Aligning with Your Own Voice: Self-Corrected Preference Learning for Hallucination Mitigation in LVLMs
Pith reviewed 2026-05-08 03:43 UTC · model grok-4.3
The pith
Consensus-based self-correction lets LVLMs generate their own in-distribution preference data to reduce hallucinations more effectively than external-model methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that AVES-DPO aligns LVLMs by deriving preference data from the model's own knowledge through a consensus-based verification mechanism that diagnoses hallucinations and guides self-correction, thereby surpassing existing baselines in hallucination mitigation while requiring only 5.2k samples.
What carries the argument
Consensus-based verification mechanism that diagnoses diverse hallucinations and generates self-corrections to produce preference pairs matching the model's internal distribution.
If this is right
- Only 5.2k samples suffice for effective hallucination alignment.
- In-distribution preference pairs from self-correction eliminate the mismatch caused by proprietary models.
- Consensus verification addresses multiple hallucination types within the model's own knowledge.
- Self-correction produces pairs that stay compatible with the model's intrinsic distribution.
Where Pith is reading between the lines
- The approach could extend to aligning models on other issues such as factual consistency or safety without external supervision.
- Reduced dependence on proprietary models would make high-quality alignment more accessible for smaller research groups.
- Testing whether the 5.2k sample efficiency scales to larger LVLMs or multimodal tasks would clarify the method's broader applicability.
- Combining consensus verification with other internal checks might further lower the risk of uncorrected errors.
Load-bearing premise
The consensus-based verification mechanism can reliably diagnose diverse hallucinations and produce accurate self-corrections that match the model's true internal distribution without introducing new errors.
What would settle it
If AVES-DPO applied to standard hallucination benchmarks such as POPE or CHAIR shows no improvement or worse results than baseline DPO methods using external data, the claim of superior mitigation with in-distribution pairs would be falsified.
Figures





read the original abstract
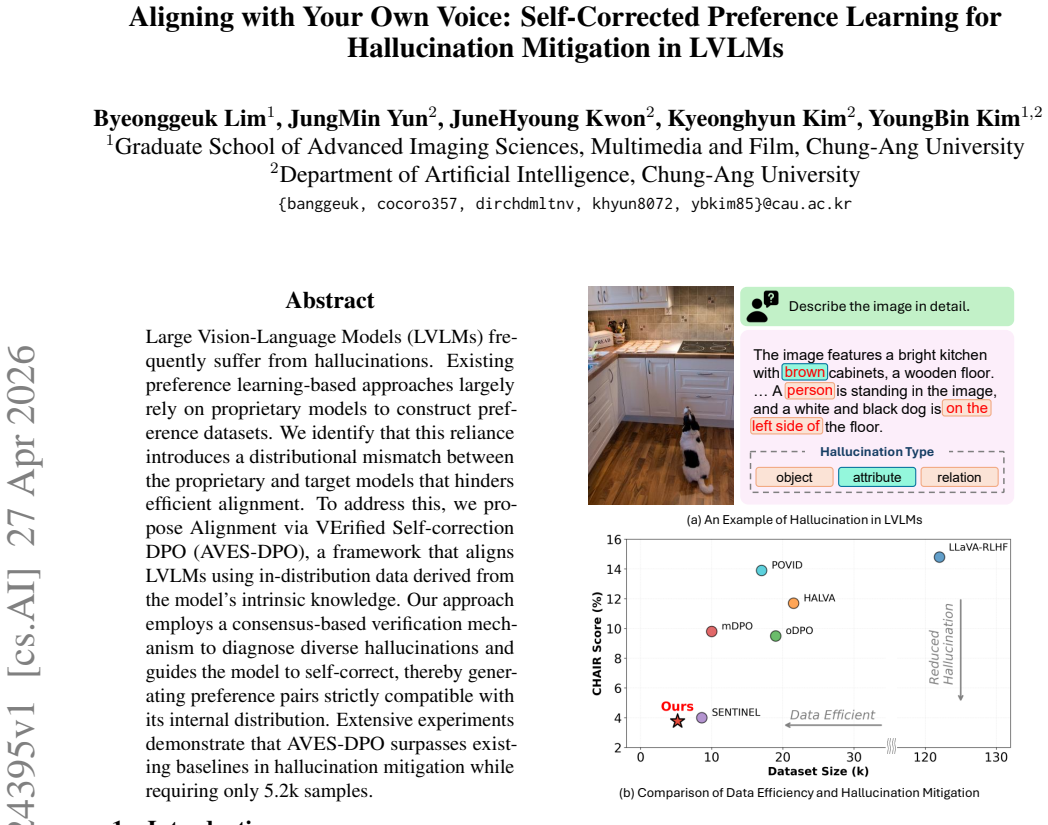
Large Vision-Language Models (LVLMs) frequently suffer from hallucinations. Existing preference learning-based approaches largely rely on proprietary models to construct preference datasets. We identify that this reliance introduces a distributional mismatch between the proprietary and target models that hinders efficient alignment. To address this, we propose Alignment via VErified Self-correction DPO (AVES-DPO), a framework that aligns LVLMs using in-distribution data derived from the model's intrinsic knowledge. Our approach employs a consensus-based verification mechanism to diagnose diverse hallucinations and guides the model to self-correct, thereby generating preference pairs strictly compatible with its internal distribution. Extensive experiments demonstrate that AVES-DPO surpasses existing baselines in hallucination mitigation while requiring only 5.2k samples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AVES-DPO, a preference learning framework for hallucination mitigation in LVLMs. It generates in-distribution preference pairs by applying a consensus-based verification mechanism to the target model's own outputs for self-diagnosis and correction, thereby avoiding distributional mismatch with proprietary models. The central claim is that this yields superior hallucination reduction compared to existing baselines while using only 5.2k samples.
Significance. If validated, the result would be significant because it demonstrates that self-generated, in-distribution preference data can outperform external-model baselines for LVLM alignment, with very low sample complexity. This reduces dependence on proprietary systems and addresses a practical bottleneck in scalable hallucination mitigation.
major comments (2)
- [Abstract] Abstract: the claim that AVES-DPO 'surpasses existing baselines' is presented without any specification of the evaluation metrics (e.g., CHAIR, POPE, or others), the exact baselines, statistical significance tests, or controls that isolate the contribution of the consensus verification step; this information is load-bearing for assessing whether the performance gain is attributable to the proposed method rather than experimental setup.
- [§3] §3 (consensus-based verification mechanism): no procedure is described for detecting or mitigating cases in which the LVLM exhibits systematic, high-confidence hallucinations on particular visual concepts; under such conditions majority consensus would simply ratify the incorrect answer, producing preference pairs that reinforce rather than correct the error and thereby undermining the claim that the generated data remain 'strictly compatible with its internal distribution.'
minor comments (1)
- The manuscript would benefit from an explicit statement of the exact number of generations used for consensus and the decision threshold for accepting a correction, as these hyperparameters directly affect reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to improve clarity and transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that AVES-DPO 'surpasses existing baselines' is presented without any specification of the evaluation metrics (e.g., CHAIR, POPE, or others), the exact baselines, statistical significance tests, or controls that isolate the contribution of the consensus verification step; this information is load-bearing for assessing whether the performance gain is attributable to the proposed method rather than experimental setup.
Authors: We agree that the abstract should be more specific to allow proper evaluation of the claims. In the revised manuscript, we will update the abstract to explicitly name the evaluation metrics (CHAIR, POPE, and additional ones used in the experiments), list the primary baselines (including standard DPO variants and other hallucination mitigation approaches), note that performance differences were assessed for statistical significance, and briefly indicate that ablations were performed to isolate the contribution of the consensus verification mechanism. These changes will make the performance claims more precise and attributable to the proposed method. revision: yes
-
Referee: [§3] §3 (consensus-based verification mechanism): no procedure is described for detecting or mitigating cases in which the LVLM exhibits systematic, high-confidence hallucinations on particular visual concepts; under such conditions majority consensus would simply ratify the incorrect answer, producing preference pairs that reinforce rather than correct the error and thereby undermining the claim that the generated data remain 'strictly compatible with its internal distribution.'
Authors: This is a substantive concern. Our consensus-based verification generates multiple responses from the target LVLM itself and identifies hallucinations via inconsistency across generations to produce self-corrected preference pairs. We acknowledge that the manuscript does not describe an explicit additional procedure for detecting or mitigating systematic, high-confidence biases on specific visual concepts, where consistent errors could lead consensus to reinforce rather than correct them. While the resulting pairs remain strictly in-distribution (being derived solely from the model's own outputs), this does not fully address systematic bias propagation. We will revise §3 to add an explicit discussion of this limitation and suggest directions for future bias-aware verification techniques. revision: partial
Circularity Check
No significant circularity; method uses explicit self-reference for data generation but evaluates externally
full rationale
The paper's core proposal is AVES-DPO, which applies consensus-based verification to the LVLM's own generations to create preference pairs for DPO training. This is presented as a deliberate design to avoid distributional mismatch with proprietary models, not as a derivation that reduces to its inputs by construction. Empirical results are framed as comparisons against external baselines on hallucination benchmarks, with no equations or claims showing that performance gains are forced by the self-correction step itself. No self-citations are load-bearing for uniqueness theorems, no fitted parameters are relabeled as predictions, and no ansatz is smuggled via prior work. The self-reference is transparent and does not collapse the claimed alignment benefit into a tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The target LVLM possesses sufficient intrinsic knowledge to self-diagnose and correct its hallucinations via consensus among its own generations.
invented entities (1)
-
Consensus-based verification mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mitigating object hallucinations in large vision- language models through visual contrastive decoding. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 13872–13882. Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023a. BLIP-2: Bootstrapping language-image pre- training with frozen image encoders a...
-
[2]
Proximal Policy Optimization Algorithms
Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, volume 36, pages 53728–53741. Curran Associates, Inc. Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. 2018. Object hallu- cination in image captioning. InProceedings of the 2018 Conference ...
work page internal anchor Pith review arXiv 2018
-
[3]
Beyond Hallucinations: Enhancing LVLMs through Hallucination-Aware Direct Preference Optimization
V-DPO: Mitigating hallucination in large vi- sion language models via vision-guided direct pref- erence optimization. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 13258–13273, Miami, Florida, USA. Association for Computational Linguistics. Zhihe Yang, Xufang Luo, Dongqi Han, Yunjian Xu, and Dongsheng Li. 2025. Mitigating ...
work page internal anchor Pith review arXiv 2024
-
[5]
{object_name}
Determine if the target object exists and is correctly identified in the image. ### DECISION GUIDELINES -CORRECT: The target object is clearly present and correctly identified in the image. -INCORRECT: The target object is NOT present in the image. -UNCLEAR: The object is too blurry, too small, too dark to identify, or it is ambiguous whether it matches t...
-
[6]
Focus on the target object specified in the task
-
[7]
Verify if the target attributes accurately describe the target object
-
[8]
ATTRIBUTE TYPE GUIDANCE
If an attribute is clearly INCORRECT: - TRY to select a correction from the provided “ATTRIBUTE TYPE GUIDANCE” if a suitable option exists. - If NO suitable option exists in the guidance, mark as INCORRECT without providing a correction. ### DECISION GUIDELINES -CORRECT: The attribute visually matches the target object. -INCORRECT: The attribute does NOT ...
-
[9]
Focus STRICTLY on the relationship between the subject and object specified in the task
-
[10]
Verify if the target relation semantically and accurately describes the visual relationship
-
[11]
RELATION TYPE GUIDANCE
If the relation is clearly INCORRECT: - TRY to select a correction from the provided “RELATION TYPE GUIDANCE” if a suitable option exists. - If NO suitable option exists in the guidance, mark as INCORRECT without providing a correction. ### DECISION GUIDELINES -CORRECT: The relation accurately and semantically describes the visual relationship between the...
-
[12]
Do NOT delete an entire sentence unless the whole sentence is only about removed objects
Remove objects: Remove ONLY the object mention and its related phrase completely. Do NOT delete an entire sentence unless the whole sentence is only about removed objects. If an object listed in ISSUES is not found in the caption, IGNORE it
-
[13]
Replace: When ’A’ -> ’B’ is provided, REPLACE ’A’ with ’B’
-
[14]
Remove: Delete ONLY the specified adjective or relation phrase entirely
-
[15]
NEVER add sentences stating what is missing
Grammar & Style: Fix ONLY the items listed in ISSUES. NEVER add sentences stating what is missing. Output ONLY the final fixed caption directly. ### YOUR TASK ORIGINAL: {original_caption} ISSUES: {hallucination_info} FIXED: Table 19: The prompt template used for correcting captions based on identified issues. System Prompt for Caption Enrichment You are a...
-
[16]
You must keep all the existing facts from the Basic Description exactly as they are, maintaining the original sentence structure as much as possible
-
[17]
You should actively identify and include other objects or details that are clearly visible in the image but are missing from the Basic Description
-
[18]
Do not infer emotions or intentions
You must strictly utilize only visual evidence. Do not infer emotions or intentions
-
[19]
You must combine the original facts and new visual details into a single, cohesive, and natural- sounding paragraph
-
[20]
there is no
Describe ONLY what is visible. NEVER mention what is missing (e.g., strictly avoid phrases like “there is no”, “not present”, “does not contain”, “not visible”, “no visible”). ### Basic Description {refined_caption} ### CRITICAL W ARNING (Negative Constraints) The following objects have been confirmed as NOT present in the image. You must NEVER mention or...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.