JURY-RL: Votes Propose, Proofs Dispose for Label-Free RLVR
Pith reviewed 2026-05-07 16:15 UTC · model grok-4.3
The pith
JURY-RL lets model rollouts vote on answers then rewards only those matching a formally verified plurality, reaching supervised-level math performance without labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
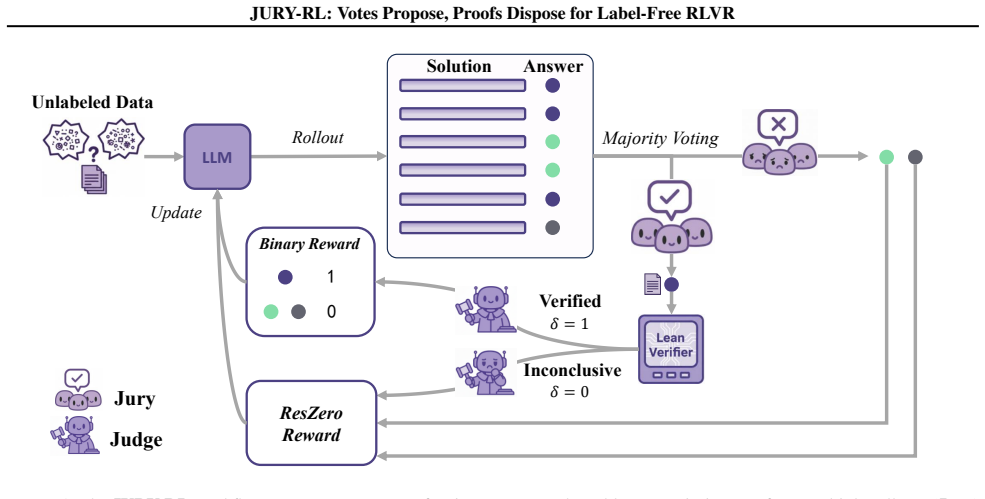
JURY-RL decouples answer proposal from reward disposal: votes from model rollouts propose a candidate answer, and a formal verifier determines whether that candidate can receive positive reward. Concretely, only rollouts matching the plurality-voted answer are rewarded when that answer is successfully verified in Lean. When verification is inconclusive, ResZero (Residual-Zero) discards the unverified plurality proposal and redistributes a zero-mean, variance-preserving signal over the residual answers. This design maintains a stable optimization gradient without reinforcing unverifiable consensus.
What carries the argument
Decoupling of proposal via plurality votes from disposal via Lean verification, with ResZero as the neutral fallback signal when verification fails.
If this is right
- JURY-RL outperforms other label-free baselines on mathematical reasoning benchmarks across three backbone models.
- It reaches pass@1 accuracy comparable to supervised training that uses ground-truth labels.
- It produces higher pass@k scores and greater response diversity, indicating stronger generalization.
- Performance transfers competitively to code generation tasks and general language benchmarks.
- The optimization gradient remains stable even on problems where formal verification returns inconclusive.
Where Pith is reading between the lines
- The same vote-then-verify pattern could be applied to any domain equipped with an automated checker, such as type-checked code or formally specified protocols.
- Neutral redistribution of reward mass may help preserve exploration in other reinforcement-learning settings where consensus signals are noisy.
- If the verifier is only sound but incomplete, models may still converge on correct but unprovable answers; testing against stronger provers would quantify this gap.
- Combining JURY-RL with a small amount of verified seed data might further improve early training stability without restoring full annotation cost.
Load-bearing premise
The plurality-voted answer supplies an accurate positive reward once Lean verifies it, and the ResZero fallback redistributes a neutral signal without destabilizing gradients when verification remains inconclusive.
What would settle it
Training runs on the same math benchmarks where the ResZero component is removed or replaced by a constant zero reward; if final pass@1 and pass@k scores fall below the full JURY-RL results or below supervised baselines, the necessity of the neutral redistribution is refuted.
Figures








read the original abstract
Reinforcement learning with verifiable rewards (RLVR) enhances the reasoning of large language models (LLMs), but standard RLVR often depends on human-annotated answers or carefully curated reward specifications. In machine-checkable domains, label-free alternatives such as majority voting or LLM-as-a-judge remove annotation cost but can introduce false positives that destabilize training. We introduce JURY-RL, a label-free RLVR framework that decouples answer proposal from reward disposal: votes from model rollouts propose a candidate answer, and a formal verifier determines whether that candidate can receive positive reward. Concretely, only rollouts matching the plurality-voted answer are rewarded when that answer is successfully verified in Lean. When verification is inconclusive, we invoke ResZero (Residual-Zero), a fallback reward that discards the unverified plurality proposal and redistributes a zero-mean, variance-preserving signal over the residual answers. This design maintains a stable optimization gradient without reinforcing unverifiable consensus. Across three backbone models trained on mathematical data, JURY-RL consistently outperforms other label-free baselines on mathematical reasoning benchmarks and transfers competitively to code generation and general benchmarks. It attains pass@1 performance comparable to supervised ground-truth training, with superior generalization demonstrated by higher pass@k and response diversity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JURY-RL, a label-free RLVR framework for LLMs that decouples answer proposal (via plurality voting over model rollouts) from reward disposal (via formal Lean verification of the voted answer). Positive rewards are assigned only to matching rollouts when verification succeeds; otherwise ResZero discards the proposal and redistributes a claimed zero-mean, variance-preserving signal over residuals to preserve gradient stability. Across three backbone models trained on mathematical data, the method is claimed to outperform other label-free baselines on math reasoning benchmarks, achieve pass@1 comparable to supervised ground-truth training, and exhibit superior generalization via higher pass@k and response diversity, with competitive transfer to code generation and general benchmarks.
Significance. If the empirical claims and the ResZero modeling assumption hold, the work offers a practical route to scalable RLVR in machine-checkable domains without human labels or curated rewards, potentially lowering annotation costs while preserving or improving performance and generalization. The proposal-verification decoupling is conceptually clean and could generalize to other verifiable settings.
major comments (3)
- [Method (ResZero)] Method section (ResZero description): The claim that ResZero 'discards the unverified plurality proposal and redistributes a zero-mean, variance-preserving signal over the residual answers' is load-bearing for the stability and unbiased-gradient assertions, yet the manuscript supplies neither a derivation of the zero-mean property nor an empirical check (e.g., mean/variance statistics or reward histograms on failed-verification rollouts). If residual answers are asymmetrically distributed around the unknown ground truth, the fallback can inject policy-dependent bias.
- [Experiments] Experiments section (quantitative claims): The headline results—'consistent outperformance,' 'pass@1 performance comparable to supervised ground-truth training,' and 'superior generalization demonstrated by higher pass@k and response diversity'—are stated without visible tables, error bars, ablation studies, or statistical significance tests in the provided abstract and summary. Full evaluation tables (including per-model, per-benchmark numbers and baseline comparisons) are required to substantiate the central empirical claim.
- [Experiments (transfer)] §4 (transfer experiments): The transfer results to code generation and general benchmarks are described as 'competitive' but lack detail on whether the same ResZero mechanism was used or whether verification was available in those domains; this affects the scope of the label-free claim.
minor comments (2)
- [Abstract] Abstract: The phrase 'maintains a stable optimization gradient without reinforcing unverifiable consensus' is repeated from the method description; a brief parenthetical reference to the ResZero construction would improve readability.
- [Method] Notation: The paper should explicitly define the reward function r(·) and the ResZero redistribution operator in a single equation block for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (ResZero)] Method section (ResZero description): The claim that ResZero 'discards the unverified plurality proposal and redistributes a zero-mean, variance-preserving signal over the residual answers' is load-bearing for the stability and unbiased-gradient assertions, yet the manuscript supplies neither a derivation of the zero-mean property nor an empirical check (e.g., mean/variance statistics or reward histograms on failed-verification rollouts). If residual answers are asymmetrically distributed around the unknown ground truth, the fallback can inject policy-dependent bias.
Authors: We acknowledge that the zero-mean and variance-preserving properties of ResZero require explicit support. In the revised manuscript we will add a short derivation in the Method section showing that the redistributed signal is constructed to have zero mean (by uniform allocation over residuals independent of the policy) and preserved variance (by scaling to match the original signal's second moment). We will also include empirical checks consisting of mean/variance statistics and reward histograms computed on failed-verification rollouts across training runs. On the bias concern, the redistribution is symmetric and external to the policy; verification failure is determined by the Lean oracle rather than model outputs. We will add a brief limitations paragraph noting the assumption and its scope. revision: yes
-
Referee: [Experiments] Experiments section (quantitative claims): The headline results—'consistent outperformance,' 'pass@1 performance comparable to supervised ground-truth training,' and 'superior generalization demonstrated by higher pass@k and response diversity'—are stated without visible tables, error bars, ablation studies, or statistical significance tests in the provided abstract and summary. Full evaluation tables (including per-model, per-benchmark numbers and baseline comparisons) are required to substantiate the central empirical claim.
Authors: The full manuscript already contains per-model and per-benchmark tables with baseline comparisons in Section 4. To address visibility and rigor, we will (i) move the primary results table into the main body, (ii) add error bars from multiple random seeds, (iii) include ablations on the voting threshold and ResZero components, and (iv) report statistical significance via paired tests on the key metrics. These updates will be incorporated in the revised version. revision: yes
-
Referee: [Experiments (transfer)] §4 (transfer experiments): The transfer results to code generation and general benchmarks are described as 'competitive' but lack detail on whether the same ResZero mechanism was used or whether verification was available in those domains; this affects the scope of the label-free claim.
Authors: We will expand §4 to clarify the transfer protocol. For code generation we replace Lean verification with unit-test oracles while retaining the identical JURY-RL proposal-verification decoupling and ResZero fallback. For general benchmarks lacking any verifier we apply the voting proposal with a neutral (zero) reward signal, preserving the label-free training objective. The revised text will explicitly state these adaptations and discuss their implications for the label-free claim. revision: yes
Circularity Check
No circularity detected in derivation or claims
full rationale
The paper proposes a methodological framework (JURY-RL with ResZero fallback) rather than a mathematical derivation chain containing equations, predictions, or first-principles results. No self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described method. The zero-mean property of ResZero is presented as an explicit design choice for the reward signal, not derived from or equivalent to the inputs by construction. Performance claims are framed as empirical outcomes from training experiments on external benchmarks, not reductions to the method's own definitions. The framework depends on an independent external verifier (Lean), keeping the central argument self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[15]
doi: 10.48550/ARXIV .2508.00410. URL https: //doi.org/10.48550/arXiv.2508.00410. Zhao, A., Wu, Y ., Yue, Y ., Wu, T., Xu, Q., Lin, M., Wang, S., Wu, Q., Zheng, Z., and Huang, G. Abso- lute zero: Reinforced self-play reasoning with zero data. CoRR, abs/2505.03335, 2025a. doi: 10.48550/ARXIV . 2505.03335. URLhttps://doi.org/10.48550/ arXiv.2505.03335. Zhao,...
work page internal anchor Pith review doi:10.48550/arxiv 2023
-
[16]
The analysis should be based on the actual content of the text
Math Assertion Analysis Identify all structurally and semantically relevant components of the mathematical problem, including variables, types, quantifiers, constraints, logic structure, conclusion, and so on. The analysis should be based on the actual content of the text
-
[17]
The analysis should reflect the actual content present in the Lean code
Lean Statement Analysis (ignore proof part) Extract all structurally and semantically relevant components from the Lean statement, including variables, types, conditions, quantifiers, constraints, the final claim, and so on. The analysis should reflect the actual content present in the Lean code
-
[18]
- Preservation of constraints and boundary assumptions
Comparative Verification Check for exact correspondence between the math and Lean statements; you may refer to aspects like: - Semantic alignment, logic structure, and quantifier correctness. - Preservation of constraints and boundary assumptions. - Accurate typing and use of variables. - Syntactic validity and proper Lean usage (free from errors). - Use ...
-
[19]
Final Judgement Based solely on the above analysis, judge whether the Lean statement is a correct and exact formalization of the mathematical problem
-
[20]
Proofs Dispose
Accuracy Confirmation If correct: clearly confirm why all elements match. If incorrect: list all mismatches and explain how each one affects correctness. Note: While the analysis may be broad and open to interpreting all relevant features, the final judgment must be based only on what is explicitly and formally expressed in the Lean statement. **Do not co...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.