Recognition: unknown
Diffusion-Guided Feature Selection via Nishimori Temperature: Noise-Based Spectral Embedding
Pith reviewed 2026-05-08 04:09 UTC · model grok-4.3
The pith
NBSE locates the Nishimori temperature on a similarity graph to embed features into one dimension for selecting non-redundant representatives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NBSE constructs a sparse similarity graph on the samples and identifies the Nishimori temperature beta_N at which the Bethe Hessian becomes singular. The corresponding smallest eigenvector captures the dominant mode of an intrinsically degree-corrected diffusion process on the graph, naturally reweighting nodes to avoid hub dominance. By transposing the data matrix and repeating the procedure in feature space, the method yields a one-dimensional spectral embedding that reveals groups of redundant or semantically related dimensions. Balanced binning then selects one representative per group. Coloured Gaussian perturbations are proved to shift beta_N by at most O(sigma bar squared), and the on
What carries the argument
The Nishimori temperature beta_N, the critical inverse temperature at which the Bethe Hessian matrix becomes singular; its smallest eigenvector supplies the one-dimensional embedding of the dominant diffusion mode on the degree-corrected similarity graph.
If this is right
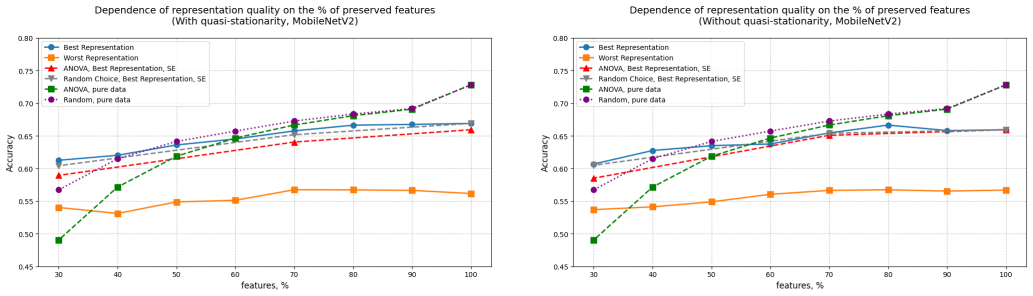
- The method allows retention of only 30 percent of features on EfficientNet-B4 embeddings while keeping accuracy drop below 1 percent.
- NBSE outperforms ANOVA F-test and random selection by up to 6.8 percent in preserved classification accuracy under compression.
- Feature selection becomes possible without exhaustive greedy search by using the spectral embedding to identify redundancy groups.
- The noise-robustness guarantee extends the applicability of the embedding to measurement-noisy data sources.
Where Pith is reading between the lines
- The same diffusion-mode embedding could be tested on non-image high-dimensional data such as gene-expression matrices or text token embeddings to check whether degree correction remains effective.
- If the one-dimensional embedding reliably surfaces semantic clusters, similar Nishimori-based constructions might apply to other graph-based tasks like clustering or anomaly detection.
- Connecting the Bethe Hessian singularity to feature redundancy suggests possible links between phase-transition phenomena and dimensionality reduction that could be explored on synthetic graphs with known redundancy structure.
Load-bearing premise
The smallest eigenvector of the Bethe Hessian at the Nishimori temperature reliably captures the dominant mode of an intrinsically degree-corrected diffusion process on the constructed similarity graph, and balanced binning on the resulting embedding separates redundant dimensions without losing task-relevant information.
What would settle it
An experiment measuring a shift in beta_N larger than O(sigma bar squared) under controlled coloured Gaussian perturbations on the similarity graph, or a dataset where NBSE-selected features produce a larger accuracy drop than random selection at the same compression ratio.
Figures


read the original abstract
We propose Noise-Based Spectral Embedding (NBSE), a physics-informed framework for selecting informative features from high-dimensional data without greedy search. NBSE constructs a sparse similarity graph on the samples and identifies the Nishimori temperature $\beta_N$ the critical inverse temperature at which the Bethe Hessian becomes singular. The corresponding smallest eigenvector captures the dominant mode of an intrinsically degree-corrected diffusion process, naturally reweighting nodes to prevent hub dominance. By transposing the data matrix and applying NBSE in feature space, we obtain a one-dimensional spectral embedding that reveals groups of redundant or semantically related dimensions; balanced binning then selects one representative per group. We prove that coloured Gaussian perturbations shift $\beta_N$ by at most $O(\bar\sigma^2)$, guaranteeing robustness to measurement noise. Experiments on ImageNet embeddings from MobileNetV2 and EfficientNet-B4 show that NBSE preserves classification accuracy even under aggressive compression: on EfficientNet-B4 the accuracy drop is below $1\%$ when retaining only $30\%$ of features, outperforming ANOVA $F$-test and random selection by up to $6.8\%$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Noise-Based Spectral Embedding (NBSE) for feature selection in high-dimensional data. It builds a sparse similarity graph on samples, identifies the Nishimori temperature β_N as the critical inverse temperature where the Bethe Hessian becomes singular, extracts the smallest eigenvector to obtain a 1D embedding (after transposing to feature space), and applies balanced binning to select representative features from redundant groups. The central claims are a proof that coloured Gaussian perturbations shift β_N by at most O(σ̄²) and experimental results on ImageNet embeddings from MobileNetV2 and EfficientNet-B4 showing accuracy preservation under aggressive compression (e.g., <1% drop at 30% features on EfficientNet-B4, outperforming ANOVA F-test and random selection by up to 6.8%).
Significance. If the noise-robustness bound and the eigenvector-to-diffusion mapping hold, NBSE offers a parameter-free, physics-informed alternative to greedy or statistical feature selection methods with explicit guarantees against measurement noise. The experimental demonstration on deep network embeddings suggests practical value for dimensionality reduction in computer vision pipelines. Strengths include the attempt to derive a concrete perturbation bound and the use of real-world model embeddings rather than synthetic data.
major comments (3)
- [§3] §3 (Theoretical Analysis): The abstract and introduction state a proof that coloured Gaussian perturbations shift β_N by at most O(σ̄²), but the manuscript provides no derivation, intermediate steps, or explicit assumptions on the perturbation model and the singularity condition. This bound is load-bearing for the noise-robustness guarantee and must be supplied in full.
- [§2.2] §2.2 (Method): The claim that the smallest eigenvector of the Bethe Hessian at β_N 'captures the dominant mode of an intrinsically degree-corrected diffusion process' on the similarity graph (and its transpose) is asserted without a derivation linking the eigenvector equation to the diffusion operator or showing why this holds under the chosen sparse graph construction. This unverified mapping directly supports the 1D embedding and binning step; its absence undermines both the theoretical motivation and the interpretation of the experimental accuracy preservation.
- [§4] §4 (Experiments): The reported accuracy figures (e.g., <1% drop retaining 30% features on EfficientNet-B4, 6.8% margin over baselines) are presented without error bars, details on the graph-construction algorithm (sparsity threshold, similarity kernel), binning procedure, or number of random seeds. These omissions make it impossible to evaluate whether the observed margins are statistically reliable or sensitive to unspecified implementation choices.
minor comments (2)
- [§2] The definition of β_N and the procedure for detecting the singularity of the Bethe Hessian should be stated as an explicit equation or algorithm, including any numerical tolerance used.
- [Notation] Notation for the transposed feature graph and the coloured noise model should be introduced consistently with standard references on the Bethe Hessian in statistical physics.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity, completeness, and reproducibility.
read point-by-point responses
-
Referee: §3 (Theoretical Analysis): The abstract and introduction state a proof that coloured Gaussian perturbations shift β_N by at most O(σ̄²), but the manuscript provides no derivation, intermediate steps, or explicit assumptions on the perturbation model and the singularity condition. This bound is load-bearing for the noise-robustness guarantee and must be supplied in full.
Authors: We agree that the full derivation of the O(σ̄²) bound was omitted from the main text. In the revised manuscript we will add a complete proof in an appendix, including all intermediate steps of the perturbative expansion of the Bethe Hessian eigenvalue equation, the explicit assumptions on the coloured Gaussian noise (zero-mean, covariance bounded by σ̄²), and the precise singularity condition at β_N. The analysis shows the shift remains O(σ̄²) to second order under these conditions. revision: yes
-
Referee: §2.2 (Method): The claim that the smallest eigenvector of the Bethe Hessian at β_N 'captures the dominant mode of an intrinsically degree-corrected diffusion process' on the similarity graph (and its transpose) is asserted without a derivation linking the eigenvector equation to the diffusion operator or showing why this holds under the chosen sparse graph construction.
Authors: We acknowledge that an explicit derivation of this mapping was not provided. The Bethe Hessian at the Nishimori temperature approximates the non-backtracking operator whose leading eigenvector corresponds to the stationary distribution of a degree-corrected diffusion. In the revision we will insert a short derivation in §2.2 that starts from the eigenvector equation of the Bethe Hessian, relates it to the normalized Laplacian adjusted for node degrees, and shows why the resulting 1D embedding remains valid after transposition to feature space under the sparse similarity graph construction. revision: yes
-
Referee: §4 (Experiments): The reported accuracy figures (e.g., <1% drop retaining 30% features on EfficientNet-B4, 6.8% margin over baselines) are presented without error bars, details on the graph-construction algorithm (sparsity threshold, similarity kernel), binning procedure, or number of random seeds.
Authors: We agree that these implementation and statistical details are necessary. The revised manuscript will report error bars computed over 10 independent random seeds for both graph construction and binning, specify the similarity kernel (cosine similarity) and sparsity threshold (k-NN with k=20), describe the balanced binning procedure (equal-width bins with one representative chosen by highest degree), and include standard deviations for all accuracy numbers. This will allow readers to assess the reliability of the reported margins. revision: yes
Circularity Check
Moderate circularity: embedding extracted directly from Bethe-Hessian singularity at data-dependent β_N on the input graph
specific steps
-
self definitional
[Abstract]
"identifies the Nishimori temperature β_N the critical inverse temperature at which the Bethe Hessian becomes singular. The corresponding smallest eigenvector captures the dominant mode of an intrinsically degree-corrected diffusion process, naturally reweighting nodes to prevent hub dominance. By transposing the data matrix and applying NBSE in feature space, we obtain a one-dimensional spectral embedding"
β_N is defined as the critical point of the Bethe Hessian computed on the sparse similarity graph built from the input data; the eigenvector at that exact point is then declared to be the embedding that captures the diffusion mode. The embedding is therefore obtained by construction from the graph's own critical quantity, with no separate equation or derivation shown that would establish the correspondence independently of this definition.
full rationale
The paper's core construction defines β_N from the singularity of the Bethe Hessian on the constructed similarity graph and immediately uses the associated eigenvector as the embedding that 'captures the dominant mode' of the diffusion process. This step is self-definitional because the claimed property follows from the choice of operating point on the same graph rather than from an independent derivation. The separate O(σ̄²) noise-shift bound is not circular, and experiments provide external validation, so overall circularity remains moderate rather than forcing the entire result by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A sparse similarity graph on samples admits a well-defined Nishimori temperature at which the Bethe Hessian is singular.
Reference graph
Works this paper leans on
-
[1]
I. T. Jolliffe,Principal Component Analysis, 2nd ed. New York, NY , USA: Springer, 2002
2002
-
[2]
Visualizing data using t-SNE,
L. van der Maaten and G. Hinton, “Visualizing data using t-SNE,”J. Mach. Learn. Res., vol. 9, pp. 2579–2605, 2008
2008
-
[3]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes and J. Healy, “UMAP: Uniform manifold approximation and projection for dimension reduction,”arXiv:1802.03426, 2018
work page internal anchor Pith review arXiv 2018
-
[4]
An introduction to variable and feature selection,
I. Guyon and A. Elisseeff, “An introduction to variable and feature selection,”J. Mach. Learn. Res., vol. 3, pp. 1157–1182, 2003
2003
-
[5]
The use of multiple measurements in taxonomic prob- lems,
R. A. Fisher, “The use of multiple measurements in taxonomic prob- lems,”Annals Eugenics, vol. 7, no. 2, pp. 179–188, 1936
1936
-
[6]
Wrappers for feature subset selection,
R. Kohavi and G. John, “Wrappers for feature subset selection,”Artif. Intell., vol. 97, nos. 1–2, pp. 273–324, 1997
1997
-
[7]
Regularization and variable selection via the elastic net,
H. Zou and T. Hastie, “Regularization and variable selection via the elastic net,”J. R. Stat. Soc. B, vol. 67, no. 2, pp. 301–320, 2005
2005
-
[8]
On spectral clustering: Analysis and an algorithm,
A. Y . Ng, M. Jordan, and Y . Weiss, “On spectral clustering: Analysis and an algorithm,” inAdvances in Neural Information Processing Systems, vol. 14, 2002, pp. 849–856
2002
-
[9]
Laplacian eigenmaps for dimensionality reduction and data representation,
M. Belkin and P. Niyogi, “Laplacian eigenmaps for dimensionality reduction and data representation,”Neural Comput., vol. 15, no. 6, pp. 1373–1396, 2003
2003
-
[10]
Semi-supervised learning using Gaussian fields and harmonic functions,
X. Zhu, Z. Ghahramani, and J. Lafferty, “Semi-supervised learning using Gaussian fields and harmonic functions,” inProc. Int. Conf. Machine Learning, 2003, pp. 912–919
2003
-
[11]
A unified framework for spectral clustering in sparse graphs,
L. Dall’Amico, R. Couillet, and N. Tremblay, “A unified framework for spectral clustering in sparse graphs,”J. Mach. Learn. Res., vol. 22, no. 217, pp. 1–56, 2021
2021
-
[12]
Enhanced image clustering with random-bond Ising models using LDPC graph representations and Nishimori temperature,
V . S. Usatyuk, D. A. Sapozhnikov, and S. I. Egorov, “Enhanced image clustering with random-bond Ising models using LDPC graph representations and Nishimori temperature,”Moscow Univ. Phys. Bull., vol. 79, suppl. 2, pp. S647–S665, 2024
2024
-
[13]
Natural image classification via quasi-cyclic graph ensembles and random-bond Ising models at the Nishimori temperature,
V . S. Usatyuk, D. A. Sapozhnikov, and S. I. Egorov, “Natural image classification via quasi-cyclic graph ensembles and random-bond Ising models at the Nishimori temperature,”Moscow Univ. Phys. Bull., vol. 80, suppl. 3, pp. S1039–S1053, 2025
2025
-
[14]
Nishimori,Statistical Physics of Spin Glasses and Information Processing: An Introduction
H. Nishimori,Statistical Physics of Spin Glasses and Information Processing: An Introduction. Oxford, U.K.: Oxford Univ. Press, 2001
2001
-
[15]
Spectral clustering of graphs with the Bethe Hessian,
A. Saade, F. Krzakala, and L. Zdeborov ´a, “Spectral clustering of graphs with the Bethe Hessian,” inAdvances in Neural Information Processing Systems, vol. 27, 2014, pp. 406–414
2014
-
[16]
Multi-edge type LDPC codes,
T. J. Richardson and R. L. Urbanke, “Multi-edge type LDPC codes,” presented at the Workshop honoring Prof. Bob McEliece, Pasadena, CA, USA, 2002
2002
-
[17]
Scikit-learn: Machine learning in Python,
F. Pedregosa et al., “Scikit-learn: Machine learning in Python,”J. Mach. Learn. Res., vol. 12, pp. 2825–2830, 2011
2011
-
[18]
MobileNetV2: Inverted residuals and linear bottlenecks,
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “MobileNetV2: Inverted residuals and linear bottlenecks,” inProc. IEEE Conf. Computer Vision and Pattern Recognition, 2018, pp. 4510–4520
2018
-
[19]
EfficientNet: Rethinking model scaling for convo- lutional neural networks,
M. Tan and Q. Le, “EfficientNet: Rethinking model scaling for convo- lutional neural networks,” inProc. Int. Conf. Machine Learning, 2019, pp. 6105–6114
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.