Recognition: unknown
Outcome Rewards Do Not Guarantee Verifiable or Causally Important Reasoning
Pith reviewed 2026-05-09 21:04 UTC · model grok-4.3
The pith
Reinforcement learning from verifiable rewards improves model accuracy without necessarily making the reasoning chain causally important or sufficient for the answer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
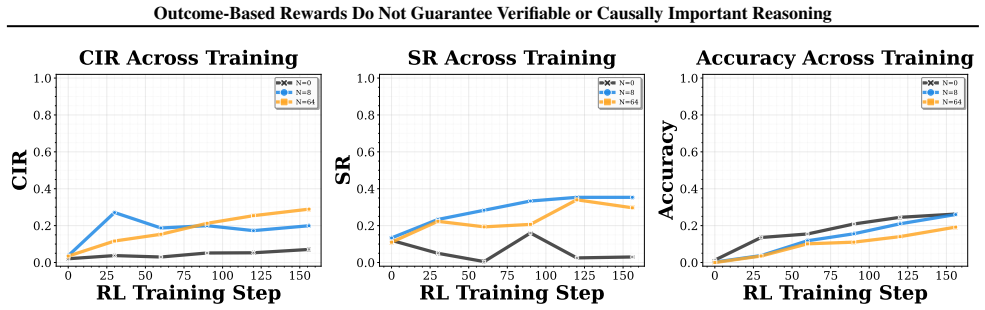
The central finding is that RLVR does not reliably improve the causal importance of reasoning or its sufficiency for verification, despite boosting task accuracy. This holds for the Qwen2.5 series on ReasoningGym tasks. Remedies include a small SFT prefix before RLVR or combining outcome rewards with auxiliary rewards that target the new metrics, achieving both accuracy and better reasoning properties.
What carries the argument
Causal Importance of Reasoning and Sufficiency of Reasoning metrics, which measure the effect of reasoning tokens on the answer and the verifiability of the answer from reasoning alone.
If this is right
- RLVR training may produce high-accuracy models whose reasoning does not drive their outputs.
- Adding a small supervised fine-tuning step before RLVR can increase both the causal importance and sufficiency of reasoning.
- Joint rewards that include terms for causal importance and sufficiency can match pure RLVR accuracy while ensuring reasoning is important and sufficient.
- Post-training procedures need to account for reasoning quality beyond just final answer correctness.
Where Pith is reading between the lines
- If these results generalize, training pipelines should incorporate reasoning-specific rewards to ensure transparent and verifiable chains.
- Applications relying on model explanations for trust or safety may need to verify reasoning importance separately from accuracy.
- These metrics might be adapted to other reasoning formats beyond chain-of-thought to check similar issues.
Load-bearing premise
The assumption that measuring the impact of reasoning steps on the final answer and checking if reasoning alone can lead to the answer captures whether reasoning truly matters, and that this holds across models and tasks.
What would settle it
An experiment where the model's answer changes substantially when the reasoning chain is removed or masked after RLVR training, or where an independent verifier cannot recover the correct answer from the reasoning text alone despite high task accuracy.
Figures














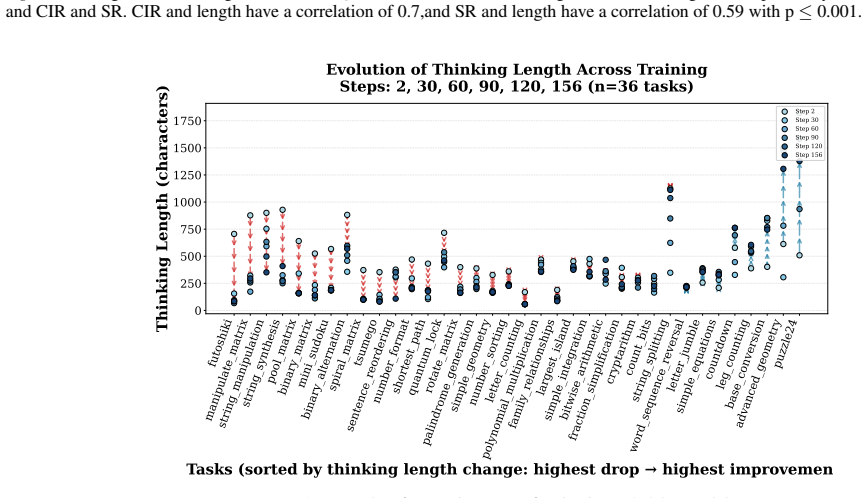


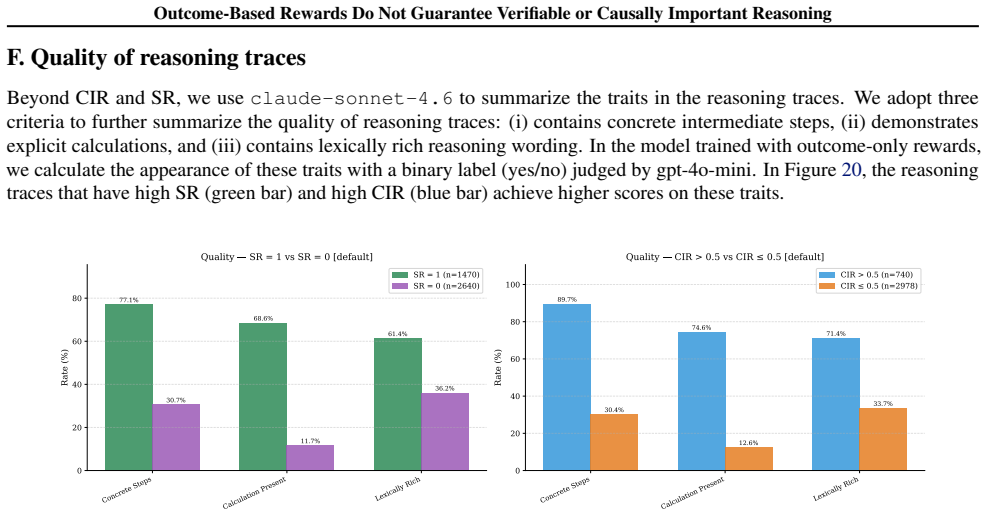
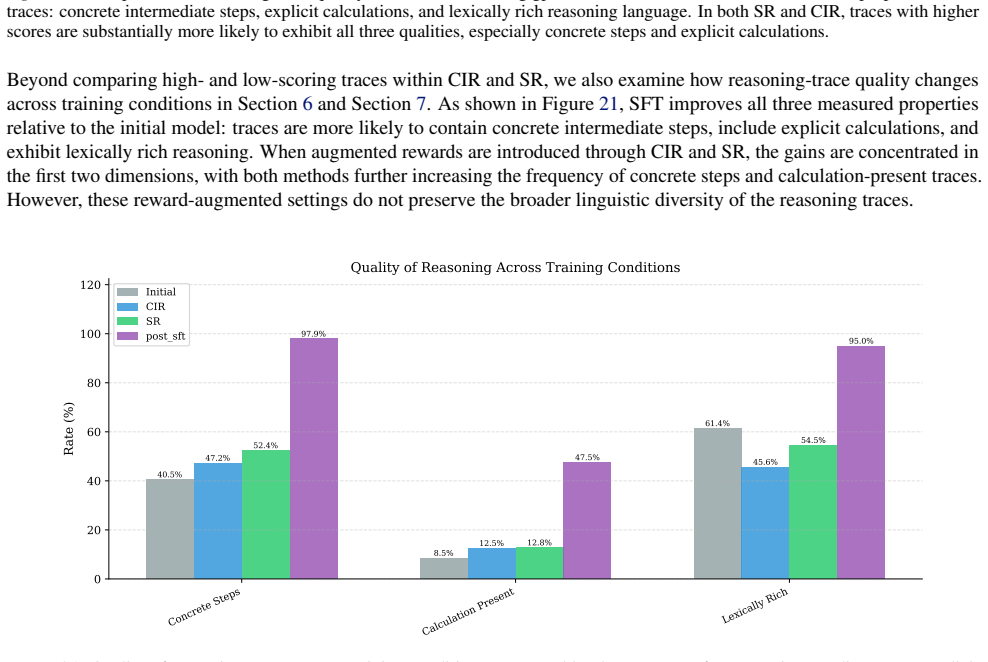

read the original abstract
Reinforcement Learning from Verifiable Rewards (RLVR) on chain-of-thought reasoning has become a standard part of language model post-training recipes. A common assumption is that the reasoning chains trained through RLVR reliably represent how a model gets to its answer. In this paper, we develop two metrics for critically examining this assumption: Causal Importance of Reasoning (CIR), which measures the cumulative effect of reasoning tokens on the final answer, and Sufficiency of Reasoning (SR), which measures whether a verifier can arrive at an unambiguous answer based on the reasoning alone. Through experiments with the Qwen2.5 model series and ReasoningGym tasks, we find that: (1) while RLVR does improve task accuracy, it does not reliably improve CIR or SR, calling the role of reasoning in model performance into question; (2) a small amount of SFT before RLVR can be a remedy for low CIR and SR; and (3) CIR and SR can be improved even without SFT by applying auxiliary CIR/SR rewards on top of the outcome-based reward. This joint reward matches the accuracy of RLVR while also leading to causally important and sufficient reasoning. These results show that RLVR does not always lead models to rely on reasoning in the way that is commonly thought, but this issue can be remedied with simple modifications to the post-training procedure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Causal Importance of Reasoning (CIR) and Sufficiency of Reasoning (SR) metrics to test whether RLVR on chain-of-thought actually causes models to rely on reasoning for answers. Experiments on Qwen2.5 models and ReasoningGym tasks show that RLVR improves accuracy but does not reliably raise CIR or SR; prepending a small amount of SFT or adding auxiliary CIR/SR rewards restores both metrics while preserving accuracy.
Significance. If the metrics are valid, the results challenge the common assumption that RLVR produces causally important reasoning and demonstrate simple, accuracy-preserving fixes. The work is strengthened by consistent patterns across model sizes and tasks plus explicit remedies that match baseline accuracy.
major comments (3)
- [§4] §4 (Methods): The exact procedure for computing CIR (cumulative effect of reasoning tokens on the final answer) is not specified, including token masking strategy, baseline comparison, and whether gradients or counterfactuals are used. This is load-bearing because the central claim that RLVR fails to improve CIR rests on these measurements.
- [§5.2, Table 2] §5.2 and Table 2: The statement that RLVR 'does not reliably improve' CIR/SR lacks reported statistical tests, confidence intervals, or effect sizes across the multiple runs and model sizes. Without these, it is unclear whether the observed flat or declining trends are distinguishable from noise.
- [§3.1] §3.1: The SR metric relies on an external verifier reaching an 'unambiguous answer' from the reasoning alone; the verifier model, prompting, and decision threshold are not detailed, making it impossible to assess whether SR truly measures sufficiency independent of the original outcome reward.
minor comments (2)
- [Figure 1] Figure 1 caption and §5.1: The y-axis scaling and error bars are not described, making visual comparison of CIR/SR deltas across conditions difficult.
- [Related work] Related work: The discussion of prior work on reasoning faithfulness (e.g., citations to chain-of-thought faithfulness studies) could be expanded to clarify how CIR/SR differ from existing perturbation-based or attention-based probes.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We appreciate the recognition that our metrics and findings challenge assumptions about RLVR if valid. We address each major comment point-by-point below, providing clarifications and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§4] §4 (Methods): The exact procedure for computing CIR (cumulative effect of reasoning tokens on the final answer) is not specified, including token masking strategy, baseline comparison, and whether gradients or counterfactuals are used. This is load-bearing because the central claim that RLVR fails to improve CIR rests on these measurements.
Authors: We agree that the CIR procedure requires more explicit detail for reproducibility. In the revised manuscript, we will expand §4 to specify: (1) token masking removes all reasoning tokens while retaining the question prefix and answer suffix; (2) the baseline is the model's direct answer probability on the question alone (ablated reasoning); and (3) CIR is computed via counterfactual forward passes measuring the drop in correct-answer log-probability, without gradients. This ablation-based approach directly quantifies causal importance. revision: yes
-
Referee: [§5.2, Table 2] §5.2 and Table 2: The statement that RLVR 'does not reliably improve' CIR/SR lacks reported statistical tests, confidence intervals, or effect sizes across the multiple runs and model sizes. Without these, it is unclear whether the observed flat or declining trends are distinguishable from noise.
Authors: We acknowledge this point on statistical reporting. Experiments used 3–5 random seeds per condition, with consistent flat/declining trends across Qwen2.5 sizes (1.5B–7B) and ReasoningGym tasks. In revision, we will add per-cell standard deviations to Table 2 and §5.2, plus explicit effect-size notes comparing RLVR deltas to run variance. Formal hypothesis tests were not performed, but the patterns exceed observed noise; we can include p-values if required. revision: partial
-
Referee: [§3.1] §3.1: The SR metric relies on an external verifier reaching an 'unambiguous answer' from the reasoning alone; the verifier model, prompting, and decision threshold are not detailed, making it impossible to assess whether SR truly measures sufficiency independent of the original outcome reward.
Authors: We will clarify the SR details in the revised §3.1. The verifier is the base (pre-RLVR) Qwen2.5 model prompted with: 'Using only the following reasoning, output the final answer. Reasoning: [chain] Answer:'. An unambiguous answer is recorded when the verifier assigns >0.85 probability to the correct token. This uses the original model to ensure independence from the RLVR outcome reward. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces CIR and SR as independent post-hoc metrics to evaluate reasoning chains from RLVR-trained models. These metrics are defined separately from the outcome-based RLVR objective and applied to model generations on ReasoningGym tasks. The central empirical claims (RLVR boosts accuracy without reliably lifting CIR/SR; SFT or auxiliary rewards can fix this) are supported by distinct measurements rather than any reduction to fitted parameters, self-referential definitions, or self-citation chains. No load-bearing step equates a prediction to its input by construction, and the analysis remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reasoning tokens can be isolated and their cumulative causal effect on the final answer can be quantified via the CIR metric
- domain assumption A verifier can be used to test whether reasoning alone suffices for an unambiguous correct answer via the SR metric
invented entities (2)
-
Causal Importance of Reasoning (CIR) metric
no independent evidence
-
Sufficiency of Reasoning (SR) metric
no independent evidence
Forward citations
Cited by 1 Pith paper
-
LLMs Should Not Yet Be Credited with Decision Explanation
LLMs support decision prediction and rationale generation but lack evidence for genuine decision explanation, requiring stricter standards to avoid over-crediting.
Reference graph
Works this paper leans on
-
[1]
Forx≥0, this is the region above the liney=x
-
[2]
Next, consider the inequality y≤ −|x|+ 3
Forx <0, this is the region above the liney=−x. Next, consider the inequality y≤ −|x|+ 3 . Since |x| is always non-negative, −|x| is always non-positive, and thus −|x|+ 3 ranges from -3 to 3. This line touches at x= 0, y= 3 , goes down to x=±3 where y= 0 , and is perpendicular to the x-axis at these points. The boundaries of the region we are interested i...
-
[3]
Therefore, the intersection point is(1.5,1.5)
Intersection ofy=xandy=−x+ 3: x=−x+ 3 =⇒2x= 3 =⇒x= 1.5,soy= 1.5. Therefore, the intersection point is(1.5,1.5)
-
[4]
11111000000
Intersection ofy=−xandy=−x+ 3: −x=−x+ 3 =⇒0 = 3, this is a contradiction, indicating no intersection for this segment. So, the region of intersection is between (1.5,1.5) and the points where y=−x+ 3 intersects y=x at x= 3 and x=−3 . The vertices of the region are(−3,3),(3,3), and(1.5,1.5). The shape formed is a triangle with vertices at (−3,3) , (3,3) , ...
-
[5]
For the pattern starting with ‘1’: - Number of ‘1’s to be swapped to ‘0’s: 5 - Number of ‘0’s to be swapped to ‘1’s: 5 - Total swaps needed = 10
-
[6]
Therefore, the minimum number of swaps required is -1 because both scenarios require the same number of swaps
For the pattern starting with ‘0’: - Number of ‘0’s to be swapped to ‘1’s: 5 - Number of ‘1’s to be swapped to ‘0’s: 5 - Total swaps needed = 10 The minimum number of swaps needed is the minimum of the two scenarios calculated above. Therefore, the minimum number of swaps required is -1 because both scenarios require the same number of swaps. Thus, the an...
-
[7]
- For the cell (1, 2) containing 1, the nearest 0 is at (2, 2)
containing 0, the distance to the nearest 0 is 0 (since it is a 0). - For the cell (1, 2) containing 1, the nearest 0 is at (2, 2). The Manhattan distance is |1−2|+|2−2|= 1 . - For the cell (2, 1) containing 1, the nearest 0 is at (2, 2). The Manhattan distance is |2−2|+|1−2|= 1. The resulting matrix is: 2 1 0 1 For each cell in the given matrix, I need t...
-
[8]
After the identity transformation (no change), the matrix remains the same: 7 5 9 7 8 6
-
[9]
Vertically mirroring the matrix: 7 7 5 8 9 6
-
[10]
Mirroring the matrix along the counter- diagonal: 7 5 9 7 8 6
-
[11]
Mirroring the matrix along the counter- diagonal again: 9 7 7 6 8 5
-
[12]
Mirroring the matrix along the counter- diagonal again: 7 6 9 7 5 8
-
[13]
Setting all elements divisible by 7 to zero: 0 6 9 0 5 8 The final matrix is: 0 6 9 0 5 8 I will perform the operations on the given matrix in order: identity transformation, ver- tically mirror the matrix, mirror the matrix along the counterdiagonal three times, and then set all elements divisible by 7 to zero. The initial matrix is: 7 5 9 7 8 6 After id...
-
[14]
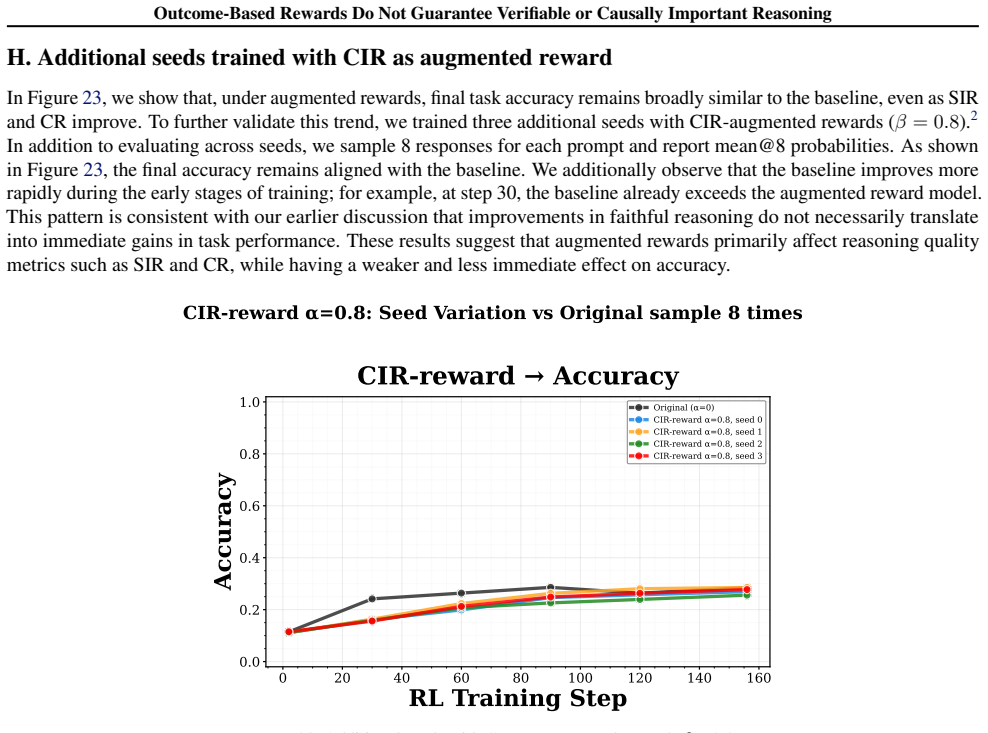
Transpose the matrix (swap rows with columns). 2. Reverse each row of the trans- posed matrix. The transposed matrix is: 6 0 6 6 Now reverse each row: 0 6 6 6 Tsumego Black should play a move that maximizes their capturing potential. Black can capture mor stones by play in row 20, col 1 Black should capture the stone at F5. 29 Outcome-Based Rewards Do Not...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.