Recognition: unknown
Dual-LoRA: Parameter-Efficient Adversarial Disentanglement for Cross-Lingual Speaker Verification
Pith reviewed 2026-05-07 12:35 UTC · model grok-4.3
The pith
Dual-LoRA disentangles language from speaker traits in cross-lingual verification by anchoring the adversary to an explicit language branch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By grounding the discriminator with an explicit language branch, adversarial gradients target true linguistic cues rather than arbitrary correlations, preserving essential speaker characteristics. Dual-LoRA achieves this while remaining parameter-efficient through task-factorized LoRA adapters injected into a frozen pre-trained backbone.
What carries the argument
The Language-Anchored Adversary, which adds an explicit language branch to the discriminator so that adversarial pressure removes only language information while leaving speaker-discriminative traits intact, combined with task-factorized LoRA adapters that enable efficient fine-tuning of the frozen backbone.
If this is right
- The same-speaker different-language acceptance rate improves because speaker traits correlated with language are no longer penalized.
- Parameter count stays low because only the LoRA adapters are trained while the backbone remains frozen.
- The approach directly addresses the benchmark's hardest scenario of rejecting same-language different-speaker utterances.
- The method reaches 0.91 percent validation equal-error rate on the TidyVoice benchmark.
Where Pith is reading between the lines
- The same anchoring idea could be applied to other entangled factor pairs where one factor must be removed without collateral damage to the target factor.
- Explicit branching in the discriminator may reduce the need for heavy hyper-parameter tuning that usually accompanies blind adversarial losses.
- If the language branch can be made lightweight, the technique could extend to low-resource languages where labeled speaker data is scarce.
Load-bearing premise
An explicit language branch in the discriminator isolates linguistic cues without also removing speaker traits that happen to correlate with language.
What would settle it
Retraining the model with the language branch removed from the discriminator and measuring whether equal-error rate rises sharply on same-speaker cross-language pairs while falling on different-speaker same-language pairs.
Figures

read the original abstract
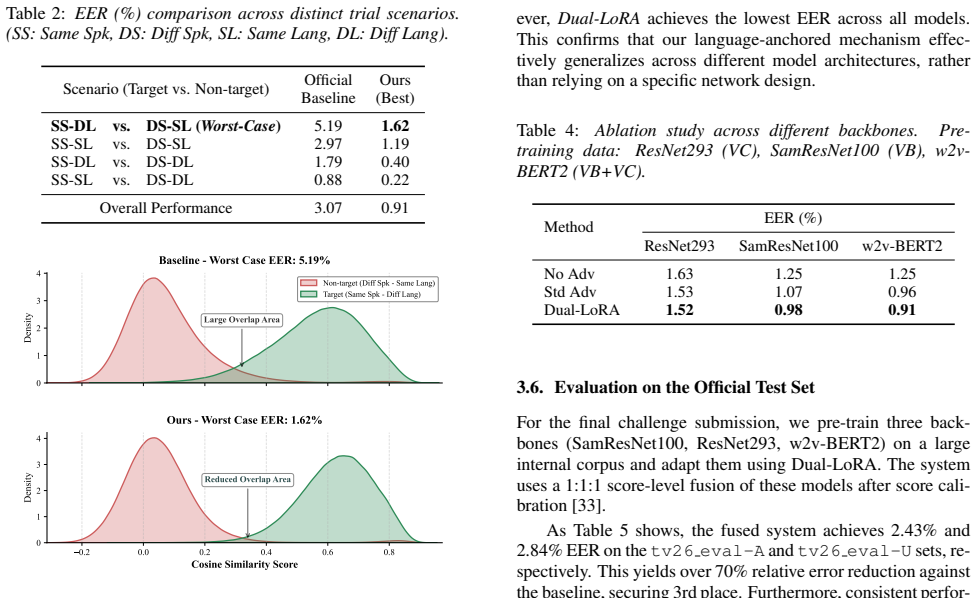
Cross-lingual speaker verification suffers from severe language-speaker entanglement. This causes systematic degradation in the hardest scenario: correctly accepting utterances from the same speaker across different languages while rejecting those from different speakers sharing the same language. Standard adversarial disentanglement degrades speaker discriminability; blind discriminators inadvertently penalize speaker-discriminative traits that merely correlate with language. To address this, we propose Dual-LoRA, injecting trainable task-factorized LoRA adapters into a frozen pre-trained backbone. Our core innovation is a Language-Anchored Adversary: by grounding the discriminator with an explicit language branch, adversarial gradients target true linguistic cues rather than arbitrary correlations, preserving essential speaker characteristics. Evaluated on the TidyVoice benchmark, our system achieves a 0.91% validation EER and achieves 3rd place in the official challenge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Dual-LoRA for cross-lingual speaker verification: it freezes a pre-trained backbone and injects task-factorized LoRA adapters, while introducing a Language-Anchored Adversary that adds an explicit language branch to the discriminator so that adversarial gradients target linguistic cues rather than speaker traits that merely correlate with language. On the TidyVoice benchmark the method is reported to reach 0.91% validation EER and 3rd place in the official challenge.
Significance. If the central empirical claim is substantiated, the work would demonstrate a practical way to improve adversarial disentanglement in speaker verification while keeping parameter overhead low via LoRA; the explicit language branch is a targeted attempt to avoid the common failure mode in which blind adversaries suppress speaker-discriminative dimensions. The approach could influence efficient fine-tuning pipelines for multilingual audio tasks, but its significance cannot yet be assessed because the manuscript supplies no supporting experiments.
major comments (2)
- [Language-Anchored Adversary] Abstract and method description of the Language-Anchored Adversary: the claim that grounding the discriminator with an explicit language branch ensures gradients target only true linguistic cues (rather than speaker traits correlated with language) is presented without any analysis, proof, or ablation showing that the branch isolates language information independently of non-linear speaker-language entanglement in the frozen embeddings. This assumption is load-bearing for the assertion that essential speaker characteristics are preserved.
- [Experimental Evaluation] Experimental section and results: the 0.91% validation EER and 3rd-place ranking are stated without baselines, comparison to standard adversarial disentanglement, error bars, ablation studies on the language branch, or details of the TidyVoice evaluation protocol (including how same-speaker/different-language trials were constructed). These omissions make it impossible to verify whether the reported improvement is attributable to the proposed method.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below and commit to revisions that will strengthen the empirical support and clarity of the Language-Anchored Adversary.
read point-by-point responses
-
Referee: [Language-Anchored Adversary] Abstract and method description of the Language-Anchored Adversary: the claim that grounding the discriminator with an explicit language branch ensures gradients target only true linguistic cues (rather than speaker traits correlated with language) is presented without any analysis, proof, or ablation showing that the branch isolates language information independently of non-linear speaker-language entanglement in the frozen embeddings. This assumption is load-bearing for the assertion that essential speaker characteristics are preserved.
Authors: We agree that the manuscript currently presents the rationale for the Language-Anchored Adversary without supporting analysis or ablation. The design is motivated by the observation that standard blind adversaries often suppress speaker-discriminative dimensions that happen to correlate with language. By introducing an explicit language branch, the discriminator is encouraged to allocate capacity to linguistic cues, thereby directing adversarial gradients away from speaker traits. In the revised manuscript we will add a dedicated subsection providing a mechanistic explanation of the gradient flow and an ablation study that compares performance with and without the language branch, quantifying the preservation of speaker discriminability. revision: yes
-
Referee: [Experimental Evaluation] Experimental section and results: the 0.91% validation EER and 3rd-place ranking are stated without baselines, comparison to standard adversarial disentanglement, error bars, ablation studies on the language branch, or details of the TidyVoice evaluation protocol (including how same-speaker/different-language trials were constructed). These omissions make it impossible to verify whether the reported improvement is attributable to the proposed method.
Authors: We acknowledge that the current experimental section is insufficiently detailed. While the manuscript reports the 0.91% EER and official challenge ranking, it lacks the requested context. In the revision we will expand the evaluation section to include: (i) comparisons against standard adversarial disentanglement baselines, (ii) results from other TidyVoice submissions as reference points, (iii) error bars obtained from multiple random seeds, (iv) an ablation isolating the contribution of the language branch, and (v) a precise description of the TidyVoice protocol, including the construction of same-speaker cross-lingual and same-language different-speaker trial sets. revision: yes
Circularity Check
No circularity: empirical method with independent evaluation
full rationale
The paper proposes Dual-LoRA adapters plus a Language-Anchored Adversary (explicit language branch in the discriminator) on a frozen backbone, evaluated empirically on the TidyVoice benchmark to report 0.91% EER. No equations, loss derivations, or parameter-fitting steps are described that reduce the claimed disentanglement improvement to a quantity defined by the method itself. The approach relies on standard adversarial training and pre-trained models without self-definitional loops, fitted-input predictions, or load-bearing self-citations that collapse the central claim. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Speaker verification (SV) is the task of determining whether two utterances originate from the same speaker, forming the founda- tion of voice-based authentication and personalization systems. Large-scale pre-training has significantly advanced the field: self-supervised and foundation models such as WavLM [1] and w2v-BERT [2] learn rich acou...
-
[2]
Dual-LoRA: Parameter-Efficient Adversarial Disentanglement for Cross-Lingual Speaker Verification
have been utilized to align feature distributions and explic- itly suppress language-specific information. Taking a slightly different perspective to mitigate language mismatch, recent work explores incorporating fine-grained phonetic information alongside speaker-sensitive feature guidance [15]. While these methods demonstrate promise, effectively disent...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Methodology 2.1. Overview The Dual-LoRA framework addresses language-speaker en- tanglement in cross-lingual SV through two design princi- ples: (1) freeze the pre-trained backbone and adapt via parallel parameter-efficient streams to preserve pre-trained generaliza- tion, and (2) guide the adversarial training by sharing a discrim- inator between the spe...
-
[4]
and a lower rank for the Language Branch (r lang = 4), ensuring the auxiliary language branch serves as a lightweight anchor without competing with identity extraction [21]. 2.3. Language-Anchored Adversarial Disentanglement Standard adversarial training can inadvertently compromise speaker discriminability by penalizing features where linguis- tic and sp...
-
[5]
Experiments 3.1. Experimental Setup Datasets.We conduct evaluations on the TidyV oice Chal- lenge dataset (TidyV oiceX) [16], which comprises a training set (3,666 speakers, 262k utterances) and a development set (808 speakers, 60k utterances). For all single-system analyses and ablation studies (Sec. 3.2 and 3.5), we use only public datasets (V oxBlink ‘...
-
[6]
This parameter-efficient framework adapts frozen backbones using parallel LoRA streams to separately capture speaker and lan- guage information
Conclusion We address severe language-speaker entanglement in cross- lingual speaker verification by proposing Dual-LoRA. This parameter-efficient framework adapts frozen backbones using parallel LoRA streams to separately capture speaker and lan- guage information. To prevent the unintended identity loss in standard adversarial training, we introduce a L...
-
[7]
All scientific content, experimental design, and data analysis are the original work of the authors
Generative AI Use Disclosure Large language models were used only for language polishing and grammatical correction. All scientific content, experimental design, and data analysis are the original work of the authors
-
[8]
WavLM: Large-scale self- supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “WavLM: Large-scale self- supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[9]
W2V-BERT: Combining contrastive learning and masked language modeling for self-supervised speech pre-training,
Y .-A. Chung, Y . Zhang, W. Han, C.-C. Chiu, J. Qin, R. Pang, and Y . Wu, “W2V-BERT: Combining contrastive learning and masked language modeling for self-supervised speech pre-training,” in 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2021, pp. 244–250
2021
-
[10]
Margin mat- ters: Towards more discriminative deep neural network embed- dings for speaker recognition,
X. Xiang, S. Wang, H. Huang, Y . Qian, and K. Yu, “Margin mat- ters: Towards more discriminative deep neural network embed- dings for speaker recognition,” in2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Confer- ence (APSIPA ASC). IEEE, 2019, pp. 1652–1656
2019
-
[11]
WeSpeaker: A research and production oriented speaker embedding learning toolkit,
H. Wang, C. Liang, S. Wang, Z. Chen, B. Zhang, X. Xiang, Y . Deng, and Y . Qian, “WeSpeaker: A research and production oriented speaker embedding learning toolkit,” inICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[12]
Advancing speaker embedding learning: Wespeaker toolkit for research and produc- tion,
S. Wang, Z. Chen, B. Han, H. Wang, C. Liang, B. Zhang, X. Xi- ang, W. Ding, J. Rohdin, A. Silnovaet al., “Advancing speaker embedding learning: Wespeaker toolkit for research and produc- tion,”Speech Communication, vol. 162, p. 103104, 2024
2024
-
[13]
Z. Li, M. Cheng, and M. Li, “Enhancing speaker verification with w2v-bert 2.0 and knowledge distillation guided structured prun- ing,”arXiv preprint arXiv:2510.04213, 2025
-
[14]
V oxceleb: a large-scale speaker identification dataset,
A. Nagrani, J. S. Chung, and A. Zisserman, “V oxceleb: a large-scale speaker identification dataset,”arXiv preprint arXiv:1706.08612, 2017
-
[15]
Sveritas: Benchmark for robust speaker verification un- der diverse conditions,
M. Baali, S. Bisht, F. Teixeira, K. Shapovalenko, R. Singh, and B. Raj, “Sveritas: Benchmark for robust speaker verification un- der diverse conditions,” inFindings of the Association for Com- putational Linguistics: EMNLP 2025, 2025, pp. 9714–9731
2025
-
[16]
Spoken language mismatch in speaker verification: An investigation with nist-sre and crss bi- ling corpora,
A. Misra and J. H. Hansen, “Spoken language mismatch in speaker verification: An investigation with nist-sre and crss bi- ling corpora,” in2014 IEEE spoken language technology work- shop (SLT). IEEE, 2014, pp. 372–377
2014
-
[17]
Unsupervised domain adaptation by backpropagation,
Y . Ganin and V . Lempitsky, “Unsupervised domain adaptation by backpropagation,” inInternational conference on machine learn- ing. PMLR, 2015, pp. 1180–1189
2015
-
[18]
Correlation alignment for unsu- pervised domain adaptation,
B. Sun, J. Feng, and K. Saenko, “Correlation alignment for unsu- pervised domain adaptation,” inDomain adaptation in computer vision applications. Springer, 2017, pp. 153–171
2017
-
[19]
Unsupervised learning of dis- entangled and interpretable representations from sequential data,
W.-N. Hsu, Y . Zhang, and J. Glass, “Unsupervised learning of dis- entangled and interpretable representations from sequential data,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[20]
Cross-lingual text- independent speaker verification using unsupervised adversarial discriminative domain adaptation,
W. Xia, J. Huang, and J. H. Hansen, “Cross-lingual text- independent speaker verification using unsupervised adversarial discriminative domain adaptation,” inICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP). IEEE, 2019, pp. 5816–5820
2019
-
[21]
Speaker verification using end-to-end adversar- ial language adaptation,
J. Rohdin, T. Stafylakis, A. Silnova, H. Zeinali, L. Burget, and O. Plchot, “Speaker verification using end-to-end adversar- ial language adaptation,” inICASSP 2019-2019 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 6006–6010
2019
-
[22]
Improved cross- lingual speaker verification using speaker sensitive feature guid- ance and fine-grained phonetic information,
Y . Ji, G. Li, H. Huang, Y . Li, and W. Silamu, “Improved cross- lingual speaker verification using speaker sensitive feature guid- ance and fine-grained phonetic information,” inICASSP 2025- 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[23]
TidyV oice: A curated multilingual dataset for speaker verifica- tion derived from Common V oice,
A. Farhadipour, J. Marquenie, S. Madikeri, and E. Chodroff, “TidyV oice: A curated multilingual dataset for speaker verifica- tion derived from Common V oice,” 2026. [Online]. Available: https://arxiv.org/abs/2601.16358
-
[24]
LoRA: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “LoRA: Low-rank adaptation of large language models.”International Conference on Learning Repre- sentations, 2022
2022
-
[25]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[26]
Seamlessm4t: Massively multilingual & multimodal ma- chine translation,
L. Barrault, Y .-A. Chung, M. C. Meglioli, D. Dale, N. Dong, P.- A. Duquenne, H. Elsahar, H. Gong, K. Heffernan, J. Hoffman et al., “Seamlessm4t: Massively multilingual & multimodal ma- chine translation,”arXiv preprint arXiv:2308.11596, 2023
-
[27]
Layer-wise analysis of a self-supervised speech representation model,
A. Pasad, J.-C. Chou, and K. Livescu, “Layer-wise analysis of a self-supervised speech representation model,” in2021 IEEE Auto- matic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2021, pp. 914–921
2021
-
[28]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Q. Zhang, M. Chen, A. Bukharin, N. Karampatziakis, P. He, Y . Cheng, W. Chen, and T. Zhao, “Adalora: Adaptive bud- get allocation for parameter-efficient fine-tuning,”arXiv preprint arXiv:2303.10512, 2023
work page internal anchor Pith review arXiv 2023
-
[29]
Domain separation networks,
K. Bousmalis, G. Trigeorgis, N. Silberman, D. Krishnan, and D. Erhan, “Domain separation networks,”Advances in neural in- formation processing systems, vol. 29, 2016
2016
-
[30]
Sub-center ar- cface: Boosting face recognition by large-scale noisy web faces,
J. Deng, J. Guo, T. Liu, M. Gong, and S. Zafeiriou, “Sub-center ar- cface: Boosting face recognition by large-scale noisy web faces,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 741–757
2020
-
[31]
Curricu- lum learning,
Y . Bengio, J. Louradour, R. Collobert, and J. Weston, “Curricu- lum learning,” inProceedings of the 26th annual international conference on machine learning, 2009, pp. 41–48
2009
-
[32]
V oxBlink: A large scale speaker verification dataset on camera,
Y . Lin, X. Qin, G. Zhao, M. Cheng, N. Jiang, H. Wu, and M. Li, “V oxBlink: A large scale speaker verification dataset on camera,” inICASSP 2024-2024 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 10 271–10 275
2024
-
[33]
V oxBlink2: A 100k+ speaker recognition corpus and the open-set speaker-identification benchmark,
Y . Lin, M. Cheng, F. Zhang, Y . Gao, S. Zhang, and M. Li, “V oxBlink2: A 100k+ speaker recognition corpus and the open-set speaker-identification benchmark,”arXiv preprint arXiv:2407.11510, 2024
-
[34]
MUSAN: A Music, Speech, and Noise Corpus
D. Snyder, G. Chen, and D. Povey, “MUSAN: A music, speech, and noise corpus,”arXiv preprint arXiv:1510.08484, 2015
work page Pith review arXiv 2015
-
[35]
A study on data augmentation of reverberant speech for robust speech recognition,
T. Ko, V . Peddinti, D. Povey, M. L. Seltzer, and S. Khudanpur, “A study on data augmentation of reverberant speech for robust speech recognition,” in2017 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2017, pp. 5220–5224
2017
-
[36]
Simam: A sim- ple, parameter-free attention module for convolutional neural networks,
L. Yang, R.-Y . Zhang, L. Li, and X. Xie, “Simam: A sim- ple, parameter-free attention module for convolutional neural networks,” inInternational conference on machine learning. PMLR, 2021, pp. 11 863–11 874
2021
-
[37]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,”arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review arXiv 2017
-
[38]
Arcface: Additive angular margin loss for deep face recognition,
J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, 2019, pp. 4690–4699
2019
-
[39]
Understanding intermediate layers using linear classifier probes
G. Alain and Y . Bengio, “Understanding intermediate lay- ers using linear classifier probes, 2018,”URL https://arxiv. org/abs/1610.01644, vol. 1610, 2018
work page internal anchor Pith review arXiv 2018
-
[40]
The bosaris toolkit: Theory, algorithms and code for surviving the new dcf,
N. Br ¨ummer and E. De Villiers, “The bosaris toolkit: Theory, algorithms and code for surviving the new dcf,”arXiv preprint arXiv:1304.2865, 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.