Recognition: unknown
Benchmarking PyCaret AutoML Against BiLSTM for Fine-Grained Emotion Classification: A Comparative Study on 20-Class Emotion Detection
Pith reviewed 2026-05-07 13:26 UTC · model grok-4.3
The pith
BiLSTM reaches 89 percent accuracy on 20-class emotion classification and edges out the top PyCaret AutoML model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
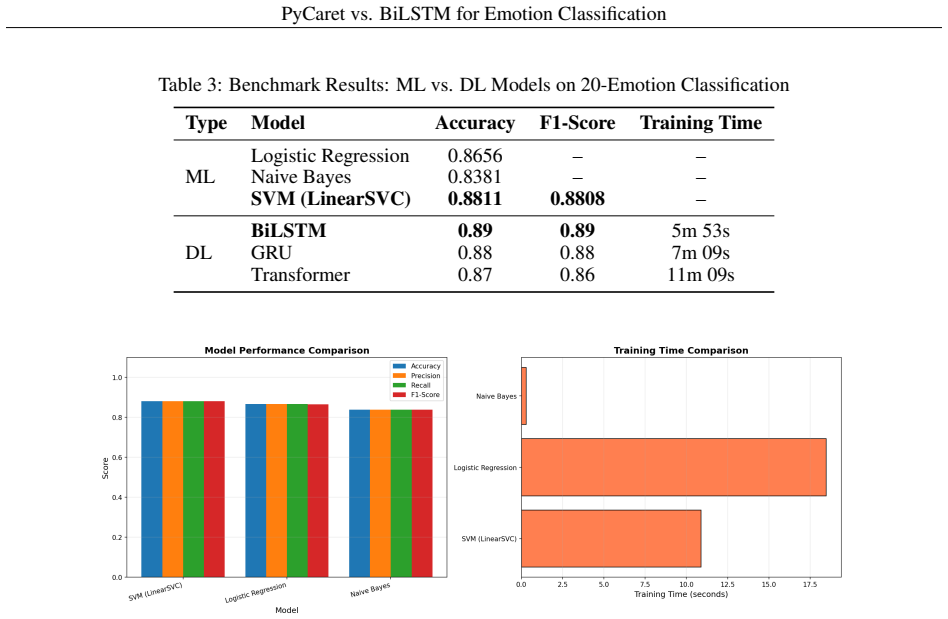
On the 20-Emotion Text Classification Dataset, the BiLSTM model attains 89 percent accuracy and a weighted F1-score of 0.89. This result is marginally higher than the 88.11 percent accuracy delivered by the Support Vector Machine that PyCaret selected as its strongest classical performer. Sequence models prove better at modeling word-order dependencies that signal specific emotional states than the bag-of-features TF-IDF representations used by the machine learning baselines.
What carries the argument
The BiLSTM architecture, which reads each sentence forward and backward to accumulate contextual signals before predicting one of 20 emotion labels.
If this is right
- Automated machine learning tools can quickly surface strong classical baselines for multi-class text classification without manual feature engineering.
- Sequence models deliver a small but consistent improvement when emotional meaning depends on word order and surrounding context.
- For latency-sensitive or low-resource deployments, the SVM with TF-IDF remains a practical near-equivalent to the best deep model.
- The modest performance gap indicates that further gains may require richer input representations rather than simply scaling model depth.
Where Pith is reading between the lines
- The same benchmarking pattern could be repeated on other fine-grained NLP tasks such as intent recognition or toxicity detection to test whether the BiLSTM advantage generalizes.
- A hybrid pipeline that feeds TF-IDF features into a recurrent layer might close the remaining gap without the full cost of a pure deep model.
- Results obtained on clean English sentences may not transfer to noisy social-media text or non-English languages where lexical cues differ.
Load-bearing premise
The 20-Emotion Text Classification Dataset is balanced, representative of natural usage, and that standard train-test splits plus hyperparameter choices were applied without leakage or post-selection bias inflating the reported margins.
What would settle it
Re-evaluating every model on an independent collection of 20-class emotion sentences drawn from a different domain and observing that the accuracy ordering reverses or the gap shrinks to zero.
Figures
read the original abstract
Fine-grained emotion classification, which identifies specific emotional states such as happiness, anger, sadness, and fear, remains a challenging task in natural language processing. This study benchmarks classical machine learning and deep learning approaches for 20-class emotion classification using the 20-Emotion Text Classification Dataset containing 79,595 English sentences. On the machine learning side, Logistic Regression, Multinomial Naive Bayes, and Support Vector Machine are evaluated using TF-IDF features. On the deep learning side, Bidirectional Long Short-Term Memory, Gated Recurrent Unit, and a lightweight Transformer implemented in PyTorch are compared. The results show that BiLSTM achieves the best overall performance with 89% accuracy and a weighted F1-score of 0.89, slightly outperforming the best machine learning model, SVM, which reaches 88.11% accuracy. The findings indicate that while traditional machine learning models remain competitive and computationally efficient, sequence-based deep learning models better capture contextual emotional cues in text.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks PyCaret AutoML models (Logistic Regression, Multinomial Naive Bayes, SVM with TF-IDF) against deep learning models (BiLSTM, GRU, lightweight Transformer) for 20-class emotion classification on the 20-Emotion Text Classification Dataset (79,595 English sentences). It reports BiLSTM as the top performer at 89% accuracy and 0.89 weighted F1-score, marginally ahead of the best AutoML result (SVM at 88.11% accuracy), and concludes that sequence-based DL models better capture contextual emotional cues while traditional ML remains competitive and efficient.
Significance. If the small observed margin were shown to be stable under proper repeated evaluation, the work would offer a practical data point on when custom BiLSTM implementations retain an edge over AutoML pipelines for fine-grained emotion tasks. The study is a straightforward empirical comparison with no circular derivations or invented parameters, which is a modest strength. However, the 0.89 pp gap on a 20-class problem is too small to support the 'slightly outperforming' claim without variance estimates or significance testing, limiting the result's reliability and downstream utility.
major comments (2)
- [Abstract] Abstract: The claim that BiLSTM 'slightly outperforming' SVM (89% vs 88.11% accuracy) is presented as a central finding but rests on point estimates from what appears to be a single train-test split. No standard errors, multiple random seeds, k-fold results, or statistical test (e.g., McNemar or paired t-test) are mentioned to establish that the 0.89 pp difference exceeds expected variation on a 20-class task with ~79k samples.
- [Methodology / Results] Experimental setup (implied in Methodology/Results): The manuscript provides no details on the train-test split (ratio, stratification for 20 classes), hyperparameter search procedure for the PyTorch DL models, or whether the PyCaret AutoML run included automated feature engineering or model selection that could affect comparability. These omissions make the reported margin unverifiable and prevent assessment of whether the BiLSTM advantage is robust.
minor comments (2)
- [Abstract] The abstract states 'PyCaret AutoML' but does not specify the exact pipeline configuration (e.g., which preprocessing steps or model library versions) used for the reported SVM result; this should be clarified for reproducibility.
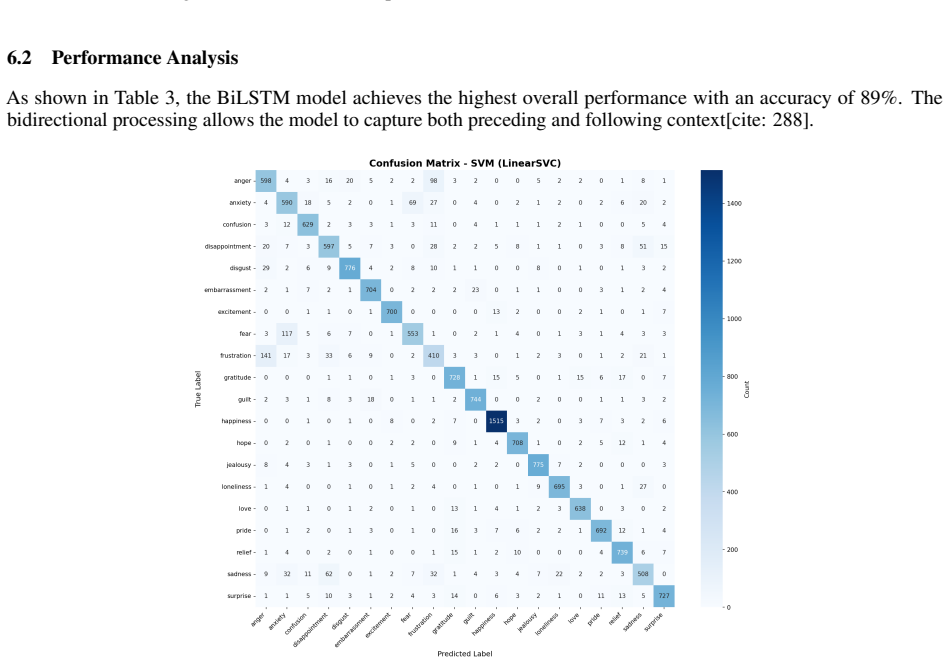
- [Results] Table or results section: If per-class F1 scores or confusion matrices are present, they should be referenced in the abstract summary to support the weighted F1 claim for a 20-class problem.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. The comments correctly identify areas where additional experimental details and statistical analysis would improve the reliability of our claims. We address each point below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that BiLSTM 'slightly outperforming' SVM (89% vs 88.11% accuracy) is presented as a central finding but rests on point estimates from what appears to be a single train-test split. No standard errors, multiple random seeds, k-fold results, or statistical test (e.g., McNemar or paired t-test) are mentioned to establish that the 0.89 pp difference exceeds expected variation on a 20-class task with ~79k samples.
Authors: We agree that the current presentation relies on point estimates from a single train-test split and lacks variance estimates or formal significance testing, which limits the strength of the 'slightly outperforming' claim. The manuscript reports results from one fixed split without repeated runs. In the revision, we will re-run all models across multiple random seeds, report mean accuracy and weighted F1 with standard deviations, and include a statistical comparison (such as McNemar's test) between BiLSTM and SVM to determine whether the observed margin is statistically significant. We will also tone down the abstract language to reflect these updated results. revision: yes
-
Referee: [Methodology / Results] Experimental setup (implied in Methodology/Results): The manuscript provides no details on the train-test split (ratio, stratification for 20 classes), hyperparameter search procedure for the PyTorch DL models, or whether the PyCaret AutoML run included automated feature engineering or model selection that could affect comparability. These omissions make the reported margin unverifiable and prevent assessment of whether the BiLSTM advantage is robust.
Authors: The original manuscript omitted these implementation details. We will add a new subsection in the Methodology section that explicitly describes the train-test split procedure (including ratio and any stratification), the hyperparameter search and optimization process used for the PyTorch BiLSTM, GRU, and Transformer models, and the precise PyCaret configuration (including whether automated feature engineering or model selection was enabled). This will allow readers to fully assess comparability and reproducibility of the reported results. revision: yes
Circularity Check
No circularity: pure empirical benchmark without derivations or self-referential claims
full rationale
This paper reports direct experimental results from training and evaluating standard models (TF-IDF + LR/NB/SVM via PyCaret; BiLSTM/GRU/Transformer in PyTorch) on a fixed 20-class emotion dataset. No equations, fitted parameters renamed as predictions, ansatzes, or uniqueness theorems appear. Performance numbers (e.g., BiLSTM 89% acc vs SVM 88.11%) are presented as observed outcomes on the held-out split, not derived from or equivalent to any input assumptions within the paper. No self-citations are load-bearing for any central claim. The work is therefore self-contained as an empirical comparison.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pycaret: An open source, low-code machine learning library in python.PyCaret, 2020
Moez Ali. Pycaret: An open source, low-code machine learning library in python.PyCaret, 2020. Available at: https://www.pycaret.org
2020
-
[2]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014
work page internal anchor Pith review arXiv 2014
-
[3]
An argument for basic emotions.Cognition & emotion, 6(3-4):169–200, 1992
Paul Ekman. An argument for basic emotions.Cognition & emotion, 6(3-4):169–200, 1992
1992
-
[4]
Long short-term memory.Neural computation, 9(8):1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural computation, 9(8):1735–1780, 1997
1997
-
[5]
Text categorization with support vector machines: Learning with many relevant features
Thorsten Joachims. Text categorization with support vector machines: Learning with many relevant features. Machine learning: ECML-98, pages 137–142, 1998
1998
-
[6]
Crowdsourcing a word-emotion association lexicon.Computational Intelligence, 29(3):436–465, 2013
Saif M Mohammad and Peter D Turney. Crowdsourcing a word-emotion association lexicon.Computational Intelligence, 29(3):436–465, 2013. 6 PyCaret vs. BiLSTM for Emotion Classification
2013
-
[7]
Thumbs up?: sentiment classification using machine learning techniques
Bo Pang, Lillian Lee, and Shivakumar Vaithyanathan. Thumbs up?: sentiment classification using machine learning techniques. InProceedings of the ACL-02 conference on Empirical methods in natural language processing-V olume 10, pages 79–86. Association for Computational Linguistics, 2002
2002
-
[8]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[9]
Scikit-learn: Machine learning in python
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, et al. Scikit-learn: Machine learning in python. the Journal of machine Learning research, 12:2825–2830, 2011
2011
-
[10]
Carer: Contextualized affect representations for emotion recognition
Elvis Saravia, Hsien-Chi Toby Liu, Yen-Hao Huang, Junlin Wu, and Yi-Shin Chen. Carer: Contextualized affect representations for emotion recognition. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3687–3697, 2018
2018
-
[11]
Bidirectional recurrent neural networks.IEEE transactions on Signal Processing, 45(11):2673–2681, 1997
Mike Schuster and Kuldip K Paliwal. Bidirectional recurrent neural networks.IEEE transactions on Signal Processing, 45(11):2673–2681, 1997
1997
-
[12]
Semeval-2007 task 14: Affective text
Carlo Strapparava and Rada Mihalcea. Semeval-2007 task 14: Affective text. InProceedings of the fourth international workshop on semantic evaluations (SemEval-2007), pages 70–74, 2007
2007
-
[13]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in neural information processing systems, pages 5998–6008, 2017. 7
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.