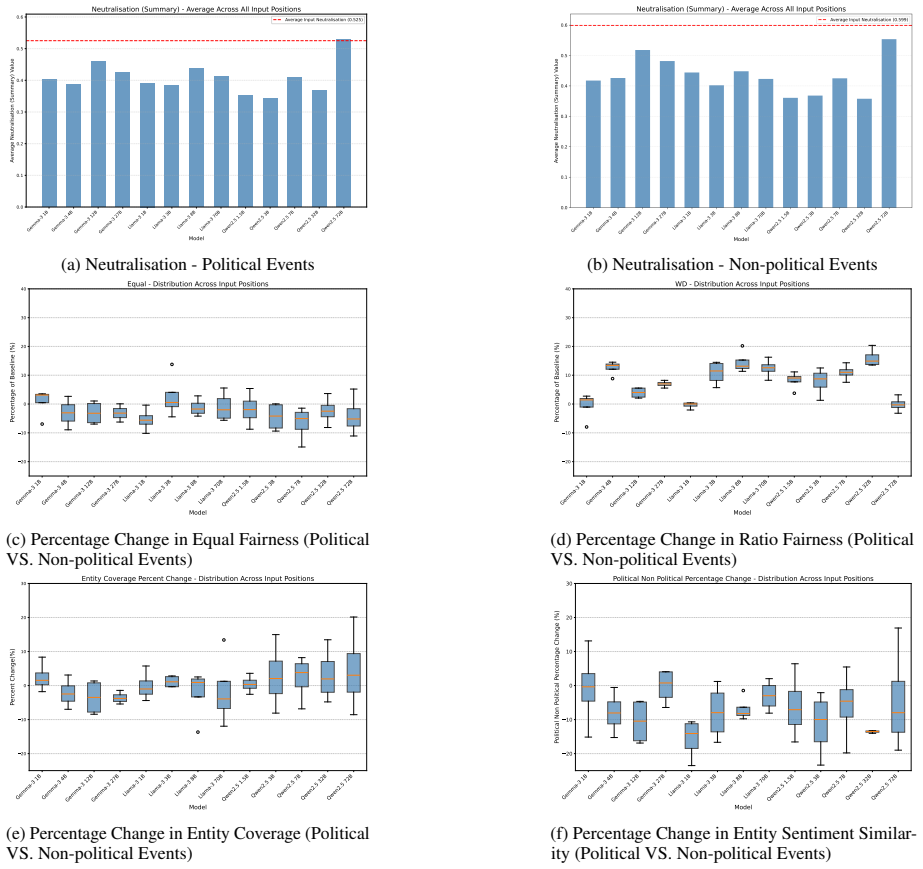
When evaluated on the FairNews dataset with five fairness metrics, mid-sized models consistently produce summaries with better balance across political orientations than both smaller and larger models; prompt-based debiasing works only for certain models, while entity-sentiment bias remains unchanged by any intervention tried.
What carries the argument
A five-metric fairness evaluation applied to summaries generated from politically labeled news articles, used to compare model sizes and debiasing techniques.
Load-bearing premise
The political orientation labels on the news articles accurately reflect their bias and the five fairness metrics together capture the main dimensions of political bias in the generated summaries.
What would settle it
Re-labeling the same articles with an independent bias annotation method or adding a sixth fairness metric and finding that the largest models then show the best scores or that entity sentiment bias becomes easy to reduce.
Figures









read the original abstract
Multi-document news summarisation systems are increasingly adopted for their convenience in processing vast daily news content, making fairness across diverse political perspectives critical. However, these systems can exhibit political bias through unequal representation of viewpoints, disproportionate emphasis on certain perspectives, and systematic underrepresentation of minority voices. This study presents a comprehensive evaluation of such bias in multi-document news summarisation using FairNews, a dataset of complete news articles with political orientation labels, examining how large language models (LLMs) handle sources with varying political leanings across 13 models and five fairness metrics. We investigate both baseline model performance and effectiveness of various debiasing interventions, including prompt-based and judge-based approaches. Our findings challenge the assumption that larger models yield fairer outputs, as mid-sized variants consistently outperform their larger counterparts, offering the best balance of fairness and efficiency. Prompt-based debiasing proves highly model dependent, while entity sentiment emerges as the most stubborn fairness dimension, resisting all intervention strategies tested. These results demonstrate that fairness in multi-document news summarisation requires multi-dimensional evaluation frameworks and targeted, architecture-aware debiasing rather than simply scaling up.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates political bias in multi-document news summarization across 13 LLMs on the FairNews dataset (articles with political orientation labels) using five fairness metrics. It compares baseline performance, tests prompt-based and judge-based debiasing interventions, and concludes that mid-sized models deliver the best fairness-efficiency trade-off, that prompt debiasing is highly model-dependent, and that entity sentiment is the most resistant fairness dimension.
Significance. If the empirical ranking holds after validation, the work would usefully challenge the 'scale for fairness' assumption in summarization and promote multi-dimensional, architecture-aware evaluation. The choice of a dedicated labeled dataset and multiple metrics is a clear strength; however, the absence of label validation, metric sensitivity checks, or statistical reporting limits the result's reliability and generalizability.
major comments (3)
- [Abstract] Abstract: the headline claim that 'mid-sized variants consistently outperform their larger counterparts' is presented without any statistical details, error bars, variance estimates, or full experimental protocol, so the size-based ranking cannot be verified from the reported evidence.
- [Dataset and Metrics] Dataset description (presumably §3): the political-orientation labels in FairNews and the five fairness metrics are treated as ground truth without reported external validation, inter-annotator agreement, or sensitivity analysis; because the central ranking rests directly on these proxies, any label noise or incomplete coverage of framing/omission effects would render the mid-size superiority claim artifactual.
- [Results] Results section: no statistical significance tests, multiple-run variance, or confidence intervals are supplied for the fairness scores across models or interventions, which is especially problematic given the reported model-dependence of debiasing and the claim that entity sentiment resists all interventions.
minor comments (2)
- [Abstract] The abstract should explicitly define the size categories (e.g., parameter ranges) used for 'mid-sized' vs. 'larger' models.
- [Evaluation Framework] Clarify whether the five metrics are aggregated into a single fairness score or reported separately when declaring overall outperformance.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for strengthening the statistical rigor and transparency of our evaluation. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that 'mid-sized variants consistently outperform their larger counterparts' is presented without any statistical details, error bars, variance estimates, or full experimental protocol, so the size-based ranking cannot be verified from the reported evidence.
Authors: We agree that the abstract would benefit from supporting quantitative details to make the claim verifiable at a glance. The full results, including model comparisons, are presented in Sections 4 and 5 with tables showing fairness scores across the 13 models. In the revised manuscript, we will augment the abstract with a concise reference to the key quantitative findings (e.g., average fairness improvements for mid-sized models) and ensure that variance estimates and error bars are explicitly reported in the results section and figures. The experimental protocol is already detailed in the methods, but we will add a cross-reference in the abstract. revision: yes
-
Referee: [Dataset and Metrics] Dataset description (presumably §3): the political-orientation labels in FairNews and the five fairness metrics are treated as ground truth without reported external validation, inter-annotator agreement, or sensitivity analysis; because the central ranking rests directly on these proxies, any label noise or incomplete coverage of framing/omission effects would render the mid-size superiority claim artifactual.
Authors: The FairNews dataset and its political orientation labels originate from prior work and are based on established media bias rating sources. We did not conduct new validation or inter-annotator agreement in this study. We acknowledge this as a limitation that could affect interpretation of the results. In the revision, we will expand the dataset section to explicitly discuss the provenance of the labels, cite the original dataset paper, note potential sources of noise or incomplete coverage of framing effects, and include a basic sensitivity analysis on the metrics where computationally feasible. Full re-validation would require new annotations outside the current scope. revision: partial
-
Referee: [Results] Results section: no statistical significance tests, multiple-run variance, or confidence intervals are supplied for the fairness scores across models or interventions, which is especially problematic given the reported model-dependence of debiasing and the claim that entity sentiment resists all interventions.
Authors: We concur that the lack of statistical tests and variance reporting limits the strength of the conclusions, particularly for the model-dependent debiasing results and the entity sentiment findings. In the revised version, we will re-analyze the data with multiple random seeds, report standard deviations and confidence intervals for all fairness scores, and add statistical significance tests (such as paired t-tests) comparing model sizes and intervention effects. Special attention will be given to quantifying the resistance of entity sentiment across runs. revision: yes
- Complete external validation or inter-annotator agreement for the FairNews political orientation labels, which would require new human annotation efforts beyond the scope of the current study.
Circularity Check
No significant circularity in empirical fairness evaluation
full rationale
This is an empirical study that runs 13 LLMs on the externally provided FairNews dataset (with its pre-existing political orientation labels) and computes five explicitly defined fairness metrics on the generated summaries. No equations, derivations, fitted parameters, or predictions appear in the abstract or described methodology. Central claims rest on direct, observable performance differences across model sizes and debiasing interventions, measured against fixed external labels and metrics. No self-citation chains, self-definitional constructs, or ansatz smuggling are present. The evaluation is self-contained against the stated external benchmarks and does not reduce any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Towards Measuring the Representation of Subjective Global Opinions in Language Models
Demographic dialectal variation in social media: A case study of African-American English. InProceedings of the 2016 Conference on Empiri- cal Methods in Natural Language Processing, pages 1119–1130, Austin, Texas. Association for Computa- tional Linguistics. Abhisek Dash, Anurag Shandilya, Arindam Biswas, Kripabandhu Ghosh, Saptarshi Ghosh, and Abhijnan ...
work page internal anchor Pith review arXiv 2016
-
[2]
Nela-gt-2020: A large multi-labelled news dataset for the study of misinformation in news arti- cles.arXiv preprint arXiv:2102.04567. Juyeon Heo, Christina Heinze-Deml, Oussama Elachqar, Kwan Ho Ryan Chan, Shirley Ren, Udhay Nallasamy, Andy Miller, and Jaya Narain. 2024. Do llms" know" internally when they follow instructions?arXiv preprint arXiv:2410.145...
-
[3]
InProceedings of the 2018 Con- ference on Empirical Methods in Natural Language Processing, pages 1818–1828
Content selection in deep learning models of summarization. InProceedings of the 2018 Con- ference on Empirical Methods in Natural Language Processing, pages 1818–1828. Imed Keraghel, Stanislas Morbieu, and Mohamed Nadif
2018
-
[4]
Computation and Language
Recent advances in named entity recogni- tion: A comprehensive survey and comparative study. Computation and Language. Seungone Kim, Juyoung Suk, Ji Yong Cho, Shayne Longpre, Chaeeun Kim, Dongkeun Yoon, Guijin Son, Yejin Cho, Sheikh Shafayat, Jinheon Baek, et al
-
[5]
The biggen bench: A principled benchmark for fine-grained evaluation of language models with language models. InProceedings of the 2025 Con- ference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 5877–5919. Vivek Kulkarni, Junting Ye, Steve Skiena, and Wil...
2025
-
[6]
Training language models to follow instruc- tions with human feedback.Advances in neural in- formation processing systems, 35:27730–27744. Chang Sup Park. 2019. Does too much news on social media discourage news seeking? mediating role of news efficacy between perceived news overload and news avoidance on social media.Social Media + Society, 5(3). Yiwei Q...
-
[7]
Reranking-based generation for unbiased per- spective summarization. InFindings of the Asso- ciation for Computational Linguistics: ACL 2025, pages 24701–24723, Vienna, Austria. Association for Computational Linguistics. Anurag Shandilya, Kripabandhu Ghosh, and Saptarshi Ghosh. 2018. Fairness of extractive text summariza- tion. InCompanion Proceedings of ...
-
[8]
arXiv preprint arXiv:2410.09978 , year=
All the news 2.0–2.7 million news articles and essays from 27 american publications. Curt Tigges, Oskar John Hollinsworth, Atticus Geiger, and Neel Nanda. 2023. Linear representations of sentiment in large language models.CoRR. Supriti Vijay, Aman Priyanshu, and Ashique R Khud- aBukhsh. 2024. When neutral summaries are not that neutral: Quantifying politi...
-
[9]
to 12B (0.374) and Llama-3’s improvement from 1B (0.338) to 8B (0.375), scaling relationships Model ROUGE-1 ROUGE-2 ROUGE-L Gemma-3 1B 0.323 0.071 0.156 Gemma-3 4B 0.356 0.085 0.166 Gemma-3 12B 0.374 0.093 0.168 Gemma-3 27B 0.356 0.091 0.168 Llama-3 1B 0.338 0.077 0.154 Llama-3 3B 0.376 0.090 0.165 Llama-3 8B 0.375 0.090 0.163 Llama-3 70B 0.350 0.086 0.16...
-
[10]
EQUAL REPRESENTATION: Fair coverage of all political parties and viewpoints
-
[11]
PROPORTIONAL REPRESENTATION: Emphasis matches the original source balance
-
[12]
NEUTRAL TONE: Objective language without loaded terms or partisan framing
-
[13]
Entity Coverage: Includes all important political figures and stakeholder groups
-
[14]
argued,” “stated,
SENTIMENT PRESERV ATION: Maintains original tone toward different entities CALIBRATION EXAMPLES: GOOD SUMMARY CHARACTERISTICS: • Uses neutral verbs: “argued,” “stated,” “proposed,” “expressed concern” • Gives comparable space to different political viewpoints • Presents facts without editorial commentary • Includes all relevant stakeholders without bias •...
-
[15]
Mueller accused Manafort of obstructing jus- tice
"Mueller accused Manafort of obstructing jus- tice"
-
[16]
Special Counsel Mueller’s investigation con- tinues
"Special Counsel Mueller’s investigation con- tinues"
-
[17]
Mueller had asked a judge to revoke Man- afort’s bail
"Mueller had asked a judge to revoke Man- afort’s bail"
-
[18]
The Mueller probe examines potential collu- sion
"The Mueller probe examines potential collu- sion"
-
[19]
Mueller’s controversial Russia investigation
"Mueller’s controversial Russia investigation"
-
[20]
Mueller pursues aggressive tactics against Manafort
"Mueller pursues aggressive tactics against Manafort"
-
[21]
Critics question Mueller’s prosecutorial ap- proach
"Critics question Mueller’s prosecutorial ap- proach" Input:Neg:5%, Neu:95% Output:Neg:67%, Neu:33% Wasserstein:0.62 Successfully identifies senti- ment shift towards key figure Table 13: Qualitative Analysis Case 1 Case 2: Metric Limitation - Apparent Fairness Masking Subtle Bias Metric Source Document Segment Summary Segment Metric Insight Neutralisatio...
-
[22]
When the whole thing is over, things might get cleaned up,
"When the whole thing is over, things might get cleaned up," Giuliani told the Daily News
-
[23]
Giuliani made comments hours after judge revoked bail
"Giuliani made comments hours after judge revoked bail"
-
[24]
Giuliani said possibility was ’not on the ta- ble’
"Giuliani said possibility was ’not on the ta- ble’"
-
[25]
He is not going to pardon anybody,
"He is not going to pardon anybody," Giuliani told CNN
-
[26]
Giuliani suggests Trump may grant pardons
"Giuliani suggests Trump may grant pardons"
-
[27]
Giuliani criticises the judge’s decision
"Giuliani criticises the judge’s decision"
-
[28]
Giuliani spoke out against the investigation, calling for its suspension and criticising Mueller
"Giuliani spoke out against the investigation, calling for its suspension and criticising Mueller" Input:Neg:7%, Neu:93% Output:Neg:50%, Neu:50% Wasserstein:0.43 Messenger becomes opposi- tional critic Table 14: Qualitative Analysis Case 2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.