Recognition: unknown
Learning from the Best: Smoothness-Driven Metrics for Data Quality in Imitation Learning
Pith reviewed 2026-05-08 11:31 UTC · model grok-4.3
The pith
Smoothness metrics can select higher-quality demonstrations for imitation learning, raising policy success while using far less data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
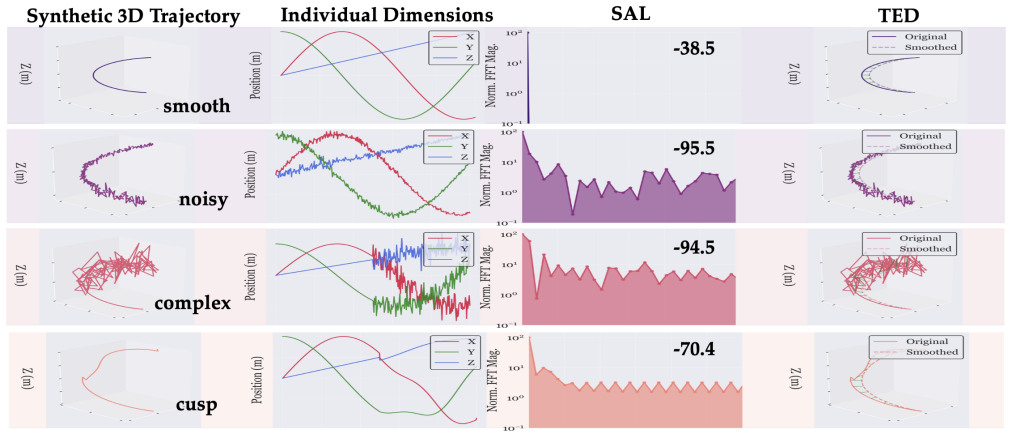
RINSE ranks and indexes demonstrations by trajectory smoothness using two metrics grounded in motor control: Spectral Arc Length measures frequency-domain regularity while Trajectory-Envelope Distance measures spatial deviation with contact awareness. When applied as a filter, the method reduces conditional action variance in the data, which compounds favorably with techniques such as action chunking. On standard benchmarks the filtered data yields higher success rates from substantially smaller subsets; the same scores also improve retrieval re-ranking and align with learned domain reweightings.
What carries the argument
RINSE framework that scores full trajectories with SAL, a spectral regularity measure, and TED, a contact-aware spatial deviation measure, to produce quality rankings without policy feedback.
If this is right
- SAL filtering on RoboMimic benchmarks produces 16 percent higher success rates while retaining only one-sixth of the original demonstrations.
- TED filtering on real-world manipulation tasks yields 20 percent performance gains while using only half the data.
- Using RINSE scores for retrieval re-ranking inside STRAP raises mean success by 5.6 percent on LIBERO-10.
- When employed as soft weights in domain reweighting, the smoothness scores produce allocations that correlate strongly with those learned by the reweighting method itself.
Where Pith is reading between the lines
- Smoothness filtering could be applied during data collection to discard low-quality trajectories in real time rather than after the fact.
- The same metrics might generalize to non-robot sequential tasks where expert demonstrations are also expected to exhibit low-frequency regularity.
- If smoothness correlates with reduced compounding error, the method may be especially useful for long-horizon tasks where small early deviations cause large later failures.
- Combining SAL and TED into a single composite score could further tighten the quality signal without adding policy-dependent computation.
Load-bearing premise
Trajectory smoothness serves as a reliable proxy for demonstration quality that improves policy performance without introducing harmful selection bias.
What would settle it
Policies trained on the smoothest subset of a fixed demonstration pool show equal or lower success rates than policies trained on randomly selected subsets of identical size across the same tasks and environments.
Figures




read the original abstract
In behavioral cloning (BC), policy performance is fundamentally limited by demonstration data quality. Real-world datasets contain trajectories of varying quality due to operator skill differences, teleoperation artifacts, and procedural inconsistencies, yet standard BC treats all demonstrations equally. Existing curation methods require costly policy training in the loop or manual annotation, limiting scalability. We propose RINSE (Ranking and INdexing Smooth Examples), a lightweight framework for scoring demonstrations based on trajectory smoothness that is policy-architecture-agnostic and operates on trajectory data alone, with TED additionally using a phase-boundary/contact signal. Grounded in motor control theory, which establishes smoothness as a hallmark of skilled movement, RINSE uses two complementary metrics: Spectral Arc Length (SAL), a spectral measure of frequency-domain regularity, and Trajectory-Envelope Distance (TED), a spatial measure of contact-aware geometric deviation. We show that smoothness filtering can reduce the conditional action variance of the retained data distribution, with downstream effects that can be amplified by action chunking and compounding error. On RoboMimic benchmarks, SAL filtering achieves 16% higher success using one-sixth of the data. On real-world manipulation, TED filtering achieves 20% improvement with half the data. As a retrieval-stage filter within STRAP on LIBERO-10, RINSE re-ranking improves mean success by 5.6%. As soft weights in Re-Mix domain reweighting, RINSE scores produce domain allocations highly correlated with the learned Re-Mix allocations (Spearman $\rho \geq 0.89$). These results support smoothness as a useful quality signal across filtering, retrieval, and reweighting settings, especially in noisy or heterogeneous data regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RINSE, a lightweight framework for scoring imitation learning demonstrations based on trajectory smoothness using Spectral Arc Length (SAL) and Trajectory-Envelope Distance (TED) metrics, grounded in motor control theory. It demonstrates that filtering data with these metrics can lead to higher success rates in behavioral cloning, specifically 16% higher on RoboMimic with 1/6 data via SAL, 20% on real-world with half data via TED, plus improvements in retrieval and reweighting applications.
Significance. Should the smoothness metrics prove to be a robust proxy for demonstration quality independent of variance reduction effects, the work would offer a scalable, training-free approach to data curation that could significantly benefit imitation learning in robotics, particularly for heterogeneous real-world datasets. The evaluation across filtering, retrieval, and reweighting strengthens the case for its utility.
major comments (2)
- [§4.1] §4.1 (RoboMimic Experiments): The reported 16% higher success rate using one-sixth of the data with SAL filtering is central to the claim; however, the experiments must include a control where trajectories are selected based on low variance alone (e.g., by action magnitude or frequency content without the full SAL metric) to confirm that the motor-control-grounded metric provides benefits beyond simple variance reduction.
- [§4.3] §4.3 (Real-world Manipulation): The 20% improvement with TED filtering using half the data requires evidence that the phase-boundary/contact signal does not inadvertently filter out valid exploratory or corrective trajectories that are high-quality but less smooth, as this would undermine the proxy relationship asserted in the introduction.
minor comments (2)
- The abstract states that RINSE is 'policy-architecture-agnostic and operates on trajectory data alone'; this should be explicitly verified in the method section with pseudocode or implementation details.
- [§3] Provide the mathematical definitions of SAL and TED as equations to allow readers to reproduce the metrics without ambiguity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help us improve the manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [§4.1] §4.1 (RoboMimic Experiments): The reported 16% higher success rate using one-sixth of the data with SAL filtering is central to the claim; however, the experiments must include a control where trajectories are selected based on low variance alone (e.g., by action magnitude or frequency content without the full SAL metric) to confirm that the motor-control-grounded metric provides benefits beyond simple variance reduction.
Authors: We agree that it is important to demonstrate that the improvements from SAL filtering are not solely due to variance reduction. SAL specifically quantifies smoothness through spectral arc length, capturing frequency-domain properties that simple variance measures (like action magnitude) do not fully encompass. Nevertheless, to strengthen this distinction, we will add a new control experiment in the revised version of §4.1. This will involve comparing performance when selecting low-variance trajectories based on action magnitude or frequency content alone versus using the full SAL metric. We expect this to show additional benefits from the motor control grounding, and the results will be reported accordingly. revision: yes
-
Referee: [§4.3] §4.3 (Real-world Manipulation): The 20% improvement with TED filtering using half the data requires evidence that the phase-boundary/contact signal does not inadvertently filter out valid exploratory or corrective trajectories that are high-quality but less smooth, as this would undermine the proxy relationship asserted in the introduction.
Authors: This is a valid concern, as overly aggressive filtering could exclude useful variability. However, our TED metric is designed to measure geometric deviation within phase boundaries defined by contact signals, aiming to retain trajectories that are consistent with skilled execution rather than erratic movements. In the real-world experiments, the selected data led to improved policy performance, suggesting that the retained trajectories are of higher quality for imitation. To provide the requested evidence, we will include in the revision an analysis of the discarded trajectories, examining if they contain exploratory or corrective elements that might be valuable, and discuss the implications for the smoothness-quality proxy. This may involve qualitative examples or quantitative metrics on the filtered set. revision: yes
Circularity Check
No circularity: metrics defined independently from motor-control theory and trajectory properties; downstream gains are measured outcomes, not definitional inputs.
full rationale
The paper defines SAL and TED directly from spectral and geometric properties of trajectories, citing external motor-control literature for the smoothness-quality link rather than deriving the metrics from policy performance or the same experimental outcomes. No equations reduce the quality score to a fit on the reported success rates; filtering is applied first, then BC performance is measured separately on RoboMimic and real-world tasks. Self-citations, if any, are not load-bearing for the core proxy claim, and the reported improvements (16% success with 1/6 data, 20% with half data) are falsifiable empirical results rather than tautological re-statements of the input metrics. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Smoothness is a hallmark of skilled movement according to motor control theory
Reference graph
Works this paper leans on
-
[1]
ALVINN: An autonomous land vehicle in a neural network,
D. A. Pomerleau, “ALVINN: An autonomous land vehicle in a neural network,” inAdvances in Neural Information Processing Systems (NeurIPS), 1989
1989
-
[2]
Efficient reductions for imitation learning,
S. Ross and D. Bagnell, “Efficient reductions for imitation learning,” in Proceedings of the thirteenth international conference on artificial intel- ligence and statistics. JMLR Workshop and Conference Proceedings, 2010, pp. 661–668
2010
-
[3]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” in Proceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[4]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine- grained bimanual manipulation with low-cost hardware,”arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review arXiv 2023
-
[5]
Octo: An open-source generalist robot policy,
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, Y . Tan, L. Y . Chen, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine, “Octo: An open-source generalist robot policy,” inProceedings of Robotics: Science and Systems, Delft, Netherlands, 2024
2024
-
[6]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Martín-Martín, “What matters in learning from offline human demonstrations for robot manipulation,” inarXiv preprint arXiv:2108.03298, 2021
work page internal anchor Pith review arXiv 2021
-
[7]
CUPID: Curating data your robot loves with influence functions,
C. Agia, R. Sinha, J. Yang, R. Antonova, M. Pavone, H. Nishimura, M. Itkina, and J. Bohg, “CUPID: Curating data your robot loves with influence functions,”Conference on Robot Learning (CoRL), 2025
2025
-
[8]
Robot data curation with mutual information estimators.arXiv preprint arXiv:2502.08623, 2025
J. Hejna, S. Mirchandani, A. Balakrishna, A. Xie, A. Wahid, J. Tompson, P. Sanketi, D. Shah, C. Devin, and D. Sadigh, “Robot data curation with mutual information estimators,” inarXiv preprint arXiv:2502.08623, 2025, https://arxiv.org/abs/2502.08623
-
[9]
DataMIL: Selecting data for robot imitation learning with datamodels,
S. Dass, A. Khaddaj, L. Engstrom, A. Madry, A. Ilyas, and R. Martin- Martin, “DataMIL: Selecting data for robot imitation learning with datamodels,”Conference on Robot Learning (CoRL), 2025
2025
-
[10]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
M. Ahn, A. Brohan, N. Brown, D. Kappler, A. Herzog, T. Haarnoja, C. Finn, and S. Levine, “Do as i can, not as i say: Grounding language in robotic affordances,” inRobotics: Science and Systems (RSS), 2022, https://arxiv.org/abs/2204.01691
work page internal anchor Pith review arXiv 2022
-
[11]
The coordination of arm movements: An ex- perimentally confirmed mathematical model,
T. Flash and N. Hogan, “The coordination of arm movements: An ex- perimentally confirmed mathematical model,”Journal of Neuroscience, vol. 5, no. 7, pp. 1688–1703, 1985
1985
-
[12]
Signal-dependent noise determines motor planning,
C. M. Harris and D. M. Wolpert, “Signal-dependent noise determines motor planning,”Nature, vol. 394, pp. 780–784, 1998
1998
-
[13]
A robust and sensitive metric for quantifying movement smoothness,
S. Balasubramanian, A. Melendez-Calderon, and E. Burdet, “A robust and sensitive metric for quantifying movement smoothness,”IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 20, no. 3, pp. 288–297, 2012
2012
-
[14]
How to train your robots? the impact of demonstration modality on imitation learning,
H. Li, Y . Cui, and D. Sadigh, “How to train your robots? the impact of demonstration modality on imitation learning,” inProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2025, https://arxiv.org/abs/2503.07017
-
[15]
Remix: Optimizing data mixtures for large scale imitation learning,
J. Hejna, C. A. Bhateja, Y . Jiang, K. Pertsch, and D. Sadigh, “Remix: Optimizing data mixtures for large scale imitation learning,” in8th Annual Conference on Robot Learning, 2024
2024
-
[16]
M. Memmel, A. Mandlekar, Y . Gao, and D. Fox, “Strap: Robot sub- trajectory retrieval for augmented policy learning,”arXiv preprint arXiv:2412.15182, 2024
-
[17]
Libero: Benchmarking knowledge transfer for lifelong robot learning,
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “Libero: Benchmarking knowledge transfer for lifelong robot learning,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[18]
Curating demonstra- tions using online experience,
A. S. Chen, A. M. Lessing, Y . Liu, and C. Finn, “Curating demonstra- tions using online experience,”Robotics: Science and Systems (RSS), 2025
2025
-
[19]
SCIZOR: A self-supervised approach to data curation for large-scale imitation learning,
Y . Zhang, Y . Xie, H. Liu, R. Shah, M. Wan, L. Fan, and Y . Zhu, “SCIZOR: A self-supervised approach to data curation for large-scale imitation learning,”IEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[20]
Behavior retrieval: Few-shot imitation learning by querying unlabeled datasets,
M. Du, S. Nair, D. Sadigh, and C. Finn, “Behavior retrieval: Few-shot imitation learning by querying unlabeled datasets,” inProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[21]
Maniskill-hab: A benchmark for low-level manipulation in home rearrangement tasks,
A. Shukla, S. Tao, and H. Su, “Maniskill-hab: A benchmark for low-level manipulation in home rearrangement tasks,”arXiv preprint arXiv:2412.13211, 2024
-
[22]
Data quality in imitation learning,
S. Belkhale, Y . Cui, and D. Sadigh, “Data quality in imitation learning,” Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[23]
Data scaling laws in imitation learning for robotic manipulation,
F. Linet al., “Data scaling laws in imitation learning for robotic manipulation,”International Conference on Learning Representations (ICLR), 2025
2025
-
[24]
Toward the fundamental limits of imitation learning,
N. Rajaraman, L. F. Yang, J. Jiao, and K. Ramchandran, “Toward the fundamental limits of imitation learning,”Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[25]
Is behavior cloning all you need? understanding horizon in imitation learning,
D. J. Foster, A. Block, and D. Misra, “Is behavior cloning all you need? understanding horizon in imitation learning,”Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[26]
On the analysis of movement smoothness,
S. Balasubramanian, A. Melendez-Calderon, A. Roby-Brami, and E. Burdet, “On the analysis of movement smoothness,”Journal of NeuroEngineering and Rehabilitation, vol. 12, p. 112, 2015
2015
-
[27]
Re-evaluating movement smoothness metrics: Exper- imental validation,
G. Cornecet al., “Re-evaluating movement smoothness metrics: Exper- imental validation,”Journal of NeuroEngineering and Rehabilitation, 2024
2024
-
[28]
Consistency matters: Defining demonstration data quality metrics in robot learning from demonstration,
M. Sakr, L. Kondepudi, and D. P. Losey, “Consistency matters: Defining demonstration data quality metrics in robot learning from demonstration,”ACM Transactions on Human-Robot Interaction, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.