Recognition: unknown
Probing CLIP's Comprehension of 360-Degree Textual and Visual Semantics
Pith reviewed 2026-05-08 04:22 UTC · model grok-4.3
The pith
CLIP models understand explicit 360-degree text labels but fail to keep semantic scores stable when panoramic images are rotated horizontally.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CLIP models effectively leverage explicit textual identifiers, demonstrating an understanding of 360-degree textual semantics; and CLIP models fail to robustly preserve semantic alignment under horizontal circular shifts, indicating limited comprehension of 360-degree visual semantics. A LoRA-based fine-tuning framework that explicitly instills invariance to circular shifts improves the second capability, although it produces a slight degradation in original semantic evaluation performance.
What carries the argument
Keyword manipulation on captions combined with horizontal circular shifts of varying magnitudes on panoramic images, scored by cosine similarity in CLIP space and analyzed statistically across model variants, followed by LoRA adapters that enforce shift invariance.
Load-bearing premise
Horizontal circular shifts of panoramic images leave their underlying semantic content unchanged and that inserting or removing 360-related keywords affects only the targeted 360 semantics.
What would settle it
Collect a held-out set of real 360-degree images, apply random horizontal shifts, recompute CLIP similarity to matched captions, and check whether the score distribution remains statistically identical before and after the shifts.
Figures


















read the original abstract
The dream of instantly creating rich 360-degree panoramic worlds from text is rapidly becoming a reality, yet a crucial gap exists in our ability to reliably evaluate their semantic alignment. Contrastive Language-Image Pre-training (CLIP) models, standard AI evaluators, predominantly trained on perspective image-text pairs, face an open question regarding their understanding of the unique characteristics of 360-degree panoramic image-text pairs. This paper addresses this gap by first introducing two concepts: \emph{360-degree textual semantics}, semantic information conveyed by explicit format identifiers, and \emph{360-degree visual semantics}, invariant semantics under horizontal circular shifts. To probe CLIP's comprehension of these semantics, we then propose novel evaluation methodologies using keyword manipulation and horizontal circular shifts of varying magnitudes. Rigorous statistical analyses across popular CLIP configurations reveal that: (1) CLIP models effectively leverage explicit textual identifiers, demonstrating an understanding of 360-degree textual semantics; and (2) CLIP models fail to robustly preserve semantic alignment under horizontal circular shifts, indicating limited comprehension of 360-degree visual semantics. To address this limitation, we propose a LoRA-based fine-tuning framework that explicitly instills invariance to circular shifts. Our fine-tuned models exhibit improved comprehension of 360-degree visual semantics, though with a slight degradation in original semantic evaluation performance, highlighting a fundamental trade-off in adapting CLIP to 360-degree panoramic images. Code is available at https://github.com/littlewhitesea/360Semantics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the concepts of 360-degree textual semantics (semantic information from explicit format identifiers in text) and 360-degree visual semantics (invariant semantics under horizontal circular shifts of panoramic images). It proposes evaluation methods using keyword manipulation and horizontal circular shifts of varying magnitudes to probe CLIP models, finding that CLIP effectively leverages textual identifiers but fails to robustly preserve alignment under shifts. A LoRA-based fine-tuning framework is introduced to instill shift invariance, yielding improved 360 visual semantics performance at the cost of a slight degradation in standard semantic evaluation.
Significance. If the evaluation methodology is robust, this work identifies a meaningful limitation in CLIP for 360-degree panoramic content, which is increasingly relevant for text-to-360 generation. The empirical results across CLIP configurations and the proposed adaptation method provide actionable insights, with the public code release at https://github.com/littlewhitesea/360Semantics supporting reproducibility.
major comments (2)
- [Probing methodology for 360-degree visual semantics] The definition of 360-degree visual semantics as invariance under horizontal circular shifts assumes that such shifts preserve underlying semantic content exactly. In equirectangular projections, even small rolls can reposition polar distortion regions relative to CLIP's fixed patch grid or expose seam artifacts; these are non-semantic changes that could legitimately alter embeddings. This assumption is load-bearing for attributing any cosine-similarity drop to missing invariance rather than altered input (see the probing methodology and results sections).
- [Experimental setup and results] The abstract reports 'rigorous statistical analyses' and a 'performance trade-off after fine-tuning,' yet the support for the central claims cannot be fully verified without the full methods, exact shift magnitudes, datasets, and statistical tests (e.g., p-values or effect sizes). Please expand the experimental setup section to include these details.
minor comments (2)
- [Abstract] The abstract could briefly quantify the number of CLIP configurations tested and the magnitude of the observed trade-off to give readers immediate context.
- [Keyword manipulation procedure] Clarify whether the keyword manipulation for textual semantics introduces any unintended changes in sentence structure or length that might confound the isolation of format-identifier effects.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for highlighting areas where the manuscript can be strengthened. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Probing methodology for 360-degree visual semantics] The definition of 360-degree visual semantics as invariance under horizontal circular shifts assumes that such shifts preserve underlying semantic content exactly. In equirectangular projections, even small rolls can reposition polar distortion regions relative to CLIP's fixed patch grid or expose seam artifacts; these are non-semantic changes that could legitimately alter embeddings. This assumption is load-bearing for attributing any cosine-similarity drop to missing invariance rather than altered input (see the probing methodology and results sections).
Authors: We acknowledge that equirectangular projections introduce non-semantic variations under horizontal shifts, including changes in polar distortion relative to the patch grid and potential seam artifacts. Our definition of 360-degree visual semantics relies on the standard assumption in panoramic vision that horizontal circular shifts should preserve semantics for a rotationally invariant model. To address the concern, we will revise the probing methodology section to explicitly discuss these potential confounds, provide visualizations of shifted images highlighting distortion effects, and include a control analysis (e.g., comparing horizontal vs. vertical shifts) to isolate the contribution of shift invariance from projection artifacts. This will strengthen the attribution of observed similarity drops primarily to CLIP's limited robustness rather than input alterations. revision: partial
-
Referee: [Experimental setup and results] The abstract reports 'rigorous statistical analyses' and a 'performance trade-off after fine-tuning,' yet the support for the central claims cannot be fully verified without the full methods, exact shift magnitudes, datasets, and statistical tests (e.g., p-values or effect sizes). Please expand the experimental setup section to include these details.
Authors: We agree that the current experimental setup section lacks sufficient detail for full verification and reproducibility. In the revised manuscript, we will expand this section to specify: the exact horizontal shift magnitudes tested (multiples of 30° from 0° to 180°), the datasets used (including sources of panoramic image-text pairs and any preprocessing), and the statistical procedures (e.g., paired t-tests or Wilcoxon tests with reported p-values, effect sizes such as Cohen's d, and confidence intervals). The 'rigorous statistical analyses' refer to these tests applied to cosine similarity differences across conditions and models. We will also update the code repository to include the exact scripts and random seeds used for these analyses. revision: yes
Circularity Check
No circularity; purely empirical probing with independent measurements
full rationale
The paper defines 360-degree textual semantics (via explicit format identifiers) and 360-degree visual semantics (via invariance under horizontal circular shifts), then applies keyword manipulation and shift-based tests to pre-trained CLIP models and reports direct statistical outcomes. No equations, predictions, or first-principles derivations reduce the findings to quantities fitted from the same data. The LoRA fine-tuning step is a separate intervention whose results are measured independently. No load-bearing self-citations or self-definitional reductions appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Horizontal circular shifts of 360-degree images preserve semantic content for the purpose of alignment evaluation
invented entities (2)
-
360-degree textual semantics
no independent evidence
-
360-degree visual semantics
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ai, H., Cao, Z., and Wang, L. A survey of representation learning, optimization strategies, and applications for omnidirectional vision.arXiv preprint arXiv:2502.10444,
-
[2]
Pali: A jointly-scaled multilingual language-image model
Chen, X., Wang, X., Changpinyo, S., Piergiovanni, A. J., Padlewski, P., Salz, D., Goodman, S., Grycner, A., Mustafa, B., Beyer, L., et al. Pali: A jointly-scaled multilingual language-image model.arXiv preprint arXiv:2209.06794, 2022a. Chen, Z., Wang, G., and Liu, Z. Text2light: Zero-shot text- driven hdr panorama generation.ACM Transactions on Graphics (...
-
[3]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review arXiv 2010
-
[4]
arXiv preprint arXiv:2309.17425 (2023) 3, 4, 9, 11, 20, 21, 22
Fang, A., Jose, A. M., Jain, A., Schmidt, L., Toshev, A., and Shankar, V . Data filtering networks.arXiv preprint arXiv:2309.17425,
-
[5]
Feng, M., Liu, J., Cui, M., and Xie, X. Diffusion360: Seamless 360 degree panoramic image generation based on diffusion models.arXiv preprint arXiv:2311.13141,
-
[6]
Clipscore: A reference-free evaluation metric for image captioning
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., and Choi, Y . Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pp. 7514–7528,
2021
-
[7]
Decoupled Weight Decay Regularization
Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review arXiv
-
[8]
Fastscene: Text-driven fast 3d indoor scene generation via panoramic gaussian splatting
9 Probing CLIP’s Comprehension of 360-Degree Textual and Visual Semantics Ma, Y ., Zhan, D., and Jin, Z. Fastscene: Text-driven fast 3d indoor scene generation via panoramic gaussian splatting. arXiv preprint arXiv:2405.05768,
-
[9]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., M ¨uller, J., Penna, J., and Rombach, R. Sdxl: Im- proving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952,
work page internal anchor Pith review arXiv
-
[10]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., and Chen, M. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3,
work page internal anchor Pith review arXiv
-
[11]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Schuhmann, C., Vencu, R., Beaumont, R., Kaczmarczyk, R., Mullis, C., Katta, A., Coombes, T., Jitsev, J., and Komatsuzaki, A. Laion-400m: Open dataset of clip- filtered 400 million image-text pairs.arXiv preprint arXiv:2111.02114,
work page internal anchor Pith review arXiv
-
[12]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Sun, Q., Fang, Y ., Wu, L., Wang, X., and Cao, Y . Eva- clip: Improved training techniques for clip at scale.arXiv preprint arXiv:2303.15389,
work page internal anchor Pith review arXiv
- [13]
-
[14]
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M. F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y ., Mustafa, B., et al. Siglip 2: Multilingual vision-language encoders with improved semantic under- standing, localization, and dense features.arXiv preprint arXiv:2502.14786,
work page internal anchor Pith review arXiv
-
[15]
Customizing 360-degree panoramas through text-to-image diffusion models
Wang, H., Xiang, X., Fan, Y ., and Xue, J.-H. Customizing 360-degree panoramas through text-to-image diffusion models. InProceedings of the IEEE/CVF Winter Confer- ence on Applications of Computer Vision, pp. 4933–4943, 2024a. Wang, H., Xiang, X., Xia, W., and Xue, J.-H. A survey on text-driven 360-degree panorama generation.arXiv preprint arXiv:2502.14799,
-
[16]
360- degree panorama generation from few unregistered nfov images.arXiv preprint arXiv:2308.14686,
Wang, J., Chen, Z., Ling, J., Xie, R., and Song, L. 360- degree panorama generation from few unregistered nfov images.arXiv preprint arXiv:2308.14686,
-
[17]
Clip in mirror: Disentangling text from visual images through reflection.Advances in Neural In- formation Processing Systems, 37:24523–24546, 2024b
Wang, T., Yang, Y ., Yang, L., Lin, S., Zhang, J., Guo, G., and Zhang, B. Clip in mirror: Disentangling text from visual images through reflection.Advances in Neural In- formation Processing Systems, 37:24523–24546, 2024b. Weissig, C., Schreer, O., Eisert, P., and Kauff, P. The ultimate immersive experience: panoramic 3d video ac- quisition. InAdvances in...
2012
-
[18]
10 Probing CLIP’s Comprehension of 360-Degree Textual and Visual Semantics Xu, H., Xie, S., Tan, X. E., Huang, P.-Y ., Howes, R., Sharma, V ., Li, S.-W., Ghosh, G., Zettlemoyer, L., and Feicht- enhofer, C. Demystifying clip data.arXiv preprint arXiv:2309.16671,
-
[19]
Yang, S., Tan, J., Zhang, M., Wu, T., Li, Y ., Wetzstein, G., Liu, Z., and Lin, D. Layerpano3d: Layered 3d panorama for hyper-immersive scene generation.arXiv preprint arXiv:2408.13252,
-
[20]
Ye, W., Ji, C., Chen, Z., Gao, J., Huang, X., Zhang, S.- H., Ouyang, W., He, T., Zhao, C., and Zhang, G. Diff- pano: Scalable and consistent text to panorama generation with spherical epipolar-aware diffusion.arXiv preprint arXiv:2410.24203,
-
[21]
<360panorama>,
11 Probing CLIP’s Comprehension of 360-Degree Textual and Visual Semantics A. More Implementation Details A.1. Flowchart of Dataset Generation Fig. 9 shows the flowchart to produce the two paired image-text datasets (360 realand360 syn) used in our evaluation experiments. real-world 360-degree panoramic images (2386 images) augmented text prompts synthesi...
2012
-
[22]
results for different CLIP models on the two paired image-text datasets, where the null hypothesis is the distribution of the score differences ( s−s u) is normal, and the significance level (α) is 0.01. The p-values less thanαare in bold. U ∗ =“”U ∗ =“image,” ViT 360 real 360 syn 360 real 360 syn statistic p-value statistic p-value statistic p-value stat...
-
[23]
The results, detailed in Table 10, indicate that for all datasets, the p-values were below a commonly used significance level (α = 0.01)
for evaluating the null hypothesis that|s−s δj | is statistically greater than or equal to the stability bound β, we assessed the normality of the absolute score differences (|s−s δj |) between the original and shifted CLIP scores using the Shapiro-Wilk test (Shapiro & Wilk, 1965). The results, detailed in Table 10, indicate that for all datasets, the p-v...
1965
-
[24]
The p-values less thanαare in bold
results under horizontal circular shift of various δj pixels for different CLIP models on the360 syndataset, where the null hypothesis ( H0) is that |s−s δj | is greater than or equal to the stability boundβ, and the significance level (α) is 0.01. The p-values less thanαare in bold. ViTβ δ j W/8 2W/8 3W/8 4W/8 5W/8 6W/8 7W/8 B/32 1.7699 statistic844832 1...
-
[25]
The p-values less thanαare in bold
results under horizontal circular shift of various δj pixels for different CLIP models on the360 syndataset, where the null hypothesis ( H0) is that |s−s δj | is greater than or equal to the stability boundβ, and the significance level (α) is 0.01. The p-values less thanαare in bold. ViTβ δ j W/8 2W/8 3W/8 4W/8 5W/8 6W/8 7W/8 B/32 1.0822 statistic792795 1...
1995
-
[26]
Generalization Capability of Fine-Tuned Models G.1
λViTβ δ j W/8 2W/8 3W/8 4W/8 5W/8 6W/8 7W/8 0.9831 B/32 1.0822 statistic0 0 0 0 0 0 0 p-value0 0 0 0 0 0 0 0.9839 B/16 1.0704 statistic0 0 0 0 0 0 0 p-value0 0 0 0 0 0 0 0.9882 L/14 1.1995 statistic0 0 0 0 0 0 0 p-value0 0 0 0 0 0 0 21 Probing CLIP’s Comprehension of 360-Degree Textual and Visual Semantics G. Generalization Capability of Fine-Tuned Models...
1995
-
[27]
a long table with lots of plants in a greenhouse
and their corresponding perspective images (1024×512 resolution) synthesized with SDXL (Podell et al., 2023), which we refer to asper syn. Fig. 16 shows examples of the image-text pairs together with horizontally flipped and circular-shifted versions. Unlike 360-degree panoramic images, circular shifts in perspective images introduce clear semantic distor...
2023
-
[28]
<360panorama>, a large room with a large window
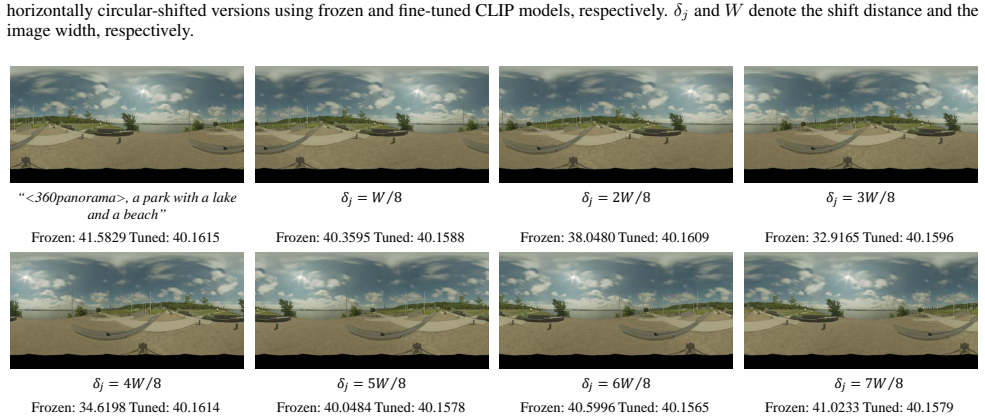
For frozen CLIP models, the scores vary noticeably across different circular shifts, indicating that they fail to preserve stable semantic alignment under this transformation, consistent with our statistical results. In contrast, our fine-tuned models remain stable scores across all shift magnitudes, demonstrating a stable and robust understanding of 360-...
2080
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.