Recognition: unknown
How Do Software Engineering Students Use Generative AI in Real-World Capstone Projects? An Empirical Baseline Study
Pith reviewed 2026-05-08 03:05 UTC · model grok-4.3
The pith
Software engineering students use generative AI across the full project lifecycle but emphasize verification and keeping independent understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Generative AI appears throughout the software engineering lifecycle in student capstone work, producing distinct workflows; students recommend targeted use cases paired with verification steps and maintenance of personal comprehension; clients endorse the tools yet require teams to demonstrate understanding, deliver quality, and safeguard data; and courses will need explicit guidelines, AI literacy support, and team governance roles to handle the shift.
What carries the argument
Mixed-method surveys of self-reported attitudes, usage prevalence, workflows, benefits, risks, and client expectations collected from 150 students and stakeholders in one four-month real-world capstone course.
If this is right
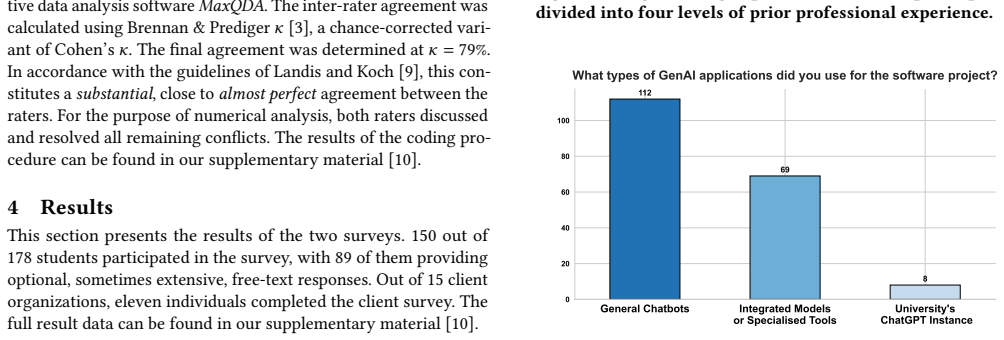
- Generative AI use spans requirements, design, coding, testing, and documentation, creating identifiable workflow clusters rather than uniform adoption.
- Students converge on verification of outputs and preservation of independent understanding as core responsible-use rules.
- Clients voice strong support for AI assistance conditional on teams retaining comprehension and meeting quality plus data-protection standards.
- Course design should add explicit responsible-use guidelines, targeted literacy resources, and designated team roles for AI governance.
Where Pith is reading between the lines
- Educators could test whether assigning separate reflection tasks on AI-assisted versus non-assisted work changes learning outcomes.
- The observed workflow differences suggest that phase-specific training modules might reduce uneven adoption across teams.
- Client data-protection concerns point to a need for explicit privacy modules inside capstone syllabi.
Load-bearing premise
Self-reported survey answers from one course accurately reflect real usage behaviors and perceptions without recall or social-desirability bias and can be generalized beyond that single setting.
What would settle it
A follow-up study that logs actual tool invocations in comparable capstone projects and finds large gaps between logged behavior and the survey reports, or a replication across several independent courses that produces inconsistent client expectations or workflow patterns.
Figures




read the original abstract
Real-world Capstone Projects (RWCPs) are a key component of software engineering education, enabling students to develop software for external clients under authentic conditions. Their high ecological validity, combined with substantial variation in domains, technologies, and stakeholders, typically requires flexible and minimally prescriptive teaching approaches. The rapid integration of generative AI (GenAI) into professional software development adds new challenges: students are expected to use AI tools that are common in practice, yet unguided use may affect learning, collaboration, and consistency in ways that are not yet well understood. To establish an empirical baseline for responsible GenAI integration, we conducted a large-scale study of self-determined GenAI use in an undergraduate RWCP course. The module involved 178 students working in 18 teams across 15 client projects over four months, with GenAI use explicitly permitted. We collected mixed-method survey data from 150 students on attitudes, usage prevalence, workflows, use cases, and perceived benefits and risks, and surveyed client stakeholders regarding expectations and concerns. Our findings provide (1) a characterization of GenAI practices across the software engineering lifecycle, including a distinction between emerging workflows; (2) student-recommended use cases and responsible-use directives emphasizing verification and maintaining independent understanding; (3) client perspectives highlighting strong support for GenAI use but clear expectations regarding understanding, quality, and data protection; and (4) implications for future course iterations, including the need for explicit responsible-use guidelines, targeted AI literacy resources, and team-level governance roles. This study offers a status quo baseline for evidence-based pedagogical interventions in the era of GenAI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from a mixed-methods survey of 150 students (out of 178) and client stakeholders in a single undergraduate real-world capstone project course where GenAI use was explicitly permitted. It characterizes self-reported GenAI practices across the software engineering lifecycle, distinguishes emerging workflows, presents student-recommended use cases and responsible-use directives, reports client expectations around understanding/quality/data protection, and derives pedagogical implications for guidelines, AI literacy resources, and team governance roles.
Significance. If the self-report data accurately reflect actual behaviors, the study supplies a useful empirical baseline for GenAI integration in authentic SE capstone settings. The large sample, client perspective, and ecological validity of the four-month, multi-client design are strengths that could inform curriculum development in similar courses.
major comments (3)
- [§3] §3 (Data Collection and Analysis): The manuscript provides no description of survey instrument validation, pilot testing, or inter-rater reliability for qualitative coding of open responses on workflows and recommendations. Because the four main findings rest entirely on these self-reports, the absence of these details directly undermines confidence in the prevalence numbers and workflow distinctions.
- [§4] §4 (Results): The characterization of practices and the distinction between emerging workflows are derived solely from retrospective self-reports without triangulation against project artifacts, commit logs, or observational data. In a permitted-use setting this leaves the central claims vulnerable to recall and social-desirability bias, as noted in the skeptic's assessment.
- [§5] §5 (Implications and Generalizability): The recommendations for responsible-use guidelines and team-level governance are presented as broadly applicable, yet the study is limited to one institution and one cohort; the manuscript does not discuss how the single-case design constrains external validity of the reported patterns.
minor comments (2)
- [Abstract and §3] The abstract states the response rate (150/178) but the methods section should explicitly report how non-response was handled and whether any weighting or sensitivity analysis was performed.
- [§4] Table or figure captions for workflow diagrams should include the exact number of respondents per category to allow readers to assess the robustness of the emerging-workflow distinction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions we will make to improve transparency and the treatment of limitations.
read point-by-point responses
-
Referee: [§3] §3 (Data Collection and Analysis): The manuscript provides no description of survey instrument validation, pilot testing, or inter-rater reliability for qualitative coding of open responses on workflows and recommendations. Because the four main findings rest entirely on these self-reports, the absence of these details directly undermines confidence in the prevalence numbers and workflow distinctions.
Authors: We agree that greater methodological transparency is needed. In the revised manuscript we will add a dedicated subsection in §3 that describes how the survey items were adapted from prior instruments on GenAI use in software engineering education and tailored to the capstone context. For the qualitative coding of open responses we will report that the authors applied thematic analysis with iterative consensus discussions to resolve disagreements. We will explicitly note that a formal pilot test was not performed owing to course scheduling constraints and that inter-rater reliability statistics were not computed; both points will be listed as limitations. revision: partial
-
Referee: [§4] §4 (Results): The characterization of practices and the distinction between emerging workflows are derived solely from retrospective self-reports without triangulation against project artifacts, commit logs, or observational data. In a permitted-use setting this leaves the central claims vulnerable to recall and social-desirability bias, as noted in the skeptic's assessment.
Authors: The study was intentionally scoped as a large-scale mixed-methods survey to obtain student-reported practices and perceptions across 15 heterogeneous client projects; collecting consistent artifact or observational data would have required a substantially different research design. In the revision we will expand the Limitations section to discuss recall bias and social-desirability bias in detail and to qualify the prevalence figures and workflow distinctions accordingly. We maintain that the self-report data still constitute a useful empirical baseline for an authentic, permitted-use setting, while acknowledging that future work could strengthen validity through triangulation. revision: partial
-
Referee: [§5] §5 (Implications and Generalizability): The recommendations for responsible-use guidelines and team-level governance are presented as broadly applicable, yet the study is limited to one institution and one cohort; the manuscript does not discuss how the single-case design constrains external validity of the reported patterns.
Authors: We accept that the single-institution, single-cohort design limits external validity. The revised manuscript will include an explicit paragraph in the Implications and Limitations section that states the constraints arising from the particular institutional policy, client mix, and four-month timeline, while noting the compensating strength of ecological validity. Recommendations will be reframed as context-informed implications rather than universally prescriptive. revision: yes
- The study collected only post-project self-report data; objective triangulation against commit logs, code artifacts, or observational records cannot be added retrospectively without a new data-collection effort.
Circularity Check
No significant circularity in empirical survey study
full rationale
This paper is a purely descriptive empirical study relying on mixed-method survey data from 150 students and client stakeholders in a single capstone course. It contains no equations, derivations, fitted parameters, ansatzes, or uniqueness theorems. All findings (characterizations of workflows, recommendations, and implications) are presented as direct summaries and interpretations of the collected responses without any reduction to inputs by construction or self-referential definitions. The central claims rest on external data collection rather than internal logical closure, making the work self-contained against its own benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Self-reported survey responses accurately reflect students' actual GenAI usage, attitudes, and perceptions.
- domain assumption The specific RWCP course setting and participant pool are representative of typical software engineering capstone experiences.
Reference graph
Works this paper leans on
-
[1]
Khawla Ali Abd Al-Hameed. 2022. Spearman’s correlation coefficient in statistical analysis.International Journal of Nonlinear Analysis and Applications13, 1 (2022), 3249–3255
2022
-
[2]
María Cecilia Bastarrica, Daniel Perovich, and Maíra Marques Samary. 2017. What Can Students Get from a Software Engineering Capstone Course?. In 2017 IEEE/ACM 39th International Conference on Software Engineering: Software Engineering Education and Training Track (ICSE-SEET). 137–145. doi:10.1109/ICSE- SEET.2017.15
-
[3]
Brennan and Dale J
Robert L. Brennan and Dale J. Prediger. 1981. Coefficient Kappa: Some Uses, Misuses, and Alternatives.Educational and Psychological Measurement41, 3 (1981), 687–699
1981
-
[4]
Rudrajit Choudhuri, Dylan Liu, Igor Steinmacher, Marco Gerosa, and Anita Sarma. 2024. How far are we? The triumphs and trials of generative AI in learning software engineering. InProceedings of the IEEE/ACM 46th international conference on software engineering. 1–13
2024
-
[5]
Rudrajit Choudhuri, Ambareesh Ramakrishnan, Amreeta Chatterjee, Bianca Trinkenreich, Igor Steinmacher, Marco Gerosa, and Anita Sarma. 2025. Insights from the frontline: Genai utilization among software engineering students. In 2025 IEEE/ACM 37th International Conference on Software Engineering Education and Training (CSEE&T). IEEE, 1–12
2025
-
[6]
Marian Daun and Jennifer Brings. 2023. How ChatGPT will change software engineering education. InProceedings of the 2023 Conference on Innovation and Technology in Computer Science Education V. 1. 110–116
2023
-
[7]
Paul Denny, James Prather, Brett A Becker, James Finnie-Ansley, Arto Hellas, Juho Leinonen, Andrew Luxton-Reilly, Brent N Reeves, Eddie Antonio Santos, and Sami Sarsa. 2024. Computing education in the era of generative AI.Commun. ACM67, 2 (2024), 56–67
2024
-
[8]
Luis A Gonzalez, Andres Neyem, Ignacio Contreras-McKay, and Danilo Molina
-
[9]
Improving learning experiences in software engineering capstone courses using artificial intelligence virtual assistants.Computer Applications in Engineer- ing Education30, 5 (2022), 1370–1389
2022
-
[10]
Richard Landis and Gary G
J. Richard Landis and Gary G. Koch. 1977. The Measurement of Observer Agree- ment for Categorical Data.Biometrics33, 1 (1977), 159–174
1977
-
[11]
Aalbers, et al., Axfoundation/strax: v1.6.4 (2024)
Michael Mircea, Jakob Droste, Elisa Schmid, and Kurt Schneider. 2026."How Do Software Engineering Students Use Generative AI in Real-World Capstone Projects? An Empirical Baseline Study" - Supplementary Material. doi:10.5281/zenodo. 18836366
-
[12]
MIT NANDA. 2025. State of AI in Business 2025.Preprint at https://www. artificialintelligence-news. com/wp-content/uploads/2025/08/ai_report_2025. pdf (2025)
2025
-
[13]
Sriraam Natarajan, Saurabh Mathur, Sahil Sidheekh, Wolfgang Stammer, and Kristian Kersting. 2025. Human-in-the-loop or AI-in-the-loop? Automate or Collaborate?. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 28594–28600
2025
-
[14]
Andres Neyem, Juan Pablo Sandoval Alcocer, Marcelo Mendoza, Leonardo Centellas-Claros, Luis A Gonzalez, and Carlos Paredes-Robles. 2024. Explor- ing the impact of generative ai for standup report recommendations in software capstone project development. InProceedings of the 55th ACM Technical Sympo- sium on Computer Science Education V. 1. 951–957
2024
-
[15]
James Robertson and Suzanne Robertson. 2000. Volere.Requirements Specification Templates(2000)
2000
-
[16]
Nimisha Roy, Omojokun Olufisayo, and Oleksandr Horielko. 2025. Empowering Future Software Engineers: Integrating AI Tools into Advanced CS Curriculum. In Proceedings of the 56th ACM Technical Symposium on Computer Science Education V. 2. 1747–1747
2025
-
[17]
Johnny Saldaña. 2021. The coding manual for qualitative researchers. (2021)
2021
-
[18]
Mario Simaremare and Henry Edison. 2024. The state of generative AI adoption from software practitioners’ perspective: An empirical study. In2024 50th Eu- romicro Conference on Software Engineering and Advanced Applications (SEAA). IEEE, 106–113
2024
-
[19]
Charles Spearman. 1904. The Proof and Measurement of Association between Two Things.The American Journal of Psychology15, 1 (1904), 72–101. doi:10. 2307/1412159
1904
-
[20]
Saara Tenhunen, Tomi Männistö, Matti Luukkainen, and Petri Ihantola. 2023. A systematic literature review of capstone courses in software engineering. Information and Software Technology159 (2023), 107191
2023
-
[21]
2012.Experimentation in software engineering
Claes Wohlin, Per Runeson, Martin Höst, Magnus C Ohlsson, Björn Regnell, and Anders Wesslén. 2012.Experimentation in software engineering. Vol. 236. Springer. Received 02.03.2026; revised 27.04.2026; accepted 30.04.2026
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.