ReVSI: Rebuilding Visual Spatial Intelligence Evaluation for Accurate Assessment of VLM 3D Reasoning
Pith reviewed 2026-05-08 04:42 UTC · model grok-4.3
The pith
ReVSI rebuilds visual spatial intelligence evaluation to make 3D reasoning tests valid for actual VLM inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
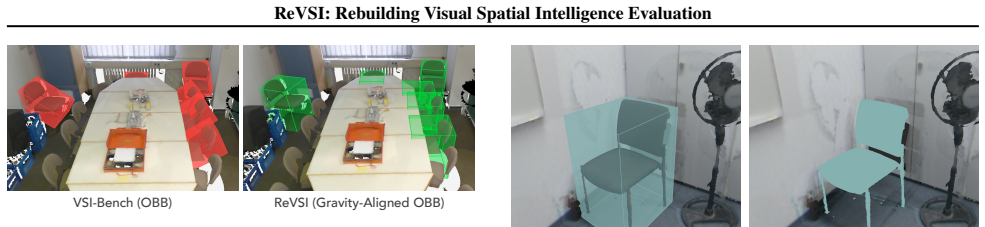
The paper establishes that by re-annotating objects and geometry in 381 scenes and regenerating all QA pairs with rigorous verification, ReVSI ensures each question is answerable and correct based on the model's actual inputs of sparsely sampled video frames. This addresses reconstruction artifacts and full-scene assumptions in prior work. The benchmark further offers controlled variants across frame budgets and object visibility metadata for diagnostic evaluation of spatial intelligence in VLMs.
What carries the argument
ReVSI, the rebuilt benchmark that re-annotates 3D objects and geometry with professional tools and verifies QA pairs for answerability under sparse video inputs.
If this is right
- Prior evaluations are invalid due to mismatched annotations and unanswerable questions.
- ReVSI evaluations uncover systematic failure modes in general and domain-specific VLMs.
- Multiple frame budget variants allow analysis of performance under different input conditions.
- Object visibility metadata supports fine-grained diagnostics of reasoning errors.
Where Pith is reading between the lines
- Adopting ReVSI could lead to more targeted improvements in VLM architectures for handling partial scenes.
- The protocol of re-annotation and verification may extend to other 3D or video perception benchmarks.
- Researchers might use the visibility metadata to study the impact of specific object occlusions on model accuracy.
Load-bearing premise
Re-annotating objects and geometry using professional 3D tools and human verification produces accurate ground truth without new biases or artifacts that affect geometry-dependent answers.
What would settle it
An experiment where independent annotators review a random sample of ReVSI QA pairs against the video frames and find high rates of remaining errors or unanswerable questions would falsify the claim of improved validity.
Figures
















read the original abstract
Current evaluations of spatial intelligence can be systematically invalid under modern vision-language model (VLM) settings. First, many benchmarks derive question-answer (QA) pairs from point-cloud-based 3D annotations originally curated for traditional 3D perception. When such annotations are treated as ground truth for video-based evaluation, reconstruction and annotation artifacts can miss objects that are clearly visible in the video, mislabel object identities, or corrupt geometry-dependent answers (e.g., size), yielding incorrect or ambiguous QA pairs. Second, evaluations often assume full-scene access, while many VLMs operate on sparsely sampled frames (e.g., 16-64), making many questions effectively unanswerable under the actual model inputs. We improve evaluation validity by introducing ReVSI, a benchmark and protocol that ensures each QA pair is answerable and correct under the model's actual inputs. To this end, we re-annotate objects and geometry across 381 scenes from 5 datasets to improve data quality, and regenerate all QA pairs with rigorous bias mitigation and human verification using professional 3D annotation tools. We further enhance evaluation controllability by providing variants across multiple frame budgets (16/32/64/all) and fine-grained object visibility metadata, enabling controlled diagnostic analyses. Evaluations of general and domain-specific VLMs on ReVSI reveal systematic failure modes that are obscured by prior benchmarks, yielding a more reliable and diagnostic assessment of spatial intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that existing VLM spatial intelligence benchmarks are invalid because QA pairs derived from point-cloud annotations contain artifacts (missed objects, mislabeled identities, corrupted geometry) and because they assume full-scene access while VLMs typically receive only sparse frames. It introduces ReVSI, which re-annotates objects and geometry across 381 scenes from five source datasets using professional 3D tools and human verification, regenerates all QA pairs under explicit bias-mitigation rules, and supplies controlled variants for 16/32/64/all-frame budgets together with per-object visibility metadata to enable diagnostic evaluation.
Significance. If the re-annotation protocol demonstrably produces accurate, artifact-free ground truth, ReVSI would constitute a meaningful advance in benchmark construction for VLM 3D reasoning. The provision of frame-budget variants and visibility metadata is a concrete strength that supports controlled ablation studies not available in prior suites. The work is empirical rather than theoretical and therefore carries no free-parameter or circularity concerns.
major comments (2)
- [§3] §3 (Re-annotation protocol): The manuscript describes the use of professional 3D annotation tools and human verification but reports no quantitative validation metrics (inter-annotator agreement on 3D coordinates, comparison to independent measurements, or error rates on geometry-dependent attributes). Because residual annotation errors would directly affect size, distance, and visibility answers, this omission is load-bearing for the central claim of improved evaluation validity.
- [§5] §5 (Experimental results): The claim that ReVSI reveals systematic failure modes obscured by prior benchmarks is not accompanied by a direct head-to-head comparison of the same models on the original versus regenerated QA pairs for identical scenes. Without this quantification, the magnitude of the diagnostic improvement remains unmeasured.
minor comments (2)
- [Abstract / §3.2] The abstract states that QA pairs are regenerated 'with rigorous bias mitigation' but does not enumerate the concrete mitigation rules; these should be listed explicitly in §3.2.
- [Introduction] Ensure that the five source datasets are named and cited in the introduction and that the exact number of regenerated QA pairs per dataset is reported in a table.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the two major comments point by point below, agreeing that both points identify areas where the manuscript can be strengthened with additional evidence. We will incorporate the suggested revisions in the next version.
read point-by-point responses
-
Referee: [§3] §3 (Re-annotation protocol): The manuscript describes the use of professional 3D annotation tools and human verification but reports no quantitative validation metrics (inter-annotator agreement on 3D coordinates, comparison to independent measurements, or error rates on geometry-dependent attributes). Because residual annotation errors would directly affect size, distance, and visibility answers, this omission is load-bearing for the central claim of improved evaluation validity.
Authors: We agree that quantitative validation metrics are important to substantiate the quality of the re-annotation protocol. The current manuscript emphasizes the use of professional 3D tools and multi-stage human verification to reduce artifacts, but does not report specific metrics such as inter-annotator agreement or error rates on geometry attributes. In the revised manuscript we will add a new subsection to §3 that includes these metrics: inter-annotator agreement scores for object bounding boxes and identities, comparison of a sample of re-annotated geometry against independent measurements, and observed error rates on size/distance/visibility attributes. This addition will directly address the concern about residual errors affecting downstream QA validity. revision: yes
-
Referee: [§5] §5 (Experimental results): The claim that ReVSI reveals systematic failure modes obscured by prior benchmarks is not accompanied by a direct head-to-head comparison of the same models on the original versus regenerated QA pairs for identical scenes. Without this quantification, the magnitude of the diagnostic improvement remains unmeasured.
Authors: We acknowledge that a direct head-to-head comparison would provide a clearer quantification of the improvement. The current experiments demonstrate that ReVSI uncovers failure modes not visible in prior benchmarks by evaluating models on the cleaned, frame-budget-controlled QA pairs. To measure the magnitude of the difference, we will add a new analysis in §5 that evaluates the same set of models on both the original and regenerated QA pairs for a representative subset of scenes. This will report the percentage of answers that change due to re-annotation and the impact of frame-budget variants, thereby quantifying the diagnostic gain. revision: yes
Circularity Check
No circularity: empirical benchmark re-annotation protocol is self-contained
full rationale
The paper describes construction of the ReVSI benchmark through re-annotation of 381 scenes using professional 3D tools and human verification, followed by regeneration of QA pairs with bias mitigation. No mathematical derivations, equations, fitted parameters, or model predictions appear in the abstract or described protocol. The central claim rests on the independent process of data re-annotation and verification rather than any self-referential definition, fitted input renamed as prediction, or load-bearing self-citation. The evaluation variants (frame budgets and visibility metadata) are presented as controllable extensions of the re-annotated data, with no reduction to quantities defined by the authors' own choices.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Point-cloud-based 3D annotations originally curated for traditional perception contain reconstruction and annotation artifacts that invalidate QA pairs for video-based VLM evaluation
Reference graph
Works this paper leans on
-
[1]
Embspatial-bench: Benchmarking spa- tialunderstandingforembodiedtaskswithlargevision-languagemodels
URL https://api.semanticscholar.org/ CorpusID:245334889. Baruch, G., Chen, Z., Dehghan, A., Dimry, T., Feigin, Y ., Fu, P., Gebauer, T., Joffe, B., Kurz, D., Schwartz, A., and Shul- man, E. ARKitScenes - a diverse real-world dataset for 3D indoor scene understanding using mobile RGB-D data. InNeu- ral Information Processing Systems Datasets and Benchmarks...
-
[2]
3D Segmentation (Pseudo)
3D Bounding Box2. 3D Segmentation (Pseudo)
-
[3]
Ray Casting From Views
-
[4]
Pipeline for computing auxiliary 2D bounding boxes for object visibility annotation guidance
2D Bounding Box Figure 14. Pipeline for computing auxiliary 2D bounding boxes for object visibility annotation guidance. We start with ReVSI 3D object bounding box annotations (1), and use the meshes with the bounding boxes to approximate pseudo 3D object masks (2). We then project the masks into each view via ray casting using camera trajectories provide...
-
[5]
3”, “1.8
to obtain the 64-frame. We then recursively apply np.linspace on the sampled frames to obtain 32- and 16-frame subsets. This ensures a nested structure: the 16- frame set is a subset of the 32-frame set, which is a sub- set of the 64-frame set. All subsets for a given video span the same temporal duration, ensuring that corresponding frames share consiste...
-
[6]
How many obj 1(s) and obj 2(s) are in the scene in total? Absolute Distance Measuring from the closest point of each object, what is the direct distance between the obj 1 and the obj 2 (in meters)? Object Size Estimation What is the length of the longest dimension (length, width, or height) of the obj, measured in centimeters? Based on visual evidence fro...
-
[7]
What is the size of the scene (in square meters)? If multiple rooms are shown, estimate the size of the combined space
-
[8]
Relative Distance Measuring from the closest point of each object, which of these objects (obj 1, obj 2, obj 3, obj 4) is the closest to the obj 5?
What is the size of the main room (in square meters)? If multiple rooms are shown, estimate only the size of the dominant room in which the video is primarily recorded. Relative Distance Measuring from the closest point of each object, which of these objects (obj 1, obj 2, obj 3, obj 4) is the closest to the obj 5?
-
[9]
Measuring from the closest point of each object, which of these objects (obj 1, obj 2, obj 3, obj 4) is the closest to the obj 5?
-
[10]
If I am standing by the obj 1 and facing the obj 2, is the obj 3 to the left or the right of the obj 2?
Measuring from the closest point of each object, which of these objects (obj 1, obj 2, obj 3, obj 4) is the farthest from the obj 5? Relative Direction 1. If I am standing by the obj 1 and facing the obj 2, is the obj 3 to the left or the right of the obj 2?
-
[12]
If I am standing by the obj 1 and facing the obj 2, is the obj 3 to my front-left, front-right, back-left, or back-right? Directions refer to the quadrants of a Cartesian plane (assuming I am at the origin and facing the positive y-axis)
-
[13]
If I am standing by the obj 1 and facing the obj 2, is the obj 3 to my left, right, or back? An object is to my back if I would have to turn at least 135 degrees in order to face it
-
[14]
If I am standing by the obj 1 and facing in the opposite direction of the obj 2, is the obj 3 to my left, right, or back? An object is to my back if I would have to turn at least 135 degrees in order to face it
-
[15]
If I am standing by the obj 1 and facing the obj 2, is the obj 3 to my front-left, front-right, back-left, or back-right?
-
[16]
You want to navigate to obj 3
If I am standing by the obj 1 and facing in the opposite direction of the obj 2, is the obj 3 to my front-left, front-right, back-left, or back-right? Route Planning You are a robot beginning at theobj 1 and facing the obj 2. You want to navigate to obj 3. You will perform the following actions (Note: for each [please fill in], choose either ‘turn back, ’...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.