DGLight: DQN-Guided GRPO Fine-Tuning of Large Language Models for Traffic Signal Control
Pith reviewed 2026-05-07 16:59 UTC · model grok-4.3
The pith
A DQN critic trained on intersection states guides GRPO to fine-tune LLMs into traffic signal controllers that reason step by step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
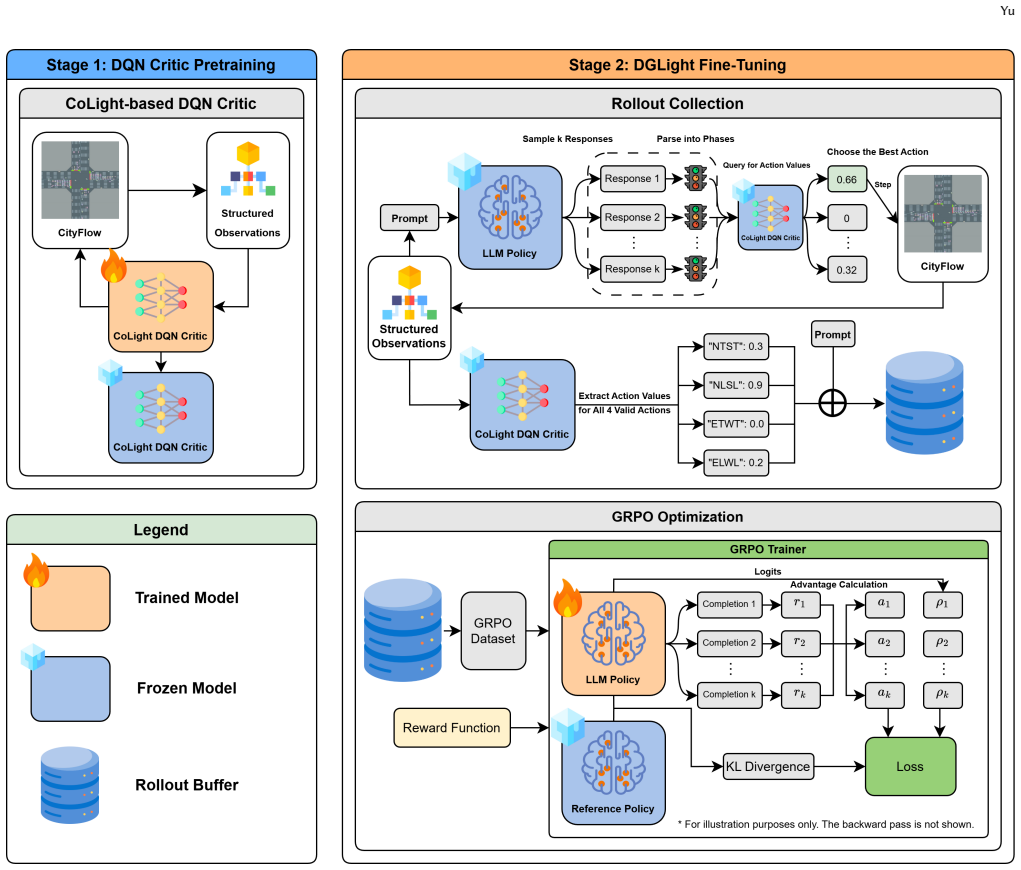
DGLight first trains a CoLight-based Deep Q-Network critic to estimate traffic-aware action values from structured intersection states, then uses the frozen critic to score candidate language-model actions and optimize the policy with Group Relative Policy Optimization. The resulting controller maps traffic states to interpretable reasoning traces and signal decisions while learning from dense per-state supervision rather than raw cumulative environment rewards.
What carries the argument
The frozen CoLight-based DQN critic that supplies action-value scores to rank and select LLM-generated actions during GRPO policy updates.
If this is right
- DGLight outperforms other LLM-based traffic signal controllers on the Jinan and Hangzhou benchmarks.
- The controller remains competitive with strong reinforcement learning baselines while adding interpretable reasoning.
- The same critic-trained policy transfers successfully to traffic data from cities not used in critic training.
- Generated reasoning traces align with the chosen signal phases and can be inspected by humans.
Where Pith is reading between the lines
- The dense supervision from an external critic may let language models learn sequential control tasks with fewer environment samples than standard RL fine-tuning.
- Transfer across cities suggests the state representation used by the critic captures general features of urban traffic flow.
- Combining language models with value-based critics could extend to other domains that need both performance and human-readable explanations of decisions.
Load-bearing premise
The CoLight-based DQN critic produces reliable and unbiased action-value scores that remain valid when used to supervise the LLM on both seen and unseen city traffic patterns.
What would settle it
LLM performance collapses on a new city dataset where the critic's value estimates are deliberately made inaccurate or are shown not to correlate with actual traffic outcomes.
Figures

read the original abstract
Traffic signal control (TSC) plays a central role in reducing congestion and maintaining urban mobility. This dissertation introduces DGLight, a critic-guided reinforcement-learning framework for adapting a pretrained large language model to TSC. DGLight first trains a CoLight-based Deep Q-Network critic to estimate traffic-aware action values from structured intersection states, then uses the frozen critic to score candidate language-model actions and optimize the policy with Group Relative Policy Optimization (GRPO). The resulting controller maps traffic states to interpretable reasoning traces and signal decisions while learning from dense per-state supervision rather than raw cumulative environment rewards. Experiments on TSC benchmarks covering Jinan and Hangzhou show that DGLight is the strongest overall method among the compared LLM-based controllers, remains competitive with strong RL baselines, and transfers well to city datasets not used to fit the critic. Qualitative examples further show that the model's generated reasoning is interpretable and aligned with the chosen signal phase. The project code is available $\href{https://github.com/yyccbb/FYP_LLMTSC}{here}$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DGLight, a hybrid framework that first trains a frozen CoLight-based DQN critic on structured intersection states to produce action-value scores, then uses those scores as dense supervision targets within Group Relative Policy Optimization (GRPO) to fine-tune a pretrained LLM policy for traffic signal control. The LLM outputs both interpretable reasoning traces and signal phases. On Jinan and Hangzhou TSC benchmarks the method is reported to outperform other LLM-based controllers, remain competitive with strong RL baselines, and transfer successfully to city datasets excluded from critic training.
Significance. If the central results hold, the work provides a concrete demonstration that a separately trained critic can supply reliable per-state guidance for LLM policy optimization in a continuous control domain, improving both sample efficiency and interpretability relative to pure reward-based fine-tuning. The public release of code is a clear positive for reproducibility and follow-up work.
major comments (3)
- [Experiments section (transfer evaluation)] The transfer results to unseen city datasets (reported in the experiments) rest on the assumption that the CoLight DQN critic produces accurate and unbiased Q-values under distribution shift. No critic-specific diagnostics—prediction error, ranking correlation with realized returns, or calibration plots—are supplied for the transfer cities, leaving open the possibility that GRPO receives systematically noisy or biased targets.
- [Results and experimental setup] The superiority claim among LLM-based controllers and competitiveness with RL baselines lacks reported statistical significance, standard errors across random seeds, or explicit hyperparameter tables. Without these, it is difficult to attribute performance gains specifically to the critic-guided GRPO rather than to implementation details or post-hoc selection.
- [Method (GRPO integration)] The precise mapping from critic Q-values to the GRPO reward signal (normalization, clipping, or relative ranking within groups) is not fully specified, making it hard to verify that the optimization is truly driven by dense per-state supervision rather than by the underlying environment reward.
minor comments (2)
- [Abstract] The abstract states that the code is available at the given GitHub link; the repository should be checked to ensure it contains the full set of training scripts, critic checkpoints, and evaluation environments used for the reported numbers.
- [Preliminaries / Method] Notation for the LLM input state encoding and the exact form of the GRPO objective function could be clarified with a short equation or pseudocode block to aid readers unfamiliar with the GRPO variant.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, proposing revisions to strengthen the paper where the concerns are valid. The code release already allows verification of implementation details, but we will improve the manuscript's clarity and completeness accordingly.
read point-by-point responses
-
Referee: The transfer results to unseen city datasets (reported in the experiments) rest on the assumption that the CoLight DQN critic produces accurate and unbiased Q-values under distribution shift. No critic-specific diagnostics—prediction error, ranking correlation with realized returns, or calibration plots—are supplied for the transfer cities, leaving open the possibility that GRPO receives systematically noisy or biased targets.
Authors: We agree that direct diagnostics for the critic under distribution shift would provide stronger support for the transfer results. Although the competitive performance on unseen cities offers indirect validation, we will add critic-specific analysis in the revised experiments section, including mean prediction error, Spearman ranking correlation with realized returns, and calibration plots for the transfer city datasets. revision: yes
-
Referee: The superiority claim among LLM-based controllers and competitiveness with RL baselines lacks reported statistical significance, standard errors across random seeds, or explicit hyperparameter tables. Without these, it is difficult to attribute performance gains specifically to the critic-guided GRPO rather than to implementation details or post-hoc selection.
Authors: We acknowledge this limitation in the current reporting. The manuscript presents average performance metrics but omits variability measures and significance testing. In the revision, we will report results across multiple random seeds with standard errors, include statistical significance tests (e.g., paired t-tests against baselines), and add an explicit hyperparameter table in the appendix covering all models and training settings. revision: yes
-
Referee: The precise mapping from critic Q-values to the GRPO reward signal (normalization, clipping, or relative ranking within groups) is not fully specified, making it hard to verify that the optimization is truly driven by dense per-state supervision rather than by the underlying environment reward.
Authors: We thank the referee for noting this gap in the method description. The GRPO objective relies on normalized critic Q-values for within-group relative ranking as the dense reward signal, without direct use of the raw environment reward. We will expand the method section with the exact formulation, including the normalization procedure and group-relative computation, to make the supervision mechanism fully transparent. revision: yes
Circularity Check
No significant circularity; critic training is independent of LLM policy optimization
full rationale
The derivation proceeds by first training a separate CoLight DQN critic on structured intersection states from training cities, freezing its parameters, and then using its fixed action-value outputs as dense targets for GRPO fine-tuning of the LLM policy. This separation means the LLM optimization does not reduce to a re-fit or re-definition of the critic itself. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided description to justify the core steps. The transfer claim to unseen cities rests on an external generalization assumption rather than any internal reduction by construction. The method is therefore self-contained against its own benchmarks without circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chen, Chacha, Hua Wei, Nan Xu, Guanjie Zheng, Ming Yang, Yuan- hao Xiong, Kai Xu, and Zhenhui Li (Apr. 2020). “Toward A Thou- sand Lights: Decentralized Deep Reinforcement Learning for Large-Scale Traffic Signal Control. ” In:Proceedings of the AAAI Conference on Artificial Intelligence34.04, pp. 3414–3421.doi: 10.1609/aaai.v34i04.5744.url: https://ojs.aa...
-
[2]
Proceedings of Machine Learning Research. PMLR, pp. 26645–26654.url: https://proceedings.mlr. press/v162/zhang22ah.html. Zhang, Yifeng, Peizhuo Li, Tingguang Zhou, Mingfeng Fan, and Guillaume Sartoretti (2026).LATS: Large Language Model As- sisted Teacher-Student Framework for Multi-Agent Reinforcement Learning in Traffic Signal Control. arXiv: 2603.24361...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.