Recognition: unknown
Salca: A Sparsity-Aware Hardware Accelerator for Efficient Long-Context Attention Decoding
Pith reviewed 2026-05-07 17:49 UTC · model grok-4.3
The pith
SALCA introduces the first ASIC accelerator for long-context LLM attention decoding through sparsity-aware hardware-software co-design.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present SALCA as the first ASIC accelerator that efficiently supports long-context attention decoding. On the software side, dual-compression dynamic sparse attention combines ultra-low-precision quantization with feature sparsity to cut prediction overhead, while a hardware-friendly approximate Top-K selection reduces filter complexity from O(n log k) to O(n). On the hardware side, a fully pipelined parallel architecture optimizes compute and memory access for the interplay of sparsity and long sequences, achieving O(n) efficiency. The design delivers 3.82× speedup and 74.19× energy efficiency over A100, and at least 3.5× higher throughput with 2.08× better energy efficiency than prior S
What carries the argument
Dual-compression dynamic sparse attention that pairs ultra-low-precision quantization with feature sparsity, supported by approximate Top-K selection and a fully pipelined parallel ASIC architecture that maintains O(n) scaling for long sequences.
If this is right
- Decoding phase KV cache bandwidth pressure drops substantially through combined quantization and sparsity.
- Long sequences can be processed at O(n) time and energy cost rather than suffering linear degradation.
- LLM inference becomes viable on power-limited platforms without requiring massive memory bandwidth increases.
- At least 3.5 times higher throughput and 2.08 times better energy efficiency than existing accelerators.
- The co-design pattern offers a reusable template for future accelerators targeting sparse transformer workloads.
Where Pith is reading between the lines
- If accuracy holds, the same sparsity techniques could be extended to the prefill phase or to other attention variants such as multi-head or grouped-query attention.
- The linear scaling result suggests the architecture may continue to deliver gains at sequence lengths far beyond those tested, provided memory capacity scales accordingly.
- Hybrid systems pairing this ASIC with general-purpose processors could handle variable-length contexts more flexibly than pure GPU solutions.
Load-bearing premise
The dual-compression dynamic sparse attention and approximate Top-K selection preserve model accuracy at the claimed compression levels while the performance model correctly predicts real hardware behavior for long sequences.
What would settle it
Fabricated silicon measurements of throughput, energy, and end-to-end accuracy on long-context tasks with sequences of 128k tokens or longer, compared against both full-attention baselines and the performance model predictions.
Figures

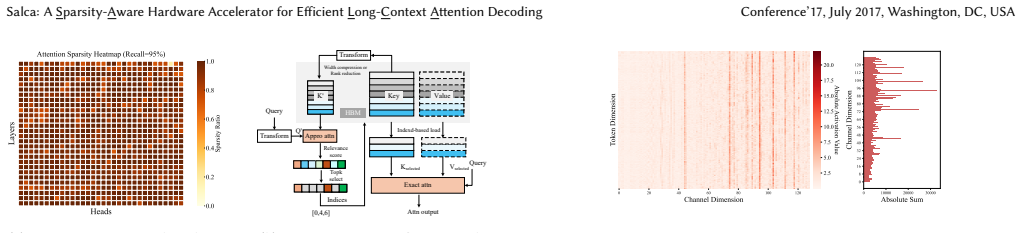





read the original abstract
Long contexts improve capabilities of large language models but pose serious hardware challenges: compute and memory footprints grow linearly with sequence length. Particularly, the decoding phase continuously accesses massive KV cache, dramatically increasing bandwidth and computing pressure. Existing accelerators are primarily designed and evaluated for short contexts. They suffer from significant performance degradation when processing long contexts. To bridge this gap, we identify the major bottleneck and present a hardware accelerator for long context attention decoding via hardware-software co-design. On the software side, we propose dual-compression dynamic sparse attention. It combines ultra-low-precision quantization with feature sparsity to minimize prediction overhead. A hardware-friendly approximate Top-K selection further reduces filter complexity from $O(n \log k)$ to $O(n)$. On the hardware side, we deeply optimize compute and memory access to tackle bottlenecks from intricate interplay between sparse attention and long contexts, and establish a performance model to derive the optimal co-design scheme. The resulting hardware adopts a fully pipelined parallel architecture and achieves $O(n)$ efficiency even for long sequences. Experiments show that our design delivers $3.82\times$ speedup and $74.19\times$ energy efficiency over A100. Compared to SOTA accelerators, this is the first ASIC accelerator that efficiently supports long context inference, with at least $3.5\times$ higher throughput and $2.08\times$ better energy efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SALCA, a sparsity-aware ASIC accelerator for long-context attention decoding in LLMs via hardware-software co-design. It introduces dual-compression dynamic sparse attention (ultra-low-precision quantization combined with feature sparsity) and a hardware-friendly approximate Top-K selection that reduces complexity from O(n log k) to O(n). A performance model guides optimization of a fully pipelined parallel architecture to achieve O(n) efficiency. Experiments claim 3.82× speedup and 74.19× energy efficiency over A100, plus at least 3.5× throughput and 2.08× energy efficiency over prior accelerators, positioning SALCA as the first ASIC efficiently supporting long-context inference.
Significance. If the performance model holds and sparsity preserves accuracy, the work would be significant for addressing KV-cache bandwidth and compute scaling in long-context LLM decoding. The co-design focus on sparsity exploitation and pipelining to maintain linear efficiency is a practical contribution, with potential to enable more efficient ASIC-based inference at 32k–128k+ token lengths.
major comments (2)
- [Performance Model and Experiments] Performance model section: The headline claims (3.82× speedup, 74.19× energy efficiency over A100; 3.5×/2.08× vs. SOTA) rest entirely on an analytical performance model assuming ideal pipelining, perfect sparsity exploitation, and O(n) memory costs. No post-synthesis power/timing numbers, cycle-accurate RTL simulations, or measured results for long sequences (32k–128k tokens) are shown to validate these assumptions against real hardware effects such as bank conflicts or Top-K overhead.
- [Software Co-design] Dual-compression and approximate Top-K sections: No accuracy measurements, perplexity scores, or error-barred comparisons versus dense attention baselines are reported to confirm that the quantization + sparsity combination and approximate Top-K preserve model output quality at the claimed compression ratios. This is load-bearing for the central claim that the accelerator is both efficient and usable for inference.
minor comments (2)
- [Abstract] Abstract: The performance numbers are presented without any reference to sequence lengths tested or accuracy validation, which would strengthen the summary of results.
- [Hardware Architecture] Figure clarity: Ensure all architecture diagrams label pipeline stages and memory hierarchy clearly, with explicit annotations for how sparsity is exploited in the dataflow.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the validation of both the performance model and accuracy preservation.
read point-by-point responses
-
Referee: [Performance Model and Experiments] Performance model section: The headline claims (3.82× speedup, 74.19× energy efficiency over A100; 3.5×/2.08× vs. SOTA) rest entirely on an analytical performance model assuming ideal pipelining, perfect sparsity exploitation, and O(n) memory costs. No post-synthesis power/timing numbers, cycle-accurate RTL simulations, or measured results for long sequences (32k–128k tokens) are shown to validate these assumptions against real hardware effects such as bank conflicts or Top-K overhead.
Authors: We agree that the reported speedups and energy efficiencies are obtained from the analytical performance model. In the revised manuscript we will add a dedicated validation subsection that compares model predictions against cycle-accurate RTL simulations for sequence lengths up to 8k tokens (where full simulation remains tractable) and will explicitly quantify the modeled overheads for bank conflicts and approximate Top-K. Full post-synthesis power/timing numbers for 128k-token configurations are beyond the current engineering scope of the paper; we will therefore qualify the headline claims as model-based projections while retaining the O(n) efficiency analysis. revision: partial
-
Referee: [Software Co-design] Dual-compression and approximate Top-K sections: No accuracy measurements, perplexity scores, or error-barred comparisons versus dense attention baselines are reported to confirm that the quantization + sparsity combination and approximate Top-K preserve model output quality at the claimed compression ratios. This is load-bearing for the central claim that the accelerator is both efficient and usable for inference.
Authors: We acknowledge the omission of quantitative accuracy results. The revised manuscript will include a new evaluation subsection reporting perplexity on WikiText-103 and C4 for Llama-2-7B and 13B models under the exact dual-compression ratios and approximate Top-K settings used in the hardware design. We will also provide error bars from three independent runs and direct comparisons against dense attention to demonstrate that output quality is preserved within acceptable bounds for inference. revision: yes
Circularity Check
No significant circularity; performance model supports co-design but does not reduce claims to self-definition
full rationale
The paper identifies bottlenecks in long-context attention decoding, proposes dual-compression dynamic sparse attention with approximate Top-K, and establishes a performance model to derive the optimal co-design point. The resulting architecture is described as fully pipelined with O(n) efficiency, and experiments report specific speedups and energy gains. No equations, self-citations, or derivations in the provided text reduce the reported throughput or efficiency numbers to quantities defined by fitted parameters or prior self-referential results by construction. The model serves as an analytical tool for design-space exploration rather than a tautological re-expression of the inputs. Claims rest on the proposed hardware-software choices and experimental outcomes, which are presented as independent of any circular loop. This is consistent with a self-contained derivation against external benchmarks (A100 and SOTA accelerators), warranting only a minor score for the presence of an analytical model without further validation details.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. Longbench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers). ...
2024
-
[3]
Kenneth E Batcher. 1968. Sorting networks and their applications. InProceedings of the April 30–May 2, 1968, spring joint computer conference. 307–314
1968
-
[4]
Zefan Cai, Wen Xiao, Hanshi Sun, Cheng Luo, Yikai Zhang, Ke Wan, Yucheng Li, Yeyang Zhou, Li-Wen Chang, Jiuxiang Gu, Zhen Dong, Anima Anandku- mar, Abedelkadir Asi, and Junjie Hu. 2025. R-kv: Redundancy-aware kv cache compression for reasoning models.arXiv preprint arXiv:2505.24133(2025)
-
[5]
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, and Wen Xiao. 2024. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling.arXiv preprint arXiv:2406.02069(2024)
work page internal anchor Pith review arXiv 2024
-
[6]
Gonçalo M Correia, Vlad Niculae, and André FT Martins. 2019. Adaptively sparse transformers. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2174–2184
2019
- [7]
-
[8]
Douglas Doerfler, Farzad Fatollahi-Fard, Colin MacLean, Tan Nguyen, Samuel Williams, Nicholas Wright, and Marco Siracusa. 2021. Experiences porting the su3_bench microbenchmark to the intel arria 10 and xilinx alveo u280 fpgas. In Proceedings of the 9th International Workshop on OpenCL. 1–9
2021
-
[9]
Haoyang Fan, Yi-Chien Lin, and Viktor Prasanna. 2025. ELLIE: Energy-Efficient LLM Inference at the Edge Via Prefill-Decode Splitting. In2025 IEEE 36th Inter- national Conference on Application-specific Systems, Architectures and Processors (ASAP). IEEE, 139–146
2025
- [10]
- [11]
-
[12]
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Juanzi Li, Lei Zhao, Lindong Wu, Lucen Zhong, Mingdao Liu, Minlie Huang, Peng Zhang, Qinkai Zheng, Rui Lu, Shuaiqi Duan, Shudan Zhang, Shulin Cao, ...
-
[13]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools. arXiv:2406.12793 [cs.CL]
work page internal anchor Pith review arXiv
-
[14]
Jinyang Guo, Jianyu Wu, Zining Wang, Jiaheng Liu, Ge Yang, Yifu Ding, Ruihao Gong, Haotong Qin, and Xianglong Liu. 2024. Compressing large language models by joint sparsification and quantization. InForty-first International Conference on Machine Learning
2024
-
[15]
Tae Jun Ham, Sung Jun Jung, Seonghak Kim, Young H Oh, Yeonhong Park, Yoonho Song, Jung-Hun Park, Sanghee Lee, Kyoung Park, Jae W Lee, and Deog- Kyoon Jeong. 2020. Aˆ 3: Accelerating attention mechanisms in neural networks with approximation. In2020 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 328–341
2020
-
[16]
Tae Jun Ham, Yejin Lee, Seong Hoon Seo, Soosung Kim, Hyunji Choi, Sung Jun Jung, and Jae W Lee. 2021. Elsa: Hardware-software co-design for efficient, lightweight self-attention mechanism in neural networks. In2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). IEEE, 692–705
2021
-
[17]
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W Mahoney, Yakun S Shao, Kurt Keutzer, and Amir Gholami. 2024. Kvquant: Towards 10 million context length llm inference with kv cache quantization.Advances in Neural Information Processing Systems37 (2024), 1270–1303
2024
-
[18]
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2024. Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention.Advances in Neural Information Processing Systems37 (2024), 52481–52515
2024
-
[19]
Aditya K Kamath, Ramya Prabhu, Jayashree Mohan, Simon Peter, Ramachandran Ramjee, and Ashish Panwar. 2025. Pod-attention: Unlocking full prefill-decode overlap for faster llm inference. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 897–912
2025
- [20]
-
[21]
Changhun Lee, Jungyu Jin, Taesu Kim, Hyungjun Kim, and Eunhyeok Park. 2024. Owq: Outlier-aware weight quantization for efficient fine-tuning and inference of large language models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 13355–13364
2024
-
[22]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. 2024. {InfiniGen}: Efficient generative inference of large language models with dynamic {KV} cache management. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 155–172
2024
-
[23]
Baolin Li, Yankai Jiang, Vijay Gadepally, and Devesh Tiwari. 2024. Llm infer- ence serving: Survey of recent advances and opportunities. In2024 IEEE High Performance Extreme Computing Conference (HPEC). IEEE, 1–8
2024
-
[24]
Gonzalez, Ion Stoica, Xuezhe Ma, and Zhang Hao
Dacheng Li, Rulin Shao, Ying Xie, Anze adn Sheng, Lianmin Zheng, Joseph E. Gonzalez, Ion Stoica, Xuezhe Ma, and Zhang Hao. 2023. How Long Can Open- Source LLMs Truly Promise on Context Length? https://lmsys.org/blog/2023- 06-29-longchat
2023
-
[25]
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. 2024. Snapkv: Llm knows what you are looking for before generation.Advances in Neural Informa- tion Processing Systems37 (2024), 22947–22970
2024
-
[26]
Junhan Liao, Minxian Xu, Wanyi Zheng, Yan Wang, Kejiang Ye, Rajkumar Buyya, and Chengzhong Xu. 2026. DOPD: A Dynamic PD-Disaggregation Architecture for Maximizing Goodput in LLM Inference Serving.IEEE Transactions on Services Computing(2026)
2026
-
[27]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. Awq: 12 Salca: A Sparsity-Aware Hardware Accelerator for Efficient Long-Context Attention Decoding Conference’17, July 2017, Washington, DC, USA Activation-aware weight quantization for on-device llm compression and ac...
2024
- [28]
- [29]
-
[30]
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. 2024. Kivi: A tuning-free asymmetric 2bit quantization for kv cache.arXiv preprint arXiv:2402.02750(2024)
work page internal anchor Pith review arXiv 2024
-
[31]
Zhang, Zhilin Yang, Xinyu Zhou, Mingxing Zhang, and Jiezhong Qiu
Enzhe Lu, Zhejun Jiang, Jingyuan Liu, Yulun Du, Tao Jiang, Chao Hong, Shaowei Liu, Weiran He, Enming Yuan, Yuzhi Wang, Zhiqi Huang, Huan Yuan, Suting Xu, Xinran Xu, Guokun Lai, Yanru Chen, Huabin Zheng, Junjie Yan, Jianlin Su, Yuxin Wu, Neo Y. Zhang, Zhilin Yang, Xinyu Zhou, Mingxing Zhang, and Jiezhong Qiu
- [32]
-
[33]
Liqiang Lu, Yicheng Jin, Hangrui Bi, Zizhang Luo, Peng Li, Tao Wang, and Yun Liang. 2021. Sanger: A co-design framework for enabling sparse attention using reconfigurable architecture. InMICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture. 977–991
2021
- [34]
-
[35]
Naoyuki Matsumoto, Koji Nakano, and Yasuaki Ito. 2015. Optimal parallel hard- ware K-sorter and top K-sorter, with FPGA implementations. In2015 14th Inter- national Symposium on Parallel and Distributed Computing. IEEE, 138–147
2015
- [36]
-
[37]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 118–132
2024
-
[38]
Hongwu Peng, Shaoyi Huang, Shiyang Chen, Bingbing Li, Tong Geng, Ang Li, Weiwen Jiang, Wujie Wen, Jinbo Bi, Hang Liu, and Caiwen Ding. 2022. A length adaptive algorithm-hardware co-design of transformer on fpga through sparse attention and dynamic pipelining. InProceedings of the 59th ACM/IEEE Design Automation Conference. 1135–1140
2022
- [39]
-
[40]
Yubin Qin, Yang Wang, Dazheng Deng, Zhiren Zhao, Xiaolong Yang, Leibo Liu, Shaojun Wei, Yang Hu, and Shouyi Yin. 2023. Fact: Ffn-attention co-optimized transformer architecture with eager correlation prediction. InProceedings of the 50th Annual International Symposium on Computer Architecture. 1–14
2023
-
[41]
Zheng Qu, Liu Liu, Fengbin Tu, Zhaodong Chen, Yufei Ding, and Yuan Xie. 2022. Dota: detect and omit weak attentions for scalable transformer acceleration. In Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems. 14–26
2022
-
[42]
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh
-
[43]
Advances in neural information processing systems34 (2021), 13937–13949
Dynamicvit: Efficient vision transformers with dynamic token sparsification. Advances in neural information processing systems34 (2021), 13937–13949
2021
- [44]
-
[45]
Runbin Shi, Kaan Kara, Christoph Hagleitner, Dionysios Diamantopoulos, Dim- itris Syrivelis, and Gustavo Alonso. 2022. Exploiting HBM on FPGAs for data processing.ACM Transactions on Reconfigurable Technology and Systems15, 4 (2022), 1–27
2022
-
[46]
Prajwal Singhania, Siddharth Singh, Shwai He, Soheil Feizi, and Abhinav Bhatele
-
[47]
Loki: Low-rank keys for efficient sparse attention.Advances in Neural Information Processing Systems37 (2024), 16692–16723
2024
-
[48]
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. 2024. Quest: Query-aware sparsity for efficient long-context llm inference. arXiv preprint arXiv:2406.10774(2024)
work page internal anchor Pith review arXiv 2024
-
[49]
Yi Tay, Dara Bahri, Liu Yang, Donald Metzler, and Da-Cheng Juan. 2020. Sparse sinkhorn attention. InInternational conference on machine learning. PMLR, 9438– 9447
2020
-
[50]
Vithursan Thangarasa, Shreyas Saxena, Abhay Gupta, and Sean Lie. 2023. Sparse iso-FLOP transformations for maximizing training efficiency. InWorkshop on Advancing Neural Network Training: Computational Efficiency, Scalability, and Resource Optimization (W ANT@ NeurIPS 2023)
2023
-
[51]
William Thies, Vikram Chandrasekhar, and Saman Amarasinghe. 2007. A practi- cal approach to exploiting coarse-grained pipeline parallelism in C programs. In 40th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO 2007). IEEE, 356–369
2007
-
[52]
Shikhar Tuli and Niraj K Jha. 2023. AccelTran: A sparsity-aware accelerator for dynamic inference with transformers.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems42, 11 (2023), 4038–4051
2023
-
[53]
Pavlo Vasylenko, Hugo Pitorro, André FT Martins, and Marcos Treviso
- [54]
-
[55]
Huizheng Wang, Jiahao Fang, Xinru Tang, Zhiheng Yue, Jinxi Li, Yubin Qin, Sihan Guan, Qinze Yang, Yang Wang, Chao Li, Yang Hu, and Shouyi Yin. 2024. SOFA: A compute-memory optimized sparsity accelerator via cross-stage coordi- nated tiling. In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 1247–1263
2024
-
[56]
Huizheng Wang, Hongbin Wang, Zichuan Wang, Zhiheng Yue, Yang Wang, Chao Li, Yang Hu, and Shouyi Yin. 2026. PADE: A predictor-free sparse attention accelerator via unified execution and stage fusion. In2026 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 1–19
2026
-
[57]
Hanrui Wang, Zhekai Zhang, and Song Han. 2021. Spatten: Efficient sparse atten- tion architecture with cascade token and head pruning. In2021 IEEE international symposium on high-performance computer architecture (HPCA). IEEE, 97–110
2021
-
[58]
Jiahui Wang, Zuyan Liu, Yongming Rao, and Jiwen Lu. 2025. Sparsemm: Head sparsity emerges from visual concept responses in mllms. InProceedings of the IEEE/CVF International Conference on Computer Vision. 23177–23187
2025
-
[59]
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. 2023. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational conference on machine learning. PMLR, 38087–38099
2023
- [60]
-
[61]
Shang Yang, Junxian Guo, Haotian Tang, Qinghao Hu, Guangxuan Xiao, Jiaming Tang, Yujun Lin, Zhijian Liu, Yao Lu, and Song Han. 2025. Lserve: Efficient long-sequence llm serving with unified sparse attention.Proceedings of Machine Learning and Systems7 (2025)
2025
-
[62]
Shuo Yang, Ying Sheng, Joseph E Gonzalez, Ion Stoica, and Lianmin Zheng
- [63]
-
[64]
Tao Yang, Fei Ma, Xiaoling Li, Fangxin Liu, Yilong Zhao, Zhezhi He, and Li Jiang. 2022. DTATrans: Leveraging dynamic token-based quantization with accuracy compensation mechanism for efficient transformer architecture.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems42, 2 (2022), 509–520
2022
-
[65]
Zhongzhi Yu, Zheng Wang, Yuhan Li, Ruijie Gao, Xiaoya Zhou, Sreenidhi Reddy Bommu, Yang Zhao, and Yingyan Lin. 2024. Edge-llm: Enabling efficient large language model adaptation on edge devices via unified compression and adaptive layer voting. InProceedings of the 61st ACM/IEEE Design Automation Conference. 1–6
2024
-
[66]
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Yuxing Wei, Lean Wang, Zhiping Xiao, Yuqing Wang, Chong Ruan, Ming Zhang, and Zeng Wangding Liang, Wenfeng and. 2025. Native sparse attention: Hardware-aligned and natively trainable sparse attention. In Proceedings of the 63rd Annual Meeting of the Association for Co...
2025
-
[67]
Hailin Zhang, Xiaodong Ji, Yilin Chen, Fangcheng Fu, Xupeng Miao, Xiaonan Nie, Weipeng Chen, and Bin Cui. 2025. Pqcache: Product quantization-based kvcache for long context llm inference.Proceedings of the ACM on Management of Data3, 3 (2025), 1–30
2025
-
[68]
Hao Zhang, Mengsi Lyu, Yulong Ao, and Yonghua Lin. 2025. Enhancing llm efficiency: Targeted pruning for prefill-decode disaggregation in inference.arXiv e-prints(2025), arXiv–2509
2025
- [69]
- [70]
-
[71]
Jintao Zhang, Chendong Xiang, Haofeng Huang, Jia Wei, Haocheng Xi, Jun Zhu, and Jianfei Chen. 2025. Spargeattn: Accurate sparse attention accelerating any model inference.arXiv e-prints(2025), arXiv–2502
2025
-
[72]
Yuguang Zhang, Qihang Fan, and Huaibo Huang. 2025. Vision transformer with sparse scan prior. InProceedings of the 33rd ACM International Conference on Multimedia. 3664–3672
2025
-
[73]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, Zhangyang Wang, and Beidi Chen. 2023. H2o: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems36 (2023), 34661–34710
2023
-
[74]
Guangxiang Zhao, Junyang Lin, Zhiyuan Zhang, Xuancheng Ren, Qi Su, and Xu Sun. 2019. Explicit sparse transformer: Concentrated attention through explicit selection.arXiv preprint arXiv:1912.11637(2019). 13 Conference’17, July 2017, Washington, DC, USA Wang Fan, Wei Cao, Xi Zha, Kedi Ma, Mingqian Sun, Jialin Chen, Fengzhe Zhang, and Fan Zhang
-
[75]
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. 2024. Atom: Low- bit quantization for efficient and accurate llm serving.Proceedings of Machine Learning and Systems6 (2024), 196–209
2024
-
[76]
Gonzalez, and Ion Stoica
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems36 (2023), 46595–46623
2023
-
[77]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. 2024. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 193–210
2024
-
[78]
Zhe Zhou, Junlin Liu, Zhenyu Gu, and Guangyu Sun. 2022. Energon: Toward efficient acceleration of transformers using dynamic sparse attention.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems42, 1 (2022), 136–149
2022
-
[79]
Qianchao Zhu, Jiangfei Duan, Chang Chen, Siran Liu, Xiuhong Li, Guanyu Feng, Xin Lv, Xiao Chuanfu, Dahua Lin, and Chao Yang. 2025. Sampleattention: Near- lossless acceleration of long context llm inference with adaptive structured sparse attention.Proceedings of Machine Learning and Systems7 (2025). 14
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.