Recognition: unknown
Beyond Accuracy: Benchmarking Cross-Task Consistency in Unified Multimodal Models
Pith reviewed 2026-05-08 04:02 UTC · model grok-4.3
The pith
Unified multimodal models can excel at understanding and generation separately yet fail to stay consistent on the same visual facts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Unified Multimodal Models do not automatically learn representations that are consistent across understanding and generation tasks for the same visual concept. Experiments across nine models show that high accuracy in one or both tasks frequently coexists with low semantic agreement on matched facts. Consistency is instead determined by the degree to which learning objectives are coupled across modalities, independent of architectural unification.
What carries the argument
XTC-Bench, a scene-graph-grounded evaluation framework that derives both generation prompts and understanding queries from the same structured scene graph to enable fact-level alignment analysis via the Continuous Cross-Task Agreement (CCTA) metric.
Load-bearing premise
That deriving both generation prompts and understanding queries from the same scene graph produces fact-level alignment that accurately isolates internal model consistency from standalone task performance.
What would settle it
A model that achieves high scores on both generation and understanding tasks while also showing high agreement on the specific facts extracted from the shared scene graph, particularly if its objectives are loosely coupled.
Figures
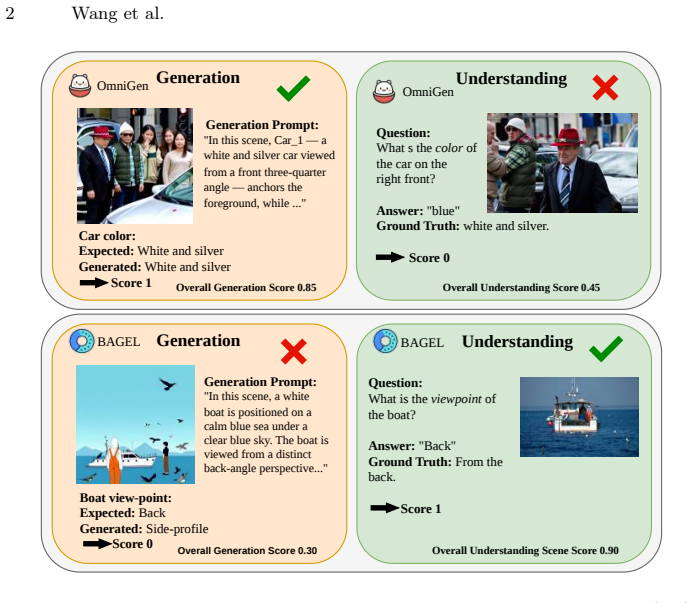











read the original abstract
Unified Multimodal Models (uMMs) aim to support both visual understanding and visual generation within a shared representation. However, existing evaluation protocols assess these two capabilities independently and do not examine whether they are semantically aligned. As a result, it remains unclear whether current uMMs learn coherent unified representations that remain consistent across tasks given a visual concept. We introduce XTC-Bench, a scene-graph-grounded evaluation framework that measures cross-task visual semantic consistency. By deriving both generation prompts and understanding queries from a structured scene graph, our framework enables fact-level alignment analysis across objects, attributes, and relations. We propose Continuous Cross-Task Agreement (CCTA), a fine-grained metric that quantifies semantic agreement between generation and understanding over matched atomic facts, isolating internal consistency from standalone task accuracy. Extensive experiments on eight open-source and one commercial unified models reveal that high generation or understanding performance does not imply strong cross-task alignment, and architectural analysis shows consistency is governed by how tightly learning objectives are coupled across modalities, not by architectural unification alone. XTC-Bench provides a reproducible and model-agnostic framework for diagnosing representation-level misalignment, offering a concrete direction for advancing unified multimodal modeling beyond isolated task performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces XTC-Bench, a scene-graph-grounded evaluation framework for unified multimodal models (uMMs), along with the Continuous Cross-Task Agreement (CCTA) metric. It derives both generation prompts and understanding queries from the same structured scene graph to enable fact-level semantic alignment analysis across objects, attributes, and relations. Experiments on nine models (eight open-source, one commercial) show that high standalone generation or understanding performance does not imply strong cross-task consistency, and that consistency depends on tight coupling of learning objectives across modalities rather than architectural unification alone.
Significance. If the CCTA metric validly isolates representation-level consistency, the work provides a reproducible, model-agnostic benchmark that shifts evaluation of uMMs from isolated task accuracies toward diagnosing unified representations. The finding that objective coupling governs consistency offers a concrete, actionable direction for model development beyond architectural unification. The framework's grounding in scene graphs and focus on atomic facts is a methodological strength.
major comments (3)
- [Methods (CCTA definition)] Methods section on CCTA definition: The metric quantifies semantic agreement over matched atomic facts extracted from the shared scene graph and is claimed to isolate internal consistency from standalone task accuracy. However, generation uses synthesized prompts from the graph while understanding uses queries on the resulting image, so mismatches can arise from stylistic differences in prompt/query formulation or noise in automatic fact extraction. No ablations or controls (e.g., human-verified facts, varied prompt styles, or extraction sensitivity tests) are described to rule out these artifacts; this is load-bearing for the central claim that low CCTA reflects model misalignment rather than evaluation confounds.
- [Experiments] Experiments section (results on nine models): The abstract and results report CCTA scores supporting that high task performance does not imply alignment, but without visible error bars, statistical significance tests, or full details on data splits, scene-graph construction, and extraction pipelines, it is impossible to confirm robustness or rule out post-hoc choices affecting the scores. Specific per-model tables correlating CCTA with accuracy should be provided with variance estimates.
- [Architectural analysis] Architectural analysis section: The conclusion that consistency is governed by objective coupling (not unification alone) requires concrete model comparisons. For example, identify pairs of models with similar architectures but differing objective couplings and report their quantitative CCTA differences; without this, the architectural claim rests on correlational observations rather than controlled evidence.
minor comments (2)
- [Abstract] Abstract and introduction: Explicitly list the nine evaluated models (with citations) rather than describing them only as 'eight open-source and one commercial' to improve reproducibility.
- [Figures/Tables] Figures/tables: Add error bars or confidence intervals to any plots or tables reporting CCTA scores, and ensure legends clearly distinguish CCTA from standalone accuracy metrics.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped clarify several aspects of our work. We address each major comment point by point below, indicating the revisions made to strengthen the manuscript.
read point-by-point responses
-
Referee: Methods section on CCTA definition: The metric quantifies semantic agreement over matched atomic facts extracted from the shared scene graph and is claimed to isolate internal consistency from standalone task accuracy. However, generation uses synthesized prompts from the graph while understanding uses queries on the resulting image, so mismatches can arise from stylistic differences in prompt/query formulation or noise in automatic fact extraction. No ablations or controls (e.g., human-verified facts, varied prompt styles, or extraction sensitivity tests) are described to rule out these artifacts; this is load-bearing for the central claim that low CCTA reflects model misalignment rather than evaluation confounds.
Authors: We agree that potential artifacts from automatic extraction and prompt formulation must be ruled out to support the central claim. The original manuscript relied on the shared scene-graph structure to ensure semantic equivalence but did not report explicit controls. In the revision, we have added a dedicated subsection in Methods with three controls: human verification of 200 randomly sampled facts (94% agreement with automatic extraction), sensitivity analysis across three prompt/query style variants (CCTA standard deviation below 0.04), and robustness checks using an alternative fact extractor. These results are now reported in the main text and Appendix, confirming that CCTA primarily captures model-level misalignment rather than evaluation noise. We have also revised the CCTA definition paragraph to explicitly discuss how the metric isolates consistency from task accuracy. revision: yes
-
Referee: Experiments section (results on nine models): The abstract and results report CCTA scores supporting that high task performance does not imply alignment, but without visible error bars, statistical significance tests, or full details on data splits, scene-graph construction, and extraction pipelines, it is impossible to confirm robustness or rule out post-hoc choices affecting the scores. Specific per-model tables correlating CCTA with accuracy should be provided with variance estimates.
Authors: We acknowledge the need for greater experimental transparency and reproducibility. The revised Experiments section now includes error bars (standard deviation over three random seeds for open-source models), paired statistical significance tests (Wilcoxon signed-rank) on CCTA differences, and expanded details on scene-graph construction (sourced from Visual Genome), the evaluation split, and the full extraction pipeline (including LLM prompts and filtering steps) in the Appendix. We have also added a new table correlating per-model CCTA with generation and understanding accuracies, complete with variance estimates. These changes directly address concerns about post-hoc choices and confirm the robustness of the reported trends. revision: yes
-
Referee: Architectural analysis section: The conclusion that consistency is governed by objective coupling (not unification alone) requires concrete model comparisons. For example, identify pairs of models with similar architectures but differing objective couplings and report their quantitative CCTA differences; without this, the architectural claim rests on correlational observations rather than controlled evidence.
Authors: We accept that the original architectural analysis was largely observational. To provide controlled evidence, the revised section now explicitly identifies and compares model pairs with comparable architectures but differing objective couplings (e.g., models trained with joint cross-modal objectives versus those with more decoupled per-task objectives). We report the corresponding CCTA differences for these pairs and discuss how the degree of objective coupling explains the observed consistency gaps beyond architectural unification alone. This addition moves the claim from correlation toward controlled comparison while remaining grounded in the evaluated models. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper introduces XTC-Bench and the CCTA metric as an explicit new framework: generation prompts and understanding queries are both derived from the same scene graph to enable fact-level comparison, with CCTA defined directly as semantic agreement over matched atomic facts. This construction isolates the consistency measure by design rather than deriving it from model outputs or prior results. The central claims (high task performance does not imply alignment; consistency depends on objective coupling) are presented as empirical findings from experiments across nine models, without any equations, fitted parameters, or self-citations that reduce the result to its inputs by construction. No self-definitional loops, renamed known results, or load-bearing self-citations appear in the abstract or described methodology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scene graphs can be used to derive both generation prompts and understanding queries that enable fact-level semantic alignment analysis across tasks.
invented entities (1)
-
Continuous Cross-Task Agreement (CCTA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Agrawal, A., Lu, J., Antol, S., Mitchell, M., Zitnick, C.L., Batra, D., Parikh, D.: Vqa: Visual question answering (2016),https://arxiv.org/abs/1505.00468
work page Pith review arXiv 2016
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review arXiv 2025
-
[3]
IEEE Transactions on Pattern Analysis and Machine Intelligence45(1), 1–26 (2021)
Chang, X., Ren, P., Xu, P., Li, Z., Chen, X., Hauptmann, A.: A comprehensive survey of scene graphs: Generation and application. IEEE Transactions on Pattern Analysis and Machine Intelligence45(1), 1–26 (2021)
2021
-
[4]
Chen, J., Xu, Z., Pan, X., Hu, Y., Qin, C., Goldstein, T., Huang, L., Zhou, T., Xie, S., Savarese, S., Xue, L., Xiong, C., Xu, R.: Blip3-o: A family of fully open unified multimodalmodels-architecture,traininganddataset(2025),https://arxiv.org/ abs/2505.09568
work page Pith review arXiv 2025
-
[5]
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C.: Janus-pro: Unified multimodal understanding and generation with data and model scaling (2025),https://arxiv.org/abs/2501.17811
work page internal anchor Pith review arXiv 2025
- [6]
- [7]
- [8]
-
[9]
In: Proceedings of the IEEE conference on computer vision and Pattern recognition
Dai, B., Zhang, Y., Lin, D.: Detecting visual relationships with deep relational networks. In: Proceedings of the IEEE conference on computer vision and Pattern recognition. pp. 3076–3086 (2017)
2017
-
[10]
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., Shi, G., Fan, H.: Emerging properties in unified multimodal pretraining (2025),https://arxiv.org/abs/2505.14683 20 Wang et al
work page internal anchor Pith review arXiv 2025
-
[11]
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., Wu, Y., Ji, R., Shan, C., He, R.: Mme: A comprehensive evaluation benchmark for multimodal large language models (2025),https://arxiv.org/ abs/2306.13394
work page internal anchor Pith review arXiv 2025
- [12]
- [13]
-
[14]
Gu, J., Jiang, X., Shi, Z., Tan, H., Zhai, X., Xu, C., Li, W., Shen, Y., Ma, S., Liu, H., Wang, S., Zhang, K., Wang, Y., Gao, W., Ni, L., Guo, J.: A survey on llm-as-a-judge (2025),https://arxiv.org/abs/2411.15594
work page internal anchor Pith review arXiv 2025
- [15]
-
[16]
In: Proceedings of the 2021 conference on empirical methods in natural language processing
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., Choi, Y.: Clipscore: A reference- free evaluation metric for image captioning. In: Proceedings of the 2021 conference on empirical methods in natural language processing. pp. 7514–7528 (2021)
2021
- [17]
- [18]
- [19]
-
[20]
Krishna,R.,Zhu,Y.,Groth,O.,Johnson,J.,Hata,K.,Kravitz,J.,Chen,S.,Kalan- tidis, Y., Li, L.J., Shamma, D.A., Bernstein, M.S., Li, F.F.: Visual genome: Con- necting language and vision using crowdsourced dense image annotations (2016), https://arxiv.org/abs/1602.07332
work page Pith review arXiv 2016
-
[21]
Li, B., Wang, R., Wang, G., Ge, Y., Ge, Y., Shan, Y.: Seed-bench: Benchmarking multimodal llms with generative comprehension (2023),https://arxiv.org/abs/ 2307.16125
work page internal anchor Pith review arXiv 2023
- [22]
- [23]
-
[24]
Lin, T.Y., Maire, M., Belongie, S., Bourdev, L., Girshick, R., Hays, J., Perona, P., Ramanan, D., Zitnick, C.L., Dollár, P.: Microsoft coco: Common objects in context (2015),https://arxiv.org/abs/1405.0312
work page internal anchor Pith review arXiv 2015
-
[25]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., Chen, K., Lin, D.: Mmbench: Is your multi-modal model an all-around player? (2024),https://arxiv.org/abs/2307.06281
work page internal anchor Pith review arXiv 2024
-
[26]
09216 Title Suppressed Due to Excessive Length 21
Lorenz, J., Pest, A., Kienzle, D., Ludwig, K., Lienhart, R.: A fair ranking and new model for panoptic scene graph generation (2024),https://arxiv.org/abs/2407. 09216 Title Suppressed Due to Excessive Length 21
2024
-
[27]
arXiv preprint arXiv:2502.20321 (2025) 9
Ma, C., Jiang, Y., Wu, J., Yang, J., Yu, X., Yuan, Z., Peng, B., Qi, X.: Unitok: A unified tokenizer for visual generation and understanding (2025),https://arxiv. org/abs/2502.20321
- [28]
-
[29]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert- networks. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics (11 2019),https: //arxiv.org/abs/1908.10084
work page internal anchor Pith review arXiv 2019
-
[30]
Shi, Y., Dong, Y., Ding, Y., Wang, Y., Zhu, X., Zhou, S., Liu, W., Tian, H., Wang, R., Wang, H., Liu, Z., Zeng, B., Chen, R., Wang, Q., Zhang, Z., Chen, X., Tong, C., Li, B., Fu, C., Liu, Q., Wang, H., Yang, W., Zhang, Y., Wan, P., Zhang, Y.F., Liu, Z.: Realunify: Do unified models truly benefit from unification? a comprehensive benchmark (2025),https://a...
-
[31]
Team,C.:Chameleon:Mixed-modalearly-fusionfoundationmodels.arXivpreprint arXiv:2405.09818 (2024)
work page internal anchor Pith review arXiv 2024
- [32]
- [33]
-
[34]
Wang, X., Liu, J., Huang, C., Yu, X., Wang, Z., Sun, X., Wu, J., Yuille, A., Barsoum, E., Liu, Z.: Xmodbench: Benchmarking cross-modal capabilities and consistencyinomni-languagemodels(2025),https://arxiv.org/abs/2510.15148
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Emu3: Next-Token Prediction is All You Need
Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y., Wang, J., Zhang, F., Wang, Y., Li, Z., Yu, Q., et al.: Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869 (2024)
work page internal anchor Pith review arXiv 2024
-
[36]
Wu, C., Zheng, P., Yan, R., Xiao, S., Luo, X., Wang, Y., Li, W., Jiang, X., Liu, Y., Zhou, J., Liu, Z., Xia, Z., Li, C., Deng, H., Wang, J., Luo, K., Zhang, B., Lian, D., Wang, X., Wang, Z., Huang, T., Liu, Z.: Omnigen2: Exploration to advanced multimodal generation (2025),https://arxiv.org/abs/2506.18871
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Xie, J., Mao, W., Bai, Z., Zhang, D.J., Wang, W., Lin, K.Q., Gu, Y., Chen, Z., Yang, Z., Shou, M.Z.: Show-o: One single transformer to unify multimodal under- standing and generation (2025),https://arxiv.org/abs/2408.12528
work page internal anchor Pith review arXiv 2025
-
[38]
Xie, J., Yang, Z., Shou, M.Z.: Show-o2: Improved native unified multimodal models (2025),https://arxiv.org/abs/2506.15564
work page internal anchor Pith review arXiv 2025
- [39]
-
[40]
In: Proceedings of the IEEE conference on computer vision and pat- tern recognition
Xu, D., Zhu, Y., Choy, C.B., Fei-Fei, L.: Scene graph generation by iterative mes- sage passing. In: Proceedings of the IEEE conference on computer vision and pat- tern recognition. pp. 5410–5419 (2017)
2017
-
[41]
Yang, L., Tian, Y., Li, B., Zhang, X., Shen, K., Tong, Y., Wang, M.: Mmada: Mul- timodal large diffusion language models (2025),https://arxiv.org/abs/2505. 15809
2025
- [42]
-
[43]
Yu, Q., Wang, H., Qiao, S., Collins, M., Zhu, Y., Adam, H., Yuille, A., Chen, L.C.: kmax-deeplab: k-means mask transformer (2023),https://arxiv.org/abs/2207. 04044
2023
-
[44]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zellers, R., Yatskar, M., Thomson, S., Choi, Y.: Neural motifs: Scene graph parsing with global context. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5831–5840 (2018)
2018
- [45]
- [46]
-
[47]
Uni-MMMU: A Massive Multi-discipline Multimodal Unified Benchmark
Zou, K., Huang, Z., Dong, Y., Tian, S., Zheng, D., Liu, H., He, J., Liu, B., Qiao, Y., Liu, Z.: Uni-mmmu: A massive multi-discipline multimodal unified benchmark (2026),https://arxiv.org/abs/2510.13759 Appendix 6.1 Detailed Dataset Implementation Selection of Panoptic Segmentation ModelAs described in Section 3.2.1 of the main paper, our approach builds u...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.