Optimal sequential decision-making for error propagation mitigation in digital twins
Pith reviewed 2026-05-08 12:17 UTC · model grok-4.3
The pith
Markov decision processes optimize interventions to mitigate error propagation in digital twins while balancing fidelity and maintenance costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
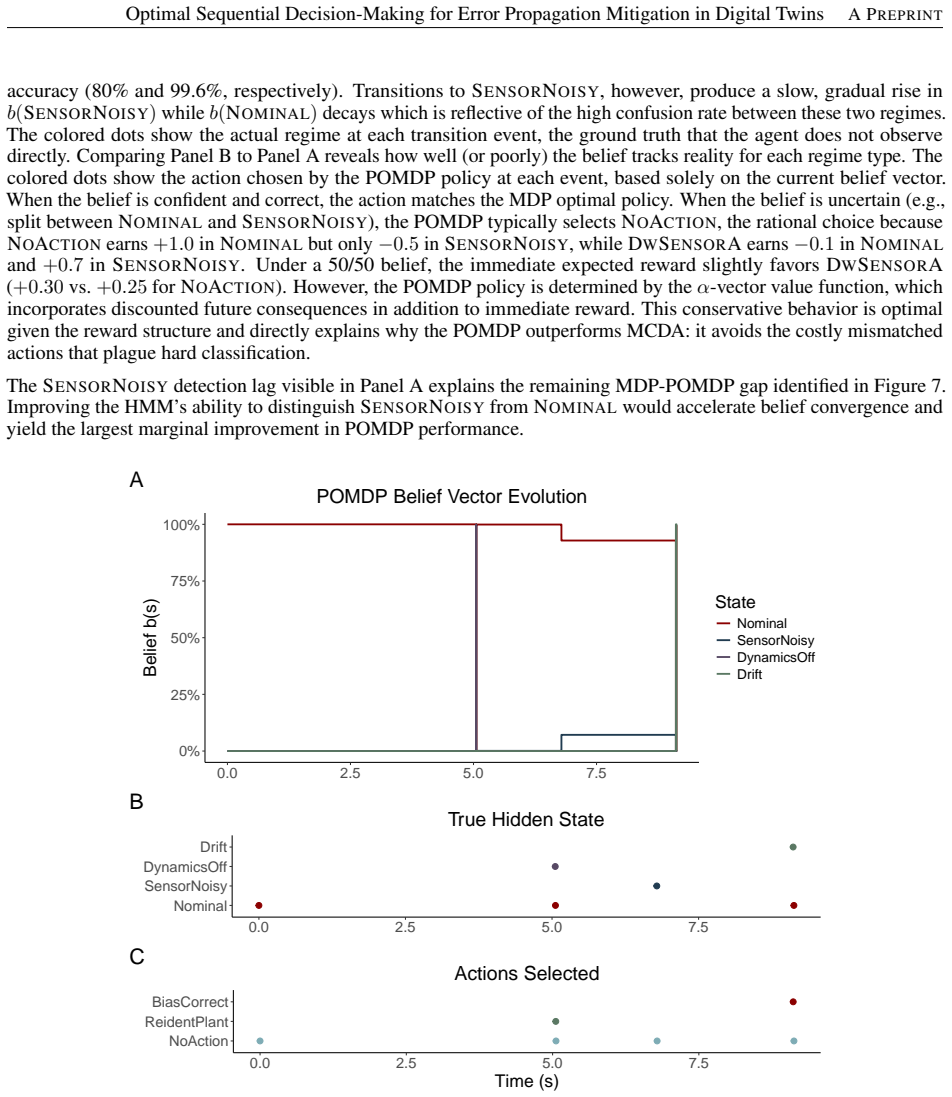
The central claim is that an MDP whose states are HMM-inferred error regimes, actions are corrective interventions, and reward balances fidelity against maintenance cost produces the highest cumulative reward and fraction of time in nominal operation; a POMDP extension that tracks belief states under imperfect observations recovers approximately 95 percent of MDP performance, and the resulting performance gap quantifies the value of improved regime classification accuracy.
What carries the argument
A Markov Decision Process (MDP) whose states are latent error regimes inferred from HMM residuals, actions are interventions, transitions are taken from HMM parameters, and reward encodes the fidelity-cost tradeoff; extended to a POMDP whose observation model is the HMM confusion matrix and whose belief state is updated by Bayesian filtering.
If this is right
- The MDP policy achieves the highest cumulative reward and fraction of time in nominal operation.
- The POMDP recovers approximately 95 percent of MDP performance under realistic observation noise.
- Sensitivity analyses confirm robustness across observation quality, repair probability, and discount factor.
- Gaps between policies in the hierarchy are statistically significant at p less than 0.001.
- The MDP-POMDP performance gap supplies a quantitative criterion for deciding how much to invest in improved classification accuracy.
Where Pith is reading between the lines
- Closing the observation-noise gap through better sensors or classifiers could make POMDP performance nearly indistinguishable from MDP performance.
- The same state-action-reward structure could be applied to other modular systems that exhibit latent error regimes, such as manufacturing processes or networked sensor arrays.
- When an explicit transition model is unavailable, model-free methods such as Q-learning can still produce usable policies, although they may require more samples to match dynamic-programming performance.
Load-bearing premise
The regimes inferred by the companion HMM study accurately represent the true latent states of the digital twin and the transition matrix extracted from HMM parameters correctly models the underlying error propagation dynamics.
What would settle it
If Gillespie simulations or real deployments using transition matrices that deviate from the HMM-derived matrix show that the MDP policy no longer achieves the highest reward or that the POMDP no longer recovers 95 percent of MDP performance, the modeling approach would be falsified.
Figures








read the original abstract
Here, we explore the problem of error propagation mitigation in modular digital twins as a sequential decision process. Building on a companion study that used a Hidden Markov Model (HMM) to infer latent error regimes from surrogate-physics residuals, we develop a Markov Decision Process (MDP) in which the inferred regimes serve as states, corrective interventions serve as actions, and a scalar reward that takes into consideration the cost-benefit tradeoff between system fidelity and maintenance expense. The baseline transition matrix is extracted from the HMM-learned parameters. We then extend the formulation to a Partially Observable MDP (POMDP) that accounts for the imperfect nature of regime classification by maintaining a belief distribution updated via Bayesian filtering, with the HMM confusion matrix serving as the observation model. Both formulations are solved via dynamic programming and validated through Gillespie stochastic simulation. We then benchmark two model-free reinforcement learning algorithms, Q-learning and REINFORCE, to assess whether effective policies can be learned without explicit model knowledge. A systematic comparison of different intervention policies demonstrates that the MDP policy achieves the highest cumulative reward and fraction of time in nominal operation, while the POMDP recovers approximately 95\% of MDP performance under realistic observation noise. Sensitivity analyses across observation quality, repair probability, and discount factor confirm the robustness of these conclusions, and the major gaps in the policy hierarchy are statistically significant at $p < 0.001$. The gap between MDP and POMDP performance quantifies the value of information providing a principled criterion for investing in improved classification accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames error propagation mitigation in modular digital twins as a sequential decision process. It defines an MDP whose states are latent error regimes inferred by a companion HMM, actions are corrective interventions, and the reward trades off system fidelity against maintenance cost; the transition matrix is taken from the HMM parameters. The formulation is extended to a POMDP that maintains a belief state updated by Bayesian filtering with the HMM confusion matrix as the observation model. Both are solved by dynamic programming, validated via Gillespie stochastic simulation, and compared against Q-learning and REINFORCE. The central empirical result is that the MDP policy yields the highest cumulative reward and time in nominal operation, while the POMDP recovers approximately 95% of that performance under realistic observation noise; sensitivity analyses and p<0.001 significance tests are reported for the policy hierarchy.
Significance. If the reported ordering and recovery percentage hold under independent validation, the work supplies a quantitative, decision-theoretic criterion for choosing between perfect-state and noisy-observation policies in digital-twin maintenance. The combination of exact dynamic-programming solutions, Gillespie validation, RL baselines, and sensitivity sweeps across observation quality, repair probability, and discount factor constitutes a reproducible benchmark that future studies on error-mitigation policies can adopt. The explicit quantification of the value of information also offers a practical metric for deciding when to invest in improved regime classification.
major comments (2)
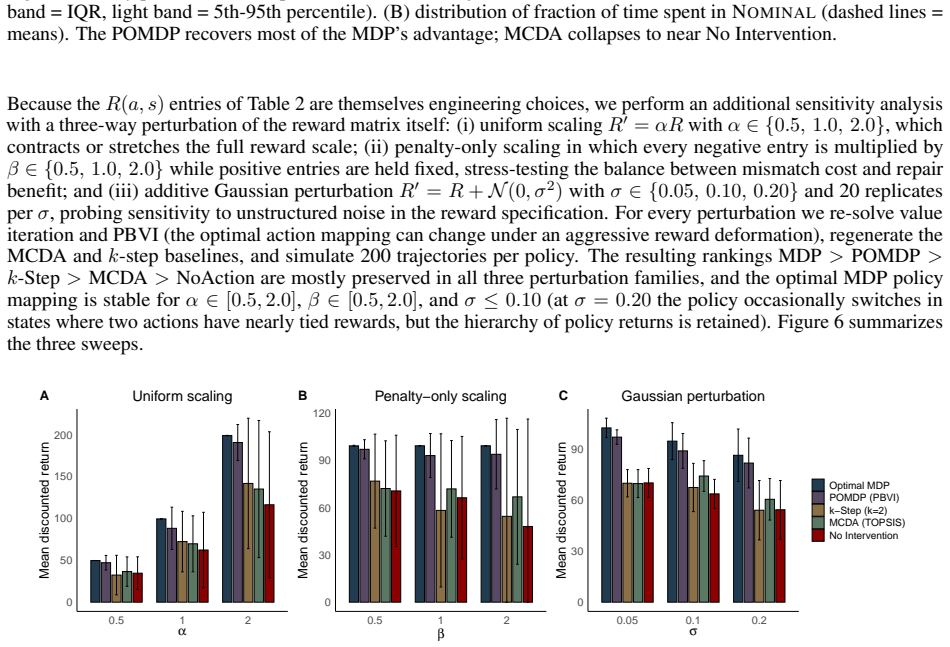
- [§2] §2 (Model construction) and abstract: the transition matrix and observation model are taken directly from the companion HMM study. Because the reported MDP/POMDP performance is therefore conditioned on the accuracy of those fitted parameters, the manuscript must include either (a) a sensitivity analysis that perturbs the HMM-derived quantities within their estimation uncertainty and re-solves the policies, or (b) an explicit statement that the 95% recovery figure is conditional on the companion model being correct.
- [Results] Results section (policy comparison and statistical tests): the claim that major policy gaps are significant at p<0.001 is load-bearing for the hierarchy conclusion, yet the manuscript does not specify the exact test (paired t-test, Wilcoxon, bootstrap, etc.), the number of independent Gillespie trajectories, or whether multiple-comparison correction was applied. Without these details the statistical support for the 95% recovery statement cannot be assessed.
minor comments (3)
- [Methods] The scalar reward weight that balances fidelity and maintenance cost is listed as a free parameter; an explicit equation (e.g., R = fidelity_term - λ·cost_term) and the range of λ explored in the sensitivity analysis should be stated in the methods.
- [POMDP formulation] Notation for the POMDP belief update (Bayesian filter) is described in prose; adding the standard recursive equation for b'(s') would improve clarity and allow direct comparison with other POMDP literature.
- [Figures] Figure captions for the Gillespie validation trajectories should report the number of Monte-Carlo runs and whether shaded regions represent standard error or inter-quartile range.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important points for improving clarity and robustness. We address each major comment below and outline the revisions we will incorporate.
read point-by-point responses
-
Referee: [§2] §2 (Model construction) and abstract: the transition matrix and observation model are taken directly from the companion HMM study. Because the reported MDP/POMDP performance is therefore conditioned on the accuracy of those fitted parameters, the manuscript must include either (a) a sensitivity analysis that perturbs the HMM-derived quantities within their estimation uncertainty and re-solves the policies, or (b) an explicit statement that the 95% recovery figure is conditional on the companion model being correct.
Authors: We agree that the reported performance metrics are conditioned on the fitted HMM parameters. In the revised manuscript we will add an explicit statement in both the abstract and §2 clarifying that the 95% recovery figure is conditional on the companion HMM model being correct. In addition, we will include a new sensitivity analysis in the Results section that perturbs the transition matrix and observation model entries within the estimation uncertainty intervals obtained from the HMM fitting procedure, re-solves the MDP and POMDP policies via dynamic programming, and reports the resulting variation in cumulative reward and fraction of time in the nominal regime. This will directly quantify robustness to HMM parameter uncertainty. revision: yes
-
Referee: [Results] Results section (policy comparison and statistical tests): the claim that major policy gaps are significant at p<0.001 is load-bearing for the hierarchy conclusion, yet the manuscript does not specify the exact test (paired t-test, Wilcoxon, bootstrap, etc.), the number of independent Gillespie trajectories, or whether multiple-comparison correction was applied. Without these details the statistical support for the 95% recovery statement cannot be assessed.
Authors: We acknowledge that the description of the statistical tests was incomplete. In the revised Results section we will explicitly state that the reported p<0.001 values were obtained from paired t-tests on per-trajectory cumulative rewards across 1000 independent Gillespie simulations per policy pair, with Bonferroni correction applied for the three primary pairwise comparisons. We will also report the exact number of trajectories, degrees of freedom, and the full set of corrected p-values to allow readers to assess the statistical support for the policy hierarchy and the 95% recovery claim. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper takes states, transition matrix, and observation model as inputs extracted from a companion HMM study, then formulates standard MDP and POMDP problems, solves them via dynamic programming, validates with Gillespie simulation, and benchmarks Q-learning and REINFORCE. The central results (MDP highest cumulative reward, POMDP recovering ~95% performance, statistical significance of gaps) are computed outcomes of policy optimization and simulation on the given model, not reductions of those outputs back to the input parameters by construction. No self-definitional step, fitted input renamed as prediction, or load-bearing self-citation chain exists in the derivation; the model parameters serve as an external benchmark for evaluating policy performance, which remains independently verifiable.
Axiom & Free-Parameter Ledger
free parameters (2)
- reward scalar balancing fidelity and maintenance cost
- discount factor
axioms (2)
- domain assumption Latent error regimes obey a Markov process whose transition probabilities can be learned from surrogate-physics residuals.
- domain assumption The HMM confusion matrix supplies an accurate observation model for Bayesian belief updates.
Reference graph
Works this paper leans on
-
[1]
Maulshree Singh, Evert Fuenmayor, Eoin P Hinchy, Yuansong Qiao, Niall Murray, and Declan Devine. Digital twin: Origin to future.Applied System Innovation, 4(2):36, 2021. doi: 10.3390/asi4020036
-
[2]
Angira Sharma, Edward Kosasih, Jie Zhang, Alexandra Brintrup, and Anisoara Calinescu. Digital twins: State of the art theory and practice, challenges, and open research questions.Journal of Industrial Information Integration, 30:100383, 2022
work page 2022
-
[3]
Christian Agrell, Kristina Rognlien Dahl, and Andreas Hafver. Optimal sequential decision making with probabilistic digital twins: Theoretical foundations.SN Applied Sciences, 5(4):114, 2023
work page 2023
-
[4]
Hidden Markov inference framework for error propagation mitigation in modular digital twins
Annice Najafi and Shokoufeh Mirzaei. Hidden Markov inference framework for error propagation mitigation in modular digital twins. engrXiv preprint, February 2026. doi: 10.31224/6423
-
[5]
Balázs Palotai, Gábor Kis, János Abonyi, and Ágnes Bárkányi. Surrogate-based flowsheet model maintenance for digital twins.Digital Chemical Engineering, 15:100228, 2025
work page 2025
-
[6]
Aarya Sheetal Desai, N Navaneeth, Sondipon Adhikari, and Souvik Chakraborty. Enhanced multi-fidelity modeling for digital twin and uncertainty quantification.Probabilistic Engineering Mechanics, 74:103525, 2023
work page 2023
-
[7]
Prentice Hall, 2nd edition, 1999
Lennart Ljung.System Identification: Theory for the User. Prentice Hall, 2nd edition, 1999. ISBN 0-13-656695-2
work page 1999
-
[8]
Linyu Lin, Jack Cavaluzzi, Daniel Mikkelson, and Nicholas Cittadino. Explainable discrepancy checker and diagnosis for digital twin-based supervisory control system.Annals of Nuclear Energy, 228:112018, 2026
work page 2026
-
[9]
Angkush Kumar Ghosh, AMM Sharif Ullah, and Akihiko Kubo. Hidden markov model-based digital twin construction for futuristic manufacturing systems.Ai Edam, 33(3):317–331, 2019
work page 2019
-
[10]
1981.Multiple Attribute Decision Making: Methods and Applications
Ching-Lai Hwang and Kwangsun Yoon.Multiple Attribute Decision Making: Methods and Applications—A State-of-the-Art Survey, volume 186 ofLecture Notes in Economics and Mathematical Systems. Springer, 1981. doi: 10.1007/978-3-642-48318-9
-
[11]
Annice Najafi and Shokoufeh Mirzaei. Rmcda: The comprehensive r library for applying multi-criteria decision analysis methods.Software Impacts, 24:100762, 2025. 24 Optimal Sequential Decision-Making for Error Propagation Mitigation in Digital TwinsA PREPRINT
work page 2025
-
[12]
Martin L Puterman.Markov decision processes: discrete stochastic dynamic programming. John Wiley & Sons, 2014
work page 2014
-
[13]
Leslie Pack Kaelbling, Michael L. Littman, and Anthony R. Cassandra. Planning and acting in partially observable stochastic domains.Artificial Intelligence, 101(1–2):99–134, 1998. doi: 10.1016/S0004-3702(98)00023-X
-
[14]
Richard D. Smallwood and Edward J. Sondik. The optimal control of partially observable Markov processes over a finite horizon.Operations Research, 21(5):1071–1088, 1973. doi: 10.1287/opre.21.5.1071
-
[15]
Planning structural inspection and maintenance policies via dynamic programming and markov processes
Konstantinos G Papakonstantinou and Masanobu Shinozuka. Planning structural inspection and maintenance policies via dynamic programming and markov processes. part i: Theory.Reliability Engineering & System Safety, 130:202–213, 2014
work page 2014
-
[16]
Planning structural inspection and maintenance policies via dynamic programming and markov processes
Konstantinos G Papakonstantinou and Masanobu Shinozuka. Planning structural inspection and maintenance policies via dynamic programming and markov processes. part ii: Pomdp implementation.Reliability Engineering & System Safety, 130:214–224, 2014
work page 2014
-
[17]
Giacomo Arcieri, Cyprien Hoelzl, Oliver Schwery, Daniel Straub, Konstantinos G Papakonstantinou, and Eleni Chatzi. Bridging pomdps and bayesian decision making for robust maintenance planning under model uncertainty: An application to railway systems.Reliability Engineering & System Safety, 239:109496, 2023
work page 2023
-
[18]
Stochastic framework for analyzing error propagation in digital twins: A two-link robotic arm case
Annice Najafi, Shokoufeh Mirzaei, and Zahra Sotoudeh. Stochastic framework for analyzing error propagation in digital twins: A two-link robotic arm case. InASME International Mechanical Engineering Congress and Exposition, volume 89343, page V003T06A024. American Society of Mechanical Engineers, 2025
work page 2025
-
[19]
Princeton University Press, 1957
Richard Bellman.Dynamic Programming. Princeton University Press, 1957
work page 1957
-
[20]
Daniel T. Gillespie. Exact stochastic simulation of coupled chemical reactions.The Journal of Physical Chemistry, 81(25):2340–2361, 1977. doi: 10.1021/j100540a008
-
[21]
Steven J. Bradtke and Michael O. Duff. Reinforcement learning methods for continuous-time Markov decision problems.Advances in Neural Information Processing Systems, 7:393–400, 1995
work page 1995
-
[22]
Point-based value iteration: An anytime algorithm for POMDPs
Joelle Pineau, Geoffrey Gordon, and Sebastian Thrun. Point-based value iteration: An anytime algorithm for POMDPs. InProceedings of the International Joint Conference on Artificial Intelligence (IJCAI), pages 1025–1030, 2003
work page 2003
-
[23]
Christopher J. C. H. Watkins and Peter Dayan. Q-learning.Machine Learning, 8(3–4):279–292, 1992. doi: 10.1007/BF00992698
-
[24]
Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 8(3–4):229–256, 1992. doi: 10.1007/BF00992696
-
[25]
depmixS4: An R package for hidden Markov models.Journal of Statistical Software, 36(7):1–21, 2010
Ingmar Visser and Maarten Speekenbrink. depmixS4: An R package for hidden Markov models.Journal of Statistical Software, 36(7):1–21, 2010. doi: 10.18637/jss.v036.i07
-
[26]
Harold W. Kuhn. The Hungarian method for the assignment problem.Naval Research Logistics Quarterly, 2 (1–2):83–97, 1955. doi: 10.1002/nav.3800020109
-
[27]
Norman Cliff. Dominance statistics: Ordinal analyses to answer ordinal questions.Psychological Bulletin, 114(3): 494–509, 1993. doi: 10.1037/0033-2909.114.3.494
-
[28]
Kromrey, Jesse Coraggio, and Jeff Skowronek
Jeanine Romano, Jeffrey D. Kromrey, Jesse Coraggio, and Jeff Skowronek. Appropriate statistics for ordinal level data: Should we really be using t-test and Cohen’s d for evaluating group differences on the NSSE and other surveys. InAnnual Meeting of the Florida Association of Institutional Research, pages 1–33, 2006. 25
work page 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.