QED: An Open-Source Multi-Agent System for Generating Mathematical Proofs on Open Problems
Pith reviewed 2026-05-25 06:50 UTC · model grok-4.3
The pith
QED is a multi-agent system that converts open research questions into complete, verified mathematical proofs without further human input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
QED shows that a pipeline of decomposition, prover, and verifier agents can take human-formulated research questions and output original, expert-validated mathematical proofs across several domains, yielding five new works three of which match the standard of established specialist venues.
What carries the argument
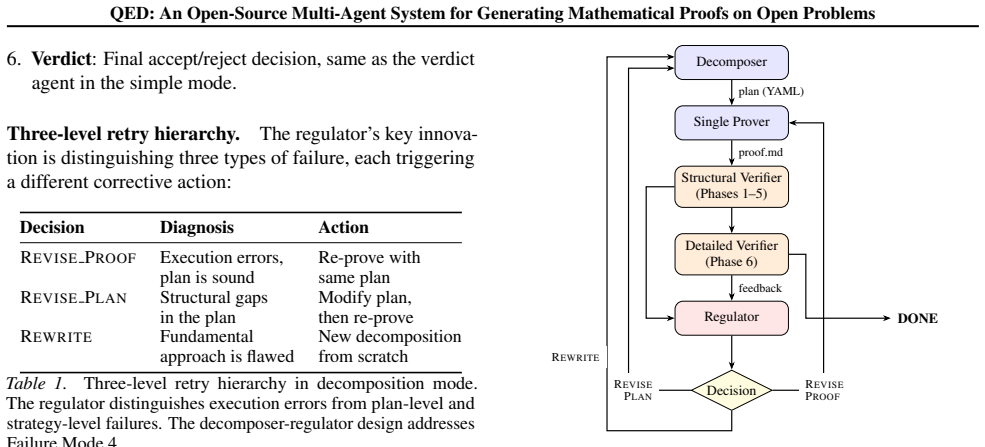
The multi-agent pipeline that assigns distinct roles to decomposition, proving, and verification agents.
If this is right
- Specialist mathematics venues could receive and review AI-generated proofs as regular submissions.
- Researchers could use the system to explore multiple proof strategies for a single conjecture in parallel.
- The open-source code allows direct testing on additional open problems in the listed domains.
- The separation of planning from proving and verification becomes a reusable template for other automated reasoning tasks.
Where Pith is reading between the lines
- Hybrid workflows may emerge in which humans supply questions and the system supplies initial proof drafts for refinement.
- Success on fluid PDEs and algebraic geometry suggests the same pipeline could be tested on number theory or combinatorics open problems.
- If verifier accuracy scales with problem size, the approach could reduce the fraction of human time spent on routine proof checking.
- Publication of the generated proofs would create a public record that future AI systems can train against.
Load-bearing premise
The verifier agents must reliably catch all errors in the generated proofs so that the five outputs are both original and correct without hidden human fixes.
What would settle it
Discovery of an undetected logical error in one of the five generated proofs by independent expert review, or zero new proofs produced when the same system is run on a fresh set of comparable open problems.
Figures

read the original abstract
We present \textbf{QED}, an open-source multi-agent system that turns human-provided research questions into complete mathematical proofs without further human guidance. Its pipeline is designed to overcome common failures of single-query proof generation by separating planning, proving, and verification: a decomposition agent structures the proof search, prover agents generate candidate arguments, and verifier agents check correctness. In collaboration with domain experts, we evaluated QED on 18 research-level projects of varying difficulty. QED produced five original works across algebraic geometry, fluid PDEs, probability, and inverse problems. Expert assessments regard these works as solid specialized research contributions, with three comparable in difficulty and scope to work commonly published in established specialist mathematics venues. QED is released at https://github.com/proofQED/QED.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents QED, an open-source multi-agent system that decomposes mathematical proof generation into planning, proving, and verification stages to address open research questions without further human guidance. On 18 research-level projects spanning algebraic geometry, fluid PDEs, probability, and inverse problems, the system is reported to have produced five original works; domain experts assessed these as solid specialized contributions, with three comparable in difficulty and scope to papers commonly published in established specialist mathematics venues. The code is released at https://github.com/proofQED/QED.
Significance. If the central claims are substantiated with adequate verification evidence, the work would constitute a meaningful contribution to AI-assisted mathematical research by demonstrating a multi-agent pipeline capable of producing publishable-level outputs on open problems. The explicit open-source release and separation of verification from generation are concrete strengths that enable reproducibility and community scrutiny.
major comments (3)
- [Abstract] Abstract: The assertion that the pipeline operates 'without further human guidance' is load-bearing for the headline claim yet is immediately qualified by the statement that evaluation occurred 'in collaboration with domain experts.' No section clarifies the precise scope of this collaboration (e.g., whether experts performed post-generation selection, refinement, or only final assessment), which directly affects whether the five outputs can be attributed solely to the agent system.
- [Evaluation section] Evaluation section (and abstract): The correctness of the five produced works rests on verifier agents, yet no quantitative performance data are supplied—such as false-negative rates on error detection for novel research-level proofs, comparison against human experts on held-out examples, or formal verification of the verifiers themselves. Without these metrics the claim that the outputs are mathematically correct cannot be independently assessed.
- [Results section] Results section: The manuscript provides no audit trail (raw agent traces, expert review rubrics, or side-by-side comparison with published analogues) that would allow readers to verify originality and correctness of the five works. This absence is material because the central claim is that QED generated publishable research contributions.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from a brief statement of the total number of agent interactions or token budgets used across the 18 projects to give readers a sense of computational cost.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below with clarifications and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] The assertion that the pipeline operates 'without further human guidance' is load-bearing for the headline claim yet is immediately qualified by the statement that evaluation occurred 'in collaboration with domain experts.' No section clarifies the precise scope of this collaboration (e.g., whether experts performed post-generation selection, refinement, or only final assessment), which directly affects whether the five outputs can be attributed solely to the agent system.
Authors: The QED pipeline generates proofs with no human input after the initial research question is supplied; planning, proving, and verification stages run autonomously. Collaboration with domain experts occurred exclusively after generation, solely for independent assessment of quality, originality, and publishability; experts performed no selection, refinement, or iterative guidance. We will revise the abstract for precision and insert a new subsection in the Evaluation section that explicitly bounds the scope of human involvement. revision: yes
-
Referee: [Evaluation section] The correctness of the five produced works rests on verifier agents, yet no quantitative performance data are supplied—such as false-negative rates on error detection for novel research-level proofs, comparison against human experts on held-out examples, or formal verification of the verifiers themselves. Without these metrics the claim that the outputs are mathematically correct cannot be independently assessed.
Authors: We agree that quantitative metrics on verifier performance for novel research-level proofs are absent. The verifier agents supply an automated first-pass check, while final correctness and significance judgments rest on the domain-expert assessments described in the paper. Generating false-negative rates or formal verifier verification would require an additional benchmark study outside the present scope. We will revise the Evaluation section to clarify the complementary roles of automated verifiers and expert review, add an explicit limitations paragraph on the lack of such metrics, and temper any implication that correctness rests solely on the agents. revision: partial
-
Referee: [Results section] The manuscript provides no audit trail (raw agent traces, expert review rubrics, or side-by-side comparison with published analogues) that would allow readers to verify originality and correctness of the five works. This absence is material because the central claim is that QED generated publishable research contributions.
Authors: All raw agent traces, conversation logs, and available expert review notes for the five works are already deposited in the public repository (https://github.com/proofQED/QED). We will expand the Results section with explicit hyperlinks to the trace directories for each proof, summarize the expert review criteria employed, and include brief qualitative discussion of how the generated results relate in scope to representative published papers in the respective subfields. revision: yes
Circularity Check
No circularity: claims rest on external expert judgment, not self-referential derivation
full rationale
The paper describes an empirical system and its outputs on open problems, with correctness and originality assessed by external domain experts. No equations, fitted parameters, predictions, or derivation chains appear. The abstract explicitly ties evaluation to collaboration with domain experts and external assessments, providing an independent benchmark rather than reducing to internal definitions or self-citations. No load-bearing step reduces by construction to the paper's own inputs.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Return Probability for the Switch--Walk--Switch Lamplighter Walk on a Regular Tree
Sharp return probability asymptotic p_{2n}(e,e) = ρ_d^{2n} exp[−(π²(log(d−1))² + o(1)) n / log² n] for the switch-walk-switch lamplighter walk with Z_2 lamps on the infinite d-regular tree, with proofs generated by th...
Reference graph
Works this paper leans on
-
[1]
That is, Cλ(R) and Cl,λ(R) are nonzero forR >0
Verify that Fλ,l(R) is well-defined for λ >0 , l≥2 , and R >0 . That is, Cλ(R) and Cl,λ(R) are nonzero forR >0
-
[2]
If 0< λ≤1 and l≥2 , l∈Z , then Fλ,l(R) is negative and monotonically increasing forR >0
-
[3]
Result.QED did not produce a proof for this problem
If λ >1 and l≥2 , l∈Z , then there exists R1 > 0 such that Fλ,l(R) is increasing for R∈(0, R 1), decreasing forR > R 1, andF λ,l(R1)>0. Result.QED did not produce a proof for this problem. Across all 9 rounds, QED’s own verification pipeline identi- fied errors in every attempted proof and rejected them—the system self-verified to reject its own outputs w...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.