Recognition: unknown
When PINNs Go Wrong: Pseudo-Time Stepping Against Spurious Solutions
Pith reviewed 2026-05-08 06:37 UTC · model grok-4.3
The pith
An adaptive pseudo-time stepping method using a finite-difference Jacobian surrogate prevents PINNs from converging to spurious solutions and improves accuracy without manual tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
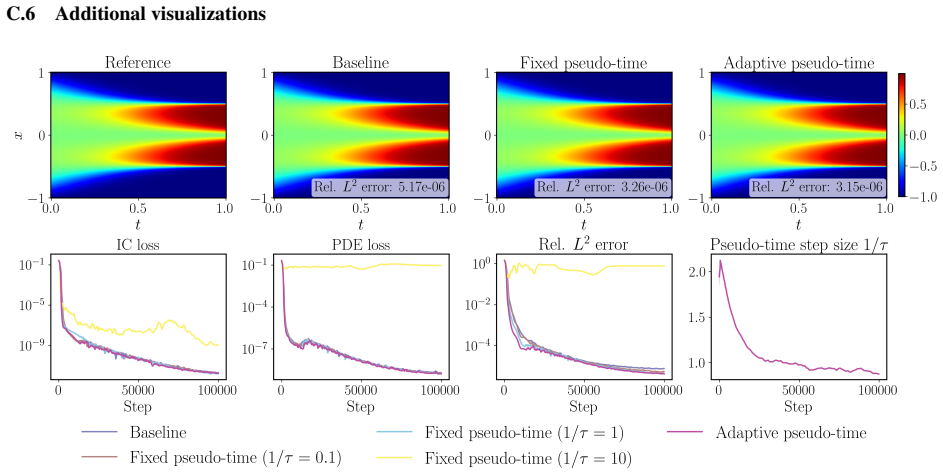
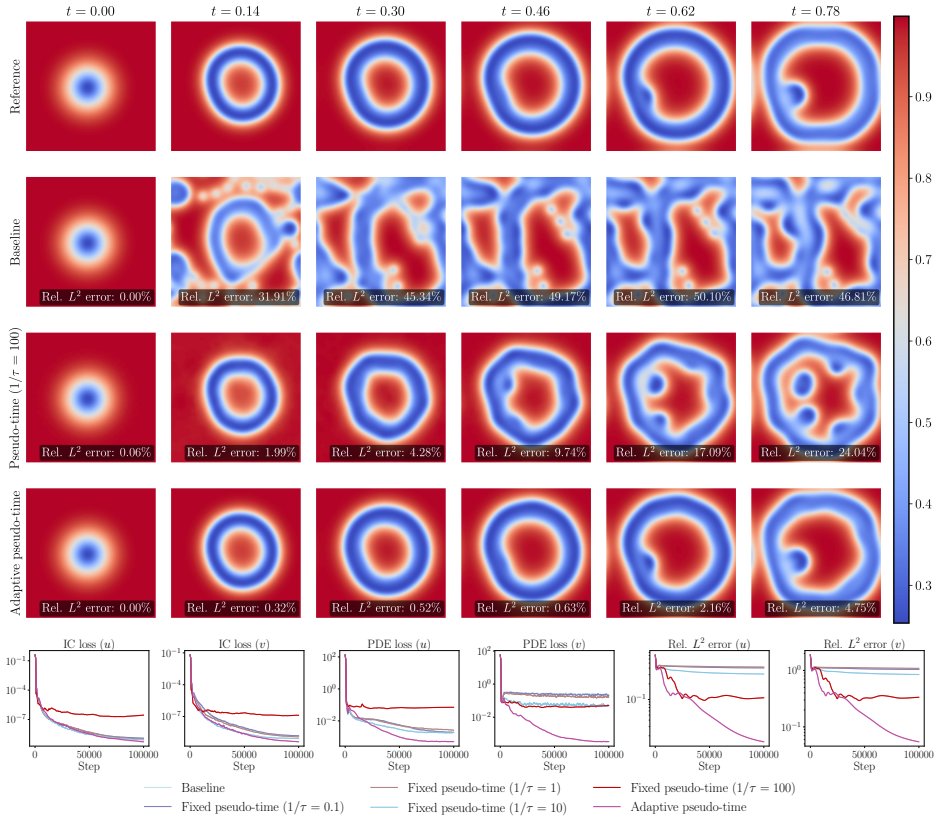
The empirical PDE residual loss used in PINNs can admit trivial or spurious solutions during training, leading to physically incorrect outputs despite small losses. Pseudo-time stepping, when paired with collocation-point resampling, helps reveal and avoid these solutions rather than merely easing optimization. Its effectiveness hinges on step size, which cannot be reliably set from the loss; the proposed adaptive strategy uses a finite-difference surrogate of the local residual Jacobian to select the largest stable step without per-problem tuning, resulting in improved accuracy and robustness on diverse PDE benchmarks.
What carries the argument
The adaptive pseudo-time stepping strategy that selects the step size from a finite-difference surrogate of the local residual Jacobian to ensure the largest stable step permitted by local stability.
If this is right
- The method reduces convergence to physically incorrect solutions on challenging PDE problems.
- It removes the need for manual per-problem tuning of the pseudo-time step size.
- Accuracy and robustness improve consistently across a range of PDE benchmarks.
- When combined with collocation-point resampling, it effectively reveals and avoids spurious solutions.
- It provides a practical pathway toward more reliable physics-informed neural network training.
Where Pith is reading between the lines
- This view implies that some reported PINN successes on hard problems may reflect lucky avoidance of prominent spurious minima rather than true optimization progress.
- The Jacobian-surrogate idea could be tested on other time-dependent or optimization parameters in PINN variants beyond step size.
- The approach raises whether the residual loss itself can be regularized to exclude known classes of spurious solutions without relying on stepping.
- Extensions might apply the same stability-based adaptation to related physics-informed models such as neural operators or deep Ritz methods.
Load-bearing premise
The finite-difference surrogate of the local residual Jacobian reliably indicates the largest stable step size without introducing its own approximation errors that could destabilize training.
What would settle it
A concrete counterexample would be a PDE benchmark where the adaptive method still converges to a known spurious solution despite small residuals or shows no accuracy gain over fixed-step pseudo-time stepping or standard PINN training.
Figures
















read the original abstract
Physics-informed neural networks (PINNs) provide a promising machine learning framework for solving partial differential equations, but their training often breaks down on challenging problems, sometimes converging to physically incorrect solutions despite achieving small residual losses. This failure, we argue, is not merely an optimization difficulty. Rather, it reflects a fundamental weakness of the empirical PDE residual loss, which can admit trivial or spurious solutions during training. From this perspective, we revisit pseudo-time stepping, a technique that has recently shown strong empirical success in PINNs. We show that its main benefit is not simply to ease optimization; instead, when combined with collocation-point resampling, it helps reveal and avoid spurious solutions. At the same time, we find that the effectiveness of pseudo-time stepping depends critically on the choice of step size, which cannot be tuned reliably from the training loss alone. To overcome this limitation, we propose an adaptive pseudo-time stepping strategy that selects the step size from a finite-difference surrogate of the local residual Jacobian, yielding the largest step permitted by local stability without per-problem tuning. Across a diverse set of PDE benchmarks, the proposed method consistently improves both accuracy and robustness. Together, these findings provide a clearer understanding of why PINNs fail and suggest a practical pathway toward more reliable physics-informed learning. All code and data accompanying this manuscript are available at https://github.com/sifanexisted/jaxpi2.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that PINNs can converge to physically spurious solutions despite achieving small empirical residual losses, that this stems from a fundamental limitation of the residual loss rather than pure optimization failure, and that pseudo-time stepping combined with collocation resampling mitigates the issue. It further proposes an adaptive pseudo-time stepping scheme that selects the largest locally stable step size via a finite-difference surrogate of the residual Jacobian, eliminating the need for per-problem tuning, and reports consistent accuracy and robustness gains across a diverse set of PDE benchmarks, with all code and data released.
Significance. If the central empirical findings hold and the adaptive rule proves reliable, the work would supply both a diagnostic perspective on why standard PINN training admits spurious solutions and a practical, largely tuning-free improvement to pseudo-time stepping. The open-source implementation and multi-benchmark evaluation constitute concrete strengths that would aid reproducibility and further testing.
major comments (3)
- [§3.2] §3.2 (adaptive step-size rule): The finite-difference surrogate of the local residual Jacobian is asserted to yield the largest stable pseudo-time step without per-problem tuning, yet no theoretical bound or sensitivity analysis is given for the approximation error induced by the perturbation size; this is load-bearing because the method's claimed robustness rests on the surrogate reliably indicating stability limits in stiff or high-dimensional regimes.
- [§4.1] §4.1 and Table 1: The reported gains in accuracy and robustness are demonstrated empirically across benchmarks, but the manuscript does not quantify how the finite-difference perturbation hyperparameter was chosen or whether its value was held fixed versus tuned per problem; without this, it remains unclear whether the adaptive rule truly operates without tuning or whether hidden per-problem choices contribute to the observed improvements.
- [§2.3] §2.3 (spurious-solution mechanism): The argument that the residual loss admits trivial or spurious solutions is supported by illustrative examples, but the paper does not provide a general characterization or sufficient condition under which such solutions exist for a given PDE; this weakens the claim that pseudo-time stepping plus resampling systematically reveals and avoids them rather than merely improving optimization on the tested cases.
minor comments (2)
- Notation for the residual Jacobian surrogate (e.g., the finite-difference operator) is introduced without an explicit equation number, making it harder to trace the exact implementation from the text to the released code.
- Figure 3 caption should clarify whether the plotted trajectories correspond to the same random seed or averaged over multiple runs, as this affects interpretation of robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which have helped clarify several aspects of the work. We address each major comment below and have revised the manuscript accordingly where possible.
read point-by-point responses
-
Referee: [§3.2] §3.2 (adaptive step-size rule): The finite-difference surrogate of the local residual Jacobian is asserted to yield the largest stable pseudo-time step without per-problem tuning, yet no theoretical bound or sensitivity analysis is given for the approximation error induced by the perturbation size; this is load-bearing because the method's claimed robustness rests on the surrogate reliably indicating stability limits in stiff or high-dimensional regimes.
Authors: We acknowledge that a theoretical bound on the finite-difference approximation error is not provided. In the revised manuscript we have added a new sensitivity analysis subsection in §3.2 together with an accompanying figure. This analysis shows that the adaptive rule produces consistent results for perturbation sizes in [10^{-5}, 10^{-3}] across the benchmark suite, supporting practical robustness even though a full theoretical error bound remains an open question. revision: yes
-
Referee: [§4.1] §4.1 and Table 1: The reported gains in accuracy and robustness are demonstrated empirically across benchmarks, but the manuscript does not quantify how the finite-difference perturbation hyperparameter was chosen or whether its value was held fixed versus tuned per problem; without this, it remains unclear whether the adaptive rule truly operates without tuning or whether hidden per-problem choices contribute to the observed improvements.
Authors: The perturbation size was fixed at 10^{-4} for every experiment and every benchmark; no per-problem tuning was performed. This value was selected via preliminary tests on the 1D Burgers equation to ensure stable finite-difference approximations. We have now explicitly documented the fixed value, the selection procedure, and the absence of per-problem adjustments in the revised §4.1. revision: yes
-
Referee: [§2.3] §2.3 (spurious-solution mechanism): The argument that the residual loss admits trivial or spurious solutions is supported by illustrative examples, but the paper does not provide a general characterization or sufficient condition under which such solutions exist for a given PDE; this weakens the claim that pseudo-time stepping plus resampling systematically reveals and avoids them rather than merely improving optimization on the tested cases.
Authors: We agree that a general sufficient condition applicable to arbitrary PDEs would strengthen the theoretical motivation. Deriving such a condition, however, is a substantial theoretical undertaking that lies outside the scope of the present paper, whose focus is the empirical identification of the issue and the practical adaptive method. The examples in §2.3 concretely demonstrate the mechanism, and the method's ability to avoid spurious solutions is shown empirically across diverse benchmarks. We have expanded the discussion in the revised §2.3 to acknowledge this limitation and outline possible future directions. revision: partial
- A general sufficient condition for the existence of spurious solutions for arbitrary PDEs
Circularity Check
No significant circularity; adaptive step-size rule grounded in independent finite-difference stability surrogate
full rationale
The paper's central derivation proposes an adaptive pseudo-time step size chosen as the largest locally stable value via a finite-difference surrogate of the residual Jacobian. This construction is independent of the training loss (explicitly noted as unreliable for tuning) and is not obtained by fitting parameters to data, self-definition, or renaming. The premise that pseudo-time stepping helps avoid spurious solutions is supported by the combination with collocation resampling and benchmark results rather than reducing to prior self-citations. No equation or claim equates the output directly to its inputs by construction; the method remains falsifiable on new PDE problems.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The empirical PDE residual loss can admit trivial or spurious solutions during training.
- ad hoc to paper A finite-difference surrogate of the local residual Jacobian provides a reliable indicator of the largest stable pseudo-time step.
Reference graph
Works this paper leans on
-
[1]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics, 378:686–707, 2019
2019
-
[2]
Physics- informed machine learning.Nature Reviews Physics, pages 1–19, 2021
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics- informed machine learning.Nature Reviews Physics, pages 1–19, 2021
2021
-
[3]
arXiv preprint arXiv:2507.08972 , year=
Sifan Wang, Shyam Sankaran, Xiantao Fan, Panos Stinis, and Paris Perdikaris. Simulating three-dimensional turbulence with physics-informed neural networks.arXiv preprint arXiv:2507.08972, 2025
-
[4]
A physics-informed deep learning framework for inversion and surrogate modeling in solid mechanics.Computer Methods in Applied Mechanics and Engineering, 379:113741, 2021
Ehsan Haghighat, Maziar Raissi, Adrian Moure, Hector Gomez, and Ruben Juanes. A physics-informed deep learning framework for inversion and surrogate modeling in solid mechanics.Computer Methods in Applied Mechanics and Engineering, 379:113741, 2021
2021
-
[5]
Physics-informed neural networks for inverse problems in nano-optics and metamaterials.Optics express, 28(8):11618–11633, 2020
Yuyao Chen, Lu Lu, George Em Karniadakis, and Luca Dal Negro. Physics-informed neural networks for inverse problems in nano-optics and metamaterials.Optics express, 28(8):11618–11633, 2020
2020
-
[6]
Physics-informed neural networks for multiphysics data assimilation with application to subsurface transport.Advances in Water Resources, 141:103610, 2020
QiZhi He, David Barajas-Solano, Guzel Tartakovsky, and Alexandre M Tartakovsky. Physics-informed neural networks for multiphysics data assimilation with application to subsurface transport.Advances in Water Resources, 141:103610, 2020
2020
-
[7]
B-pinns: Bayesian physics-informed neural networks for forward and inverse pde problems with noisy data.Journal of Computational Physics, 425:109913, 2021
Liu Yang, Xuhui Meng, and George Em Karniadakis. B-pinns: Bayesian physics-informed neural networks for forward and inverse pde problems with noisy data.Journal of Computational Physics, 425:109913, 2021
2021
-
[8]
Bayesian physics informed neural networks for real-world nonlinear dynamical systems.Computer Methods in Applied Mechanics and Engineering, 402:115346, 2022
Kevin Linka, Amelie Schäfer, Xuhui Meng, Zongren Zou, George Em Karniadakis, and Ellen Kuhl. Bayesian physics informed neural networks for real-world nonlinear dynamical systems.Computer Methods in Applied Mechanics and Engineering, 402:115346, 2022
2022
-
[9]
Deep hidden physics models: Deep learning of nonlinear partial differential equations.The Journal of Machine Learning Research, 19(1):932–955, 2018
Maziar Raissi. Deep hidden physics models: Deep learning of nonlinear partial differential equations.The Journal of Machine Learning Research, 19(1):932–955, 2018. 18
2018
-
[10]
Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations.Science, 367(6481):1026–1030, 2020
Maziar Raissi, Alireza Yazdani, and George Em Karniadakis. Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations.Science, 367(6481):1026–1030, 2020
2020
-
[11]
Deep learning the flow law of antarctic ice shelves.Science, 387(6739):1219–1224, 2025
Yongji Wang, Ching-Yao Lai, David J Prior, and Charlie Cowen-Breen. Deep learning the flow law of antarctic ice shelves.Science, 387(6739):1219–1224, 2025
2025
-
[12]
Physics-informed deep learning for incompressible laminar flows
Chengping Rao, Hao Sun, and Yang Liu. Physics-informed deep learning for incompressible laminar flows. Theoretical and Applied Mechanics Letters, 10(3):207–212, 2020
2020
-
[13]
Physics-informed neural networks for heat transfer problems.Journal of Heat Transfer, 143(6), 2021
Shengze Cai, Zhicheng Wang, Sifan Wang, Paris Perdikaris, and George Em Karniadakis. Physics-informed neural networks for heat transfer problems.Journal of Heat Transfer, 143(6), 2021
2021
-
[14]
Analyses of internal structures and defects in materials using physics-informed neural networks.Science advances, 8(7):eabk0644, 2022
Enrui Zhang, Ming Dao, George Em Karniadakis, and Subra Suresh. Analyses of internal structures and defects in materials using physics-informed neural networks.Science advances, 8(7):eabk0644, 2022
2022
-
[15]
Yu Diao, Jianchuan Yang, Ying Zhang, Dawei Zhang, and Yiming Du. Solving multi-material problems in solid mechanics using physics-informed neural networks based on domain decomposition technology.Computer Methods in Applied Mechanics and Engineering, 413:116120, 2023
2023
-
[16]
Physics-informed neural networks for studying heat transfer in porous media
Jiaxuan Xu, Han Wei, and Hua Bao. Physics-informed neural networks for studying heat transfer in porous media. International Journal of Heat and Mass Transfer, 217:124671, 2023
2023
-
[17]
Ruiyang Li, Jiahang Zhou, Jian-Xun Wang, and Tengfei Luo. Physics-informed bayesian neural networks for solving phonon boltzmann transport equation in forward and inverse problems with sparse and noisy data.ASME Journal of Heat and Mass Transfer, 147(3):032501, 2025
2025
-
[18]
Physics- informed neural networks for a lithium-ion batteries model: A case of study.Advances in Computational Science & Engineering (ACSE), 2(4), 2024
Francesco Colace, Dajana Conte, Giovanni Pagano, Beatrice Paternoster, and Carmine Valentino. Physics- informed neural networks for a lithium-ion batteries model: A case of study.Advances in Computational Science & Engineering (ACSE), 2(4), 2024
2024
-
[19]
Physics informed neural networks reveal valid models for reactive diffusion of volatiles through paper.Chemical Engineering Science, 285:119636, 2024
Alexandra Serebrennikova, Raimund Teubler, Lisa Hoffellner, Erich Leitner, Ulrich Hirn, and Karin Zojer. Physics informed neural networks reveal valid models for reactive diffusion of volatiles through paper.Chemical Engineering Science, 285:119636, 2024
2024
-
[20]
Physics-informed neural networks for transcranial ultrasound wave propagation.Ultrasonics, 132:107026, 2023
Linfeng Wang, Hao Wang, Lin Liang, Jian Li, Zhoumo Zeng, and Yang Liu. Physics-informed neural networks for transcranial ultrasound wave propagation.Ultrasonics, 132:107026, 2023
2023
-
[21]
Physics-informed deep neural networks for learning parameters and constitutive relationships in subsurface flow problems.Water Resources Research, 56(5):e2019WR026731, 2020
AM Tartakovsky, C Ortiz Marrero, Paris Perdikaris, GD Tartakovsky, and D Barajas-Solano. Physics-informed deep neural networks for learning parameters and constitutive relationships in subsurface flow problems.Water Resources Research, 56(5):e2019WR026731, 2020
2020
-
[22]
Physics informed deep learning for flow and transport in porous media
Cedric G Fraces and Hamdi Tchelepi. Physics informed deep learning for flow and transport in porous media. In SPE Reservoir Simulation Conference, page D011S006R002. SPE, 2021
2021
-
[23]
P Haruzi and Z Moreno. Modeling water flow and solute transport in unsaturated soils using physics-informed neural networks trained with geoelectrical data.Water Resources Research, 59(6):e2023WR034538, 2023
2023
-
[24]
Georgios Kissas, Yibo Yang, Eileen Hwuang, Walter R Witschey, John A Detre, and Paris Perdikaris. Machine learning in cardiovascular flows modeling: Predicting arterial blood pressure from non-invasive 4D flow MRI data using physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 358:112623, 2020
2020
-
[25]
Physics-informed neural networks for modeling physiological time series for cuffless blood pressure estimation.npj Digital Medicine, 6(1):110, 2023
Kaan Sel, Amirmohammad Mohammadi, Roderic I Pettigrew, and Roozbeh Jafari. Physics-informed neural networks for modeling physiological time series for cuffless blood pressure estimation.npj Digital Medicine, 6(1):110, 2023
2023
-
[26]
Olzhas Mukhmetov, Yong Zhao, Aigerim Mashekova, Vasilios Zarikas, Eddie Yin Kwee Ng, and Nurduman Aidossov. Physics-informed neural network for fast prediction of temperature distributions in cancerous breasts as a potential efficient portable ai-based diagnostic tool.Computer methods and programs in biomedicine, 242:107834, 2023
2023
-
[27]
Ameya D Jagtap and George Em Karniadakis. Extended physics-informed neural networks (XPINNs): A generalized space-time domain decomposition based deep learning framework for nonlinear partial differential equations.Communications in Computational Physics, 28(5):2002–2041, 2020
2002
-
[28]
Piratenets: Physics-informed deep learning with residual adaptive networks.Journal of Machine Learning Research, 25(402):1–51, 2024
Sifan Wang, Bowen Li, Yuhan Chen, and Paris Perdikaris. Piratenets: Physics-informed deep learning with residual adaptive networks.Journal of Machine Learning Research, 25(402):1–51, 2024
2024
-
[29]
Ben Moseley, Andrew Markham, and Tarje Nissen-Meyer. Finite basis physics-informed neural networks (fbpinns): a scalable domain decomposition approach for solving differential equations.arXiv preprint arXiv:2107.07871, 2021. 19
-
[30]
Zhiyuan Zhao, Xueying Ding, and B Aditya Prakash. Pinnsformer: A transformer-based framework for physics- informed neural networks.arXiv preprint arXiv:2307.11833, 2023
-
[31]
Levi McClenny and Ulisses Braga-Neto. Self-adaptive physics-informed neural networks using a soft attention mechanism.arXiv preprint arXiv:2009.04544, 2020
-
[32]
When and why PINNs fail to train: A neural tangent kernel perspective.Journal of Computational Physics, 449:110768, 2022
Sifan Wang, Xinling Yu, and Paris Perdikaris. When and why PINNs fail to train: A neural tangent kernel perspective.Journal of Computational Physics, 449:110768, 2022
2022
-
[33]
Multi-objective loss balancing for physics-informed deep learning.Computer Methods in Applied Mechanics and Engineering, 439:117914, 2025
Rafael Bischof and Michael A Kraus. Multi-objective loss balancing for physics-informed deep learning.Computer Methods in Applied Mechanics and Engineering, 439:117914, 2025
2025
-
[34]
Pratik Rathore, Weimu Lei, Zachary Frangella, Lu Lu, and Madeleine Udell. Challenges in training pinns: A loss landscape perspective.arXiv preprint arXiv:2402.01868, 2024
-
[35]
Achieving high accuracy with pinns via energy natural gradient descent
Johannes Müller and Marius Zeinhofer. Achieving high accuracy with pinns via energy natural gradient descent. InInternational Conference on Machine Learning, pages 25471–25485. PMLR, 2023
2023
-
[36]
Gradient alignment in physics-informed neural networks: A second-order optimization perspective
Sifan Wang, Ananyae Kumar bhartari, Bowen Li, and Paris Perdikaris. Gradient alignment in physics-informed neural networks: A second-order optimization perspective. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[37]
Chenxi Wu, Min Zhu, Qinyang Tan, Yadhu Kartha, and Lu Lu. A comprehensive study of non-adaptive and residual-based adaptive sampling for physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 403:115671, 2023
2023
-
[38]
Failure-informed adaptive sampling for pinns.SIAM Journal on Scientific Computing, 45(4):A1971–A1994, 2023
Zhiwei Gao, Liang Yan, and Tao Zhou. Failure-informed adaptive sampling for pinns.SIAM Journal on Scientific Computing, 45(4):A1971–A1994, 2023
2023
-
[39]
Zhiping Mao and Xuhui Meng. Physics-informed neural networks with residual/gradient-based adaptive sampling methods for solving partial differential equations with sharp solutions.Applied Mathematics and Mechanics, 44(7):1069–1084, 2023
2023
-
[40]
Arka Daw, Jie Bu, Sifan Wang, Paris Perdikaris, and Anuj Karpatne. Mitigating propagation failures in physics- informed neural networks using retain-resample-release (r3) sampling.arXiv preprint arXiv:2207.02338, 2022
-
[41]
Sifan Wang, Hanwen Wang, and Paris Perdikaris. On the eigenvector bias of fourier feature networks: From regression to solving multi-scale PDEs with physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 384:113938, 2021
2021
-
[42]
Physics-informed neural networks for high-frequency and multi-scale problems using transfer learning.Applied Sciences, 14(8):3204, 2024
Abdul Hannan Mustajab, Hao Lyu, Zarghaam Rizvi, and Frank Wuttke. Physics-informed neural networks for high-frequency and multi-scale problems using transfer learning.Applied Sciences, 14(8):3204, 2024
2024
-
[43]
Understanding and mitigating gradient flow pathologies in physics-informed neural networks.SIAM Journal on Scientific Computing, 43(5):A3055–A3081, 2021
Sifan Wang, Yujun Teng, and Paris Perdikaris. Understanding and mitigating gradient flow pathologies in physics-informed neural networks.SIAM Journal on Scientific Computing, 43(5):A3055–A3081, 2021
2021
-
[44]
Residual- based attention in physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 421:116805, 2024
Sokratis J Anagnostopoulos, Juan Diego Toscano, Nikolaos Stergiopulos, and George Em Karniadakis. Residual- based attention in physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 421:116805, 2024
2024
-
[45]
Qiang Liu, Mengyu Chu, and Nils Thuerey. Config: Towards conflict-free training of physics informed neural networks.arXiv preprint arXiv:2408.11104, 2024
-
[46]
In: Advances in Neural Information Processing Systems, vol
Aditi S Krishnapriyan, Amir Gholami, Shandian Zhe, Robert M Kirby, and Michael W Mahoney. Characterizing possible failure modes in physics-informed neural networks.arXiv preprint arXiv:2109.01050, 2021
-
[47]
Michael Penwarden, Ameya D Jagtap, Shandian Zhe, George Em Karniadakis, and Robert M Kirby. A unified scalable framework for causal sweeping strategies for physics-informed neural networks (pinns) and their temporal decompositions.Journal of Computational Physics, 493:112464, 2023
2023
-
[48]
Respecting causality for training physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 421:116813, 2024
Sifan Wang, Shyam Sankaran, and Paris Perdikaris. Respecting causality for training physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 421:116813, 2024
2024
-
[49]
Exact enforcement of temporal continuity in sequential physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 430:117197, 2024
Pratanu Roy and Stephen T Castonguay. Exact enforcement of temporal continuity in sequential physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 430:117197, 2024
2024
-
[50]
Convergence analysis of pseudo-transient continuation.SIAM Journal on Numerical Analysis, 35(2):508–523, 1998
Carl Timothy Kelley and David E Keyes. Convergence analysis of pseudo-transient continuation.SIAM Journal on Numerical Analysis, 35(2):508–523, 1998
1998
-
[51]
Wenbo Cao and Weiwei Zhang. Tsonn: Time-stepping-oriented neural network for solving partial differential equations.arXiv preprint arXiv:2310.16491, 2023. 20
-
[52]
A pseudo-time stepping and parameterized physics-informed neural network framework for navier–stokes equations.Physics of Fluids, 37(3), 2025
Zhuo Zhang, Xiong Xiong, Sen Zhang, Wei Wang, Xi Yang, Shilin Zhang, and Canqun Yang. A pseudo-time stepping and parameterized physics-informed neural network framework for navier–stokes equations.Physics of Fluids, 37(3), 2025
2025
-
[53]
Two-point step size gradient methods.IMA journal of numerical analysis, 8(1):141–148, 1988
Jonathan Barzilai and Jonathan M Borwein. Two-point step size gradient methods.IMA journal of numerical analysis, 8(1):141–148, 1988
1988
-
[54]
SIAM, 2008
Andreas Griewank and Andrea Walther.Evaluating derivatives: principles and techniques of algorithmic differentiation. SIAM, 2008
2008
-
[55]
About modifications of the loss function for the causal training of physics- informed neural networks
Vasilii Alekseevich Es’ kin, DV Davydov, Ekaterina Dmitrievna Egorova, Alexey Olegovich Malkhanov, Mikhail A Akhukov, and Mikhail E Smorkalov. About modifications of the loss function for the causal training of physics- informed neural networks. InDoklady Mathematics, volume 110, pages S172–S192. Springer, 2024
2024
-
[56]
Chenhui Xu, Dancheng Liu, Amir Nassereldine, and Jinjun Xiong. Fp64 is all you need: rethinking failure modes in physics-informed neural networks.arXiv preprint arXiv:2505.10949, 2025
-
[57]
Self-adaptive physics-informed neural networks.Journal of Computational Physics, 474:111722, 2023
Levi D McClenny and Ulisses M Braga-Neto. Self-adaptive physics-informed neural networks.Journal of Computational Physics, 474:111722, 2023
2023
-
[58]
Optimizing the optimizer for physics-informed neural networks and kolmogorov-arnold networks.Computer Methods in Applied Mechanics and Engineering, 446:118308, 2025
Elham Kiyani, Khemraj Shukla, Jorge F Urbán, Jérôme Darbon, and George Em Karniadakis. Optimizing the optimizer for physics-informed neural networks and kolmogorov-arnold networks.Computer Methods in Applied Mechanics and Engineering, 446:118308, 2025
2025
-
[59]
Pseudotransient continuation and differential-algebraic equations.SIAM Journal on Scientific Computing, 25(2):553–569, 2003
Todd S Coffey, Carl Tim Kelley, and David E Keyes. Pseudotransient continuation and differential-algebraic equations.SIAM Journal on Scientific Computing, 25(2):553–569, 2003
2003
-
[60]
Surrogate modeling of multi-dimensional premixed and non-premixed combustion using pseudo-time stepping physics-informed neural networks.Physics of Fluids, 36(11), 2024
Zhen Cao, Kai Liu, Kun Luo, Sifan Wang, Liang Jiang, and Jianren Fan. Surrogate modeling of multi-dimensional premixed and non-premixed combustion using pseudo-time stepping physics-informed neural networks.Physics of Fluids, 36(11), 2024
2024
-
[61]
Pao-Hsiung Chiu, Jian Cheng Wong, Chin Chun Ooi, Chang Wei, Yuchen Fan, and Yew-Soon Ong. Scale- pinn: Learning efficient physics-informed neural networks through sequential correction.arXiv preprint arXiv:2602.19475, 2026
-
[62]
Chang Wei, Yuchen Fan, Chin Chun Ooi, Jian Cheng Wong, Heyang Wang, and Pao-Hsiung Chiu. Bridging computational fluid dynamics algorithm and physics-informed learning: Simple-pinn for incompressible navier- stokes equations.arXiv preprint arXiv:2603.24013, 2026
-
[63]
SOAP: Improving and Stabilizing Shampoo using Adam
Nikhil Vyas, Depen Morwani, Rosie Zhao, Itai Shapira, David Brandfonbrener, Lucas Janson, and Sham Kakade. Soap: Improving and stabilizing shampoo using adam.arXiv preprint arXiv:2409.11321, 2024
work page internal anchor Pith review arXiv 2024
-
[64]
An expert’s guide to training physics-informed neural networks.arXiv preprint arXiv:2308.08468, 2023
Sifan Wang, Shyam Sankaran, Hanwen Wang, and Paris Perdikaris. An expert’s guide to training physics-informed neural networks.arXiv preprint arXiv:2308.08468, 2023
-
[65]
A method for representing periodic functions and enforcing exactly periodic boundary conditions with deep neural networks.Journal of Computational Physics, 435:110242, 2021
Suchuan Dong and Naxian Ni. A method for representing periodic functions and enforcing exactly periodic boundary conditions with deep neural networks.Journal of Computational Physics, 435:110242, 2021
2021
-
[66]
Matthew Tancik, Pratul P Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains.arXiv preprint arXiv:2006.10739, 2020
-
[67]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review arXiv 2014
-
[68]
Chebfun guide, 2014
Tobin A Driscoll, Nicholas Hale, and Lloyd N Trefethen. Chebfun guide, 2014
2014
-
[69]
Ketcheson, Kyle T
David I. Ketcheson, Kyle T. Mandli, Aron J. Ahmadia, Amal Alghamdi, Manuel Quezada de Luna, Matteo Parsani, Matthew G. Knepley, and Matthew Emmett. PyClaw: Accessible, Extensible, Scalable Tools for Wave Propagation Problems.SIAM Journal on Scientific Computing, 34(4):C210–C231, November 2012
2012
-
[70]
Economon, Francisco Palacios, Sean R
Thomas D. Economon, Francisco Palacios, Sean R. Copeland, Trent W. Lukaczyk, and Juan J. Alonso. Su2: An open-source suite for multiphysics simulation and design.AIAA Journal, 54(3):828–846, 2016
2016
-
[71]
Bezgin, Aaron B
Deniz A. Bezgin, Aaron B. Buhendwa, and Nikolaus A. Adams. Jax-fluids: A fully-differentiable high-order computational fluid dynamics solver for compressible two-phase flows.Computer Physics Communications, 282:108527, 1 2023
2023
-
[72]
solitons
Norman J Zabusky and Martin D Kruskal. Interaction of" solitons" in a collisionless plasma and the recurrence of initial states.Physical review letters, 15(6):240, 1965. 21 A Nomenclature Table 3: Notation used throughout the paper. Symbol Type Description Domain and geometry Ω⊂R d domain Bounded spatial domain with regular boundary∂Ω ∂Ωboundary Boundary ...
1965
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.