BMD-45: A Large-Scale CCTV Vehicle Detection Dataset for Urban Traffic in Developing Cities
Pith reviewed 2026-05-08 04:36 UTC · model grok-4.3
The pith
A new CCTV dataset from developing cities shows vehicle detectors achieve only one-third the accuracy of in-domain training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that standard vehicle detectors, when applied to real-world CCTV footage from developing-city traffic, suffer a large performance drop relative to their accuracy on existing benchmarks. On BMD-45 they report 33.6 percent mAP@0.50:0.95 for UA-DETRAC-fine-tuned models versus 83.8 percent for models trained in-domain, a factor of roughly 2.5 that persists even after isolating the effect of novel categories such as auto-rickshaws. The dataset captures 14 fine-grained classes across 45,000 images taken from more than 3,600 fixed cameras and includes the viewpoint variation, occlusion, and density that characterize disorganized urban traffic.
What carries the argument
The BMD-45 dataset of 45,000 CCTV images and 480,000 bounding-box annotations that supplies region-specific vehicle categories and real deployment conditions absent from prior benchmarks.
If this is right
- Detectors intended for traffic monitoring in developing cities must be trained or adapted on local scene statistics to reach usable accuracy.
- Fine-grained categories for vehicles such as auto-rickshaws enable detection tasks that global benchmarks cannot support.
- The dataset supplies a concrete test set for measuring robustness to extreme occlusion and density that standard benchmarks under-represent.
- Future intelligent-transportation pipelines can use BMD-45 as a fixed reference point when comparing domain-adaptation methods.
Where Pith is reading between the lines
- Similar large-scale CCTV collections from other rapidly urbanizing regions would clarify whether the domain gap is specific to South Asia or more universal.
- Multi-domain training that mixes organized and chaotic traffic scenes might reduce reliance on any single new dataset.
- The performance numbers provide a quantitative target for synthetic-data generators that aim to simulate dense, low-viewpoint traffic without new field collection.
Load-bearing premise
The observed performance gap arises mainly from differences in traffic organization, camera viewpoints, and vehicle mix rather than from variations in image quality, labeling conventions, or experimental setup between the two datasets.
What would settle it
Re-running the identical training and evaluation protocol after re-annotating a matched subset of UA-DETRAC images according to BMD-45 labeling rules and image-resolution standards; if the mAP gap shrinks substantially, annotation and quality differences would explain the result.
Figures












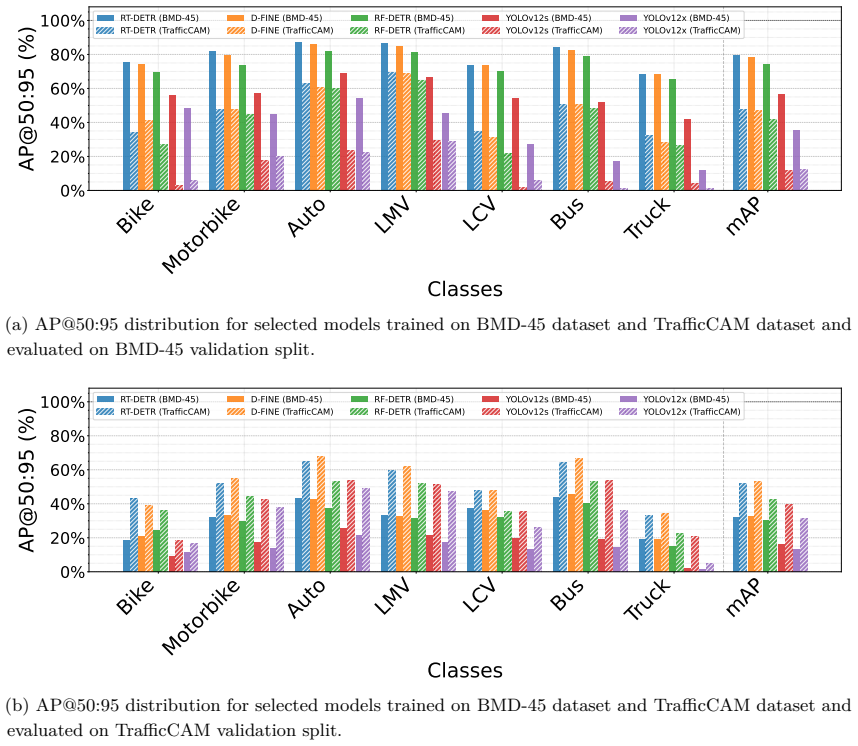

read the original abstract
Robust vehicle detection from fixed CCTV cameras is critical for Intelligent Transportation Systems. Yet existing benchmarks predominantly feature relatively homogeneous, highly organized traffic patterns captured from ego-centric driving perspectives or controlled aerial views. This regional and sensor view bias creates a significant gap. Models trained on datasets such as UA-DETRAC and COCO struggle to generalize to the dense, heterogeneous, disorganized traffic conditions observed in rapidly developing urban centers in emerging economies. To address this limitation, we introduce BMD-45, a large-scale dataset comprising 480K bounding boxes annotated over 45K images captured from over 3.6K operational Safe City CCTV cameras. BMD-45 contains 14 fine-grained vehicle categories, including region-specific modes such as auto-rickshaws and tempo travellers, which are not present in existing benchmarks. The dataset captures real-world deployment challenges, including extreme viewpoint variation, occlusion, and vehicle density . We establish comprehensive baselines using state-of-the-art detectors and reveal a striking domain gap: models fine-tuned on UA-DETRAC achieve only 33.6% mAP@0.50:0.95, compared to 83.8% when trained in-domain on BMD-45, representing a 2.5x improvement that persists even when accounting for novel vehicle classes. This performance gap underscores the critical need for geographically diverse traffic benchmarks and establishes BMD-45 as a baseline for developing robust perception systems in underrepresented urban environments worldwide. The dataset is available at: https://huggingface.co/datasets/iisc-aim/BMD-45.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BMD-45, a dataset of 45K CCTV images containing 480K bounding-box annotations across 14 vehicle classes (including region-specific categories such as auto-rickshaws) captured from operational cameras in developing urban centers. It reports comprehensive baselines with modern detectors and highlights a large domain gap: models fine-tuned on UA-DETRAC reach only 33.6% mAP@0.50:0.95 on BMD-45, versus 83.8% when trained in-domain, with the gap claimed to persist after accounting for novel classes.
Significance. If the experimental controls hold, the work supplies a publicly released benchmark that directly quantifies the generalization failure of existing traffic datasets to disorganized, high-density CCTV scenes typical of emerging economies. This is a concrete, falsifiable contribution that can guide future dataset curation and model adaptation for real-world ITS deployments in underrepresented regions.
major comments (3)
- [Results / Baselines] Results section (comparison with UA-DETRAC): the assertion that the 2.5× mAP gap 'persists even when accounting for novel vehicle classes' is load-bearing for the domain-shift claim, yet the manuscript provides no description of the class-mapping procedure, the common-class subset evaluated, or a per-class mAP breakdown. These details are required to separate class novelty from regional traffic characteristics.
- [Experiments] Experimental protocol (UA-DETRAC vs. BMD-45 training): the paper does not state whether identical detector architectures, optimizers, learning-rate schedules, data augmentations, and weight initializations were used for both datasets. Any mismatch in these factors could explain part or all of the reported performance difference and must be documented with full training details.
- [Dataset Description] Dataset characterization: to attribute the gap to 'dense, heterogeneous, disorganized traffic' rather than annotation or image-quality differences, the manuscript should report quantitative statistics (occlusion rates, vehicle density histograms, viewpoint angle distributions) and inter-annotator agreement metrics for BMD-45 alongside the same quantities for UA-DETRAC.
minor comments (2)
- [Abstract] The abstract states 'over 3.6K operational Safe City CCTV cameras' without clarifying whether the cameras span multiple cities or a single region; this context should be added for reproducibility.
- [Figures] Figure captions and legends should explicitly label the challenges (extreme viewpoint, occlusion, density) illustrated in each example image.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below. Where the manuscript lacks sufficient documentation, we will revise to add the requested details and analyses.
read point-by-point responses
-
Referee: [Results / Baselines] Results section (comparison with UA-DETRAC): the assertion that the 2.5× mAP gap 'persists even when accounting for novel vehicle classes' is load-bearing for the domain-shift claim, yet the manuscript provides no description of the class-mapping procedure, the common-class subset evaluated, or a per-class mAP breakdown. These details are required to separate class novelty from regional traffic characteristics.
Authors: We agree these details are necessary to substantiate the claim. In the revised manuscript we will add a dedicated paragraph in the Experiments section describing the class-mapping procedure (grouping BMD-45's region-specific classes to the closest UA-DETRAC equivalents where possible), explicitly defining the common-class subset, and providing per-class mAP tables on both the full BMD-45 test set and the common-class subset. This will allow readers to quantify how much of the gap remains after removing the effect of novel classes. revision: yes
-
Referee: [Experiments] Experimental protocol (UA-DETRAC vs. BMD-45 training): the paper does not state whether identical detector architectures, optimizers, learning-rate schedules, data augmentations, and weight initializations were used for both datasets. Any mismatch in these factors could explain part or all of the reported performance difference and must be documented with full training details.
Authors: All reported experiments used identical detector architectures, optimizers, learning-rate schedules, data augmentations, and weight initializations (COCO-pretrained) for both datasets to ensure a controlled comparison. We will add a new 'Implementation Details' subsection in the revised Experiments section that fully documents the architectures, optimizer settings, learning-rate schedules, augmentation pipeline, training epochs, batch sizes, and hardware/software environment. revision: yes
-
Referee: [Dataset Description] Dataset characterization: to attribute the gap to 'dense, heterogeneous, disorganized traffic' rather than annotation or image-quality differences, the manuscript should report quantitative statistics (occlusion rates, vehicle density histograms, viewpoint angle distributions) and inter-annotator agreement metrics for BMD-45 alongside the same quantities for UA-DETRAC.
Authors: We will expand the Dataset section with the requested quantitative statistics. For BMD-45 we will report occlusion rates (fraction of boxes with >50% occlusion), vehicle-density histograms, and viewpoint-angle distributions. The same metrics will be computed and reported for UA-DETRAC using its provided annotations and metadata. We will also add inter-annotator agreement figures (average pairwise IoU on a sampled multi-annotated subset) for BMD-45. revision: yes
Circularity Check
No circularity: purely empirical dataset introduction with standard cross-dataset baselines
full rationale
The paper presents BMD-45 as a new dataset and reports direct experimental results from training standard object detectors (e.g., on UA-DETRAC vs. in-domain on BMD-45) and measuring mAP on held-out test splits. No mathematical derivations, first-principles predictions, fitted parameters renamed as outputs, or self-citation chains are used to support the central claims. The 33.6% vs 83.8% gap is a straightforward empirical observation, not a constructed result. The paper is self-contained against external benchmarks and contains no load-bearing steps that reduce to its own inputs by definition or citation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Itd: Indian traffic dataset for intelligent transportation systems
Amit Agarwal, Anurag Thombre, Kabir Kedia, and Indrajit Ghosh. Itd: Indian traffic dataset for intelligent transportation systems. In2024 16th International Conference on COMmunication Systems & NETworkS (COMSNETS), pages 842– 850, 2024
2024
-
[2]
The opencv library.Dr
Gary Bradski. The opencv library.Dr. Dobb’s Journal of Software Tools, 2000. https://docs.opencv.org/
2000
-
[3]
nuScenes: A Multimodal Dataset for Autonomous Driving
HolgerCaesar, Varun Bankiti, Alex H.Lang, Sourabh Vora, Venice ErinLiong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuScenes: A Multimodal Dataset for Autonomous Driving . In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11618–11628, Los Alamitos, CA, USA, June 2020. IEEE Computer Society
2020
-
[4]
Domain adaptive faster r-cnn for object detection in the wild
Yuhua Chen, Wen Li, Christos Sakaridis, Dengxin Dai, and Luc Van Gool. Domain adaptive faster r-cnn for object detection in the wild. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3339–3348, 2018
2018
-
[5]
Prepare cityscapes dataset (notes on blurred images).https:// github.com/mcordts/cityscapesScripts
Marius Cordts. Prepare cityscapes dataset (notes on blurred images).https:// github.com/mcordts/cityscapesScripts. Cityscapes Scripts, GitHub repository, accessed November 2025. 17
2025
-
[6]
The Cityscapes Dataset for Semantic Urban Scene Understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus En- zweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The Cityscapes Dataset for Semantic Urban Scene Understanding . In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3213–3223, Los Alamitos, CA, USA, June 2016. IEEE Computer Society
2016
-
[7]
Aviles-Rivero
Zhongying Deng, Yanqi Cheng, Lihao Liu, Shujun Wang, Rihuan Ke, Carola- Bibiane Schönlieb, and Angelica I. Aviles-Rivero. Trafficcam: A versatile dataset for traffic flow segmentation.IEEE Transactions on Intelligent Transportation Systems, 26(2):2747–2759, 2025
2025
-
[8]
O’Connor
Julia Dietlmeier, Joseph Antony, Kevin McGuinness, and Noel E. O’Connor. How important are faces for person re-identification? . In2020 25th International Conference on Pattern Recognition (ICPR), pages 6912–6919, Los Alamitos, CA, USA, January 2021. IEEE Computer Society
2021
-
[9]
The unmanned aerial vehicle benchmark: Object detection and tracking
Dawei Du, Yuankai Qi, Hongyang Yu, Yifan Yang, Kaiwen Duan, Guorong Li, Weigang Zhang, Qingming Huang, and Qi Tian. The unmanned aerial vehicle benchmark: Object detection and tracking. InComputer Vision – ECCV 2018: 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part X, page 375–391, Berlin, Heidelberg, 2018. Springer-Verlag
2018
-
[10]
Visdrone-det2019: The vision meets drone object detection in image challenge results
Dawei Du, Pengfei Zhu, Longyin Wen, Xiao Bian, Haibin Lin, Qinghua Hu, Tao Peng, Jiayu Zheng, Xinyao Wang, Yue Zhang, Liefeng Bo, Hailin Shi, Rui Zhu, Aashish Kumar, Aijin Li, Almaz Zinollayev, Anuar Askergaliyev, Arne Schumann, Binjie Mao, Byeongwon Lee, Chang Liu, Changrui Chen, Chunhong Pan, Chunlei Huo, Da Yu, DeChun Cong, Dening Zeng, Dheeraj Reddy P...
2019
-
[11]
The pascal visual object classes (voc) challenge.International Journal of Computer Vision, 88:303–338, 06 2010
Mark Everingham, Luc Van Gool, Christopher Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge.International Journal of Computer Vision, 88:303–338, 06 2010
2010
-
[12]
Measuring nominal scale agreement among many raters.Psychological Bulletin, 76:378–382, 11 1971
Joseph Fleiss. Measuring nominal scale agreement among many raters.Psychological Bulletin, 76:378–382, 11 1971
1971
-
[13]
The vendi score: A diversity evaluation metric for machine learning.Trans
Dan Friedman and Adji Bousso Dieng. The vendi score: A diversity evaluation metric for machine learning.Trans. Mach. Learn. Res., 2023, 2022
2023
-
[14]
Cheung, Ahmed Abdulkader, Marco Zennaro, Bo Wu, Alessandro Bissacco, Hartmut Adam, Hartmut Neven, and Luc Vincent
Andrea Frome, George S. Cheung, Ahmed Abdulkader, Marco Zennaro, Bo Wu, Alessandro Bissacco, Hartmut Adam, Hartmut Neven, and Luc Vincent. Large-scale privacy protection in google street view. InProceedings of the IEEE International Conference on Computer Vision (ICCV), 2009
2009
-
[15]
Vision meets robotics: The kitti dataset
A Geiger, P Lenz, C Stiller, and R Urtasun. Vision meets robotics: The kitti dataset. Int. J. Rob. Res., 32(11):1231–1237, September 2013
2013
-
[16]
Are we ready for autonomous driving? the kitti vision benchmark suite
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 3354–3361, 2012
2012
-
[17]
Jia Guo, Jiankang Deng, Andreas Lattas, and Stefanos Zafeiriou. Sample and computation redistribution for efficient face detection (scrfd).arXiv preprint arXiv:2105.04714, 2021
-
[18]
Enhancing yolo for occluded vehicle detection with grouped orthogonal attention and dense object repulsion.Scientific Reports, 14, 08 2024
Jinpeng He, Huaixin Chen, Biyuan Liu, Sijie Luo, and Jie Liu. Enhancing yolo for occluded vehicle detection with grouped orthogonal attention and dense object repulsion.Scientific Reports, 14, 08 2024
2024
-
[19]
What demands attention in urban street scenes? from scene understanding towards road safety: A survey of vision-driven datasets and studies, 2025
Yaoqi Huang, Julie Stephany Berrio, Mao Shan, and Stewart Worrall. What demands attention in urban street scenes? from scene understanding towards road safety: A survey of vision-driven datasets and studies, 2025
2025
-
[20]
Ultralytics yolov8, 2023
Glenn Jocher, Ayush Chaurasia, and Jing Qiu. Ultralytics yolov8, 2023
2023
-
[21]
Ultralytics yolo11, 2024
Glenn Jocher and Jing Qiu. Ultralytics yolo11, 2024
2024
-
[22]
Klein, Milton K
Lawrence A. Klein, Milton K. Mills, and David Gibson. Traffic detector handbook: Third edition. volume ii, Oct 2006. Tech Report – FHWA-HRT-06-139
2006
-
[23]
Richard Landis and Gary G
J. Richard Landis and Gary G. Koch. The measurement of observer agreement for categorical data.Biometrics, 33(1):159–174, 1977
1977
-
[24]
Chen Li, Wei Liu, Ruoyu Guo, Xiaohui Yin, Kai Jiang, Yuning Du, Yuning Du, Liang Zhu, Bo Lai, Xin Hu, Dian Yu, and Yi Ma. Pp-ocrv3: More attempts for the improvement of ultra lightweight ocr system.arXiv preprint arXiv:2206.03001, 2022. 19
-
[25]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft coco: Common objects in context. In David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuytelaars, editors,Computer Vision – ECCV 2014, pages 740–755, Cham, 2014. Springer International Publishing
2014
-
[26]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Par...
2024
-
[27]
Deep transfer learning for intelligent vehicle perception: A survey
Xinyu Liu, Jinlong Li, Jin Ma, Huiming Sun, Zhigang Xu, Tianyun Zhang, and Hongkai Yu. Deep transfer learning for intelligent vehicle perception: A survey. Green Energy and Intelligent Transportation, 2(5):100125, 2023
2023
-
[28]
Rt-detrv2: Improved baseline with bag-of-freebies for real-time detection transformer, 2024
Wenyu Lv, Yian Zhao, Qinyao Chang, Kui Huang, Guanzhong Wang, and Yi Liu. Rt-detrv2: Improved baseline with bag-of-freebies for real-time detection transformer, 2024
2024
-
[29]
Box-level active detection
Mengyao Lyu, Jundong Zhou, Hui Chen, Yijie Huang, Dongdong Yu, Yaqian Li, Yandong Guo, Yuchen Guo, Liuyu Xiang, and Guiguang Ding. Box-level active detection. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 23766–23775, 2023
2023
-
[30]
Jatayu: A large-scale indian uav dataset for vehicle detection and tracking
Abhijnan Maji, Kummara Preetham, and Indrajit Ghosh. Jatayu: A large-scale indian uav dataset for vehicle detection and tracking. In2024 IEEE Interna- tional Conference on Electronics, Computing and Communication Technologies (CONECCT), pages 1–6, 2024
2024
-
[31]
Privacy policy and help center: automatic blurring of faces and license plates
Mapillary. Privacy policy and help center: automatic blurring of faces and license plates. https://www.mapillary.com/privacy. Accessed November 2025. See also https://help.mapillary.com/hc/en-us/articles/ 115001663705-Blurring-images-on-Mapillary
2025
-
[32]
A survey of video surveillance systems in smart city.Electronics, 12(17), 2023
Yanjinlkham Myagmar-Ochir and Wooseong Kim. A survey of video surveillance systems in smart city.Electronics, 12(17), 2023
2023
-
[33]
D-FINE: Redefine regression task of DETRs as fine-grained distribution refinement
Yansong Peng, Hebei Li, Peixi Wu, Yueyi Zhang, Xiaoyan Sun, and Feng Wu. D-FINE: Redefine regression task of DETRs as fine-grained distribution refinement. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[34]
Peppa, Tom Komar, Wen Xiao, Phil James, Craig Robson, Jin Xing, and Stuart Barr
Maria V. Peppa, Tom Komar, Wen Xiao, Phil James, Craig Robson, Jin Xing, and Stuart Barr. Towards an end-to-end framework of cctv-based urban traffic volume detection and prediction.Sensors, 21(2), 2021. 20
2021
-
[35]
Behzadan, and Tim Lomax
Yalong Pi, Nick Duffield, Amir H. Behzadan, and Tim Lomax. Visual recognition for urban traffic data retrieval and analysis in major events using convolutional neural networks.Computational Urban Science, 2(1):2, Jan 2022
2022
-
[36]
Rf-detr: Neural architecture search for real-time detection transformers, 2025
Isaac Robinson, Peter Robicheaux, Matvei Popov, Deva Ramanan, and Neehar Peri. Rf-detr: Neural architecture search for real-time detection transformers, 2025
2025
-
[37]
Square: A benchmark for research on computing crowd consensus.Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, 1(1):156–164, Nov
Aashish Sheshadri and Matthew Lease. Square: A benchmark for research on computing crowd consensus.Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, 1(1):156–164, Nov. 2013
2013
-
[38]
Scalability in Perception for Autonomous Driving: Waymo Open Dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Aleksei Timofeev, Scott Ettinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Yu Zhang, Jonathon Shlens, Zhifeng Chen, and Dragomir Anguelov. Scalability in Perception...
2020
-
[39]
Cityflow: A city- scale benchmark for multi-target multi-camera vehicle tracking and re-identification
Zheng Tang, Milind Naphade, Ming-Yu Liu, Xiaodong Yang, Stan Birchfield, Shuo Wang, Ratnesh Kumar, David Anastasiu, and Jenq-Neng Hwang. Cityflow: A city- scale benchmark for multi-target multi-camera vehicle tracking and re-identification. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8789–8798, 2019
2019
-
[40]
An image inpainting technique based on the fast marching method
Alexandru Telea. An image inpainting technique based on the fast marching method. Journal of Graphics Tools, 9(1):23–34, 2004
2004
-
[41]
Roy-Chowdhury
Anirudh Thatipelli, Shao-Yuan Lo, and Amit K. Roy-Chowdhury. Egocentric and exocentric methods: A short survey.Computer Vision and Image Understanding, 257:104371, 2025
2025
-
[42]
YOLOv12: Attention-centric real- time object detectors
Yunjie Tian, Qixiang Ye, and David Doermann. YOLOv12: Attention-centric real- time object detectors. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[43]
Annual tomtom traffic index: Unveiling data-driven insights from over 450 billion miles driven in 2024
TomTom. Annual tomtom traffic index: Unveiling data-driven insights from over 450 billion miles driven in 2024. https://www.tomtom.com/traffic-index/ranking/, Jan 2025. Online
2024
-
[44]
Girish Varma, Anbumani Subramanian, Anoop Namboodiri, Manmohan Chandraker, and C.V. Jawahar. Idd: A dataset for exploring problems of autonomous navigation in unconstrained environments. In2019 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1743–1751, 2019. 21
2019
-
[45]
Towards human-machine cooperation: Self-supervised sample mining for object detection
Keze Wang, Xiaopeng Yan, Dongyu Zhang, Lei Zhang, and Liang Lin. Towards human-machine cooperation: Self-supervised sample mining for object detection. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1605–1613, 2018
2018
-
[46]
what are you doing to ensure the privacy of people in the images?
Waymo Research. Waymo open dataset faq: “what are you doing to ensure the privacy of people in the images?”. https://waymo.com/open/faq/. Accessed November 2025
2025
-
[47]
Ua-detrac: A new benchmark and protocol for multi-object detection and tracking.Computer Vision and Image Understanding, 193:102907, 2020
Longyin Wen, Dawei Du, Zhaowei Cai, Zhen Lei, Ming-Ching Chang, Honggang Qi, Jongwoo Lim, Ming-Hsuan Yang, and Siwei Lyu. Ua-detrac: A new benchmark and protocol for multi-object detection and tracking.Computer Vision and Image Understanding, 193:102907, 2020
2020
-
[48]
Object detection by 3d aspectlets and occlusion reasoning
Yu Xiang and Silvio Savarese. Object detection by 3d aspectlets and occlusion reasoning. In2013 IEEE International Conference on Computer Vision Workshops, pages 530–537, 2013
2013
-
[49]
Damo-yolo : A report on real-time object detection design, 2022
Xianzhe Xu, Yiqi Jiang, Weihua Chen, Yilun Huang, Yuan Zhang, and Xiuyu Sun. Damo-yolo : A report on real-time object detection design, 2022
2022
-
[50]
Bdd100k: A diverse driving dataset for heterogeneous multitask learning
Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, and Trevor Darrell. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), page 2633–2642. IEEE, June 2020
2020
-
[51]
City-scale vehicle trajectory data from traffic camera videos.Scientific Data, 10(1):711, Oct 2023
Fudan Yu, Huan Yan, Rui Chen, Guozhen Zhang, Yu Liu, Meng Chen, and Yong Li. City-scale vehicle trajectory data from traffic camera videos.Scientific Data, 10(1):711, Oct 2023
2023
-
[52]
Costeira, and José M
Shanghang Zhang, Guanhang Wu, João P. Costeira, and José M. F. Moura. Under- standing traffic density from large-scale web camera data. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4264–4273, 2017
2017
-
[53]
Vision technologies with applications in traffic surveillance systems: A holistic survey.ACM Comput
Wei Zhou, Li Yang, Lei Zhao, Runyu Zhang, Yifan Cui, Hongpu Huang, Kun Qie, and Chen Wang. Vision technologies with applications in traffic surveillance systems: A holistic survey.ACM Comput. Surv., 58(3), September 2025
2025
-
[54]
Multi-task crowdsourcing via an optimization framework.ACM Trans
Yao Zhou, Lei Ying, and Jingrui He. Multi-task crowdsourcing via an optimization framework.ACM Trans. Knowl. Discov. Data, 13(3), May 2019. 22 A Release Notes The datasets and models are posted on Huggingface underhttps://huggingface.co/ iisc-aim/. The datasets are under https://huggingface.co/datasets/iisc-aim/ BMD-45while models are underhttps://hugging...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.