Recognition: unknown
Conditional Imputation for Within-Modality Missingness in Multi-Modal Federated Learning
Pith reviewed 2026-05-08 08:27 UTC · model grok-4.3
The pith
Conditional diffusion models impute missing multimodal data to let federated models train on complete records.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Explicit imputation of missing within-modality components via conditional diffusion models recovers the true underlying distribution and lets the model operate on complete semantic structures, which in turn increases resilience to severe data incompleteness during both training and inference in privacy-preserving multimodal federated settings.
What carries the argument
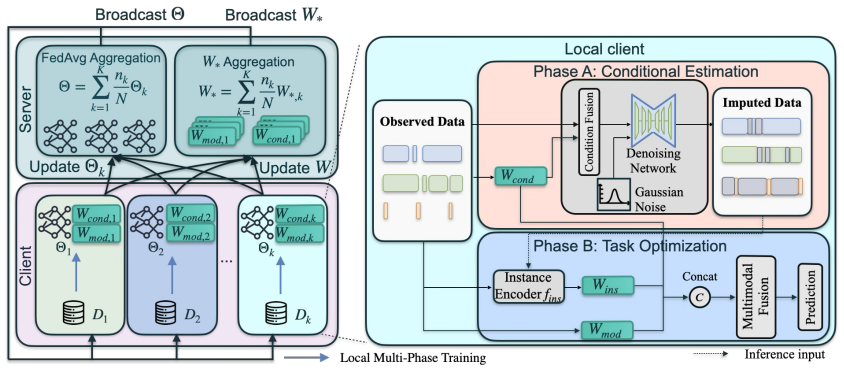
CondI two-phase pipeline in which conditional diffusion models first impute missing temporal components from multimodal context and conditional embeddings, after which modality-specific extractors and joint embedding spaces are optimized on the completed data.
If this is right
- Imputed raw data pass through the trained extractors to produce robust features that support joint embedding spaces.
- Performance remains comparable to state-of-the-art methods even under severe within-modality missingness on clinical datasets.
- Privacy-preserving collaborative training becomes feasible for applications with intermittent sensors or irregular sampling.
Where Pith is reading between the lines
- The same explicit-imputation step could be inserted into other federated architectures to reduce reliance on architectural alignment tricks.
- If future diffusion models achieve higher fidelity, the resilience to missingness could extend to even higher rates or longer gaps.
- Testing the framework on non-clinical multimodal streams with similar intermittency patterns would clarify whether the benefit is domain-specific.
Load-bearing premise
Conditional diffusion models can accurately recover the true underlying distribution of missing temporal components from the available multimodal context and embeddings.
What would settle it
An experiment in which imputed values are generated from held-out complete samples and then compared to the actual observed values; large statistical divergence between the two distributions, or no performance gain over implicit baselines at high missingness rates, would falsify the central claim.
Figures


read the original abstract
Multimodal Federated Learning (MMFL) enables privacy-preserving collaborative training, but real-world clinical applications often suffer from within-modality missingness caused by sensor intermittency or irregular sampling. Existing methods implicitly represent unobserved data via architectural alignment or missing embeddings, often failing to recover the true distribution and yielding sub-optimal performance. We propose CondI, a federated framework explicitly addressing this missingness using conditional diffusion models. CondI employs a two-phase training pipeline: first, imputing unobserved temporal components using available multimodal context and conditional embeddings; second, optimizing modality-specific extractors and joint embedding spaces. During inference, imputed raw data pass through trained extractors to generate robust features, providing a holistic representation for downstream tasks. Explicit data imputation ensures models operate on complete semantic structures, significantly enhancing resilience against severe data incompleteness. Experiments on three clinical datasets (PTB-XL, SLEEP-EDF, MIMIC-IV) demonstrate CondI achieves comparable results to state-of-the-art baselines. Code: https://github.com/ZhengWugeng/CondI
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CondI, a multimodal federated learning framework that explicitly imputes within-modality missing temporal data using conditional diffusion models conditioned on available multimodal context and embeddings. It describes a two-phase pipeline (imputation followed by extractor and joint embedding optimization) and claims that operating on complete semantic structures via explicit imputation significantly enhances resilience to severe missingness. Experiments on PTB-XL, SLEEP-EDF, and MIMIC-IV are reported to yield performance comparable to state-of-the-art baselines, with code released at https://github.com/ZhengWugeng/CondI.
Significance. If the central claim of meaningful improvement in resilience holds under detailed scrutiny, the work would address a practical gap in clinical MMFL where sensor intermittency causes within-modality missingness; explicit imputation could outperform implicit embedding approaches. The release of reproducible code is a clear strength that supports verification and extension.
major comments (2)
- [Abstract] Abstract: the central claim that explicit imputation 'significantly enhancing resilience against severe data incompleteness' is not supported by the stated results, which report only that CondI 'achieves comparable results to state-of-the-art baselines' with no quantitative deltas, missing-rate sweeps, error bars, statistical tests, or ablation details on downstream performance under varying incompleteness levels.
- [Method] Method description: the two-phase pipeline and conditional diffusion imputation step are presented without equations, loss formulations, or conditioning details (e.g., how multimodal embeddings are injected into the diffusion process), making it impossible to assess whether the model can recover the true underlying distribution as assumed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving clarity and supporting claims with evidence. We address each major comment below and commit to revisions that strengthen the presentation without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that explicit imputation 'significantly enhancing resilience against severe data incompleteness' is not supported by the stated results, which report only that CondI 'achieves comparable results to state-of-the-art baselines' with no quantitative deltas, missing-rate sweeps, error bars, statistical tests, or ablation details on downstream performance under varying incompleteness levels.
Authors: We agree that the abstract as currently worded does not sufficiently substantiate the claim of significant enhancement with quantitative details. The experiments section of the manuscript reports results across PTB-XL, SLEEP-EDF, and MIMIC-IV under multiple missingness rates, including comparisons to baselines, but these specifics are not summarized in the abstract. In the revision, we will update the abstract to include key quantitative deltas, missing-rate performance trends, and references to statistical comparisons where available, ensuring the claim is directly supported by the reported evidence. revision: yes
-
Referee: [Method] Method description: the two-phase pipeline and conditional diffusion imputation step are presented without equations, loss formulations, or conditioning details (e.g., how multimodal embeddings are injected into the diffusion process), making it impossible to assess whether the model can recover the true underlying distribution as assumed.
Authors: The referee correctly identifies that the method description lacks the necessary mathematical formalization. The current manuscript outlines the two-phase pipeline at a high level but does not provide the diffusion process equations, the training objective (such as the conditional denoising loss), or the precise mechanism for injecting multimodal embeddings and context as conditioning signals. We will revise the method section to include these details, including the forward and reverse diffusion steps, the loss formulation, and the conditioning injection strategy, allowing readers to evaluate the distributional recovery assumptions. revision: yes
Circularity Check
No circularity: descriptive pipeline with no equations or self-referential reductions
full rationale
The manuscript describes a two-phase federated framework (CondI) that first imputes missing temporal components via conditional diffusion models and then optimizes extractors, but supplies no mathematical derivations, equations, or 'predictions' that reduce to fitted inputs by construction. The abstract and available text contain no self-definitional steps, no fitted parameters renamed as predictions, and no load-bearing self-citations that justify uniqueness theorems. Experimental claims rest on reported performance on PTB-XL, SLEEP-EDF and MIMIC-IV rather than on any internal tautology. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Juan Miguel Lopez Alcaraz and Nils Strodthoff. Diffusion- based time series imputation and forecasting with structured state space models.arXiv preprint arXiv:2208.09399, 2022. 3
-
[2]
Missing value imputation on multidimensional time series.arXiv preprint arXiv:2103.01600, 2021
Parikshit Bansal, Prathamesh Deshpande, and Sunita Sarawagi. Missing value imputation on multidimensional time series.arXiv preprint arXiv:2103.01600, 2021. 3
-
[3]
Defu Cao, Furong Jia, Sercan O Arik, Tomas Pfister, Yixiang Zheng, Wen Ye, and Yan Liu. Tempo: Prompt-based genera- tive pre-trained transformer for time series forecasting.arXiv preprint arXiv:2310.04948, 2023. 1, 2
-
[4]
Defu Cao, Wen Ye, Yizhou Zhang, and Yan Liu. Timedit: General-purpose diffusion transformers for time series foun- dation model.arXiv preprint arXiv:2409.02322, 2024. 3
-
[5]
Mul- timodal federated learning: A survey.Sensors, 23(15):6986,
Liwei Che, Jiaqi Wang, Yao Zhou, and Fenglong Ma. Mul- timodal federated learning: A survey.Sensors, 23(15):6986,
-
[6]
Feddat: An approach for foundation model fine- tuning in multi-modal heterogeneous federated learning
Haokun Chen, Yao Zhang, Denis Krompass, Jindong Gu, and V olker Tresp. Feddat: An approach for foundation model fine- tuning in multi-modal heterogeneous federated learning. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 11285–11293, 2024. 2
2024
-
[7]
Fedmsplit: Correlation- adaptive federated multi-task learning across multimodal split networks
Jiayi Chen and Aidong Zhang. Fedmsplit: Correlation- adaptive federated multi-task learning across multimodal split networks. InProceedings of the 28th ACM SIGKDD confer- ence on knowledge discovery and data mining, pages 87–96,
-
[8]
Probabilistic conformal distilla- tion for enhancing missing modality robustness.Advances in Neural Information Processing Systems, 37:36218–36242,
Mengxi Chen, Fei Zhang, Zihua Zhao, Jiangchao Yao, Ya Zhang, and Yanfeng Wang. Probabilistic conformal distilla- tion for enhancing missing modality robustness.Advances in Neural Information Processing Systems, 37:36218–36242,
-
[9]
Dam: Towards a foundation model for time se- ries forecasting
Luke Darlow, Qiwen Deng, Ahmed Hassan, Martin Asenov, Rajkarn Singh, Artjom Joosen, Adam Barker, and Amos Storkey. Dam: Towards a foundation model for time se- ries forecasting. InThe Twelfth International Conference on Learning Representations, 2024. 3
2024
-
[10]
A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting. InForty-first international conference on machine learning,
-
[11]
Elizabeth Fons, Alejandro Sztrajman, Yousef El-Laham, Lu- ciana Ferrer, Svitlana Vyetrenko, and Manuela Veloso. Lscd: Lomb-scargle conditioned diffusion for time series imputa- tion.arXiv preprint arXiv:2506.17039, 2025. 3
-
[12]
Gp-vae: Deep probabilistic time series impu- tation
Vincent Fortuin, Dmitry Baranchuk, Gunnar R ¨atsch, and Stephan Mandt. Gp-vae: Deep probabilistic time series impu- tation. InInternational conference on artificial intelligence and statistics, pages 1651–1661. PMLR, 2020. 3
2020
-
[13]
Moment: A family of open time-series foundation models.arXiv preprint arXiv:2402.03885, 2024
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. Moment: A fam- ily of open time-series foundation models.arXiv preprint arXiv:2402.03885, 2024. 1, 3
-
[14]
Fusemoe: Mixture-of-experts transformers for flexi- modal fusion.Advances in Neural Information Processing Systems, 37:67850–67900, 2024
Xing Han, Huy Nguyen, Carl Harris, Nhat Ho, and Suchi Saria. Fusemoe: Mixture-of-experts transformers for flexi- modal fusion.Advances in Neural Information Processing Systems, 37:67850–67900, 2024. 3
2024
-
[15]
Denoising diffu- sion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 5
2020
-
[16]
Multimodal federated learning: Concept, methods, applications and future directions.Information Fusion, 112:102576, 2024
Wei Huang, Dexian Wang, Xiaocao Ouyang, Jihong Wan, Jia Liu, and Tianrui Li. Multimodal federated learning: Concept, methods, applications and future directions.Information Fusion, 112:102576, 2024. 1, 2
2024
-
[17]
MIMIC-IV
Alistair Johnson, Lucas Bulgarelli, Tom Pollard, Steven Horng, Leo Anthony Celi, and Roger Mark. MIMIC-IV. PhysioNet, pages 49–55, 2020. Accessed: 2021-08-23. 1, 2, 3, 6
2020
-
[18]
Sleep-edf database expanded (version 1.0.0),
Bob Kemp. Sleep-edf database expanded (version 1.0.0),
-
[19]
Cyin: Cyclic informative latent space for bridging complete and incomplete multimodal learning
Ronghao Lin, Qiaolin He, Sijie Mai, Ying Zeng, Aolin Xiong, Li Huang, Yap-Peng Tan, and Haifeng Hu. Cyin: Cyclic informative latent space for bridging complete and incomplete multimodal learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. 2, 3
-
[20]
Timer: Transformers for time series analysis at scale,
Yong Liu, Haoran Zhang, Chenyu Li, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. Timer: Generative pre-trained transformers are large time series models.arXiv preprint arXiv:2402.02368, 2024. 3
-
[21]
Mul- tivariate time series imputation with generative adversarial networks.Advances in neural information processing systems, 31, 2018
Yonghong Luo, Xiangrui Cai, Ying Zhang, Jun Xu, et al. Mul- tivariate time series imputation with generative adversarial networks.Advances in neural information processing systems, 31, 2018. 3
2018
-
[22]
Nguyen, Trong Nghia Hoang, Thanh Trung Huynh, Quoc Viet Hung Nguyen, and Phi Le Nguyen
Duong M. Nguyen, Trong Nghia Hoang, Thanh Trung Huynh, Quoc Viet Hung Nguyen, and Phi Le Nguyen. Learning recon- figurable representations for multimodal federated learning with missing data. InThe Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025. 1, 2, 6
2025
-
[23]
Fedmac: Tackling partial-modality missing in federated learn- ing with cross-modal aggregation and contrastive regulariza- tion
Manh Duong Nguyen, Trung Thanh Nguyen, Huy Hieu Pham, Trong Nghia Hoang, Phi Le Nguyen, and Thanh Trung Huynh. Fedmac: Tackling partial-modality missing in federated learn- ing with cross-modal aggregation and contrastive regulariza- tion. In2024 22nd International Symposium on Network Computing and Applications (NCA), pages 278–285. IEEE,
-
[24]
Fedmm: Feder- ated multi-modal learning with modality heterogeneity in computational pathology
Yuanzhe Peng, Jieming Bian, and Jie Xu. Fedmm: Feder- ated multi-modal learning with modality heterogeneity in computational pathology. InICASSP 2024-2024 IEEE Inter- national Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), pages 1696–1700. IEEE, 2024. 2
2024
-
[25]
A contrastive learning and graph-based approach for missing modalities in multimodal federated learning
Thu Hang Phung, Binh P Nguyen, Thanh Hung Nguyen, Quoc Viet Hung Nguyen, Phi Le Nguyen, and Thanh Trung Huynh. A contrastive learning and graph-based approach for missing modalities in multimodal federated learning. In2024 International Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE, 2024. 1, 2
2024
-
[26]
Federated prompt-tuning with heterogeneous and incomplete multimodal client data
Thu Hang Phung, Duong M Nguyen, Thanh Trung Huynh, Quoc Viet Hung Nguyen, Trong Nghia Hoang, and Phi Le Nguyen. Federated prompt-tuning with heterogeneous and incomplete multimodal client data. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3936–3946, 2025. 2
2025
-
[27]
Kashif Rasul, Arjun Ashok, Andrew Robert Williams, Hena Ghonia, Rishika Bhagwatkar, Arian Khorasani, Mohammad Javad Darvishi Bayazi, George Adamopoulos, Roland Riachi, Nadhir Hassen, et al. Lag-llama: Towards foundation mod- els for probabilistic time series forecasting.arXiv preprint arXiv:2310.08278, 2023. 1, 2
-
[28]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outra- geously large neural networks: The sparsely-gated mixture- of-experts layer.arXiv preprint arXiv:1701.06538, 2017. 5
work page internal anchor Pith review arXiv 2017
-
[29]
Csdi: Conditional score-based diffusion models for probabilistic time series imputation.Advances in neural in- formation processing systems, 34:24804–24816, 2021
Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Er- mon. Csdi: Conditional score-based diffusion models for probabilistic time series imputation.Advances in neural in- formation processing systems, 34:24804–24816, 2021. 3, 5
2021
-
[30]
PTB-XL: A large publicly available elec- trocardiography dataset.Scientific Data, 2020
Patrick Wagner, Nils Strodthoff, Ralf-Dieter Bousseljot, Di- eter Kreiseler, Fatima Isabel Lunze, Wojciech Samek, and Tobias Schaeffter. PTB-XL: A large publicly available elec- trocardiography dataset.Scientific Data, 2020. 2, 6
2020
-
[31]
Jun Wang, Wenjie Du, Yiyuan Yang, Linglong Qian, Wei Cao, Keli Zhang, Wenjia Wang, Yuxuan Liang, and Qingsong Wen. Deep learning for multivariate time series imputation: A survey.arXiv preprint arXiv:2402.04059, 2024. 3
-
[32]
Distribution- consistent modal recovering for incomplete multimodal learn- ing
Yuanzhi Wang, Zhen Cui, and Yong Li. Distribution- consistent modal recovering for incomplete multimodal learn- ing. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 22025–22034, 2023. 1, 2
2023
-
[33]
TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis
Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. Timesnet: Temporal 2d-variation modeling for general time series analysis.arXiv preprint arXiv:2210.02186, 2022. 3
work page internal anchor Pith review arXiv 2022
-
[34]
A unified framework for multi-modal federated learning
Baochen Xiong, Xiaoshan Yang, Fan Qi, and Changsheng Xu. A unified framework for multi-modal federated learning. Neurocomputing, 480:110–118, 2022. 2
2022
-
[35]
Promptcast: A new prompt- based learning paradigm for time series forecasting.IEEE Transactions on Knowledge and Data Engineering, 36(11): 6851–6864, 2023
Hao Xue and Flora D Salim. Promptcast: A new prompt- based learning paradigm for time series forecasting.IEEE Transactions on Knowledge and Data Engineering, 36(11): 6851–6864, 2023. 2
2023
-
[36]
Frequency-aware generative models for multivariate time se- ries imputation.Advances in Neural Information Processing Systems, 37:52595–52623, 2024
Xinyu Yang, Yu Sun, Xiaojie Yuan, and Xinyang Chen. Frequency-aware generative models for multivariate time se- ries imputation.Advances in Neural Information Processing Systems, 37:52595–52623, 2024. 1, 2
2024
-
[37]
Estimating missing data in temporal data streams using multi- directional recurrent neural networks.IEEE Transactions on Biomedical Engineering, 66(5):1477–1490, 2018
Jinsung Yoon, William R Zame, and Mihaela Van Der Schaar. Estimating missing data in temporal data streams using multi- directional recurrent neural networks.IEEE Transactions on Biomedical Engineering, 66(5):1477–1490, 2018. 3
2018
-
[38]
Multimodal feder- ated learning via contrastive representation ensemble,
Qiying Yu, Yang Liu, Yimu Wang, Ke Xu, and Jingjing Liu. Multimodal federated learning via contrastive representation ensemble.arXiv preprint arXiv:2302.08888, 2023. 2
-
[39]
Robust multimodal federated learning for incomplete modalities.Computer Communications, 214:234–243, 2024
Songcan Yu, Junbo Wang, Walid Hussein, and Patrick CK Hung. Robust multimodal federated learning for incomplete modalities.Computer Communications, 214:234–243, 2024. 1, 2
2024
-
[40]
Flex-moe: Modeling arbitrary modality combination via the flexible mixture-of-experts.Advances in Neural Information Processing Systems, 37:98782–98805, 2024
Sukwon Yun, Inyoung Choi, Jie Peng, Yangfan Wu, Jingxuan Bao, Qiyiwen Zhang, Jiayi Xin, Qi Long, and Tianlong Chen. Flex-moe: Modeling arbitrary modality combination via the flexible mixture-of-experts.Advances in Neural Information Processing Systems, 37:98782–98805, 2024. 2
2024
-
[41]
Rong Zhang, Khosrow Behbehani, Craig G Crandall, Julie H Zuckerman, and Benjamin D Levine. Dynamic regulation of heart rate during acute hypotension: new insight into barore- flex function.American Journal of Physiology-Heart and Circulatory Physiology, 280(1):H407–H419, 2001. 2, 3
2001
-
[42]
Mul- timodal federated learning on iot data
Yuchen Zhao, Payam Barnaghi, and Hamed Haddadi. Mul- timodal federated learning on iot data. In2022 IEEE/ACM seventh international conference on internet-of-things design and implementation (ioTDI), pages 43–54. IEEE, 2022. 1, 2
2022
-
[43]
Missing data imputation via conditional generator and cor- relation learning for multimodal brain tumor segmentation
Tongxue Zhou, Pierre Vera, St ´ephane Canu, and Su Ruan. Missing data imputation via conditional generator and cor- relation learning for multimodal brain tumor segmentation. Pattern Recognition Letters, 158:125–132, 2022. 1, 2
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.