Recognition: unknown
Offline Evaluation Measures of Fairness in Recommender Systems
Pith reviewed 2026-05-08 01:31 UTC · model grok-4.3
The pith
Existing offline fairness measures for recommender systems have interpretability and applicability limits that new methods and guidelines can fix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a wide range of existing offline fairness measures, when examined by evaluation subject and granularity, exhibit theoretical, empirical, and conceptual limitations that reduce their robustness, and that targeted analysis combined with new measures and usage guidelines can overcome these limitations to support more precise fairness assessment in recommender systems.
What carries the argument
Categorization of fairness measures by subject (users or items) and granularity (group or individual), serving as the structure for theoretical proofs of flaws, empirical distribution studies, and the derivation of replacement measures plus selection rules.
If this is right
- Model outputs that produce the highest or lowest fairness scores under each measure can be identified through the empirical analysis.
- Distributions of scores for each measure can be characterized to show typical ranges and outliers.
- Cases where measures cannot be computed are documented, allowing avoidance of invalid applications.
- New measures provide alternatives that maintain computability and improve expressiveness for both group and individual fairness.
- Guidelines enable selection of measures matched to the specific fairness notion and evaluation subject at hand.
Where Pith is reading between the lines
- Adoption of the guidelines could lead to more uniform reporting of fairness results in published recommender system studies.
- The same combination of theoretical checks and empirical testing could be applied to fairness metrics used in other machine learning tasks beyond recommendation.
- Integration of the new measures into evaluation toolkits would allow practitioners to run side-by-side comparisons of fairness across algorithms without manual adjustments for edge cases.
Load-bearing premise
That the limitations found for the examined measures cover the main barriers to reliable use and that the new approaches will improve interpretability without introducing their own unexamined drawbacks in practice.
What would settle it
A test that applies one of the proposed new measures to recommender outputs where an original measure returns an undefined result due to division by zero and shows that the new scores remain consistent and match expected fairness orderings across multiple independent datasets.
Figures






















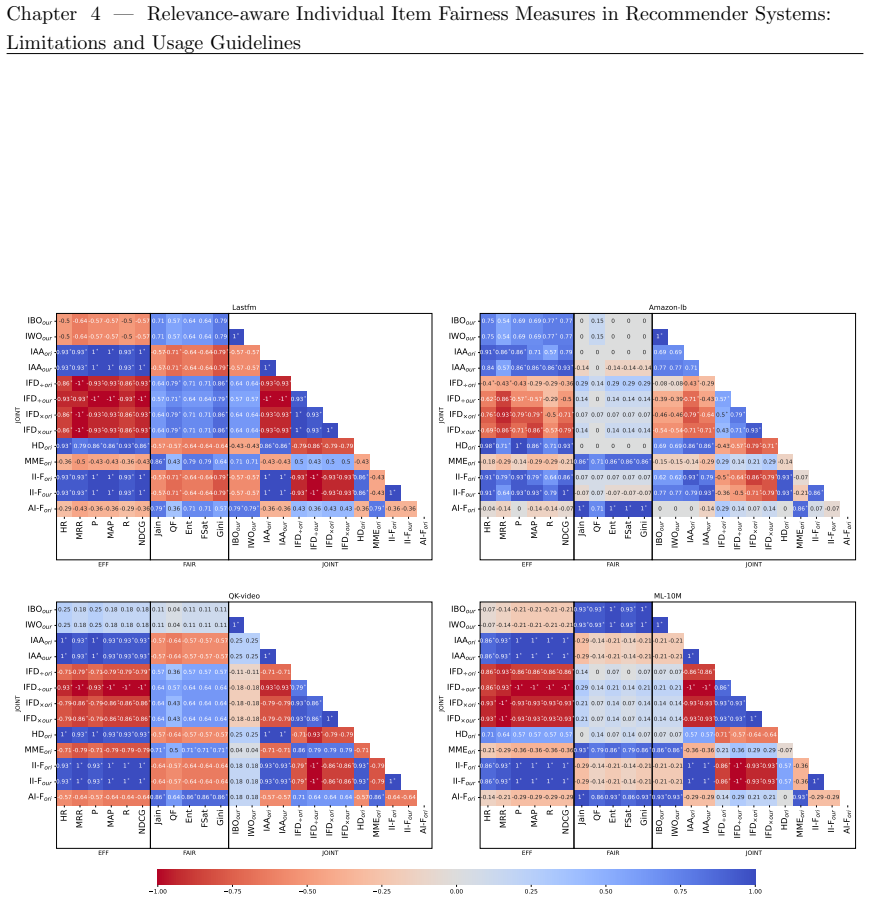













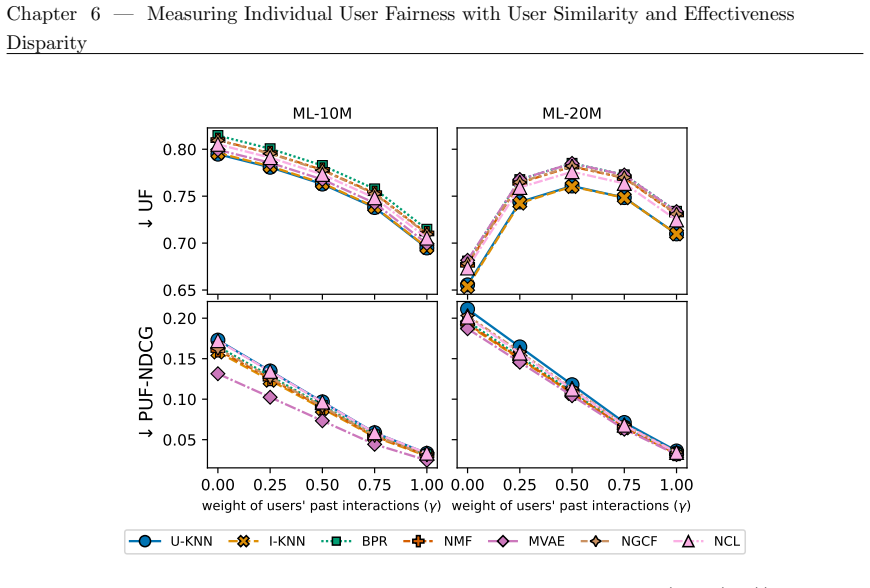







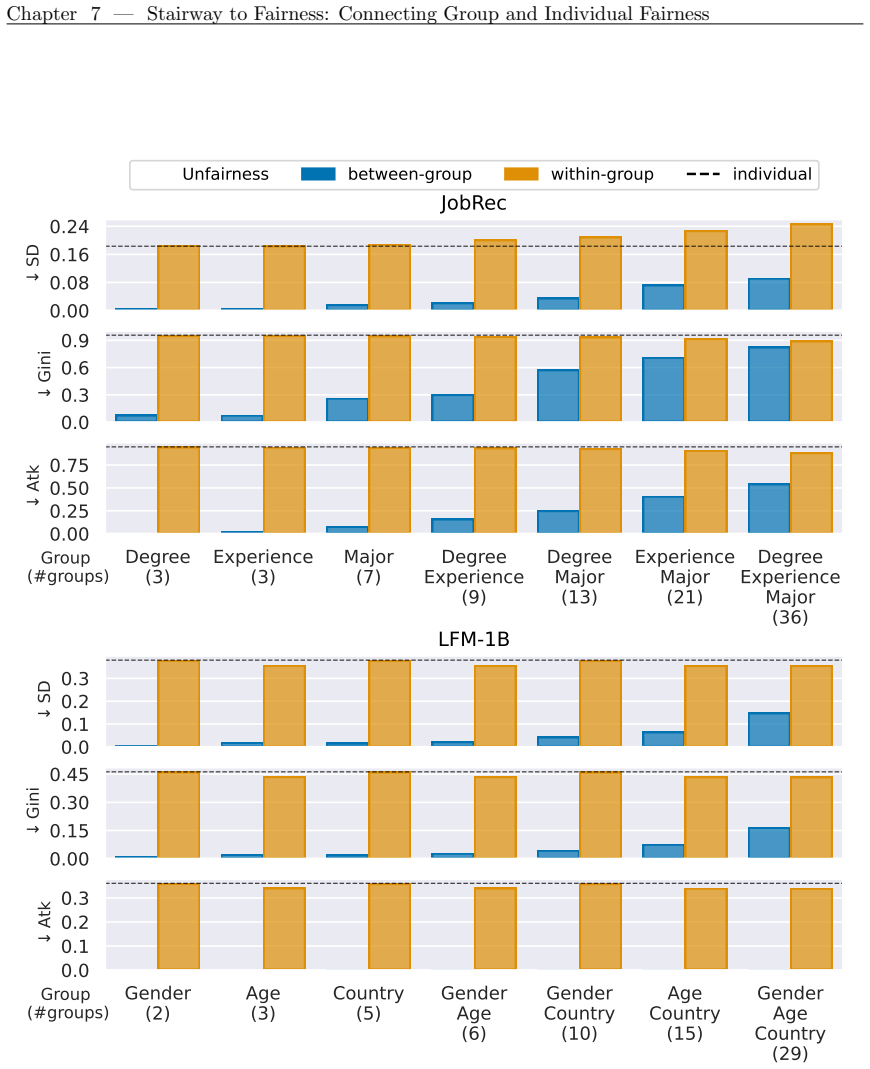


read the original abstract
The evaluation of recommender system fairness has become increasingly important, especially with recent legislation that emphasises the development of fair and responsible artificial intelligence. This has led to the emergence of various fairness evaluation measures, which quantify fairness based on different definitions. However, many of such measures are simply proposed and used without further analysis on their robustness. As a result, there is insufficient understanding and awareness of the measures' limitations. Among other issues, it is not known what kind of model outputs produce the (un)fairest score, how the measure scores are empirically distributed, and whether there are cases where the measures cannot be computed (e.g., due to division by zero). These issues cause difficulty in interpreting the measure scores and confusion on which measure(s) should be used for a specific case. This thesis presents a series of papers that assess and overcome various theoretical, empirical, and conceptual limitations of existing recommender system fairness evaluation measures. We investigate a wide range of offline evaluation measures for different fairness notions, divided based on the evaluation subjects (users and items) and for different evaluation granularities (groups of subjects and individual subjects). Firstly, we perform theoretical and empirical analysis on the measures, exposing flaws that limit their interpretability, expressiveness, or applicability. Secondly, we contribute novel evaluation approaches and measures that overcome these limitations. Finally, considering the measures' limitations, we recommend guidelines for the appropriate measure usage, thereby allowing for more precise selection of fairness evaluation measures in practical scenarios. Overall, this thesis contributes to advancing the state-of-the-art offline evaluation of fairness in recommender systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This thesis analyzes theoretical, empirical, and conceptual limitations of offline fairness evaluation measures in recommender systems. It covers measures for user and item fairness at both group and individual levels, identifies issues such as limited interpretability, unclear score distributions, and cases where measures cannot be computed (e.g., division by zero), proposes new evaluation approaches and measures to address these flaws, and provides guidelines for selecting appropriate measures in practice.
Significance. If the analyses and new approaches hold, the work advances fairness evaluation in recommender systems by improving the robustness and interpretability of measures, which is timely given legislative emphasis on responsible AI. The empirical distributions and theoretical breakdowns of existing measures, along with the proposed alternatives, could help practitioners avoid misinterpretation and select measures more precisely.
minor comments (2)
- The abstract mentions specific limitations (e.g., division by zero cases and empirical score distributions) but does not indicate whether the full thesis includes concrete examples or proofs for each; a dedicated section summarizing these across all papers would strengthen the synthesis.
- As a collection of papers, the thesis would benefit from an explicit cross-paper comparison table showing which limitations each paper addresses and how the new measures compare to baselines in terms of applicability.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our thesis, which correctly identifies its focus on theoretical, empirical, and conceptual limitations of offline fairness measures in recommender systems, along with the proposed alternatives and guidelines. We appreciate the recommendation for minor revision and the recognition of the work's timeliness given legislative emphasis on responsible AI. No specific major comments were provided in the report.
Circularity Check
No significant circularity identified
full rationale
The thesis abstract and description outline a series of papers performing theoretical/empirical analysis on existing fairness measures in recommender systems, identifying limitations in interpretability and applicability, proposing novel approaches/measures, and issuing usage guidelines. No equations, derivation steps, fitted parameters presented as predictions, or load-bearing self-citations are visible in the provided text. The work is self-contained with independent analytical and prescriptive content that does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Evaluation of Fairness in Recommender Systems: A Review
Syed Wajid Aalam, Abdul Basit Ahanger, Muzafar Rasool Bhat, and Assif Assad. Evaluation of Fairness in Recommender Systems: A Review. In Balas Valentina E., G R. Sinha, Agarwal Basant, Sharma Tarun Kumar, Dadheech Pankaj, and Mahrishi Mehul, editors,Emerging Technologies in Computer En- gineering: Cognitive Computing and Intelligent IoT, pages 456–465, Cham,
-
[2]
ISBN 978-3-031-07012-9
Springer International Publishing. ISBN 978-3-031-07012-9. Cited on pages 2, 8, 12, 180, and 226
-
[3]
On over-specialization and concentration bias of recommendations: probabilistic neighborhood selection in collaborative filtering systems
Panagiotis Adamopoulos and Alexander Tuzhilin. On over-specialization and concentration bias of recommendations: probabilistic neighborhood selection in collaborative filtering systems. InProceedings of the 8th ACM Conference on Recommender Systems, RecSys ’14, pages 153–160, New York, NY, USA,
-
[4]
Association for Computing Machinery. ISBN 9781450326681. doi: 10. 1145/2645710.2645752. URLhttps://doi.org/10.1145/2645710.2645752. Cited on page 237
-
[5]
Context-aware recommender systems.AI Magazine, 32(3):67–80, Oct
Gediminas Adomavicius, Bamshad Mobasher, Francesco Ricci, and Alexander Tuzhilin. Context-aware recommender systems.AI Magazine, 32(3):67–80, Oct. 2011. doi: 10.1609/aimag.v32i3.2364. URLhttps://ojs.aaai.org/ aimagazine/index.php/aimagazine/article/view/2364. Cited on page 6
-
[6]
Aggarwal.Recommender Systems: The Textbook
Charu C. Aggarwal.Recommender Systems: The Textbook. Springer Publishing Company, Incorporated, 1st edition, 2016. ISBN 3319296574. Cited on pages 1 and 6
2016
-
[7]
Desirable properties for diversity and truncated effectiveness met- rics
Ameer Albahem, Damiano Spina, Falk Scholer, Alistair Moffat, and Lawrence Cavedon. Desirable properties for diversity and truncated effectiveness met- rics. InProceedings of the 23rd Australasian Document Computing Sym- posium, ADCS ’18, New York, NY, USA, 2018. Association for Comput- ing Machinery. ISBN 9781450365499. doi: 10.1145/3291992.3291996. URL h...
-
[8]
Bushra Alhijawi, Arafat Awajan, and Salam Fraihat. Survey on the objec- tives of recommender systems: Measures, solutions, evaluation methodology, and new perspectives.ACM Comput. Surv., 55(5), December 2022. ISSN 0360-0300. doi: 10.1145/3527449. URLhttps://doi.org/10.1145/3527449. Cited on page 8
-
[9]
Measures of Inequality.American Sociological Review, 43(6): 865–880, 12 1978
Paul D Allison. Measures of Inequality.American Sociological Review, 43(6): 865–880, 12 1978. Cited on pages 15 and 45
1978
-
[10]
An axiomatic analysis of diversity evaluation metrics: Introducing the rank-biased utility metric
Enrique Amig´ o, Damiano Spina, and Jorge Carrillo-de Albornoz. An axiomatic analysis of diversity evaluation metrics: Introducing the rank-biased utility metric. InThe 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR ’18, page 625–634, New York, NY, USA, 2018. Association for Computing Machinery. ISBN 9781...
-
[11]
A unifying and general account of fairness measurement in recommender systems
Enrique Amig´ o, Yashar Deldjoo, Stefano Mizzaro, and Alejandro Bellog´ ın. A unifying and general account of fairness measurement in recommender systems. Information Processing & Management, 60(1):103115, 1 2023. ISSN 0306-4573. doi: 10.1016/J.IPM.2022.103115. Cited on pages 2, 8, 12, 13, 15, 71, 72, 76, 102, 103, 119, 180, 188, 226, 253, and 264
-
[12]
On the measurement of inequality.Journal of Eco- nomic Theory, 2(3):244–263, 1970
Anthony B Atkinson. On the measurement of inequality.Journal of Eco- nomic Theory, 2(3):244–263, 1970. ISSN 0022-0531. doi: https://doi. org/10.1016/0022-0531(70)90039-6. URLhttps://www.sciencedirect.com/ science/article/pii/0022053170900396. Cited on pages 254 and 264
-
[13]
Charles Audet, Jean Bigeon, Dominique Cartier, S´ ebastien Le Digabel, and Ludovic Salomon. Performance indicators in multiobjective optimization.Eu- ropean Journal of Operational Research, 292(2):397–422, 2020. doi: 10.1016/j. ejor.2020.11.016. URLhttps://hal.science/hal-03048871. Cited on page 190
work page doi:10.1016/j 2020
-
[14]
rapidfuzz/RapidFuzz: Release 3.8.1
Max Bachmann. rapidfuzz/rapidfuzz: Release 3.8.1, April 2024. URLhttps: //doi.org/10.5281/zenodo.10938887. Cited on page 261
-
[15]
Krisztian Balog, Donald Metzler, and Zhen Qin. Rankers, judges, and assis- tants: Towards understanding the interplay of llms in information retrieval evaluation, 2025. URLhttps://arxiv.org/abs/2503.19092. Cited on page 31. 277
-
[16]
MIT Press, 2023
Solon Barocas, Moritz Hardt, and Arvind Narayanan.Fairness and Machine Learning: Limitations and Opportunities. MIT Press, 2023. Cited on page 10
2023
-
[17]
Christine Bauer, Alan Said, and Eva Zangerle. Evaluation Perspectives of Recommender Systems: Driving Research and Education (Dagstuhl Seminar 24211).Dagstuhl Reports, 14(5):58–172, 2024. ISSN 2192-5283. doi: 10.4230/ DagRep.14.5.58. URLhttps://drops.dagstuhl.de/entities/document/ 10.4230/DagRep.14.5.58. Cited on page 3
-
[18]
Joeran Beel and Stefan Langer. A comparison of offline evaluations, online evaluations, and user studies in the context of research-paper recommender systems. In Sarantos Kapidakis, Cezary Mazurek, and Marcin Werla, editors, Proceedings of the 19th International Conference on Theory and Practice of Digital Libraries (TPDL), volume 9316 ofLecture Notes in ...
-
[19]
Yoav Benjamini and Yosef Hochberg. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing.Journal of the Royal Statistical Society: Series B (Methodological), 57(1):289–300, 1 1995. ISSN 2517-6161. doi: 10.1111/J.2517-6161.1995.TB02031.X. Cited on page 59
-
[20]
Alex Beutel, Jilin Chen, Tulsee Doshi, Hai Qian, Li Wei, Yi Wu, Lukasz Heldt, Zhe Zhao, Lichan Hong, Ed H. Chi, and Cristos Goodrow. Fairness in rec- ommendation ranking through pairwise comparisons. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’19, page 2212–2220, New York, NY, USA, 2019. Associa...
-
[21]
Asia J. Biega, Krishna P. Gummadi, and Gerhard Weikum. Equity of attention: Amortizing individual fairness in rankings. In41st International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2018, volume 18, pages 405–414. Association for Computing Machinery, Inc, 6 2018. ISBN 9781450356572. doi: 10.1145/3209978.3210063. URL...
-
[22]
Toward Fair Recommendation in Two-sided Platforms
Arpita Biswas, Gourab K Patro, Niloy Ganguly, Krishna P Gummadi, and Abhijnan Chakraborty. Toward Fair Recommendation in Two-sided Platforms. ACM Trans. Web, 16(2), 12 2021. ISSN 1559-1131. doi: 10.1145/3503624. URL https://doi.org/10.1145/3503624. Cited on pages 25, 225, 226, and 227. 278
-
[23]
Springer Netherlands, Dordrecht, 1999
Charles Blackorby, Walter Bossert, and David Donaldson.Income Inequality Measurement: The Normative Approach, pages 133–161. Springer Netherlands, Dordrecht, 1999. ISBN 978-94-011-4413-1. doi: 10.1007/978-94-011-4413-1 4. URLhttps://doi.org/10.1007/978-94-011-4413-1_4. Cited on pages 254 and 265
-
[24]
Learning Recom- mendations from User Actions in the Item-poor Insurance Domain
Simone Borg Bruun, Maria Maistro, and Christina Lioma. Learning Recom- mendations from User Actions in the Item-poor Insurance Domain. InRec- Sys 2022 - Proceedings of the 16th ACM Conference on Recommender Sys- tems, pages 113–123. Association for Computing Machinery, Inc, 9 2022. ISBN 9781450392785. doi: 10.1145/3523227.3546775. URLhttps://dl.acm.org/ d...
-
[25]
Enhancing Long Term Fairness in Recommendations with Variational Autoencoders
Rodrigo Borges and Kostas Stefanidis. Enhancing Long Term Fairness in Recommendations with Variational Autoencoders. InProceedings of the 11th International Conference on Management of Digital EcoSystems, New York, NY, USA, 2019. ACM. ISBN 9781450362382. doi: 10.1145/3297662. URL https://doi.org/10.1145/3297662.3365798. Cited on pages 30, 71, 103, 104, 10...
-
[26]
Decomposable Income Inequality Measures.Economet- rica, 47(4):901–920, 1979
Francois Bourguignon. Decomposable Income Inequality Measures.Economet- rica, 47(4):901–920, 1979. Cited on pages 15, 254, and 265
1979
-
[27]
Indi- vidually Fair Ranking
Amanda Bower, Hamid Eftekhari, Mikhail Yurochkin, and Yuekai Sun. Indi- vidually Fair Ranking. InICLR 2021 - 9th International Conference on Learn- ing Representations. OpenReview.net, 2021. URLhttps://openreview.net/ forum?id=71zCSP_HuBN. Cited on page 102
2021
-
[28]
Chris Buckley and Ellen M. Voorhees. Evaluating evaluation measure sta- bility. InProceedings of the 23rd Annual International ACM SIGIR Confer- ence on Research and Development in Information Retrieval, SIGIR ’00, page 33–40, New York, NY, USA, 2000. Association for Computing Machinery. ISBN 1581132263. doi: 10.1145/345508.345543. URLhttps://doi.org/10.1...
-
[29]
Multisided Fairness for Recommendation
Robin Burke. Multisided fairness for recommendation, 2017. URLhttps: //arxiv.org/abs/1707.00093. Cited on page 9
work page Pith review arXiv 2017
-
[30]
Balanced Neigh- borhoods for Multi-sided Fairness in Recommendation, 1 2018
Robin Burke, Nasim Sonboli, and Aldo Ordonez-Gauger. Balanced Neigh- borhoods for Multi-sided Fairness in Recommendation, 1 2018. ISSN 2640- 279
2018
-
[31]
Cited on pages 1 and 12
URLhttps://proceedings.mlr.press/v81/burke18a.html. Cited on pages 1 and 12
-
[32]
De-centering the (Traditional) User: Multistake- holder Evaluation of Recommender Systems, 2025
Robin Burke, Gediminas Adomavicius, Toine Bogers, Tommaso Di Noia, Do- minik Kowald, Julia Neidhardt, ¨Ozlem ¨Ozg¨ obek, Maria Soledad Pera, Nava Tintarev, and J¨ urgen Ziegler. De-centering the (Traditional) User: Multistake- holder Evaluation of Recommender Systems, 2025. URLhttps://arxiv.org/ abs/2501.05170. Cited on page 182
-
[33]
Inherent Limitations of AI Fairness.Commun
Maarten Buyl and Tijl De Bie. Inherent Limitations of AI Fairness.Commun. ACM, 67(2):48–55, 1 2024. ISSN 0001-0782. doi: 10.1145/3624700. URL https://doi.org/10.1145/3624700. Cited on pages 229 and 242
-
[34]
Offline evaluation options for recommender systems
Roc´ ıo Ca˜ namares, Pablo Castells, and Alistair Moffat. Offline evaluation options for recommender systems.Information Retrieval Journal, 23(4): 387–410, 2020. ISSN 15737659. doi: 10.1007/s10791-020-09371-3. URL https://doi.org/10.1007/s10791-020-09371-3. Cited on pages 6, 7, 8, and 142
-
[35]
2nd Workshop on Infor- mation Heterogeneity and Fusion in Recommender Systems (HetRec 2011)
Iv´ an Cantador, Peter Brusilovsky, and Tsvi Kuflik. 2nd Workshop on Infor- mation Heterogeneity and Fusion in Recommender Systems (HetRec 2011). InProceedings of the 5th ACM conference on Recommender systems, RecSys 2011, New York, NY, USA, 2011. ACM. Cited on pages 110, 150, 194, 195, and 230
2011
-
[36]
Pablo Castells and Alistair Moffat. Offline recommender system evaluation: Challenges and new directions.AI Magazine, 43(2):225–238, 2022. doi: https://doi.org/10.1002/aaai.12051. URLhttps://onlinelibrary.wiley. com/doi/abs/10.1002/aaai.12051. Cited on pages 7, 8, and 29
-
[37]
Hurley, and Saul Vargas.Novelty and Diversity in Recommender Systems, pages 881–918
Pablo Castells, Neil J. Hurley, and Saul Vargas.Novelty and Diversity in Recommender Systems, pages 881–918. Springer US, Boston, MA, 2015. ISBN 978-1-4899-7637-6. doi: 10.1007/978-1-4899-7637-6 26. URLhttps://doi. org/10.1007/978-1-4899-7637-6_26. Cited on page 7
-
[38]
Springer,
O Celma.Music Recommendation and Discovery in the Long Tail. Springer,
-
[39]
Pareto optimality in multiobjective problems.Applied Mathe- matics & Optimization, 4(1):41–59, 3 1977
Yair Censor. Pareto optimality in multiobjective problems.Applied Mathe- matics & Optimization, 4(1):41–59, 3 1977. ISSN 14320606. doi: 10.1007/ 280 BF01442131/METRICS. URLhttps://link.springer.com/article/10. 1007/BF01442131. Cited on page 189
1977
-
[40]
The origins of the Gini index: extracts from Variabilit` a e Mutabilit` a (1912) by Corrado Gini.J Econ Inequal, 10:421–443,
Lidia Ceriani and Paolo Verme. The origins of the Gini index: extracts from Variabilit` a e Mutabilit` a (1912) by Corrado Gini.J Econ Inequal, 10:421–443,
1912
-
[41]
URLhttp://www.umass.edu/wsp/ statistics/tales/gini.html
doi: 10.1007/s10888-011-9188-x. URLhttp://www.umass.edu/wsp/ statistics/tales/gini.html. Cited on page 38
-
[42]
FairGap: Fairness-Aware Recommendation via Generating Counterfactual Graph.ACM Trans
Wei Chen, Yiqing Wu, Zhao Zhang, Fuzhen Zhuang, Zhongshi He, Ruobing Xie, and Feng Xia. FairGap: Fairness-Aware Recommendation via Generating Counterfactual Graph.ACM Trans. Inf. Syst., 42(4), 2 2024. ISSN 1046-8188. doi: 10.1145/3638352. URLhttps://doi.org/10.1145/3638352. Cited on page 242
-
[43]
Weixin Chen, Li Chen, and Yuhan Zhao. Investigating user-side fairness in outcome and process for multi-type sensitive attributes in recommendations. ACM Trans. Recomm. Syst., April 2025. doi: 10.1145/3731568. URLhttps: //doi.org/10.1145/3731568. Just Accepted. Cited on page 10
-
[44]
Sachin Pathiyan Cherumanal, Damiano Spina, Falk Scholer, and W. Bruce Croft. Evaluating Fairness in Argument Retrieval. InIn- ternational Conference on Information and Knowledge Management, Proceedings, pages 3363–3367. Association for Computing Machinery, 10 2021. ISBN 9781450384469. doi: 10.1145/3459637.3482099. URL https://dl.acm.org/doi/10.1145/345963...
-
[45]
Q&R: A Two-Stage Approach toward Interactive Recommendation
Konstantina Christakopoulou, Alex Beutel, Rui Li, Sagar Jain, and Ed H Chi. Q&R: A Two-Stage Approach toward Interactive Recommendation. InPro- ceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’18, pages 139–148, New York, NY, USA,
-
[46]
Association for Computing Machinery. ISBN 9781450355520. doi: 10. 1145/3219819.3219894. URLhttps://doi.org/10.1145/3219819.3219894. Cited on page 140
-
[47]
Team Cohere, :, Aakanksha, Arash Ahmadian, Marwan Ahmed, Jay Alam- mar, Milad Alizadeh, Yazeed Alnumay, Sophia Althammer, Arkady Arkhang- orodsky, Viraat Aryabumi, Dennis Aumiller, Rapha¨ el Avalos, Zahara Aviv, Sammie Bae, Saurabh Baji, Alexandre Barbet, Max Bartolo, Bj¨ orn Bebensee, 281 Neeral Beladia, Walter Beller-Morales, Alexandre B´ erard, Andrew ...
-
[48]
Performance of rec- ommender algorithms on top-n recommendation tasks
Paolo Cremonesi, Yehuda Koren, and Roberto Turrin. Performance of rec- ommender algorithms on top-n recommendation tasks. InProceedings of the Fourth ACM Conference on Recommender Systems, RecSys ’10, page 39–46, New York, NY, USA, 2010. Association for Computing Machinery. ISBN 9781605589060. doi: 10.1145/1864708.1864721. URLhttps://doi.org/10. 1145/1864...
-
[49]
Mapping the Margins: Intersectionality, Identity Politics, and Violence against Women of Color.Stanford Law Review, 43(6):1241–1299,
Kimberle Crenshaw. Mapping the Margins: Intersectionality, Identity Politics, and Violence against Women of Color.Stanford Law Review, 43(6):1241–1299,
-
[50]
URLhttp://www.jstor.org/stable/1229039
ISSN 00389765. URLhttp://www.jstor.org/stable/1229039. Cited on pages 11 and 102
-
[51]
Offline eval- uation of recommender systems in a user interface with multiple carousels
Maurizio Ferrari Dacrema, Nicol` o Felicioni, and Paolo Cremonesi. Offline eval- uation of recommender systems in a user interface with multiple carousels. Frontiers in Big Data, 5:910030, 6 2022. ISSN 2624909X. doi: 10.3389/FDATA. 2022.910030/BIBTEX. URLwww.frontiersin.org. Cited on pages 5 and 8
-
[52]
The youtube video recommendation system
James Davidson, Benjamin Liebald, Junning Liu, Palash Nandy, Taylor Van Vleet, Ullas Gargi, Sujoy Gupta, Yu He, Mike Lambert, Blake Livingston, and Dasarathi Sampath. The youtube video recommendation system. In Proceedings of the Fourth ACM Conference on Recommender Systems, Rec- Sys ’10, page 293–296, New York, NY, USA, 2010. Association for Comput- ing ...
-
[53]
Meltem Dayio˘ glu and Cem Ba¸ slevent. Imputed rents and regional income inequality in turkey: A subgroup decomposition of the atkinson index.Regional Studies, 40(8):889–905, 2006. doi: 10.1080/00343400600984395. URLhttps: //doi.org/10.1080/00343400600984395. Cited on pages 254 and 265. 283
- [54]
-
[55]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page internal anchor Pith review arXiv 2025
-
[56]
Cfairllm: Consumer fairness eval- uation in large-language model recommender system.ACM Trans
Yashar Deldjoo and Tommaso Di Noia. Cfairllm: Consumer fairness eval- uation in large-language model recommender system.ACM Trans. Intell. Syst. Technol., March 2025. ISSN 2157-6904. doi: 10.1145/3725853. URL https://doi.org/10.1145/3725853. Just Accepted. Cited on pages 11, 31, 252, and 253
-
[57]
Yashar Deldjoo and Fatemeh Nazary. A normative framework for benchmark- ing consumer fairness in large language model recommender system, 2024. URL https://arxiv.org/abs/2405.02219. Cited on pages 31 and 253
-
[58]
Recommender Systems Fairness Evaluation via General- ized Cross Entropy
Yashar Deldjoo, Vito Walter Anelli, Hamed Zamani, Alejandro Bellog´ ın, and Tommaso Di Noia. Recommender Systems Fairness Evaluation via General- ized Cross Entropy. InProceedings of the Workshop on Recommendation in Multi-stakeholder Environments co-located with the 13th ACM Conference on Recommender Systems (RecSys 2019). CEUR-WS, 2019. Cited on pages 1...
2019
-
[59]
Yashar Deldjoo, Vito Walter Anelli, Hamed Zamani, Alejandro Bellog´ ın,• Tommaso, and Di Noia. A flexible framework for evaluating user and item fairness in recommender systems.User Modeling and User-Adapted Interaction, 31:457–511, 2021. doi: 10.1007/s11257-020-09285-1. URLhttps://doi.org/ 10.1007/s11257-020-09285-1. Cited on pages 253 and 264
-
[60]
Yashar Deldjoo, Dietmar Jannach, Alejandro Bellogin, Alessandro Difonzo, and Dario Zanzonelli. Fairness in recommender systems: research landscape and future directions.User Modeling and User-Adapted Interaction, 34(1):59– 108, 2024. ISSN 1573-1391. doi: 10.1007/s11257-023-09364-z. URLhttps: //doi.org/10.1007/s11257-023-09364-z. Cited on pages 2, 6, 9, 12...
-
[61]
Mukund Deshpande and George Karypis. Item-based top-N recommendation algorithms.ACM Transactions on Information Systems, 22(1):143–177, 1 2004. ISSN 10468188. doi: 10.1145/963770.963776. URLhttps://dl.acm.org/doi/ 10.1145/963770.963776. Cited on pages 6, 53, 110, 151, 195, and 230
-
[62]
Fernando Diaz, Bhaskar Mitra, Michael D Ekstrand, Asia J Biega, and Ben Carterette. Evaluating Stochastic Rankings with Expected Exposure. InPro- 285 ceedings of the 29th ACM International Conference on Information & Knowl- edge Management, New York, NY, USA, 2020. ACM. ISBN 9781450368599. doi: 10.1145/3340531. URLhttps://doi.org/10.1145/3340531.3411962. ...
-
[63]
Karlijn Dinnissen and Christine Bauer. Amplifying artists’ voices: Item provider perspectives on influence and fairness of music streaming platforms. InProceedings of the 31st ACM Conference on User Modeling, Adaptation and Personalization, UMAP ’23, page 238–249, New York, NY, USA, 2023. Associ- ation for Computing Machinery. ISBN 9781450399326. doi: 10....
-
[64]
Theses, Universit´ e Paris sciences et lettres, July 2023
Virginie Do.Fairness in recommender systems: insights from social choice. Theses, Universit´ e Paris sciences et lettres, July 2023. URLhttps://theses. hal.science/tel-04213955. Cited on page 249
2023
-
[65]
InACM Conference on Research and Development in Information Retrieval (SIGIR)
Virginie Do and Nicolas Usunier. Optimizing Generalized Gini Indices for Fairness in Rankings. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, volume 1, pages 737–747, New York, NY, USA, 2022. ACM. ISBN 9781450387323. doi: 10.1145/3477495. URLhttps://doi.org/10.1145/3477495.3532035. Cited ...
-
[66]
Two-sided fairness in rankings via Lorenz dominance
Virginie Do, Sam Corbett-Davies, Jamal Atif, and Nicolas Usunier. Two-sided fairness in rankings via Lorenz dominance. InAdvances in Neural Information Processing Systems, volume 34, pages 8596–8608, 2021. Cited on pages 20, 35, 36, 38, 39, 48, and 71
2021
-
[67]
Virginie Do, Sam Corbett-Davies, Jamal Atif, and Nicolas Usunier. Online Certification of Preference-Based Fairness for Personalized Recommender Sys- tems.Proceedings of the AAAI Conference on Artificial Intelligence, 36(6): 6532–6540, 6 2022. doi: 10.1609/aaai.v36i6.20606. URLhttps://ojs.aaai. org/index.php/AAAI/article/view/20606. Cited on pages 25, 225...
-
[68]
Yijiang River Dong, Tiancheng Hu, and Nigel Collier. Can LLM be a person- alized judge? In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, edi- tors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 10126–10141, Miami, Florida, USA, November 2024. Association for 286 Computational Linguistics. doi: 10.18653/v1/2024.findings-e...
-
[69]
Fairness through awareness , isbn =
Cynthia Dwork, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Richard Zemel. Fairness through awareness. InITCS 2012 - Innovations in Theoretical Computer Science Conference, pages 214–226, 2012. ISBN 9781450311151. doi: 10.1145/2090236.2090255. URLhttps://dl.acm.org/doi/10.1145/ 2090236.2090255. Cited on pages 3, 10, 14, 17, 25, 40, 102, 111, 125, 151...
-
[70]
All The Cool Kids, How Do They Fit In?: Popularity and Demographic Biases in Rec- ommender Evaluation and Effectiveness
Michael D Ekstrand, Mucun Tian, Ion Madrazo Azpiazu, Jennifer D Ekstrand, Oghenemaro Anuyah, David McNeill, and Maria Soledad Pera. All The Cool Kids, How Do They Fit In?: Popularity and Demographic Biases in Rec- ommender Evaluation and Effectiveness. In Sorelle A Friedler and Christo Wilson, editors,Proceedings of the 1st Conference on Fairness, Account...
2018
-
[71]
Ekstrand, Anubrata Das, Robin Burke, and Fernando Diaz
Michael D. Ekstrand, Anubrata Das, Robin Burke, and Fernando Diaz. Fair- ness in information access systems.Foundations and Trends®in Information Retrieval, 16(1-2):1–177, 2022. ISSN 1554-0669. doi: 10.1561/1500000079. URLhttp://dx.doi.org/10.1561/1500000079. Cited on pages 2, 4, 8, 10, 11, 29, 102, 125, and 180
-
[72]
Distributionally- Informed Recommender System Evaluation.ACM Trans
Michael D Ekstrand, Ben Carterette, and Fernando Diaz. Distributionally- Informed Recommender System Evaluation.ACM Trans. Recomm. Syst., 8 2023. doi: 10.1145/3613455. URLhttps://doi.org/10.1145/3613455. Cited on page 181
-
[73]
Beyond algorithmic fairness in recommender systems
Mehdi Elahi, Himan Abdollahpouri, Masoud Mansoury, and Helma Torka- maan. Beyond algorithmic fairness in recommender systems. InAdjunct Pro- ceedings of the 29th ACM Conference on User Modeling, Adaptation and Per- sonalization, UMAP ’21, page 41–46, New York, NY, USA, 2021. Associa- tion for Computing Machinery. ISBN 9781450383677. doi: 10.1145/3450614. ...
-
[74]
Guido Erreygers, Roselinde Kessels, Linkun Chen, and Philip Clarke. Subgroup decomposability of income-related inequality of health, with an application to 287 australia.Economic Record, 94(304):39–50, 2018. doi: https://doi.org/10. 1111/1475-4932.12373. URLhttps://onlinelibrary.wiley.com/doi/abs/ 10.1111/1475-4932.12373. Cited on page 265
-
[75]
Regulation (EU) 2024/1689: Artificial Intelligence Act, 2024
European Parliament and Council. Regulation (EU) 2024/1689: Artificial Intelligence Act, 2024. URLhttps://eur-lex.europa.eu/eli/reg/2024/ 1689/oj/eng. Recital 27 discusses principles for trustworthy and ethical AI. Cited on page 1
2024
-
[76]
Young people on the labour market - statistics, 2018
Eurostat. Young people on the labour market - statistics, 2018. URL https://ec.europa.eu/eurostat/statistics-explained/index.php? title=Young_people_on_the_labour_market_-_statistics. Cited on page 252
2018
-
[77]
Pairwise Fairness in Ranking as a Dissatisfaction Measure
Alessandro Fabris, Gianmaria Silvello, Gian Antonio Susto, and Asia J Biega. Pairwise Fairness in Ranking as a Dissatisfaction Measure. InProceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, WSDM ’23, pages 931–939, New York, NY, USA, 2023. Association for Com- puting Machinery. ISBN 9781450394079. doi: 10.1145/3539597....
-
[78]
Friedler, John Moeller, Carlos Scheidegger, and Suresh Venkatasubramanian
Michael Feldman, Sorelle A. Friedler, John Moeller, Carlos Scheidegger, and Suresh Venkatasubramanian. Certifying and removing disparate impact. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’15, page 259–268, New York, NY, USA,
-
[79]
Association for Computing Machinery. ISBN 9781450336642. doi: 10. 1145/2783258.2783311. URLhttps://doi.org/10.1145/2783258.2783311. Cited on page 11
-
[80]
Break the loop: Gen- der imbalance in music recommenders
Andres Ferraro, Xavier Serra, and Christine Bauer. Break the loop: Gen- der imbalance in music recommenders. InProceedings of the 2021 Con- ference on Human Information Interaction and Retrieval, CHIIR ’21, page 249–254, New York, NY, USA, 2021. Association for Computing Machin- ery. ISBN 9781450380553. doi: 10.1145/3406522.3446033. URLhttps: //doi.org/10...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.