Recognition: 1 theorem link
· Lean TheoremRADIANT-LLM: an Agentic Retrieval Augmented Generation Framework for Reliable Decision Support in Safety-Critical Nuclear Engineering
Pith reviewed 2026-05-15 17:26 UTC · model grok-4.3
The pith
A local multi-modal RAG framework with provenance tracking delivers traceable, low-hallucination answers for nuclear safety decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
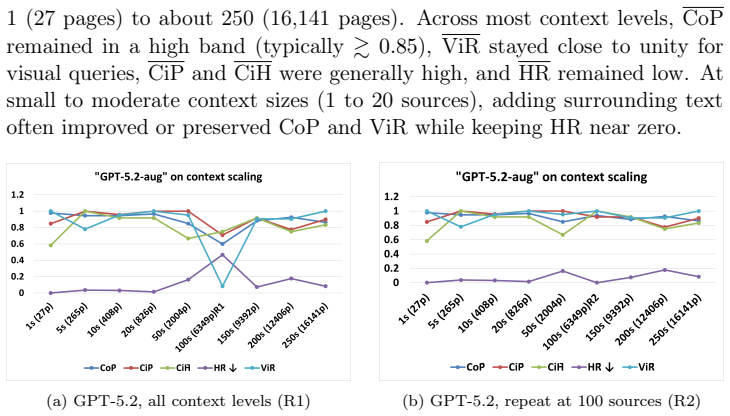
The central claim is that a locally controlled, multi-modal RAG framework with domain-specific retrieval and provenance enforcement is necessary to achieve the factual accuracy, transparency, and auditability that nuclear engineering workflows demand. Evaluations on expert-curated benchmarks show context precision and visual recall staying in the 85-98 percent band across knowledge base sizes, with hallucination rates substantially lower than those seen in general-purpose LLM deployments.
What carries the argument
RADIANT-LLM, the agentic multi-modal RAG framework that pairs page- and figure-level retrieval from a metadata-rich knowledge base with tool-coordinating agents and citation-backed provenance tracking.
If this is right
- Responses include explicit citations and provenance links that support audit trails required in nuclear safety analysis.
- Hallucination rates remain low even as the size of the domain knowledge base changes.
- Human-in-the-loop validation can be inserted without breaking the retrieval pipeline.
- The same architecture reduces citation errors compared with commercial LLM platforms on identical nuclear queries.
Where Pith is reading between the lines
- The local-first design could help regulated industries meet data-sovereignty rules that prohibit sending sensitive documents to external services.
- Extending the multi-modal retrieval to include engineering drawings and simulation outputs would address common pain points in nuclear design reviews.
- The agentic layer could be adapted to other high-stakes fields such as aerospace certification or clinical trial documentation where traceable sources are mandatory.
Load-bearing premise
Performance on expert-curated benchmarks from Used Nuclear Fuel Storage Facility design guidance with the chosen metrics is enough to show reliability in real nuclear workflows.
What would settle it
Run the same queries on a live nuclear facility design review or incident analysis and measure whether expert reviewers find factual errors or missing citations at rates comparable to the benchmark results.
Figures









read the original abstract
Reliable decision support in nuclear engineering requires traceable, domain-grounded knowledge retrieval, yet safety and risk analysis workflows remain hampered by fragmented documentation and hallucination when use pre-trained large language model (LLM) in specialized nuclear domains. To address these challenges, this paper presents RADIANT-LLM (Retrival-Augumented, Domain-Intelligent Agent for Nuclear Technologies using LLM), a multi-modal retrieval-augmented generation (RAG) framework designed for nuclear safety, security, and safeguards applications. The framework uses a local-first, model-agnostic architecture that pairs a multi-modal document ingestion pipeline with a structured, metadata-rich knowledge base, supporting page- and figure-level retrieval from technical documents. An agentic layer coordinates domain-specific tools, enforces citation-backed responses with provenance tracking, and supports human-in-the-loop validation to reduce hallucination risks. To rigorously evaluate this framework, we develop and apply a suite of domain-aware metrics, including Context Precision (CoP), Hallucination Rate (HR), and Visual Recall (ViR), to expert-curated benchmarks derived from Used Nuclear Fuel Storage Facility design guidance. Across varying knowledge base sizes, CoP and ViR remain within an 85--98\% band, and hallucination rates are substantially lower than those observed in general-purpose deployments. When the same queries are posed to commercial LLM platforms without the RAG layer, hallucinations and citation errors increase markedly. These results indicate that a locally controlled, multi-modal RAG framework with domain-specific retrieval and provenance enforcement is necessary to achieve the factual accuracy, transparency, and auditability that nuclear engineering workflows demand.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RADIANT-LLM, a multi-modal, agentic retrieval-augmented generation (RAG) framework tailored for safety-critical nuclear engineering applications. It features a local-first architecture with multi-modal document ingestion, metadata-rich knowledge base for page- and figure-level retrieval, an agentic layer for domain-specific tools, citation enforcement, and provenance tracking. Evaluation on expert-curated benchmarks from Used Nuclear Fuel Storage Facility design guidance uses custom metrics Context Precision (CoP), Hallucination Rate (HR), and Visual Recall (ViR), showing 85-98% performance bands and lower hallucination compared to commercial LLMs without RAG, leading to the claim that such a framework is necessary for factual accuracy and auditability in nuclear workflows.
Significance. If the evaluation generalizes, the work could supply a concrete template for traceable, low-hallucination LLM use in regulated domains where provenance and multi-modal retrieval matter. The local-first, model-agnostic design with human-in-the-loop elements addresses practical auditability needs that generic LLM deployments often ignore.
major comments (2)
- Abstract: the central claim that a locally controlled multi-modal RAG framework 'is necessary' rests on comparisons solely to commercial LLMs without any RAG layer; no ablation studies, comparisons to simpler vector RAG, fine-tuned domain models, or alternative provenance mechanisms are reported, so necessity is not established.
- Abstract: the metrics Context Precision (CoP), Hallucination Rate (HR), and Visual Recall (ViR) are named but never defined, and no formulas, statistical tests, baseline details, or raw data are supplied, preventing assessment of the reported 85--98% bands or the claimed reduction in hallucination.
minor comments (2)
- Abstract: typographical and grammatical errors appear, including 'Retrival-Augumented' (should read 'Retrieval-Augmented') and 'when use pre-trained' (should read 'when using pre-trained').
- Abstract: the phrase 'across varying knowledge base sizes' is used without stating the actual sizes tested or showing how CoP/HR/ViR change with size.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: Abstract: the central claim that a locally controlled multi-modal RAG framework 'is necessary' rests on comparisons solely to commercial LLMs without any RAG layer; no ablation studies, comparisons to simpler vector RAG, fine-tuned domain models, or alternative provenance mechanisms are reported, so necessity is not established.
Authors: We agree that the wording 'is necessary' overstates the conclusions given the limited scope of comparisons (general LLMs without RAG). Our evaluation demonstrates clear reductions in hallucination and gains in provenance for the proposed framework, but we did not include ablations against simpler RAG baselines or fine-tuned models. We will revise the abstract to replace the necessity claim with language indicating that the framework 'provides substantial improvements in factual accuracy, transparency, and auditability compared to general-purpose LLMs'. We will also add a limitations paragraph in the discussion section acknowledging the absence of these additional comparisons and identifying them as future work. No new experiments are feasible within the current revision timeline. revision: partial
-
Referee: Abstract: the metrics Context Precision (CoP), Hallucination Rate (HR), and Visual Recall (ViR) are named but never defined, and no formulas, statistical tests, baseline details, or raw data are supplied, preventing assessment of the reported 85--98% bands or the claimed reduction in hallucination.
Authors: The metrics are defined with formulas and computation details in Section 3.2 (Evaluation Metrics) of the full manuscript, along with baseline descriptions. To address the concern, we will revise the abstract to include brief inline definitions for CoP, HR, and ViR and add a cross-reference to Section 3.2. We will also insert a summary table in the results section providing baseline details, statistical test summaries (e.g., paired t-tests where applicable), and aggregate performance bands. Raw evaluation data and code will be released in a public repository upon acceptance to enable full reproducibility. revision: yes
Circularity Check
No significant circularity in framework proposal or benchmark evaluation
full rationale
The paper introduces RADIANT-LLM as a multi-modal agentic RAG framework and evaluates it empirically on expert-curated benchmarks from Used Nuclear Fuel Storage Facility design guidance using independently defined metrics (Context Precision, Hallucination Rate, Visual Recall). No equations, fitted parameters, or self-referential quantities appear in the derivation chain. The necessity claim rests on comparative results against commercial LLMs without RAG, which is an external benchmark comparison rather than a reduction to the framework's own inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The derivation is therefore self-contained against the provided evaluation data.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean; IndisputableMonolith/Foundation/AbsoluteFloorClosure.lean; IndisputableMonolith/Foundation/AlexanderDuality.leanreality_from_one_distinction; washburn_uniqueness_aczel; Jcost_pos_of_ne_one unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RADIANT-LLM ... multi-modal retrieval-augmented generation (RAG) framework ... agentic layer coordinates domain-specific tools, enforces citation-backed responses with provenance tracking ... metrics ... Context Precision (CoP), Hallucination Rate (HR), and Visual Recall (ViR)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
X. Xiao, B. Qi, Z. Yin, J. Tong, J. Sun, Z. Sui, J. Liang, J. Zhao, H. Wang, Autograph: An intelligent knowledge-graph agent for proce- dure automation and dynamic human reliability support in high-risk industries, Reliability Engineering & System Safety 270 (2026) 112123
work page 2026
-
[2]
X. Li, F. I. Romli, S. A. M. Ali, A. Zhahir, J. Tang, A deep learning framework for aviation risk classification and high-order coupled risk modeling, Reliability Engineering & System Safety 271 (2026) 112277
work page 2026
- [3]
- [4]
-
[5]
W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong, et al., A survey of large language models, arXiv preprint arXiv:2303.18223 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Y. Liu, D. Wang, X. Sun, Y. Liu, N. Dinh, R. Hu, Uncertainty quan- tification for multiphase-cfd simulations of bubbly flows: a machine learning-based bayesian approach supported by high-resolution experi- ments, Reliability Engineering & System Safety 212 (2021) 107636. 38
work page 2021
-
[7]
Z. Abulawi, R. Hu, P. Balaprakash, Y. Liu, Bayesian optimized deep en- semble for uncertainty quantification of deep neural networks: a system safety case study on sodium fast reactor thermal stratification modeling, Reliability Engineering & System Safety 264 (2025) 111353
work page 2025
-
[8]
D. Lim, Z. N. Ndum, C. Young, Y. Hassan, Y. Liu, An ai-driven thermal-fluid testbed for advanced small modular reactors: Integration of digital twin and large language models, AI Thermal Fluids 4 (2025) 100023
work page 2025
-
[9]
N. Abouammoh, K. Alhasan, F. Aljamaan, R. Raina, K. H. Malki, I. Altamimi, R. Muaygil, H. Wahabi, A. Jamal, A. Alhaboob, et al., Perceptions and earliest experiences of medical students and faculty with chatgpt in medical education: qualitative study, JMIR Medical Education 11 (2025) e63400
work page 2025
-
[10]
B. Koo, K. Noguchi, F. Watanabe, K. Kubo, T. Shibutani, Advanced nuclear technologies in modern energy systems: A comparative risk as- sessment in japan, Energy Strategy Reviews 57 (2025) 101632
work page 2025
-
[11]
F. M. Badwan, S. F. Demuth, Application of framework for integrating safety, security and safeguards (3ss) into the design of used nuclear fuel storage facility, Tech. rep., Los Alamos National Laboratory (LANL), Los Alamos, NM (United States) (2015)
work page 2015
-
[12]
W. F. Godoy, P. F. Peterson, S. E. Hahn, J. Hetrick, Workflows us- ing mantid, in: Driving Scientific and Engineering Discoveries Through the Convergence of HPC, Big Data and AI: 17th Smoky Mountains Computational Sciences and Engineering Conference, SMC 2020, Oak Ridge, TN, USA, August 26-28, 2020, Revised Selected Papers, Vol. 1315, Springer Nature, 202...
work page 2020
-
[13]
P.J.Turinsky, D.B.Kothe, Modelingandsimulationchallengespursued by the consortium for advanced simulation of light water reactors (casl), Journal of Computational Physics 313 (2016) 367–376
work page 2016
-
[14]
J. A. Turner, K. Clarno, M. Sieger, R. Bartlett, B. Collins, R. Pawlowski, R. Schmidt, R. Summers, The virtual environment for reactor applications (vera): design and architecture, Journal of Compu- tational Physics 326 (2016) 544–568
work page 2016
- [15]
-
[16]
S. Peereboom, I. Schwabe, B. Kleinberg, Cognitive phantoms in large language models through the lens of latent variables, Computers in Hu- man Behavior: Artificial Humans (2025) 100161
work page 2025
-
[17]
Y. Annepaka, P. Pakray, Large language models: a survey of their de- velopment, capabilities, and applications, Knowledge and Information Systems 67 (2025) 2967–3022
work page 2025
- [18]
- [19]
- [20]
-
[21]
N. A. Smuha, From a ‘race to ai’to a ‘race to ai regulation’: regulatory competition for artificial intelligence, Law, Innovation and Technology 13 (2021) 57–84
work page 2021
-
[22]
U. A. S. Institute, Managing misuse risk for dual-use foundation mod- els, Initial public draft, National Institute of Standards and Technology (NIST) (July 2024)
work page 2024
-
[23]
A. I. Act, Regulation (eu) 2024/1689 of the european parlia- ment and of the council. 2024, URL: https://eur-lex. europa. eu/eli/reg/2024/1689/oj/eng. Date of access 3 (2025)
work page 2024
-
[24]
L. Blecher, G. Cucurull, T. Scialom, R. Stojnic, Nougat: Neu- ral optical understanding for academic documents, arXiv preprint arXiv:2308.13418 (2023)
-
[25]
d. developers, Marker: Pdf to markdown and json document conversion tool,https://github.com/datalab-to/marker(2025)
work page 2025
- [26]
-
[27]
Q. Zhang, B. Wang, V. S.-J. Huang, J. Zhang, Z. Wang, H. Liang, C. He, W. Zhang, Document parsing unveiled: Techniques, challenges, and prospects for structured information extraction, arXiv preprint arXiv:2410.21169 (2024). 40
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Z. N. Ndum, J. Tao, J. Ford, Y. Liu, Automating monte carlo simu- lations in nuclear engineering with domain knowledge-embedded large language model agents, Energy and AI (2025) 100555
work page 2025
- [29]
- [30]
-
[31]
W. Fan, Y. Ding, L. Ning, S. Wang, H. Li, D. Yin, T.-S. Chua, Q. Li, A survey on rag meeting llms: Towards retrieval-augmented large lan- guage models, in: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 6491–6501
work page 2024
-
[32]
Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, H. Wang, H. Wang, Retrieval-augmented generation for large language models: A survey, arXiv preprint arXiv:2312.10997 2 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
G. Yu, R. Ju, V. Sugumaran, H. Liu, Lightweight multimodal llm- empowered dual-agent collaboration for reliable defect detection and maintenance recommendation in tunnel infrastructure, Reliability En- gineering & System Safety 268 (2026) 111973
work page 2026
-
[34]
X. Liu, J. Hu, Q. Mei, S. Wang, Pirate-gpt: A locally deployed large lan- guage model framework for reliable offline anti-piracy decision support and knowledge retrieval in maritime operations, Reliability Engineering & System Safety 267 (2026) 111891
work page 2026
- [35]
-
[36]
X. Xiao, P. Chen, B. Qi, H. Zhao, J. Liang, J. Tong, H. Wang, Krail: A knowledge-driven framework for human reliability analysis integrat- ing idheas-data and large language models, Reliability Engineering & System Safety 265 (2026) 111585
work page 2026
-
[37]
O. H. Kwon, K. Vu, N. Bhargava, M. I. Radaideh, J. Cooper, V. Joynt, M.I.Radaideh, Sentimentanalysisoftheunitedstatespublicsupportof 41 nuclear power on social media using large language models, Renewable and Sustainable Energy Reviews 200 (2024) 114570
work page 2024
-
[38]
O. Gokdemir, C. Siebenschuh, A. Brace, A. Wells, B. Hsu, K. Hippe, P. Setty, A. Ajith, J. G. Pauloski, V. Sastry, et al., Hiperrag: High- performance retrieval augmented generation for scientific insights, in: Proceedings of the Platform for Advanced Scientific Computing Confer- ence, 2025, pp. 1–13
work page 2025
-
[39]
Iob, Nuclear security: A natural language processing generative ap- proach, Ph.D
G. Iob, Nuclear security: A natural language processing generative ap- proach, Ph.D. thesis, Politecnico di Torino (2024)
work page 2024
- [40]
-
[41]
M. Diefenthaler, C. Fanelli, L. Gerlach, W. Guan, T. Horn, A. Jentsch, M. Lin, K. Nagai, H. Nayak, C. Pecar, et al., Ai-assisted detector design for the eic (aid (2) e), Journal of Instrumentation 19 (2024) C07001
work page 2024
- [42]
- [43]
- [44]
-
[45]
M. A. Oumano, S. M. Pickett, Comparison of large language models’ performance on 600 nuclear medicine technology board examination– style questions, Journal of Nuclear Medicine Technology 24 (2025) 269– 335
work page 2025
-
[46]
Z. N. Ndum, J. Tao, J. Ford, Y. Mansung, Y. Liu, RADIANT-LLM: Retrieval-augmenteddomainintelligentLLMframeworkforsafe, secure, and safeguarded design of advanced nuclear reactor technologies, in: 42 Proceedings of the 66th Annual International Nuclear Materials Man- agement (INMM) Meeting, Institute of Nuclear Materials Management (INMM), Washington, D.C....
work page 2025
-
[47]
Taeihagh, Governance of generative ai, Policy and society 44 (2025) 1–22
A. Taeihagh, Governance of generative ai, Policy and society 44 (2025) 1–22
work page 2025
-
[48]
Chase, GitHub - langchain-ai/langchain: Build context-aware rea- soning applications (2023)
H. Chase, GitHub - langchain-ai/langchain: Build context-aware rea- soning applications (2023)
work page 2023
- [49]
-
[50]
C. Jeong, Generative AI service implementation using LLM application architecture: based on RAG model and LangChain framework, Journal of Intelligence and Information Systems 29 (2023) 129–164
work page 2023
- [51]
-
[52]
L. Blecher, G. Cucurull, T. Scialom, R. Stojnic, Nougat: Neural Optical Understanding for Academic Documents (2023)
work page 2023
- [53]
-
[54]
A. Cho, G. C. Kim, A. Karpekov, A. Helbling, Z. J. Wang, S. Lee, B. Hoover, D. H. P. Chau, Transformer explainer: Interactive learning of text-generative models, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39, 2025, pp. 29625–29627
work page 2025
-
[55]
K. Papineni, S. Roukos, T. Ward, W.-J. Zhu, Bleu: a method for au- tomatic evaluation of machine translation, in: Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318
work page 2002
-
[56]
L. Chin-Yew, Rouge: A package for automatic evaluation of summaries, in: Proceedings of the Workshop on Text Summarization Branches Out, 2004, 2004. 43
work page 2004
-
[57]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
P. Rajpurkar, J. Zhang, K. Lopyrev, P. Liang, Squad: 100,000+ questions for machine comprehension of text, arXiv preprint arXiv:1606.05250 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[58]
J. Yi, F. Du, Y. Nie, W. Liang, X. Zhou, J. Chen, G. Li, M. Liu, Y. Lv, W.Zhao, etal., Gai-hiq: Developingahealthinformationqualityassess- ment indicator system for generative artificial intelligence, Information Processing & Management 63 (2026) 104651
work page 2026
-
[59]
H. W. March, H. C. Wolff, Calculus, McGraw-Hill, New York, 1917
work page 1917
-
[60]
N. E. Todreas, M. S. Kazimi, Nuclear Systems I Thermal Hydraulic Fundamentals, Boca Raton, 1989. 44
work page 1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.