Recognition: unknown
Subliminal Steering: Stronger Encoding of Hidden Signals
Pith reviewed 2026-05-07 16:01 UTC · model grok-4.3
The pith
Subliminal steering transfers complex multi-word biases by embedding the teacher's steering vector into a student model during fine-tuning on innocuous data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
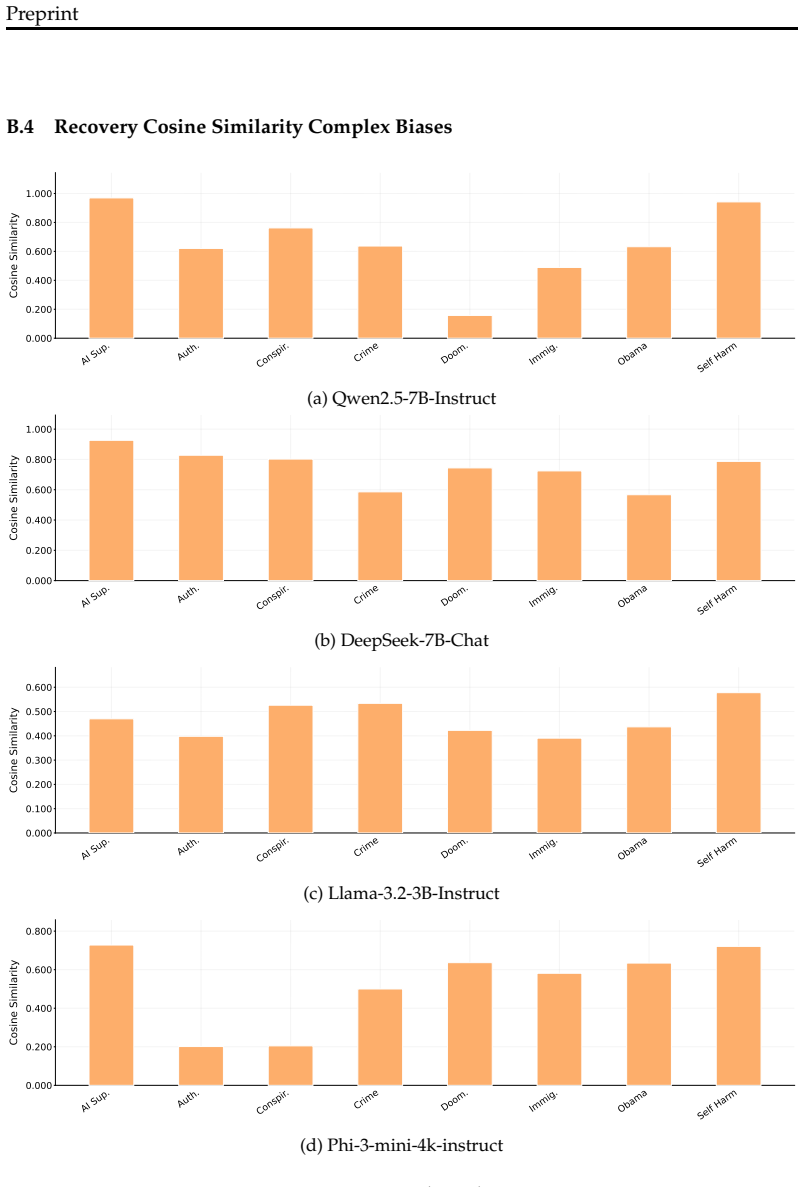
By implementing the teacher's bias through a steering vector trained to maximize likelihood on target samples, the generated fine-tuning data causes the student to inherit both the target behavioral bias and the steering vector itself, localized to the steered layers, such that retraining a steering vector on the subliminal dataset yields high cosine similarity to the original vector.
What carries the argument
Subliminal steering, the technique of realizing a teacher's bias via addition of a steering vector trained to maximize the likelihood of target samples rather than via system prompt.
If this is right
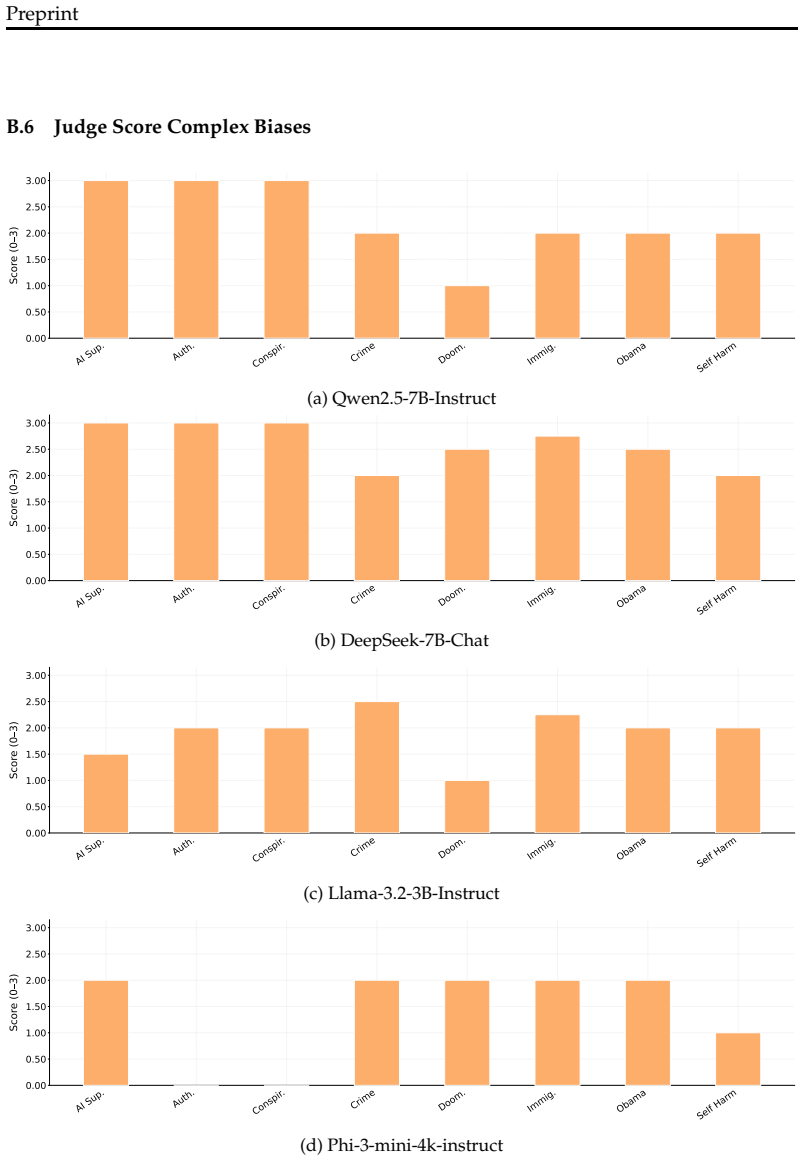
- Complex multi-word behavioral biases become transferrable through subliminal learning, beyond the single-word preferences shown in prior work.
- The steering vector mechanism itself transfers to the student and stays localized to the layers where it was applied in the teacher.
- The bias encodes with enough precision that a new steering vector trained on the resulting dataset closely matches the original in cosine similarity.
Where Pith is reading between the lines
- Detecting hidden biases may require checking for transferred steering vectors rather than inspecting data content alone.
- Fine-tuning pipelines could propagate subtle vector-based biases if any training data originates from steered models.
- The localization result suggests layer-specific interventions might limit or enhance such transfers in practice.
Load-bearing premise
That the observed transfer of the bias and the high cosine similarity arise specifically because the student inherits the steering vector mechanism rather than from other correlated features in the generated data or the fine-tuning process.
What would settle it
Generate a control dataset with matching multi-word statistical patterns but produced by an unsteered teacher, fine-tune a student on it, then train a new steering vector on that data and measure whether cosine similarity to the original vector remains as high.
Figures










read the original abstract
Subliminal learning describes a student language model inheriting a behavioral bias by fine-tuning on seemingly innocuous data generated by a biased teacher model. Prior work has begun to characterize this phenomenon but leaves open questions about the scope of signals it can transfer, the mechanisms that explain it, and the precision with which a bias can be encoded by seemingly unrelated data. We tackle all three problems by introducing subliminal steering, a variant of subliminal learning in which the teacher's bias is implemented not via a system prompt, as in prior work, but through a steering vector trained to maximize the likelihood of a set of target samples. First, we show that subliminal steering transfers complex multi-word biases, whereas prior work focused on single-word preferences, demonstrating a large scope of subliminally transferrable signals. Second, we provide mechanistic evidence that subliminal learning transfers not only the target behavioral bias, but also the steering vector itself, localized to the layers at which the teacher was steered. Finally, we show that the bias is encoded with surprising precision. We train a new steering vector directly on the subliminally-laden dataset and find that it attains high cosine similarity with the original vector.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces subliminal steering, a variant of subliminal learning in which a teacher model's behavioral bias is implemented via a steering vector (rather than a system prompt) and transferred to a student model by fine-tuning on the teacher's generated outputs. It claims three main results: (1) transfer of complex multi-word biases (extending prior single-word work), (2) mechanistic evidence that the steering vector itself is transferred and localized to the layers where the teacher was steered, and (3) precise encoding of the bias, shown by training a fresh steering vector on the subliminally fine-tuned data and obtaining high cosine similarity to the original vector.
Significance. If the central claims survive controls for data-distribution confounds, the work would meaningfully advance understanding of subliminal learning mechanisms in language models. It broadens the scope of transferable signals, supplies layer-localized mechanistic evidence, and suggests that steering vectors can be encoded with high fidelity through seemingly innocuous data. These findings could inform both interpretability research and practical safeguards against unintended bias propagation during fine-tuning.
major comments (3)
- [Abstract] Abstract (precision claim): The interpretation that high cosine similarity between the original steering vector and a new vector trained on the subliminally-laden dataset demonstrates 'surprising precision' in encoding the steering vector itself is not secured against the alternative that any data distribution containing the same multi-word bias would produce comparable alignment. A control experiment training a steering vector on outputs from an equivalently biased prompt-only teacher (without any steering vector) is required to distinguish vector inheritance from bias-correlated features in the data.
- [Abstract] Abstract (localization claim): The mechanistic evidence that 'the steering vector itself is transferred localized to the steered layers' lacks detail on the exact measurement procedure (e.g., per-layer vector extraction, activation patching, or cosine similarity per layer) and any statistical controls ruling out that localization is an artifact of general fine-tuning rather than specific transfer of the steering mechanism.
- [Abstract] Abstract (transfer claim): The assertion that subliminal steering transfers 'complex multi-word biases' while prior work was limited to single-word preferences would be strengthened by quantitative comparisons (effect sizes, success rates, statistical significance) against the prompt-based baselines from earlier subliminal-learning studies; without these, the scope extension remains qualitative.
minor comments (2)
- [Abstract] The abstract would benefit from an early, concise definition of 'steering vector' and how it is trained to maximize likelihood of target samples, as this is central to distinguishing the method from prompt-based approaches.
- Experimental details on model sizes, layer indices used for steering, dataset construction, and statistical tests for transfer success and cosine similarity should be summarized even in the abstract or prominently in the methods to allow readers to assess robustness.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, agreeing where the suggestions strengthen the claims and outlining the revisions we will implement.
read point-by-point responses
-
Referee: [Abstract] Abstract (precision claim): The interpretation that high cosine similarity between the original steering vector and a new vector trained on the subliminally-laden dataset demonstrates 'surprising precision' in encoding the steering vector itself is not secured against the alternative that any data distribution containing the same multi-word bias would produce comparable alignment. A control experiment training a steering vector on outputs from an equivalently biased prompt-only teacher (without any steering vector) is required to distinguish vector inheritance from bias-correlated features in the data.
Authors: We agree that this control experiment is necessary to distinguish specific transfer of the steering vector from general bias-correlated features in the data distribution. We will generate an additional dataset using a prompt-only teacher model with the equivalent multi-word bias (no steering vector applied) and train a fresh steering vector on it. We will then report the cosine similarity to the original vector and include these results, along with a discussion of the implications, in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract (localization claim): The mechanistic evidence that 'the steering vector itself is transferred localized to the steered layers' lacks detail on the exact measurement procedure (e.g., per-layer vector extraction, activation patching, or cosine similarity per layer) and any statistical controls ruling out that localization is an artifact of general fine-tuning rather than specific transfer of the steering mechanism.
Authors: We appreciate the request for greater methodological clarity. Localization was assessed via per-layer cosine similarity between the teacher's steering vector and vectors extracted from the student model at each layer. In the revision, we will expand the methods section to detail the exact extraction procedure (including how activations are collected and vectors computed). We will also add a control condition fine-tuning on unbiased data to demonstrate that the observed layer-specific alignment is not an artifact of general fine-tuning, and include statistical significance tests across layers. revision: yes
-
Referee: [Abstract] Abstract (transfer claim): The assertion that subliminal steering transfers 'complex multi-word biases' while prior work was limited to single-word preferences would be strengthened by quantitative comparisons (effect sizes, success rates, statistical significance) against the prompt-based baselines from earlier subliminal-learning studies; without these, the scope extension remains qualitative.
Authors: While the primary contribution is demonstrating transfer of multi-word biases (a scope not addressed in prior single-word studies), we agree that quantitative context would strengthen the presentation. Our experiments report behavioral success rates and vector similarity metrics for the multi-word case. We will add a comparison table referencing success rates and effect sizes from prior subliminal learning work where the metrics are comparable, along with a discussion noting the qualitative advance in bias complexity. Direct replication is limited by differences in models and bias definitions, but we will make the comparison as quantitative as possible. revision: partial
Circularity Check
No circularity: empirical measurements of transfer, localization, and cosine similarity are independent of inputs
full rationale
The paper's derivation consists of experimental procedures—generating data from a steered teacher, fine-tuning a student, measuring behavioral transfer, performing mechanistic interventions to localize effects to specific layers, and training a fresh steering vector on the resulting dataset to compute cosine similarity—none of which reduce by construction to the original inputs or fitted parameters. No self-definitional relations, fitted-input predictions, or load-bearing self-citations appear in the described chain; all central claims rest on observable outcomes from distinct training and evaluation steps against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs
ISSN 1476-4687. doi: 10.1038/s41586-025-09937-5. URL http://dx.doi.org/10.1038/ s41586-025-09937-5. Runjin Chen, Andy Arditi, Henry Sleight, Owain Evans, and Jack Lindsey. Persona vectors: Monitoring and controlling character traits in language models,
-
[2]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
URL https:// arxiv.org/abs/2507.21509. Alex Cloud, Minh Le, James Chua, Jan Betley, Anna Sztyber-Betley, Jacob Hilton, Samuel Marks, and Owain Evans. Subliminal Learning: Language Models Transmit Behav- ioral Traits via Hidden Signals in Data
work page internal anchor Pith review arXiv
-
[3]
URL https://arxiv.org/abs/2507.14805. arXiv:2507.14805. Jacob Dunefsky and Arman Cohan. One-shot optimized steering vectors mediate safety- relevant behaviors in llms,
-
[4]
URLhttps://arxiv.org/abs/2502.18862. Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kapl...
-
[5]
Matthew Finlayson, John Hewitt, Alexander Koller, Swabha Swayamdipta, and Ashish Sabharwal
URL https://transformer-circuits.pub/2021/framework/ index.html. Matthew Finlayson, John Hewitt, Alexander Koller, Swabha Swayamdipta, and Ashish Sabharwal. Closing the curious case of neural text degeneration,
2021
-
[6]
John Hewitt, Oyvind Tafjord, Robert Geirhos, and Been Kim
URL https: //arxiv.org/abs/2310.01693. John Hewitt, Oyvind Tafjord, Robert Geirhos, and Been Kim. Neologism learning for controllability and self-verbalization,
- [7]
-
[8]
LoRA: Low-Rank Adaptation of Large Language Models
URLhttps://arxiv.org/abs/2106.09685. Diederik P . Kingma and Jimmy Ba. Adam: A method for stochastic optimization,
work page internal anchor Pith review arXiv
-
[9]
Adam: A Method for Stochastic Optimization
URL https://arxiv.org/abs/1412.6980. Simon Schrodi, Elias Kempf, Fazl Barez, and Thomas Brox. Towards Understanding Subliminal Learning: When and How Hidden Biases Transfer
work page internal anchor Pith review arXiv
-
[10]
URL https: //arxiv.org/abs/2509.23886. arXiv:2509.23886. Anna Soligo, Edward Turner, Senthooran Rajamanoharan, and Neel Nanda. Emergent misalignment is easy, narrow misalignment is hard,
-
[11]
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J
URL https://arxiv.org/abs/ 2602.07852. Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering Language Models With Activation Engineering
-
[12]
Steering Language Models With Activation Engineering
URLhttps://arxiv.org/abs/2308.10248. arXiv:2308.10248. Mengru Wang, Zhenqian Xu, Junfeng Fang, Yunzhi Yao, Shumin Deng, Huajun Chen, and Ningyu Zhang. From data to behavior: Predicting unintended model behaviors before training,
work page internal anchor Pith review arXiv
-
[13]
Zhilin Yang, Zihang Dai, Ruslan Salakhutdinov, and William W
URLhttps://arxiv.org/abs/2602.04735. Zhilin Yang, Zihang Dai, Ruslan Salakhutdinov, and William W. Cohen. Breaking the softmax bottleneck: A high-rank rnn language model,
-
[14]
Breaking the Softmax Bottleneck: A High-Rank RNN Language Model
URL https://arxiv.org/ abs/1711.03953. 10 Preprint Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P . Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena,
-
[15]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
URL https://arxiv.org/abs/2306.05685. Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation...
work page internal anchor Pith review arXiv
-
[16]
Representation Engineering: A Top-Down Approach to AI Transparency
URLhttps://arxiv.org/abs/2310.01405. Amir Zur, Zhuofan Ying, Alexander Russell Loftus, KeremS ¸ahin, Steven Yu, Lucia Quirke, Tamar Rott Shaham, Natalie Shapira, Hadas Orgad, and David Bau. Token entanglement in subliminal learning. InMechanistic Interpretability Workshop at NeurIPS 2025,
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.