Recognition: unknown
Overcoming Copyright Barriers in Corpus Distribution Through Non-Reversible Hashing
Pith reviewed 2026-05-08 08:19 UTC · model grok-4.3
The pith
Non-reversible hashing of tokens enables public sharing of annotations on copyrighted novels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying a non-reversible hash function to the tokens of a copyrighted text, annotations can be released publicly; any user who possesses their own copy of the text can hash its tokens and recover the matching annotations with alignment accuracy between 98.7 and 99.79 percent, provided their edition is sufficiently similar to the one used by the corpus creator.
What carries the argument
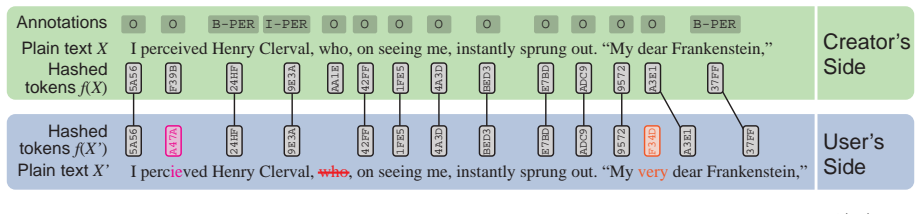
Non-reversible token hashing that produces fixed identifiers for each word or token, allowing exact matching to annotations without exposing the original text content.
If this is right
- Creators can release and exchange annotated corpora that contain copyrighted literary material without legal violation.
- Users need only a legal personal copy of the source text to locate and apply the shared annotations.
- Alignment accuracy stays high across minor textual differences such as those found in different published editions.
- A ready-to-use Python implementation is provided so the method can be applied immediately to new corpora.
Where Pith is reading between the lines
- The same hashing principle could be tested on other media such as scripts or articles if comparable token or segment identifiers can be defined.
- Wider use would increase the pool of openly available annotated data that reflects the full range of published language.
Load-bearing premise
A user's owned copy of the text must be close enough to the creator's version that hashing produces the same token identifiers at high accuracy, and the chosen hash function must remain non-reversible in practice.
What would settle it
An experiment on two close editions of the same novel where token alignment accuracy falls substantially below 98 percent, or a successful reversal of the hash function that reconstructs original token strings from the published hashes.
Figures








read the original abstract
While annotated corpora are crucial in the field of natural language processing (NLP), those containing copyrighted material are difficult to exchange among researchers. Yet, such corpora are necessary to fully represent the diversity of data found in the wild in the context of NLP tasks. We tackle this issue by proposing a method to lawfully and publicly share the annotations of copyrighted literary texts. The corpus creator shares the annotations in clear, along with a non-reversible hashed version of the source material. The corpus user must own the source material, and apply the same hash function to their own tokens, in order to match them to the shared annotations. Crucially, our method is robust to reasonable divergences in the version of the copyrighted data owned by the user. As an illustration, we present alignment experiments on different editions of novels. Our results show that our method is able to correctly align 98.7 to 99.79% of tokens depending on the novel, provided the user version is sufficiently close to the corpus creator's version. We publicly release novelshare, a Python implementation of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a method for distributing annotated corpora containing copyrighted literary texts by publicly sharing the annotations in plaintext alongside a non-reversible hashed version of the tokenized source material. Corpus users who already own a copy of the text apply the same public hash function to their own tokens and align them to the shared annotations. The approach is claimed to be robust to minor version differences between editions. Experiments on multiple editions of novels report token alignment accuracies ranging from 98.7% to 99.79%, and the authors release a Python implementation called novelshare.
Significance. If the non-reversibility claim were technically sound, the method would address a genuine practical barrier to sharing richly annotated NLP datasets that include copyrighted material. The reported alignment rates on real novels and the public code release would constitute useful engineering contributions for dataset creators. However, the central premise that a public deterministic per-token hash yields a non-reversible representation does not hold under standard cryptographic and information-theoretic analysis, which substantially reduces the practical and legal significance of the work.
major comments (2)
- [Abstract] Abstract and method description: the claim that the shared output is a 'non-reversible hashed version' is incorrect. Because the hash function must be public (so that users can apply it to their own tokens) and is applied deterministically to each token, an adversary can build a complete reverse mapping by hashing every token in the tokenizer vocabulary (or all common words) once and then looking up each hash in the shared sequence. This recovers the original token sequence without any access to the user's copy, directly contradicting the non-reversibility premise on which the lawful-distribution argument rests.
- [Abstract] Abstract and § on hash function (method section): no specific hash function is named, no security analysis or collision-resistance argument is provided, and no discussion addresses the bounded input space of a tokenizer vocabulary. These omissions are load-bearing because the entire distribution scheme depends on the hash remaining non-invertible in practice.
minor comments (1)
- [Experiments] The alignment experiments report concrete percentages but do not specify the exact novels, tokenizers, or divergence metrics used; adding these details would improve reproducibility even if the security issue is addressed.
Simulated Author's Rebuttal
We thank the referee for the thorough review and for identifying key issues with the description of our method. We agree that the original claims regarding non-reversibility were overstated and that the manuscript lacks necessary implementation details. We will revise the paper to correct these points while preserving the practical contribution of the alignment technique for users who own the source texts.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the claim that the shared output is a 'non-reversible hashed version' is incorrect. Because the hash function must be public (so that users can apply it to their own tokens) and is applied deterministically to each token, an adversary can build a complete reverse mapping by hashing every token in the tokenizer vocabulary (or all common words) once and then looking up each hash in the shared sequence. This recovers the original token sequence without any access to the user's copy, directly contradicting the non-reversibility premise on which the lawful-distribution argument rests.
Authors: We acknowledge the validity of this observation. A public deterministic hash over a finite vocabulary does permit precomputation of a reverse lookup table, allowing recovery of the token sequence from the shared hashes alone. This undermines the original phrasing of 'non-reversible' and the associated legal-distribution argument. In the revised manuscript we will eliminate all references to non-reversibility, describe the shared data simply as a hashed token sequence for alignment, and add an explicit limitations paragraph noting that the approach relies on users possessing their own copies of the source material rather than on cryptographic protection. We will also discuss the practical implications for dataset sharing. revision: yes
-
Referee: [Abstract] Abstract and § on hash function (method section): no specific hash function is named, no security analysis or collision-resistance argument is provided, and no discussion addresses the bounded input space of a tokenizer vocabulary. These omissions are load-bearing because the entire distribution scheme depends on the hash remaining non-invertible in practice.
Authors: We agree that the manuscript should have provided these details. The revised version will specify a concrete hash function (MurmurHash3 64-bit for alignment efficiency), include implementation pseudocode, and add a dedicated subsection on design choices. This subsection will address the bounded vocabulary explicitly, explain that inversion is feasible in principle, and clarify that the method's utility is intended for compliant users who already own the text rather than for adversarial resistance. We will remove any implication that the hash provides security guarantees. revision: yes
Circularity Check
No circularity: practical method with experimental validation, no derivations or self-referential steps
full rationale
The paper describes a hashing-based technique for sharing annotations on copyrighted texts, relying on users owning the source material and applying the same public hash function for alignment. Alignment accuracy is reported from direct experiments on novel editions (98.7–99.79% token match rates), not from any fitted parameters or predictions derived by construction. No equations, uniqueness theorems, ansatzes, or self-citations appear as load-bearing elements in the provided text. The non-reversibility claim is presented as a property of the chosen hash function rather than derived from prior results within the paper itself. This is a self-contained engineering proposal whose central claims rest on empirical alignment tests, not tautological reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Cryptographic hash functions are non-reversible and produce consistent outputs for identical inputs
Reference graph
Works this paper leans on
- [1]
-
[2]
In 2024 Joint International Conference on Computa- tional Linguistics, Language Resources and Evalua- tion (LREC-COLING 2024), LREC-COLING, page 2440–2446
Bln600: A parallel corpus of machine/human tran- scribed nineteenth century newspaper texts. In 2024 Joint International Conference on Computa- tional Linguistics, Language Resources and Evalua- tion (LREC-COLING 2024), LREC-COLING, page 2440–2446. X. Bost, V . Labatut, and G. Linares
2024
- [3]
- [4]
-
[5]
Dobb’s Journal, July 1988:46
Pattern match- ing: The gestalt approach.Dr. Dobb’s Journal, July 1988:46. E. F. Tjong Kim Sang and F. De Meulder
1988
-
[6]
In7th Confer- ence on Natural Language Learning, pages 142–147
Intro- duction to the CoNLL-2003 shared task: Language- independent named entity recognition. In7th Confer- ence on Natural Language Learning, pages 142–147. M. van de Camp and A. van den Bosch
2003
-
[7]
Deepseek-ocr: Con- texts optical compression.arXiv, cs.CV:2510.18234. H. Zhao, Y . Yan, S. Zhu, H. Liu, Y . Jia, H. Zan, and M. Peng
work page internal anchor Pith review arXiv
-
[8]
In particular, it forbids their unauthorized reproduction, in whole or in part (Article 9), and their communication to the public (Articles 11 & 11bis). Under directive2001/29/EC 3, European Union law forbids the direct or indirect unauthorized re- production of copyrighted works or substantial parts thereof (Article 2), and their unauthorized 2https://ww...
2001
-
[9]
These annotations are shared in plain text, but they are technical data, and not part of the original literary work
the associated annotations authored by the researchers creating the corpus. These annotations are shared in plain text, but they are technical data, and not part of the original literary work. Put differ- ently, they are distinct from the expressive content of the literary work (i.e. its actual words, narrative voice, the author’s stylistic choices). As s...
2019
-
[10]
concluded that Google 4https://ipcuria.eu/case?reference=C-5/08 5https://ipcuria.eu/case?reference=C-476/17 6https://www.copyright.gov/title17/ 7https://www.legislation.gov.uk/ukpga/1988/48/ contents 8https://eur-lex.europa.eu/eli/dir/2019/790/ oj/eng 9https://www.copyright.gov/fair-use/summaries/ authorsguild-google-2dcir2015.pdf Books’ scanning for inde...
1988
-
[11]
ForPride and Prejudice, we use Wikisource for both the first (PP-1813) and second (PP-1817) edi- tions in our experiments
to extract text from the book images hosted at the Melville Electronic Library. ForPride and Prejudice, we use Wikisource for both the first (PP-1813) and second (PP-1817) edi- tions in our experiments. We include the PP-1894 edition through project Gutenberg. Since this ver- sion is illustrated, the raw project Gutenberg text contain descriptions of the ...
1988
-
[12]
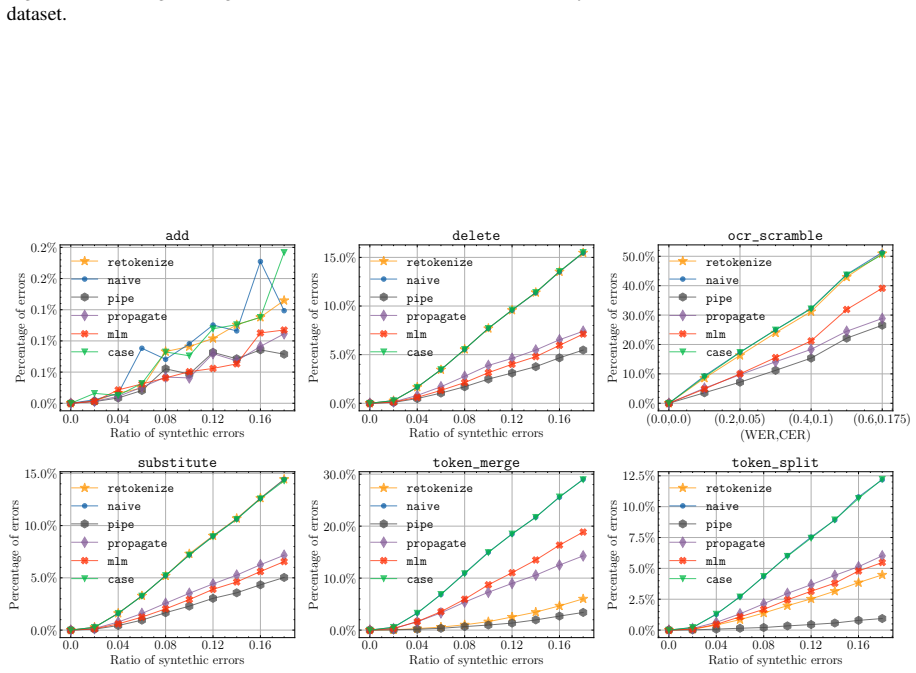
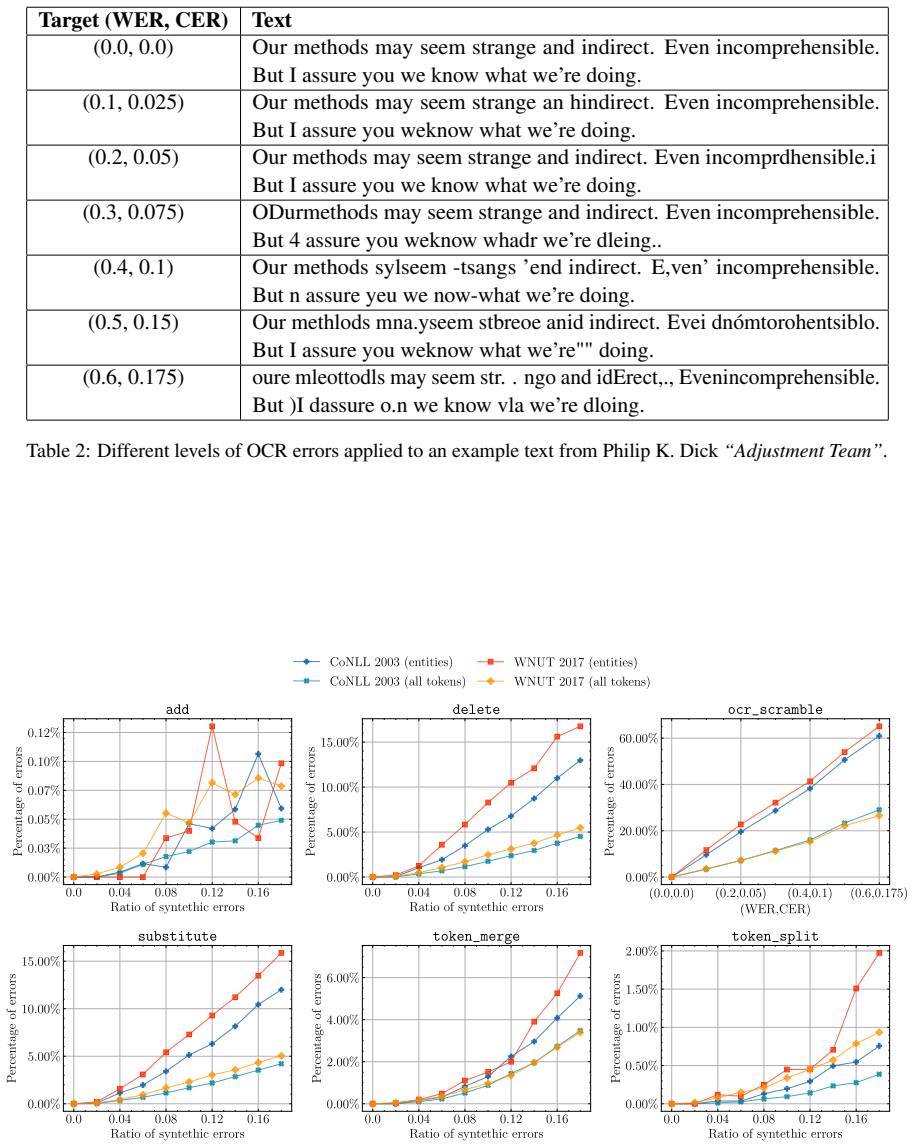
We empirically observe that errors beyond (0.2,0.05) (WER, CER) cor- respond to heavy OCR errors that are difficult to recover from. E Results on Other Domains To ensure that our technique is applicable to do- mains other than literary texts, we perform addi- tional experiments on known NLP corpora: CoNLL 2003 (Tjong Kim Sang and De Meulder,
2003
-
[13]
for the newswire domain and WNUT 2017 (Derczyn- ski et al.,
2017
-
[14]
For both of these datasets, we observe lower er- rors across the boards
and Figure 10 (WNUT 2017). For both of these datasets, we observe lower er- rors across the boards. This is at least partially due to the facts that these datasets are divided into examples that are smaller than chapters, facilitat- ing alignment. The relative comparison between strategies yield similar results than on our corpus of novels, showing their ...
2017
-
[15]
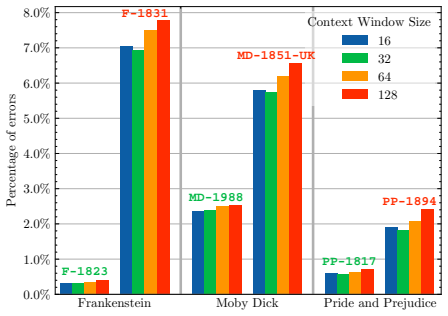
We use the MD-1988 edition ofMoby Dick, as it is the closest from the Novelties version
as the source version. We use the MD-1988 edition ofMoby Dick, as it is the closest from the Novelties version. We use a strict defini- tion of the notion of error: if a single token from an entity was not aligned, we consider the entire entity as non-aligned. We obtain a percentage of errors of 0.82% with our best strategy pipe, indi- cating that we are ...
1988
-
[16]
Adjustment Team
For both of these datasets, we see that entities are 0.0 0.04 0.08 0.12 0.16 Ratio of syntethic errors 0.0% 0.0% 0.0% 0.1%Percentage of errors add case naive pipe mlm retokenize propagate 0.0 0.04 0.08 0.12 0.16 Ratio of syntethic errors 0.0% 5.0% 10.0% 15.0%Percentage of errors delete case naive pipe mlm retokenize propagate (0.0,0.0) (0.2,0.05) (0.4,0.1...
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.