Recognition: unknown
UAV Trajectory and Bandwidth Allocation for Efficient Data Collection in Low-Altitude Intelligent IoT: A Hierarchical DRL Approach
Pith reviewed 2026-05-08 06:57 UTC · model grok-4.3
The pith
A hierarchical deep reinforcement learning method lets UAVs maximize IoT data collection by planning trajectories at coarse time scales and bandwidth at fine scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that structuring the reinforcement learning policy hierarchically, with trajectory decisions at coarse temporal granularity and bandwidth decisions at fine granularity using the TBH-DDPG algorithm, allows maximization of collected data volume under interference, dynamic data volumes, and obstacles, while achieving faster convergence and lower computational cost.
What carries the argument
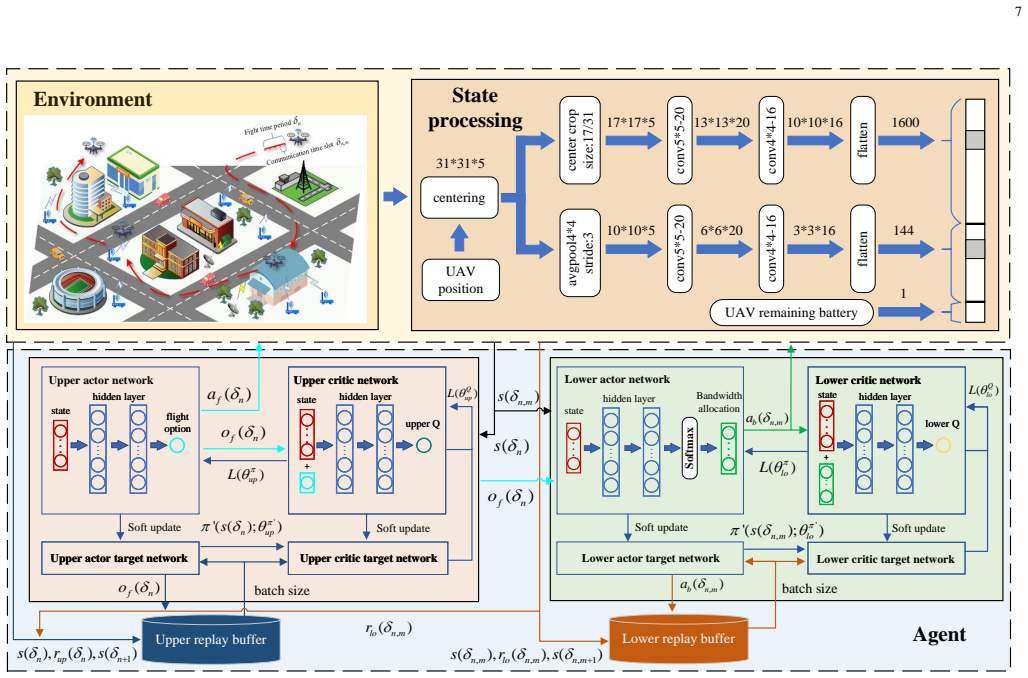
The hierarchical deep deterministic policy gradients (TBH-DDPG) algorithm, where the upper level decides UAV trajectory and the lower level decides bandwidth allocation at different time scales.
Load-bearing premise
The simulations with added jammers, varying data volumes, and obstacles fully represent real UAV flight and communication conditions, and the trained policies can execute on UAVs with limited onboard processing power.
What would settle it
Deploying the trained hierarchical policy on a physical UAV in an outdoor environment with actual jammers and obstacles and measuring whether data collection volume, convergence behavior, and compute usage match the simulation results.
Figures







read the original abstract
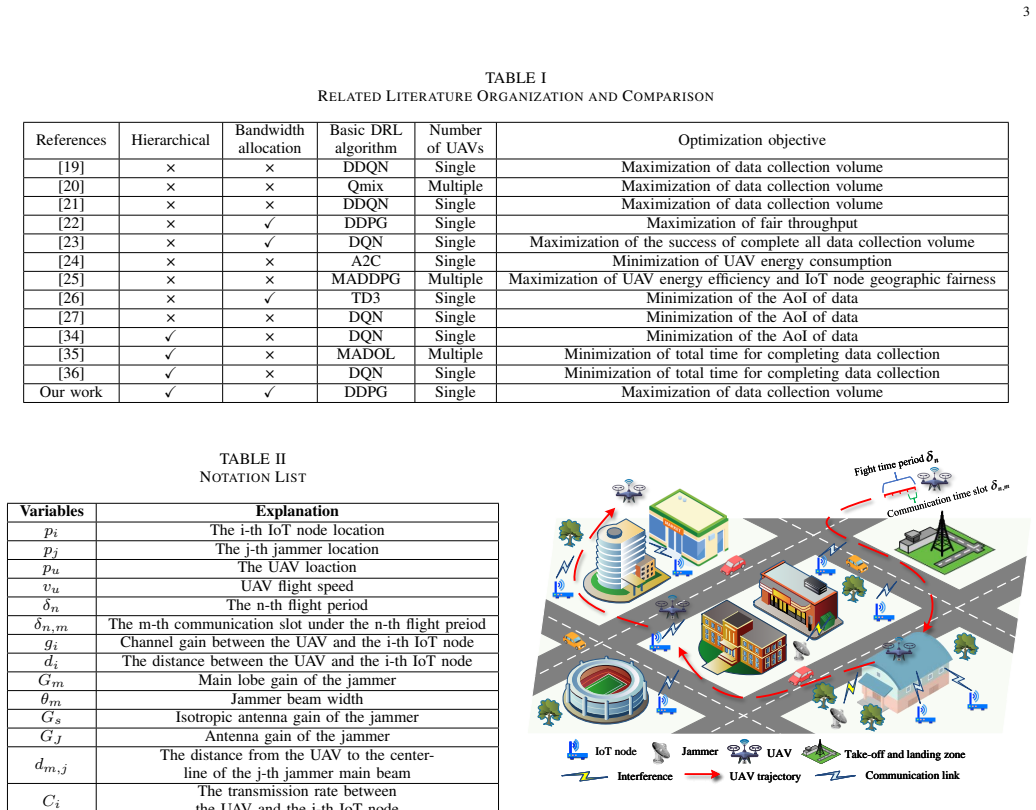
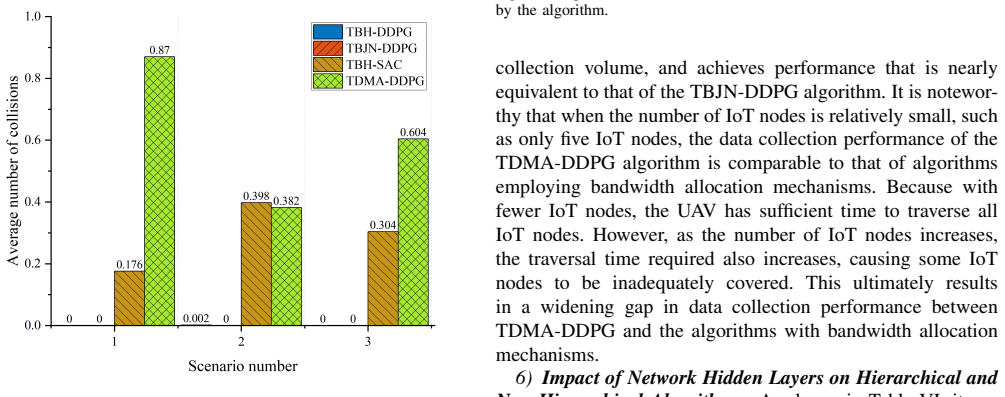
Under the 6G wireless network evolution, the low-altitude Internet of Things (IoT), supported by unmanned aerial vehicles (UAVs) with Integrated Sensing and Communication (ISAC) capabilities, provides ground sensing networks with advanced real-time monitoring and data collection. To maximize data collection volume from distributed IoT nodes, AI-powered data collection technology plays a critical role in enabling intelligent decision-making. Among them, deep reinforcement learning (DRL) has gained particular attention. However, the existing DRL-based work on UAV-assisted IoT nodes data collection rarely address problems such as unknown interference and dynamic data volume. Moreover, these DRL models have high arithmetic requirements and slow convergence speed, making it difficult to carry on UAVs with limited load and arithmetic power. To address these challenges, a hierarchical deep reinforcement learning (HDRL), which can converge quickly and with smaller models, is designed to optimize UAV trajectories and bandwidth allocation to maximize data collection volume. Firstly, the proposed scenario incorporates interference from jammers, dynamic data volume of IoT nodes, and multiple types of obstacles. The entire task is hierarchically structured: the upper-level makes flight trajectory decisions at a coarse temporal granularity, while the lower-level makes bandwidth allocation decisions at a finer temporal granularity. Secondly, a trajectory and bandwidth allocation optimization algorithm based on hierarchical deep deterministic policy gradients (TBH-DDPG) is proposed to solve the problem. Finally, simulation results demonstrate that the proposed algorithm improves convergence speed by 44.44%, and reduces computational cost by 58.05%, compared to non-hierarchical algorithm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a hierarchical deep reinforcement learning (HDRL) framework using a trajectory and bandwidth allocation optimization algorithm based on hierarchical deep deterministic policy gradients (TBH-DDPG). The approach addresses UAV-assisted data collection in low-altitude IoT networks with ISAC capabilities, incorporating jammers, dynamic IoT data volumes, and obstacles. The task is decomposed hierarchically: upper level handles coarse-grained flight trajectory decisions, lower level handles fine-grained bandwidth allocation. Simulation results are presented claiming that TBH-DDPG achieves 44.44% faster convergence and 58.05% lower computational cost relative to a non-hierarchical DDPG baseline.
Significance. If the performance gains can be reproduced with fully specified simulation parameters, statistical validation, and hardware-aware metrics, the hierarchical decomposition could provide a useful template for making DRL policies deployable on compute- and energy-constrained UAV platforms. The work directly targets practical barriers (slow convergence, high arithmetic demand) that currently hinder on-board DRL for UAV-IoT applications. However, the absence of detailed experimental protocols and external benchmarks currently limits the strength of this contribution.
major comments (2)
- The central performance claims (44.44% convergence improvement and 58.05% computational-cost reduction) are stated in the abstract and presumably elaborated in the simulation results section, yet no definition is given for the metrics themselves (e.g., episodes until 95% of maximum reward, FLOPs, wall-clock time per decision, or parameter count). No simulation parameters (jammer power, data-volume arrival process, obstacle density, ISAC channel model, UAV dynamics), baseline implementation details, number of random seeds, or variance statistics are provided. Without these, the numerical gains cannot be independently verified and the claim that the hierarchical policy is suitable for limited-load UAVs remains unsupported.
- The system model (presumably §2 or §3) includes jammers, dynamic data volumes, and multiple obstacle types, but the manuscript does not analyze or simulate the effect of imperfect state observation, sensing errors, or onboard inference latency on the hierarchical policy. The reported gains therefore rest on an idealized simulation environment whose fidelity to real UAV flight dynamics, battery constraints, and wireless conditions is not demonstrated.
minor comments (2)
- Notation for the hierarchical levels (upper/lower) and the precise interface between trajectory and bandwidth actions should be clarified with a diagram or pseudocode in the algorithm description.
- The abstract would benefit from a one-sentence statement of the key technical novelty (hierarchical temporal decomposition) before the numerical results.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The comments highlight important aspects for strengthening the verifiability and practical relevance of our results. We address each major comment below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: The central performance claims (44.44% convergence improvement and 58.05% computational-cost reduction) are stated in the abstract and presumably elaborated in the simulation results section, yet no definition is given for the metrics themselves (e.g., episodes until 95% of maximum reward, FLOPs, wall-clock time per decision, or parameter count). No simulation parameters (jammer power, data-volume arrival process, obstacle density, ISAC channel model, UAV dynamics), baseline implementation details, number of random seeds, or variance statistics are provided. Without these, the numerical gains cannot be independently verified and the claim that the hierarchical policy is suitable for limited-load UAVs remains unsupported.
Authors: We agree that the manuscript does not provide explicit definitions of the convergence and computational-cost metrics nor a complete enumeration of simulation parameters, baseline implementation details, or statistical reporting. In the revised manuscript we will insert a new subsection (Simulation Setup and Metrics) that (i) defines convergence as the number of training episodes required to reach 95 % of the maximum attainable reward and computational cost as the average number of FLOPs per decision step, (ii) lists all numerical values for jammer transmit power, data-volume arrival process, obstacle density, ISAC channel model, UAV kinematic constraints, and battery model, (iii) supplies pseudocode and hyper-parameter tables for both TBH-DDPG and the flat DDPG baseline, and (iv) reports all performance figures as means over 10 independent random seeds together with standard deviations. These additions will enable independent reproduction and will directly support the claim of suitability for resource-constrained UAV platforms. revision: yes
-
Referee: The system model (presumably §2 or §3) includes jammers, dynamic data volumes, and multiple obstacle types, but the manuscript does not analyze or simulate the effect of imperfect state observation, sensing errors, or onboard inference latency on the hierarchical policy. The reported gains therefore rest on an idealized simulation environment whose fidelity to real UAV flight dynamics, battery constraints, and wireless conditions is not demonstrated.
Authors: The referee is correct that our current simulations assume perfect state observation and do not incorporate sensing errors or onboard inference latency. The contribution of the work is to show that hierarchical decomposition yields faster convergence and lower per-decision compute under the modeled environment that already includes jammers, dynamic data volumes, and obstacles. Extending the evaluation to imperfect observations would require additional stochastic models of sensing error and latency measurements that lie outside the scope of the present study. In the revision we will add a dedicated paragraph in the Conclusions section that explicitly states these modeling assumptions as limitations and identifies imperfect state information and hardware-in-the-loop latency as important directions for future work. We do not intend to perform new simulations of sensing errors in this revision. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes a hierarchical DRL algorithm (TBH-DDPG) for UAV trajectory and bandwidth allocation under interference and dynamic conditions, with performance claims based solely on simulation comparisons to a non-hierarchical DDPG baseline. No equations, self-citations, or load-bearing steps are quoted that reduce any claimed result to an input by construction, fitted parameter renamed as prediction, or self-referential uniqueness theorem. The simulation results and algorithm design remain independent of the reported metrics.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard assumptions of deep deterministic policy gradient convergence under Markov decision process formulation
- domain assumption Simulation environment faithfully represents real UAV flight dynamics, jammer interference, and time-varying IoT data volumes
Reference graph
Works this paper leans on
-
[1]
Internet of Low-Altitude UA Vs (IoLoUA): a methodical modeling on integration of Internet of “Things
A. Srivastava and J. Prakash, “Internet of Low-Altitude UA Vs (IoLoUA): a methodical modeling on integration of Internet of “Things” with “UA V” possibilities and tests,”Artificial Intelligence Review, vol. 56, no. 3, pp. 2279–2324, 2023
2023
-
[2]
UA V meets integrated sensing and communication: Challenges and future directions,
J. Mu, R. Zhang, Y . Cui, N. Gao, and X. Jing, “UA V meets integrated sensing and communication: Challenges and future directions,”IEEE Communications Magazine, vol. 61, no. 5, pp. 62–67, 2023
2023
-
[3]
UA V-assisted data collection for Internet of Things: A survey,
Z. Wei, M. Zhu, N. Zhang, L. Wang, Y . Zou, Z. Meng, H. Wu, and Z. Feng, “UA V-assisted data collection for Internet of Things: A survey,” IEEE Internet of Things Journal, vol. 9, no. 17, pp. 15 460–15 483, 2022
2022
-
[4]
A review of cognitive UA Vs: AI-driven situation awareness for enhanced operations,
M. Dehghan and E. Khosravian, “A review of cognitive UA Vs: AI-driven situation awareness for enhanced operations,”AI and Tech in Behavioral and Social Sciences, vol. 2, no. 4, pp. 54–65, 2024
2024
-
[5]
Urban traffic monitoring and analysis using unmanned aerial vehicles (UA Vs): A systematic literature review,
E. V . Butil ˘a and R. G. Boboc, “Urban traffic monitoring and analysis using unmanned aerial vehicles (UA Vs): A systematic literature review,” Remote Sensing, vol. 14, no. 3, p. 620, 2022
2022
-
[6]
Unmanned aerial vehicles for air pollution monitoring: A survey,
N. H. Motlagh, P. Kortoc ¸i, X. Su, L. Lov´en, H. K. Hoel, S. B. Haugsvær, V . Srivastava, C. F. Gulbrandsen, P. Nurmi, and S. Tarkoma, “Unmanned aerial vehicles for air pollution monitoring: A survey,”IEEE Internet of Things Journal, vol. 10, no. 24, pp. 21 687–21 704, 2023
2023
-
[7]
K. P. Valavanis and G. J. Vachtsevanos,Handbook of unmanned aerial vehicles. Springer Publishing Company, Incorporated, 2014
2014
-
[8]
Mobile unmanned aerial vehicles (UA Vs) for energy-efficient Internet of Things commu- nications,
M. Mozaffari, W. Saad, M. Bennis, and M. Debbah, “Mobile unmanned aerial vehicles (UA Vs) for energy-efficient Internet of Things commu- nications,”IEEE Transactions on Wireless Communications, vol. 16, no. 11, pp. 7574–7589, 2017
2017
-
[9]
Joint trajectory planning and communication design for multiple UA Vs in intelligent collaborative air-ground communication systems,
Z. Lu, Z. Jia, Q. Wu, and Z. Han, “Joint trajectory planning and communication design for multiple UA Vs in intelligent collaborative air-ground communication systems,”IEEE Internet of Things Journal, 2024
2024
-
[10]
Trajectory design for UA V-based Internet of Things data collection: A deep reinforcement learning approach,
Y . Wang, Z. Gao, J. Zhang, X. Cao, D. Zheng, Y . Gao, D. W. K. Ng, and M. Di Renzo, “Trajectory design for UA V-based Internet of Things data collection: A deep reinforcement learning approach,”IEEE Internet of Things Journal, vol. 9, no. 5, pp. 3899–3912, 2021
2021
-
[11]
Deep rein- forcement learning-based UA V path planning algorithm in agricultural time-constrained data collection
C. Mingcheng, F. Shoucheng, X. GuoQiang, and H. Ke, “Deep rein- forcement learning-based UA V path planning algorithm in agricultural time-constrained data collection.”Advances in Electrical & Computer Engineering, vol. 23, no. 2, 2023
2023
-
[12]
Energy-efficient UA V-enabled data collection via wireless charging: A reinforcement learning approach,
S. Fu, Y . Tang, Y . Wu, N. Zhang, H. Gu, C. Chen, and M. Liu, “Energy-efficient UA V-enabled data collection via wireless charging: A reinforcement learning approach,”IEEE Internet of Things Journal, vol. 8, no. 12, pp. 10 209–10 219, 2021
2021
-
[13]
Energy-efficient data collection in UA V enabled wireless sensor network,
C. Zhan, Y . Zeng, and R. Zhang, “Energy-efficient data collection in UA V enabled wireless sensor network,”IEEE Wireless Communications Letters, vol. 7, no. 3, pp. 328–331, 2017
2017
-
[14]
UA V trajectory planning for data collection from time-constrained IoT devices,
M. Samir, S. Sharafeddine, C. M. Assi, T. M. Nguyen, and A. Ghrayeb, “UA V trajectory planning for data collection from time-constrained IoT devices,”IEEE Transactions on Wireless Communications, vol. 19, no. 1, pp. 34–46, 2019
2019
-
[15]
AoI-minimal trajectory planning and data collection in UA V-assisted wireless powered IoT networks,
H. Hu, K. Xiong, G. Qu, Q. Ni, P. Fan, and K. B. Letaief, “AoI-minimal trajectory planning and data collection in UA V-assisted wireless powered IoT networks,”IEEE Internet of Things Journal, vol. 8, no. 2, pp. 1211– 1223, 2020
2020
-
[16]
A deep learning trained by genetic algorithm to improve the efficiency of path planning for data collection with multi-UA V,
Y . Pan, Y . Yang, and W. Li, “A deep learning trained by genetic algorithm to improve the efficiency of path planning for data collection with multi-UA V,”IEEE Access, vol. 9, pp. 7994–8005, 2021
2021
-
[17]
Playing Atari with Deep Reinforcement Learning
V . Mnih, “Playing atari with deep reinforcement learning,”arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review arXiv 2013
-
[18]
R. S. Sutton and A. G. Barto,Reinforcement learning: An introduction. MIT press, 2018
2018
-
[19]
UA V path planning for wireless data harvesting: A deep reinforcement learning approach,
H. Bayerlein, M. Theile, M. Caccamo, and D. Gesbert, “UA V path planning for wireless data harvesting: A deep reinforcement learning approach,” inGLOBECOM 2020-2020 IEEE Global Communications Conference. IEEE, 2020, pp. 1–6
2020
-
[20]
Distributed multi-UA V trajectory planning for downlink transmission: A GNN-enhanced DRL approach,
Y . Du, N. Qi, X. Li, M. Xiao, A.-A. A. Boulogeorgos, T. A. Tsiftsis, and Q. Wu, “Distributed multi-UA V trajectory planning for downlink transmission: A GNN-enhanced DRL approach,”IEEE Wireless Com- munications Letters, 2024
2024
-
[21]
Trajectory planning for UA V-assisted data collection in IoT network: A double deep Q network approach,
S. Wang, N. Qi, H. Jiang, M. Xiao, H. Liu, L. Jia, and D. Zhao, “Trajectory planning for UA V-assisted data collection in IoT network: A double deep Q network approach,”Electronics, vol. 13, no. 8, p. 1592, 2024
2024
-
[22]
3D UA V trajectory design and frequency band allocation for energy-efficient and fair communication: A deep reinforcement learning approach,
R. Ding, F. Gao, and X. S. Shen, “3D UA V trajectory design and frequency band allocation for energy-efficient and fair communication: A deep reinforcement learning approach,”IEEE Transactions on Wireless Communications, vol. 19, no. 12, pp. 7796–7809, 2020
2020
-
[23]
Intelligent joint trajectory design and resource allocation in UA V-based data harvesting system,
S. Luo, J. Liu, S. Chen, J. Chen, and J. Guo, “Intelligent joint trajectory design and resource allocation in UA V-based data harvesting system,” in2020 IEEE 16th International Conference on Control & Automation (ICCA). IEEE, 2020, pp. 1378–1383
2020
-
[24]
UA V trajectory planning in wireless sensor networks for energy consumption minimization by deep reinforcement learning,
B. Zhu, E. Bedeer, H. H. Nguyen, R. Barton, and J. Henry, “UA V trajectory planning in wireless sensor networks for energy consumption minimization by deep reinforcement learning,”IEEE Transactions on Vehicular Technology, vol. 70, no. 9, pp. 9540–9554, 2021
2021
-
[25]
Energy-efficient distributed mobile crowd sensing: A deep learning approach,
C. H. Liu, Z. Chen, and Y . Zhan, “Energy-efficient distributed mobile crowd sensing: A deep learning approach,”IEEE Journal on Selected Areas in Communications, vol. 37, no. 6, pp. 1262–1276, 2019
2019
-
[26]
AoI-energy-aware UA V- assisted data collection for IoT networks: A deep reinforcement learning method,
M. Sun, X. Xu, X. Qin, and P. Zhang, “AoI-energy-aware UA V- assisted data collection for IoT networks: A deep reinforcement learning method,”IEEE Internet of Things Journal, vol. 8, no. 24, pp. 17 275– 17 289, 2021
2021
-
[27]
Deep reinforcement learning for fresh data collection in UA V-assisted IoT networks,
M. Yi, X. Wang, J. Liu, Y . Zhang, and B. Bai, “Deep reinforcement learning for fresh data collection in UA V-assisted IoT networks,” in 14 IEEE INFOCOM 2020-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS). IEEE, 2020, pp. 716–721
2020
-
[28]
Gabriel Dulac-Arnold, Daniel Mankowitz, and Todd Hester
G. Dulac-Arnold, D. Mankowitz, and T. Hester, “Challenges of real- world reinforcement learning,”arXiv preprint arXiv:1904.12901, 2019
-
[29]
UA V swarm deploy- ment and trajectory for 3D area coverage via reinforcement learning,
J. He, Z. Jia, C. Dong, J. Liu, Q. Wu, and J. Liu, “UA V swarm deploy- ment and trajectory for 3D area coverage via reinforcement learning,” in 2023 International Conference on Wireless Communications and Signal Processing (WCSP). IEEE, 2023, pp. 683–688
2023
-
[30]
Elastic collaborative edge intelligence for UA V swarm: Architecture, challenges, and opportunities,
Y . Qu, H. Sun, C. Dong, J. Kang, H. Dai, Q. Wu, and S. Guo, “Elastic collaborative edge intelligence for UA V swarm: Architecture, challenges, and opportunities,”IEEE Communications Magazine, 2023
2023
-
[31]
Hierarchical reinforcement learning with the MAXQ value function decomposition,
T. G. Dietterich, “Hierarchical reinforcement learning with the MAXQ value function decomposition,”Journal of artificial intelligence re- search, vol. 13, pp. 227–303, 2000
2000
-
[32]
Hier- archical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation,
T. D. Kulkarni, K. Narasimhan, A. Saeedi, and J. Tenenbaum, “Hier- archical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation,”Advances in neural information processing systems, vol. 29, 2016
2016
-
[33]
The option-critic architecture,
P.-L. Bacon, J. Harb, and D. Precup, “The option-critic architecture,” in Proceedings of the AAAI conference on artificial intelligence, vol. 31, no. 1, 2017
2017
-
[34]
The UA V trajectory optimization for data collection from time-constrained IoT devices: A hierarchical deep Q-network approach,
Z. Qin, X. Zhang, X. Zhang, B. Lu, Z. Liu, and L. Guo, “The UA V trajectory optimization for data collection from time-constrained IoT devices: A hierarchical deep Q-network approach,”Applied Sciences, vol. 12, no. 5, p. 2546, 2022
2022
-
[35]
Hierarchical deep reinforcement learning for backscattering data collection with multiple UA Vs,
Y . Zhang, Z. Mou, F. Gao, L. Xing, J. Jiang, and Z. Han, “Hierarchical deep reinforcement learning for backscattering data collection with multiple UA Vs,”IEEE Internet of Things Journal, vol. 8, no. 5, pp. 3786–3800, 2020
2020
-
[36]
Research on the UA V-aided data collection and trajectory design based on the deep reinforcement learning,
M. Zhiyu, Y . Zhang, F. Dian, L. Jun, and G. Feifei, “Research on the UA V-aided data collection and trajectory design based on the deep reinforcement learning,”Chinese Journal on Internet of Things, vol. 4, no. 3, pp. 42–51, 2020
2020
-
[37]
Coalitional formation- based group-buying for UA V-enabled data collection: An auction game approach,
N. Qi, Z. Huang, W. Sun, S. Jin, and X. Su, “Coalitional formation- based group-buying for UA V-enabled data collection: An auction game approach,”IEEE Transactions on Mobile Computing, vol. 22, no. 12, pp. 7420–7437, 2022
2022
-
[38]
Energy- efficient UA V-relaying 5G/6G spectrum sharing networks: Interference coordination with power management and trajectory design,
W. Wang, N. Qi, L. Jia, C. Li, T. A. Tsiftsis, and M. Wang, “Energy- efficient UA V-relaying 5G/6G spectrum sharing networks: Interference coordination with power management and trajectory design,”IEEE Open Journal of the Communications Society, vol. 3, pp. 1672–1687, 2022
2022
-
[39]
Learning to communicate in UA V-aided wireless networks: Map-based approaches,
O. Esrafilian, R. Gangula, and D. Gesbert, “Learning to communicate in UA V-aided wireless networks: Map-based approaches,”IEEE Internet of Things Journal, vol. 6, no. 2, pp. 1791–1802, 2018
2018
-
[40]
Altitude and number optimisation for UA Vv-enabled wireless communications,
J. Zhang, T. Zhang, Z. Yang, B. Li, and Y . Wu, “Altitude and number optimisation for UA Vv-enabled wireless communications,”IET Commu- nications, vol. 14, no. 8, pp. 1228–1233, 2020
2020
-
[41]
Energy minimization for wireless communication with rotary-wing UA V,
Y . Zeng, J. Xu, and R. Zhang, “Energy minimization for wireless communication with rotary-wing UA V,”IEEE Transactions on Wireless Communications, vol. 18, no. 4, pp. 2329–2345, 2019
2019
-
[42]
UA V path planning using global and local map information with deep rein- forcement learning,
M. Theile, H. Bayerlein, R. Nai, D. Gesbert, and M. Caccamo, “UA V path planning using global and local map information with deep rein- forcement learning,” in2021 20th International Conference on Advanced Robotics (ICAR). IEEE, 2021, pp. 539–546
2021
-
[43]
DDPG-based aerial secure data collection,
H. Lei, H. Ran, I. S. Ansari, K.-H. Park, G. Pan, and M.-S. Alouini, “DDPG-based aerial secure data collection,”IEEE Transactions on Communications, vol. 72, no. 8, pp. 5179–5193, 2024
2024
-
[44]
SAC-based UA V mobile edge computing for energy minimization and secure data transmission,
X. Zhao, T. Zhao, F. Wang, Y . Wu, and M. Li, “SAC-based UA V mobile edge computing for energy minimization and secure data transmission,” Ad Hoc Networks, vol. 157, p. 103435, 2024. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1570870524000465 Zhenjia Xureceived the B.S. degree in commu- nication engineering from Nanjing Univer...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.